
Cascading failure
Encyclopedia
A cascading failure is a failure in a system of interconnected parts in which the failure of a part can trigger the failure of successive parts.
systems, where a single point of failure
(SPF) on a fully loaded or slightly overloaded system results in a sudden spike across all nodes of the system. This surge current can induce the already overloaded nodes into failure, setting off more overloads and thereby taking down the entire system in a very short time.
This failure process cascades through the elements of the system like a ripple on a pond and continues until substantially all of the elements in the system are compromised and/or the system becomes functionally disconnected from the source of its load. For example, under certain conditions a large power grid can collapse after the failure of a single transformer.
Monitoring the operation of a system, in real-time
, and judicious disconnection of parts can help stop a cascade. Another common technique is to calculate a safety margin for the system by computer simulation of possible failures, to establish safe operating levels below which none of the calculated scenarios is predicted to cause cascading failure, and to identify the parts of the network which are most likely to cause cascading failures.
One of the primary problems with preventing electical grid failures is that the speed of the control signal is no faster than the speed of the propagating power overload, i.e. since both the control signal and the electrical power are moving at the speed of light, it is not possible to isolate the outage by sending a warning ahead to isolate the element. To ameliorate this systemic defect, superconducting magnetic energy storage units at critical junctions can store or release power for a few seconds to allow control systems to catch up and actuate isolating procedures.
s (such as the Internet
) in which network traffic
is severely impaired or halted to or between larger sections of the network, caused by failing or disconnected hardware or software. In this context, the cascading failure is known by the term cascade failure. A cascade failure can affect large groups of people and systems.
The cause of a cascade failure is usually the overloading of a single, crucial router or node, which causes the node to go down, even briefly. It can also be caused by taking a node down for maintenance or upgrades. In either case, traffic is routed
to or through another (alternative) path. This alternative path, as a result, becomes overloaded, causing it to go down, and so on. It will also affect systems which depend on the node for regular operation.
and high network latency
, not just to single systems, but to whole sections of a network or the internet. The high latency and packet loss is caused by the nodes that fail to operate due to congestion collapse, which causes them to still be present in the network but without much or any useful communication going through them. As a result, routes can still be considered valid, without them actually providing communication.
If enough routes go down because of a cascade failure, a complete section of the network or internet can become unreachable. Although undesired, this can help speed up the recovery from this failure as connections will time out, and other nodes will give up trying to establish connections to the section(s) that have become cut off, decreasing load on the involved nodes.
A common thing to see during a cascade failure is a walking failure, where sections go down, causing the next section to fail, after which the first section comes back up. This ripple can make several passes through the same sections or connecting nodes before stability is restored.
