

Accuracy paradox
Encyclopedia
The accuracy paradox for predictive analytics
states that predictive models with a given level of accuracy may have greater predictive power
than models with higher accuracy. It may be better to avoid the accuracy metric in favor of other metrics such as precision
and recall.
Accuracy is often the starting point for analyzing the quality of a predictive model, as well as an obvious criterion for prediction. Accuracy measures the ratio of correct predictions to the total number of cases evaluated. It may seem obvious that the ratio of correct predictions to cases should be a key metric. A predictive model may have high accuracy, but be useless.
In an example predictive model for an insurance fraud
application, all cases that are predicted as high-risk by the model will be investigated. To evaluate the performance of the model, the insurance company has created a sample data set of 10,000 claims. All 10,000 cases in the validation
sample have been carefully checked and it is known which cases are fraudulent. To analyze the quality of the model, the insurance uses the table of confusion. The definition of accuracy, the table of confusion for model M1Fraud, and the calculation of accuracy for model M1Fraud is shown below.
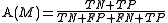
where
Formula 1: Definition of Accuracy
Table 1: Table of Confusion for Fraud Model M1Fraud.
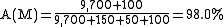
Formula 2: Accuracy for model M1Fraud
With an accuracy of 98.0% model M1Fraud appears to perform fairly well. The paradox lies in the fact that accuracy can be easily improved to 98.5% by always predicting "no fraud". The table of confusion and the accuracy for this trivial “always predict negative” model M2Fraud and the accuracy of this model are shown below.
Table 2: Table of Confusion for Fraud Model M2Fraud.
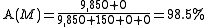
Formula 3: Accuracy for model M2Fraud
Model M2Fraudreduces the rate of inaccurate predictions from 2% to 1.5%. This is an apparent improvement of 25%. The new model M2Fraud shows fewer incorrect predictions and markedly improved accuracy, as compared to the original model M1Fraud, but is obviously useless.
The alternative model M2Fraud does not offer any value to the company for preventing fraud. The less accurate model is more useful than the more accurate model.
Model improvements should not be measured in terms of accuracy gains. It may be going too far to say that accuracy is irrelevant, but caution is advised when using accuracy in the evaluation of predictive models.
Predictive analytics
Predictive analytics encompasses a variety of statistical techniques from modeling, machine learning, data mining and game theory that analyze current and historical facts to make predictions about future events....
states that predictive models with a given level of accuracy may have greater predictive power
Predictive power
The predictive power of a scientific theory refers to its ability to generate testable predictions. Theories with strong predictive power are highly valued, because the predictions can often encourage the falsification of the theory...
than models with higher accuracy. It may be better to avoid the accuracy metric in favor of other metrics such as precision
Accuracy and precision
In the fields of science, engineering, industry and statistics, the accuracy of a measurement system is the degree of closeness of measurements of a quantity to that quantity's actual value. The precision of a measurement system, also called reproducibility or repeatability, is the degree to which...
and recall.
Accuracy is often the starting point for analyzing the quality of a predictive model, as well as an obvious criterion for prediction. Accuracy measures the ratio of correct predictions to the total number of cases evaluated. It may seem obvious that the ratio of correct predictions to cases should be a key metric. A predictive model may have high accuracy, but be useless.
In an example predictive model for an insurance fraud
Insurance fraud
Insurance fraud is any act committed with the intent to fraudulently obtain payment from an insurer.Insurance fraud has existed ever since the beginning of insurance as a commercial enterprise. Fraudulent claims account for a significant portion of all claims received by insurers, and cost billions...
application, all cases that are predicted as high-risk by the model will be investigated. To evaluate the performance of the model, the insurance company has created a sample data set of 10,000 claims. All 10,000 cases in the validation
Validity (statistics)
In science and statistics, validity has no single agreed definition but generally refers to the extent to which a concept, conclusion or measurement is well-founded and corresponds accurately to the real world. The word "valid" is derived from the Latin validus, meaning strong...
sample have been carefully checked and it is known which cases are fraudulent. To analyze the quality of the model, the insurance uses the table of confusion. The definition of accuracy, the table of confusion for model M1Fraud, and the calculation of accuracy for model M1Fraud is shown below.
where
- TN is the number of true negative cases
- FP is the number of false positive cases
- FN is the number of false negative cases
- TP is the number of true positive cases
Formula 1: Definition of Accuracy
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Negative Cases | 9,700 | 150 |
| Positive Cases | 50 | 100 |
Table 1: Table of Confusion for Fraud Model M1Fraud.
Formula 2: Accuracy for model M1Fraud
With an accuracy of 98.0% model M1Fraud appears to perform fairly well. The paradox lies in the fact that accuracy can be easily improved to 98.5% by always predicting "no fraud". The table of confusion and the accuracy for this trivial “always predict negative” model M2Fraud and the accuracy of this model are shown below.
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Negative Cases | 9,850 | 0 |
| Positive Cases | 150 | 0 |
Table 2: Table of Confusion for Fraud Model M2Fraud.
Formula 3: Accuracy for model M2Fraud
Model M2Fraudreduces the rate of inaccurate predictions from 2% to 1.5%. This is an apparent improvement of 25%. The new model M2Fraud shows fewer incorrect predictions and markedly improved accuracy, as compared to the original model M1Fraud, but is obviously useless.
The alternative model M2Fraud does not offer any value to the company for preventing fraud. The less accurate model is more useful than the more accurate model.
Model improvements should not be measured in terms of accuracy gains. It may be going too far to say that accuracy is irrelevant, but caution is advised when using accuracy in the evaluation of predictive models.
See also
- Receiver operating characteristicReceiver operating characteristicIn signal detection theory, a receiver operating characteristic , or simply ROC curve, is a graphical plot of the sensitivity, or true positive rate, vs. false positive rate , for a binary classifier system as its discrimination threshold is varied...
for other measures of how good model predictions are.