Algorithms for calculating variance play a major role in statistical
Statistics
Statistics is the study of the collection, organization, analysis, and interpretation of data. It deals with all aspects of this, including the planning of data collection in terms of the design of surveys and experiments....
computing. A key problem in the design of good algorithm
Algorithm
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
s for this problem is that formulas for the variance
Variance
In probability theory and statistics, the variance is a measure of how far a set of numbers is spread out. It is one of several descriptors of a probability distribution, describing how far the numbers lie from the mean . In particular, the variance is one of the moments of a distribution...
may involve sums of squares, which can lead to numerical instability as well as to arithmetic overflow
Arithmetic overflow
The term arithmetic overflow or simply overflow has the following meanings.# In a computer, the condition that occurs when a calculation produces a result that is greater in magnitude than that which a given register or storage location can store or represent.# In a computer, the amount by which a...
when dealing with large values.
Naïve algorithm
A formula for calculating the variance of an entire population
Statistical population
A statistical population is a set of entities concerning which statistical inferences are to be drawn, often based on a random sample taken from the population. For example, if we were interested in generalizations about crows, then we would describe the set of crows that is of interest...
of size n is:
A formula for calculating an unbiased estimate of the population variance from a finite sample of n observations is:
Therefore a naive algorithm to calculate the estimated variance is given by the following:
def naive_variance(data):
n = 0
Sum = 0
Sum_sqr = 0
for x in data:
n = n + 1
Sum = Sum + x
Sum_sqr = Sum_sqr + x*x
This algorithm can easily be adapted to compute the variance of a finite population: simply divide by n instead of n − 1 on the last line.
Because sum_sqr and sum * mean can be very similar numbers, the precision
Precision (arithmetic)
The precision of a value describes the number of digits that are used to express that value. In a scientific setting this would be the total number of digits or, less commonly, the number of fractional digits or decimal places...
of the result can be much less than the inherent precision of the floating-point arithmetic used to perform the computation. This is particularly bad if the standard deviation is small relative to the mean.
Two-pass algorithm
An alternate approach, using a different formula for the variance, first computes the sample mean,,
and then computes the sum of the squares of the differences from the mean,,
as given by the following pseudocode:
for x in data:
sum2 = sum2 + (x - mean)*(x - mean)
variance = sum2/(n - 1)
return variance
This algorithm is often more numerically reliable than the naïve algorithm for large sets of data, although it can be worse if much of the data is very close to but not precisely equal to the mean and some are quite far away from it.
The results of both of these simple algorithms (I and II) can depend inordinately on the ordering of the data and can give poor results for very large data sets due to repeated roundoff error in the accumulation of the sums. Techniques such as compensated summation can be used to combat this error to a degree.
Compensated variant
The compensated-summation version of the algorithm above reads:
def compensated_variance(data):
n = 0
sum1 = 0
for x in data:
n = n + 1
sum1 = sum1 + x
mean = sum1/n
It is often useful to be able to compute the variance in a single pass, inspecting each value only once; for example, when the data are being collected without enough storage to keep all the values, or when costs of memory access dominate those of computation. For such an online algorithm
Online algorithm
In computer science, an online algorithm is one that can process its input piece-by-piece in a serial fashion, i.e., in the order that the input is fed to the algorithm, without having the entire input available from the start. In contrast, an offline algorithm is given the whole problem data from...
In mathematics, a recurrence relation is an equation that recursively defines a sequence, once one or more initial terms are given: each further term of the sequence is defined as a function of the preceding terms....
is required between quantities from which the required statistics can be calculated in a numerically stable fashion.
The following formulas can be used to update the mean
Mean
In statistics, mean has two related meanings:* the arithmetic mean .* the expected value of a random variable, which is also called the population mean....
and (estimated) variance of the sequence, for an additional element . Here, n denotes the sample mean of the first n samples (x1, ..., xn), s2n their sample variance, and σ2n their population variance.
It turns out that a more suitable quantity for updating is the sum of squares of differences from the (current) mean, , here denoted :
A numerically stable algorithm is given below. It also computes the mean.
This algorithm is due to Knuth,
who cites Welford.
def online_variance(data):
n = 0
mean = 0
M2 = 0
for x in data:
n = n + 1
delta = x - mean
mean = mean + delta/n
M2 = M2 + delta*(x - mean)
This algorithm is much less prone to loss of precision due to massive cancellation, but might not be as efficient because of the division operation inside the loop. For a particularly robust two-pass algorithm for computing the variance, first compute and subtract an estimate of the mean, and then use this algorithm on the residuals.
The parallel algorithm below illustrates how to merge multiple sets of statistics calculated on-line.
Weighted incremental algorithm
The algorithm can be extended to handle unequal sample weights, replacing the simple counter n with the sum of weights seen so far. West (1979) suggests this incremental algorithm:
Chan et al. note that the above on-line algorithm III is a special case of an algorithm that works for any partition of the sample into sets , :.
This may be useful when, for example, multiple processing units may be assigned to discrete parts of the input.
Chan's method for estimating the mean is numerically unstable when and both are large, because the numerical error in is not scaled down in the way that it is in the case. In such cases, prefer .
Example