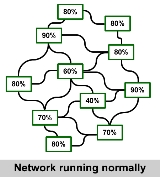
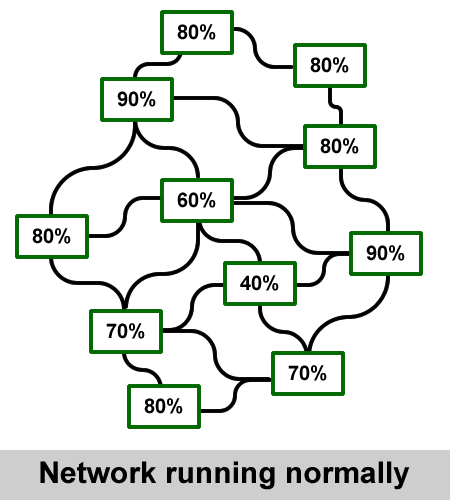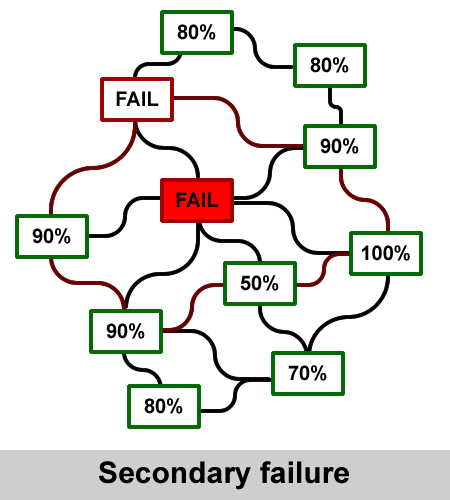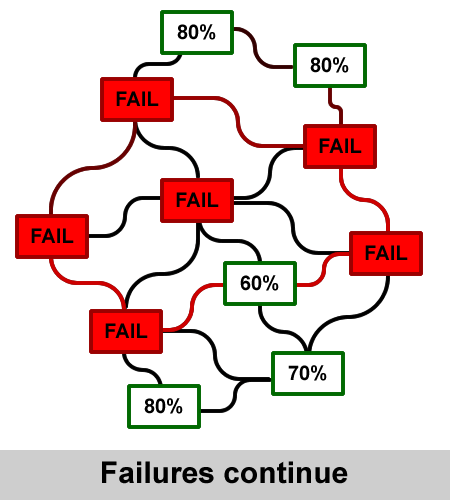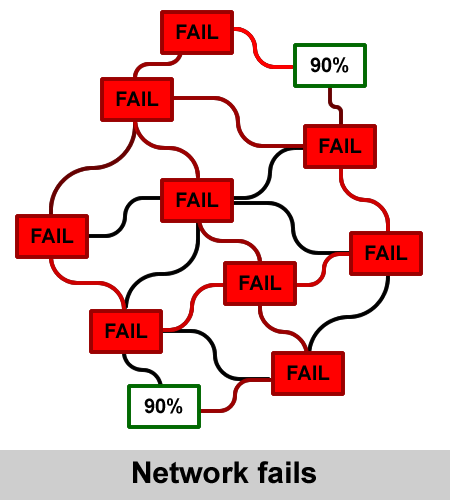 The animation shown here illustrates an example of a connecting node between a local ISP and their Internet backbone
The animation shown here illustrates an example of a connecting node between a local ISP and their Internet backbone
being overloaded.
Initially, the traffic that would normally go through the node is stopped. Systems and users get errors about not being able to reach hosts. Usually, the redundant systems of an ISP respond very quickly, choosing another path through a different backbone. The routing path through this alternative route is longer, with more hops
and subsequently going through more systems that normally do not process the amount of traffic suddenly offered.
This can cause one or more systems along the alternative route to go down, creating similar problems of their own.
Also, related systems are affected in this case. As an example, DNS
resolution might fail and what would normally cause systems to be interconnected, might break connections that are not even directly involved in the actual systems that went down. This, in turn, may cause seemingly unrelated nodes to develop problems, that can cause another cascade failure all on its own.
s caused by a small ischaemic
attack, which kill off far more cells than the initial damage, resulting in more toxins being released. Current research is to find a way to block this cascade in stroke patients to minimize the damage.
, which can also experience cascade failures wherein one failed diode
can result in all the diodes failing in a fraction of a second.
Yet another example of this effect in a scientific experiment was the implosion in 2001 of several thousand fragile glass photomultiplier tubes used in the Super-Kamiokande
experiment, where the shock wave caused by the failure of a single detector appears to have triggered the implosion of the other detectors in a chain reaction.
, the risk of cascading failures of financial institutions is referred to as systemic risk
: the failure of one financial institution may cause other financial institutions (its counterparties) to fail, cascading throughout the system. Institutions that are believed to pose systemic risk are deemed either "too big to fail
" (TBTF) or "too interconnected to fail" (TICTF), depending on why they appear to pose a threat.
Note however that systematic risk is not due to individual institutions per se, but due to the interconnections.
Cascading failure in power transmission
Cascading failure is common in power grids when one of the elements fails (completely or partially) and shifts its load to nearby elements in the system. Those nearby elements are then pushed beyond their capacity so they become overloaded and shift their load onto other elements. Cascading failure is a common effect seen in high voltageHigh voltage
The term high voltage characterizes electrical circuits in which the voltage used is the cause of particular safety concerns and insulation requirements...
systems, where a single point of failure
Single point of failure
A single point of failure is a part of a system that, if it fails, will stop the entire system from working. They are undesirable in any system with a goal of high availability or reliability, be it a business practice, software application, or other industrial system.-Overview:Systems can be made...
