

Active learning (machine learning)
Encyclopedia
Active learning is a form of supervised machine learning
in which the learning algorithm is able to interactively query the user (or some other information source) to obtain the desired outputs at new data points. In statistics literature it is sometimes also called optimal experimental design.
There are situations in which unlabeled data is abundant but labeling data is expensive. In such a scenario the learning algorithm can actively query the user/teacher for labels. This type of iterative supervised learning is called active learning. Since the learner chooses the examples, the number of examples to learn a concept can often be much lower than the number required in normal supervised learning. With this approach there is a risk that the algorithm might focus on unimportant or even invalid examples.
Active learning can be especially useful in biological research problems such as Protein engineering
where a few proteins have been discovered with a certain interesting function and one wishes to determine which of many possible mutants to make next that will have a similar function.
 be the total set of all data under consideration. For example, in a protein engineering problem,
be the total set of all data under consideration. For example, in a protein engineering problem,  would include all proteins that are known to have a certain interesting activity and all additional proteins that one might want to test for that activity.
would include all proteins that are known to have a certain interesting activity and all additional proteins that one might want to test for that activity.
During each iteration, ,
,  is broken up into three subsets
is broken up into three subsets
Most of the current research in active learning involves the best method to choose the data points for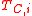 .
.
and exploit the structure of the SVM to determine which data points to label. Such methods usually calculate the margin, , of each unlabeled datum in
, of each unlabeled datum in 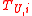 and treat
and treat  as an
as an  -dimensional distance from that datum to separating hyperplane.
-dimensional distance from that datum to separating hyperplane.
Minimum Marginal Hyperplane methods assume that the data with the smallest are those that the SVM is most uncertain about and therefore should be placed in
are those that the SVM is most uncertain about and therefore should be placed in 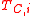 to be labeled. Other similar methods, such as Maximum Marginal Hyperplane, choose data with the largest
to be labeled. Other similar methods, such as Maximum Marginal Hyperplane, choose data with the largest  . Tradeoff methods choose a mix of the smallest and largest
. Tradeoff methods choose a mix of the smallest and largest  s.
s.
Maximum curiosity takes each unlabeled datum in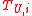 and assumes all possible labels that datum might have. This datum with each assumed class is added to
and assumes all possible labels that datum might have. This datum with each assumed class is added to 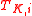 and then the new
and then the new 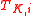 is cross-validated. It is assumed that when the datum is paired up with its correct label, the cross-validated accuracy (or correlation coefficient) of
is cross-validated. It is assumed that when the datum is paired up with its correct label, the cross-validated accuracy (or correlation coefficient) of 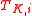 will most improve. The datum with the most improved accuracy is placed in
will most improve. The datum with the most improved accuracy is placed in 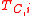 to be labeled
to be labeled
Supervised learning
Supervised learning is the machine learning task of inferring a function from supervised training data. The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value...
in which the learning algorithm is able to interactively query the user (or some other information source) to obtain the desired outputs at new data points. In statistics literature it is sometimes also called optimal experimental design.
There are situations in which unlabeled data is abundant but labeling data is expensive. In such a scenario the learning algorithm can actively query the user/teacher for labels. This type of iterative supervised learning is called active learning. Since the learner chooses the examples, the number of examples to learn a concept can often be much lower than the number required in normal supervised learning. With this approach there is a risk that the algorithm might focus on unimportant or even invalid examples.
Active learning can be especially useful in biological research problems such as Protein engineering
Protein engineering
Protein engineering is the process of developing useful or valuable proteins. It is a young discipline, with much research taking place into the understanding of protein folding and recognition for protein design principles....
where a few proteins have been discovered with a certain interesting function and one wishes to determine which of many possible mutants to make next that will have a similar function.
Definitions
Let be the total set of all data under consideration. For example, in a protein engineering problem, would include all proteins that are known to have a certain interesting activity and all additional proteins that one might want to test for that activity.During each iteration,
, is broken up into three subsets
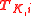 : Data points where the label is known.
: Data points where the label is known.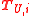 : Data points where the label is unknown.
: Data points where the label is unknown.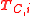 : A subset of
: A subset of 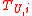 that is chosen to be labeled.
that is chosen to be labeled.
Most of the current research in active learning involves the best method to choose the data points for
.Minimum Marginal Hyperplane
Some active learning algorithms are built upon Support vector machines (SVMs)Support vector machine
A support vector machine is a concept in statistics and computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis...
and exploit the structure of the SVM to determine which data points to label. Such methods usually calculate the margin,
, of each unlabeled datum in and treat as an -dimensional distance from that datum to separating hyperplane.Minimum Marginal Hyperplane methods assume that the data with the smallest
are those that the SVM is most uncertain about and therefore should be placed in to be labeled. Other similar methods, such as Maximum Marginal Hyperplane, choose data with the largest . Tradeoff methods choose a mix of the smallest and largest s.Maximum Curiosity
Another active learning method, that typically learns a data set with fewer examples than Minimum Marginal Hyperplane but is more computationally intensive and only works for discrete classifiers is Maximum Curiosity.Maximum curiosity takes each unlabeled datum in
and assumes all possible labels that datum might have. This datum with each assumed class is added to and then the new is cross-validated. It is assumed that when the datum is paired up with its correct label, the cross-validated accuracy (or correlation coefficient) of will most improve. The datum with the most improved accuracy is placed in to be labeled