Assume that all floating point operations use the standard IEEE 754 double-precision arithmetic. Consider the sample (4, 7, 13, 16) from an infinite population. Based on this sample, the estimated population mean is 10, and the unbiased estimate of population variance is 30. Both Algorithm I and Algorithm II compute these values correctly. Next consider the sample (108 + 4, 108 + 7, 108 + 13, 108 + 16), which gives rise to the same estimated variance as the first sample. Algorithm II computes this variance estimate correctly, but Algorithm I returns 29.333333333333332 instead of 30. While this loss of precision may be tolerable and viewed as a minor flaw of Algorithm I, it is easy to find data that reveal a major flaw in the naive algorithm: Take the sample to be (109 + 4, 109 + 7, 109 + 13, 109 + 16). Again the estimated population variance of 30 is computed correctly by Algorithm II, but the naive algorithm now computes it as −170.66666666666666. This is a serious problem with Algorithm I and is due to catastrophic cancellation in the subtraction of two similar numbers at the final stage of the algorithm.
Higher-order statistics
Terriberry extends Chan's formulae to calculating the third and fourth central moment
Central moment
In probability theory and statistics, central moments form one set of values by which the properties of a probability distribution can be usefully characterised...
In probability theory and statistics, skewness is a measure of the asymmetry of the probability distribution of a real-valued random variable. The skewness value can be positive or negative, or even undefined...
In probability theory and statistics, kurtosis is any measure of the "peakedness" of the probability distribution of a real-valued random variable...
:
Here the are again the sums of powers of differences from the mean , giving
skewness:
kurtosis:
For the incremental case (i.e., ), this simplifies to:
By preserving the value , only one division operation is needed and the higher-order statistics can thus be calculated for little incremental cost.
An example of the online algorithm for kurtosis implemented as described is:
def online_kurtosis(data):
n = 0
mean = 0
M2 = 0
M3 = 0
M4 = 0
for x in data:
n1 = n
n = n + 1
delta = x - mean
delta_n = delta / n
delta_n2 = delta_n * delta_n
term1 = delta * delta_n * n1
mean = mean + delta_n
M4 = M4 + term1 * delta_n2 * (n*n - 3*n + 3) + 6 * delta_n2 * M2 - 4 * delta_n * M3
M3 = M3 + term1 * delta_n * (n - 2) - 3 * delta_n * M2
M2 = M2 + term1
kurtosis = (n*M4) / (M2*M2) - 3
return kurtosis
Pébay
further extends these results to arbitrary-order central moment
Central moment
In probability theory and statistics, central moments form one set of values by which the properties of a probability distribution can be usefully characterised...
s, for the incremental and the pairwise cases. One can also find there similar formulas for covariance
Covariance
In probability theory and statistics, covariance is a measure of how much two variables change together. Variance is a special case of the covariance when the two variables are identical.- Definition :...
.
Choi and Sweetman
offer two alternate methods to compute the skewness and kurtosis, each of which can save substantial computer memory requirements and CPU time in certain applications. The first approach is to compute the statistical moments by separating the data into bins and then computing the moments from the geometry of the resulting histogram, which effectively becomes a one-pass algorithm for higher moments. One benefit is that the statistical moment calculations can be carried out to arbitrary accuracy such that the computations can be tuned to the precision of, e.g., the data storage format or the original measurement hardware. A relative histogram of a random variable can be constructed in
the conventional way: the range of potential values is
divided into bins and the number of occurrences within each bin are
counted and plotted such that the area of each rectangle equals
the portion of the sample values within that bin:
where and represent the frequency and
the relative frequency at bin and is the total area of the histogram. After this
normalization, the raw moments and central moments of
can be calculated from the relative histogram:
where the superscript indicates the moments are
calculated from the histogram. For constant bin width these two expressions can be simplified using :
The second approach from Choi and Sweetman
is an analytical methodology to combine statistical moments from individual segments of a time-history such that the resulting overall moments are those of the complete time-history. This methodology could be used for parallel computation of statistical moments with subsequent combination of those moments, or for combination of statistical moments computed at sequential times.
If sets of statistical moments are known: for , then each can
be expressed in terms of the equivalent raw moments:
where is generally taken to be the duration of the time-history, or the number of points if is constant.
The benefit of expressing the statistical moments in
terms of is that the sets can be combined by
addition, and there is no upper limit on the value of .
where the subscript represents the concatenated
time-history or combined . These combined values of can then be inversely transformed into raw moments
representing the complete concatenated time-history
Known relationships between the raw moments () and the central moments ()
are then used to compute the central moments of the concatenated time-history. Finally, the statistical moments of the concatenated history are computed from the central moments:
Covariance
Very similar algorithms can be used to compute the covariance. The naive algorithm is:
For the algorithm above, one could use the following pseudocode:
def naive_covariance(data1, data2):
n = len(data1)
sum12 = 0
sum1 = sum(data1)
sum2 = sum(data2)
A more numerically stable two-pass algorithm first computes the sample means, and then the covariance:
The two-pass algorithm may be written as:
def two_pass_covariance(data1, data2):
n = len(data1)
mean1 = sum(data1) / n
mean2 = sum(data2) / n
covariance = 0
for i in range(n):
a = data1[i] - mean1
b = data2[i] - mean2
covariance += a*b / n
return covariance
A slightly more accurate compensated version performs the full naive algorithm on the residuals. The final sums and should be zero, but the second pass compensates for any small error.
A stable one-pass algorithm exists, similar to the one above, that computes :
The apparent asymmetry in that last equation is due to the fact that , so both update terms are equal to . Even greater accuracy can be achieved by first computing the means, then using the stable one-pass algorithm on the residuals.
Likewise, there is a formula for combining the covariances of two sets that can be used to parallelize the computation:.
Compute running(continuous) variance
The following algorithm may be applied.
For k = 1
M1 = x1 and S1 = 0
For 2 ≤ k ≤ n
The : estimate of the mean :
The : estimate of the variance is :
The : estimate of the standard deviation is :
The source of this article is wikipedia, the free encyclopedia. The text of this article is licensed under the GFDL.