(SPF) on a fully loaded or slightly overloaded system results in a sudden spike across all nodes of the system. This surge current can induce the already overloaded nodes into failure, setting off more overloads and thereby taking down the entire system in a very short time.
This failure process cascades through the elements of the system like a ripple on a pond and continues until substantially all of the elements in the system are compromised and/or the system becomes functionally disconnected from the source of its load. For example, under certain conditions a large power grid can collapse after the failure of a single transformer.
Monitoring the operation of a system, in real-time
Real-time computing
In computer science, real-time computing , or reactive computing, is the study of hardware and software systems that are subject to a "real-time constraint"— e.g. operational deadlines from event to system response. Real-time programs must guarantee response within strict time constraints...
, and judicious disconnection of parts can help stop a cascade. Another common technique is to calculate a safety margin for the system by computer simulation of possible failures, to establish safe operating levels below which none of the calculated scenarios is predicted to cause cascading failure, and to identify the parts of the network which are most likely to cause cascading failures.
One of the primary problems with preventing electical grid failures is that the speed of the control signal is no faster than the speed of the propagating power overload, i.e. since both the control signal and the electrical power are moving at the speed of light, it is not possible to isolate the outage by sending a warning ahead to isolate the element. To ameliorate this systemic defect, superconducting magnetic energy storage units at critical junctions can store or release power for a few seconds to allow control systems to catch up and actuate isolating procedures.
Examples
- Blackout in northeast America in 1965Northeast Blackout of 1965The Northeast blackout of 1965 was a significant disruption in the supply of electricity on November 9, 1965, affecting Ontario, Canada and Connecticut, Massachusetts, New Hampshire, Rhode Island, Vermont, New York, and New Jersey in the United States...
- Blackout in northeast America in 2003Northeast Blackout of 2003The Northeast blackout of 2003 was a widespread power outage that occurred throughout parts of the Northeastern and Midwestern United States and Ontario, Canada on Thursday, August 14, 2003, just before 4:10 p.m....
- Blackout in Italy in 20032003 Italy blackoutThe 2003 Italy blackout was a serious power outage that affected all of Italy—except the islands of Sardinia and Capri—for 12 hours and part of Switzerland near Geneva for 3 hours on 28 September 2003. It was the largest blackout in the series of blackouts in 2003, affecting a total of...
- Blackout in London in 20032003 London blackoutThe 2003 London blackout was a serious power outage that occurred in parts of southern London and north-west Kent on 28 August 2003. It was the largest blackout in South East England since the Great Storm of 1987, affecting an estimated 500,000 people....
Cascading failure in computer networks
Cascading failures can also occur in computer networkComputer network
A computer network, often simply referred to as a network, is a collection of hardware components and computers interconnected by communication channels that allow sharing of resources and information....
s (such as the Internet
Internet
The Internet is a global system of interconnected computer networks that use the standard Internet protocol suite to serve billions of users worldwide...
) in which network traffic
Network traffic control
In computer networking, network traffic control is the process of managing, prioritising, controlling or reducing the network traffic, particularly Internet bandwidth, used by network administrators, to reduce congestion, latency and packet loss. This is part of bandwidth management...
is severely impaired or halted to or between larger sections of the network, caused by failing or disconnected hardware or software. In this context, the cascading failure is known by the term cascade failure. A cascade failure can affect large groups of people and systems.
The cause of a cascade failure is usually the overloading of a single, crucial router or node, which causes the node to go down, even briefly. It can also be caused by taking a node down for maintenance or upgrades. In either case, traffic is routed
Routing
Routing is the process of selecting paths in a network along which to send network traffic. Routing is performed for many kinds of networks, including the telephone network , electronic data networks , and transportation networks...
to or through another (alternative) path. This alternative path, as a result, becomes overloaded, causing it to go down, and so on. It will also affect systems which depend on the node for regular operation.
Symptoms
The symptoms of a cascade failure are easy to see: packet lossPacket loss
Packet loss occurs when one or more packets of data travelling across a computer network fail to reach their destination. Packet loss is distinguished as one of the three main error types encountered in digital communications; the other two being bit error and spurious packets caused due to noise.-...
and high network latency
Lag
Lag is a common word meaning to fail to keep up or to fall behind. In real-time applications, the term is used when the application fails to respond in a timely fashion to inputs...