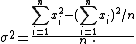
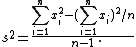
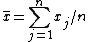 ,
, ,
,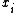 only once; for example, when the data are being collected without enough storage to keep all the values, or when costs of memory access dominate those of computation. For such an online algorithm
only once; for example, when the data are being collected without enough storage to keep all the values, or when costs of memory access dominate those of computation. For such an online algorithm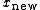 . Here, n denotes the sample mean of the first n samples (x1, ..., xn), s2n their sample variance, and σ2n their population variance.
. Here, n denotes the sample mean of the first n samples (x1, ..., xn), s2n their sample variance, and σ2n their population variance.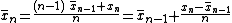
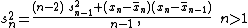

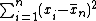 , here denoted
, here denoted  :
: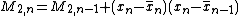

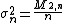
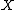 into sets
into sets 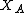 ,
, 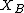 :
:
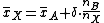
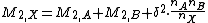 .
.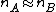 and both are large, because the numerical error in
and both are large, because the numerical error in 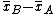 is not scaled down in the way that it is in the
is not scaled down in the way that it is in the 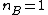 case. In such cases, prefer
case. In such cases, prefer  .
.
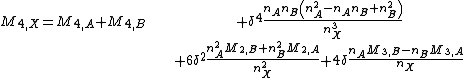
 are again the sums of powers of differences from the mean
are again the sums of powers of differences from the mean 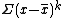 , giving
, giving
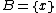 ), this simplifies to:
), this simplifies to:
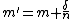


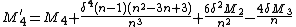
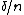 , only one division operation is needed and the higher-order statistics can thus be calculated for little incremental cost.
, only one division operation is needed and the higher-order statistics can thus be calculated for little incremental cost.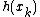 and
and  represent the frequency and
represent the frequency and and
and 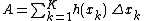 is the total area of the histogram. After this
is the total area of the histogram. After this raw moments and central moments of
raw moments and central moments of 
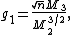
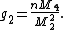

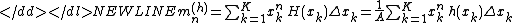
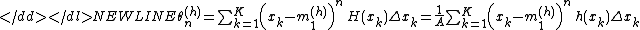
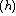 indicates the moments are
indicates the moments are these two expressions can be simplified using
these two expressions can be simplified using 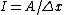 :
: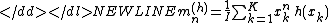
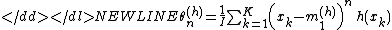
 sets of statistical moments are known:
sets of statistical moments are known: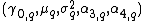 for
for  , then each
, then each  can
can raw moments:
raw moments:
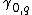 is generally taken to be the duration of the
is generally taken to be the duration of the  time-history, or the number of points if
time-history, or the number of points if  is constant.
is constant. is that the
is that the  sets can be combined by
sets can be combined by .
.
 represents the concatenated
represents the concatenated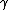 . These combined values of
. These combined values of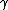 can then be inversely transformed into raw moments
can then be inversely transformed into raw moments
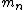 ) and the central moments (
) and the central moments ( )
)

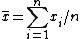
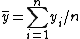
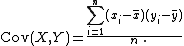
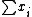 and
and 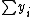 should be zero, but the second pass compensates for any small error.
should be zero, but the second pass compensates for any small error. :
: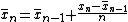


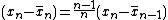 , so both update terms are equal to
, so both update terms are equal to 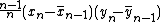 . Even greater accuracy can be achieved by first computing the means, then using the stable one-pass algorithm on the residuals.
. Even greater accuracy can be achieved by first computing the means, then using the stable one-pass algorithm on the residuals. .
.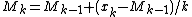

 estimate of the mean :
estimate of the mean :
 estimate of the variance is :
estimate of the variance is :
 estimate of the standard deviation is :
estimate of the standard deviation is :