, not just to single systems, but to whole sections of a network or the internet. The high latency and packet loss is caused by the nodes that fail to operate due to congestion collapse, which causes them to still be present in the network but without much or any useful communication going through them. As a result, routes can still be considered valid, without them actually providing communication.
If enough routes go down because of a cascade failure, a complete section of the network or internet can become unreachable. Although undesired, this can help speed up the recovery from this failure as connections will time out, and other nodes will give up trying to establish connections to the section(s) that have become cut off, decreasing load on the involved nodes.
A common thing to see during a cascade failure is a walking failure, where sections go down, causing the next section to fail, after which the first section comes back up. This ripple can make several passes through the same sections or connecting nodes before stability is restored.
History
Cascade failures are a relatively recent development, with the massive increase in traffic and the high interconnectivity between systems and networks. The term was first applied in this context in the late 1990s by a Dutch IT professional and has slowly become a relatively common term for this kind of large-scale failure.Example
Internet backbone
The Internet backbone refers to the principal data routes between large, strategically interconnected networks and core routers in the Internet...
being overloaded.
Initially, the traffic that would normally go through the node is stopped. Systems and users get errors about not being able to reach hosts. Usually, the redundant systems of an ISP respond very quickly, choosing another path through a different backbone. The routing path through this alternative route is longer, with more hops
Hop (telecommunications)
In telecommunication, the term hop has the following meanings:#The excursion of a radio wave from the Earth to the ionosphere and back to the Earth...
and subsequently going through more systems that normally do not process the amount of traffic suddenly offered.
This can cause one or more systems along the alternative route to go down, creating similar problems of their own.
Also, related systems are affected in this case. As an example, DNS
Domain name system
The Domain Name System is a hierarchical distributed naming system for computers, services, or any resource connected to the Internet or a private network. It associates various information with domain names assigned to each of the participating entities...
resolution might fail and what would normally cause systems to be interconnected, might break connections that are not even directly involved in the actual systems that went down. This, in turn, may cause seemingly unrelated nodes to develop problems, that can cause another cascade failure all on its own.
Biology
Analogues to this exist in biology of cascade-like effects where a small reaction can have system-wide implications. One example of this is the release of toxinToxin
A toxin is a poisonous substance produced within living cells or organisms; man-made substances created by artificial processes are thus excluded...
s caused by a small ischaemic
Ischemia
In medicine, ischemia is a restriction in blood supply, generally due to factors in the blood vessels, with resultant damage or dysfunction of tissue. It may also be spelled ischaemia or ischæmia...
attack, which kill off far more cells than the initial damage, resulting in more toxins being released. Current research is to find a way to block this cascade in stroke patients to minimize the damage.
Electronics
Another example is the Cockcroft-Walton generatorCockcroft-Walton generator
The Cockcroft–Walton generator, or multiplier, is an electric circuit which generates a high DC voltage from a low voltage AC or pulsing DC input...
, which can also experience cascade failures wherein one failed diode
Diode
In electronics, a diode is a type of two-terminal electronic component with a nonlinear current–voltage characteristic. A semiconductor diode, the most common type today, is a crystalline piece of semiconductor material connected to two electrical terminals...
can result in all the diodes failing in a fraction of a second.
Yet another example of this effect in a scientific experiment was the implosion in 2001 of several thousand fragile glass photomultiplier tubes used in the Super-Kamiokande
Super-Kamiokande
Super-Kamiokande is a neutrino observatory which is under Mount Kamioka near the city of Hida, Gifu Prefecture, Japan...
experiment, where the shock wave caused by the failure of a single detector appears to have triggered the implosion of the other detectors in a chain reaction.
Finance
In financeFinance
"Finance" is often defined simply as the management of money or “funds” management Modern finance, however, is a family of business activity that includes the origination, marketing, and management of cash and money surrogates through a variety of capital accounts, instruments, and markets created...
, the risk of cascading failures of financial institutions is referred to as systemic risk
Systemic risk
In finance, systemic risk is the risk of collapse of an entire financial system or entire market, as opposed to risk associated with any one individual entity, group or component of a system. It can be defined as "financial system instability, potentially catastrophic, caused or exacerbated by...
: the failure of one financial institution may cause other financial institutions (its counterparties) to fail, cascading throughout the system. Institutions that are believed to pose systemic risk are deemed either "too big to fail
Too Big to Fail
Too Big to Fail is a television drama film in the United States broadcast on HBO on May 23, 2011. It is based on the non-fiction book Too Big to Fail by Andrew Ross Sorkin. The TV film was directed by Curtis Hanson...
" (TBTF) or "too interconnected to fail" (TICTF), depending on why they appear to pose a threat.
Note however that systematic risk is not due to individual institutions per se, but due to the interconnections.
Infrastructures
Today’s networks are becoming increasingly dependent on one another. Diverse infrastructures such as water supply, transportation, fuel and power stations are coupled together. Owing to this coupling, interdependent networks are extremely sensitive to random failure, and in particular to targeted attacks, such that a failure of a small fraction of nodes from one network can produce an iterative cascade of failures in several interdependent networks. Electrical blackouts frequently result from a cascade of failures between interdependent networks, and the problem has been dramatically exemplified by the several large-scale blackouts that have occurred in recent years. Blackouts are a fascinating demonstration of the important role played by the dependencies between networks. For example, the September 28, 2003 blackout in Italy resulted in a widespread failure of the railway network, health care systems, and financial services and, in addition, severely influenced communication networks. The partial failure of the communication system in turn further impaired the power grid management system, thus producing a negative feedback on the power grid. This example emphasizes how inter-dependence can significantly magnify the damage in an interacting network system. A framework to study the cascading failures between coupled networks based on percolation theory was developed recently.See also
- Butterfly effectButterfly effectIn chaos theory, the butterfly effect is the sensitive dependence on initial conditions; where a small change at one place in a nonlinear system can result in large differences to a later state...
- Byzantine failure
- Cascading rollback
- Chain reactionChain reactionA chain reaction is a sequence of reactions where a reactive product or by-product causes additional reactions to take place. In a chain reaction, positive feedback leads to a self-amplifying chain of events....
- Chaos theoryChaos theoryChaos theory is a field of study in mathematics, with applications in several disciplines including physics, economics, biology, and philosophy. Chaos theory studies the behavior of dynamical systems that are highly sensitive to initial conditions, an effect which is popularly referred to as the...
- Cache stampedeCache stampedeA cache stampede is a type of cascading failure that can occur when massively parallel computing systems with caching mechanisms come under very high load. This behaviour is sometimes also called dog-piling....
- Congestion collapse
- Kessler SyndromeKessler SyndromeThe Kessler syndrome , proposed by NASA scientist Donald J...
- Virtuous circle and vicious circleVirtuous circle and vicious circleA virtuous circle and a vicious circle are economic terms. They refer to a complex of events that reinforces itself through a feedback loop. A virtuous circle has favorable results, while a vicious circle has detrimental results...
External links
- Space Weather: Blackout - Massive Power Grid Failure
- Cascading failure demo applet (Monash University's Virtual Lab)
- A. E. Motter and Y.-C. Lai, Cascade-based attacks on complex networks, Physical Review E (Rapid Communications) 66, 065102 (2002).
- Protection Strategies for Cascading Grid Failures — A Shortcut Approach
- Ian Dobson, Benjamin A. Carreras, and David E. Newman, preprint A loading-dependent model of probabilistic cascading failure, Probability in the Engineering and Informational Sciences, vol. 19, no. 1, January 2005, pp. 15–32.
- Nova: Crash of Flight 111 on September 2, 1998. Swissair Flight 111Swissair Flight 111Swissair Flight 111 was a Swissair McDonnell Douglas MD-11 on a scheduled airline flight from John F. Kennedy International Airport in New York City, United States to Cointrin International Airport in Geneva, Switzerland...
flying from New York to Geneva slammed into the Atlantic Ocean off the coast of Nova Scotia with 229 people aboard. Originally believed a terrorist act. After $39 million investigation, insurance settlement of $1.5 billion and more than four years, investigators unravel the puzzle: cascading failure. What is the legacy of Swissair 111? "We have a window into the internal structure of design, checks and balances, protection, and safety." -David Evans, Editor-in-Chief of Air Safety Week. - PhysicsWeb story: Accident grounds neutrino lab