
Data fusion
Encyclopedia
Data fusion, is generally defined as the use of techniques that combine data from multiple sources and gather that information into discrete, actionable items in order to achieve inferences, which will be more efficient and narrowly tailored than if they were achieved by means of disparate sources.
Data fusion processes are often categorized as low, intermediate or high, depending on the processing stage at which fusion takes place. Low level fusion, (Data fusion) combines several sources of raw data to produce new raw data. The expectation is that fused data is more informative and synthetic than the original inputs.
For example, sensor fusion
is also known as (multi-sensor) data fusion and is a subset of information fusion.
. In these applications, there is often a need to combine diverse data sets into a unified (fused) data set which includes all of the data points and time steps from the input data sets. The fused data set is different from a simple combined superset in that the points in the fused data set contain attributes and metadata which might not have been included for these points in the original data set.
A simplified example of this process is shown below where data set "α" is fused with data set β to form the fused data set δ. Data points in set "α" have spatial coordinates X and Y and attributes A1 and A2. Data points in set β have spatial coordinates X and Y and attributes B1 and B2. The fused data set contains all points and attributes
Input Data Set α
Input Data Set β
Fused Data Set δ
In this simple case all attributes are uniform across the entire analysis domain, so attributes may be simply assigned. In more realistic applications, attributes are rarely uniform and some type of interpolation is usually required to properly assign attributes to the data points in the fused set.
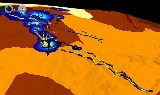
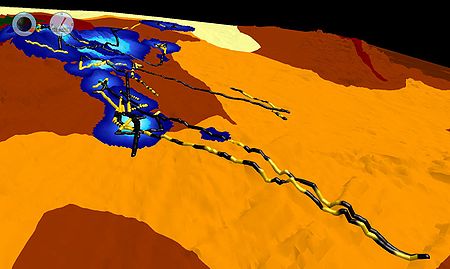 In a much more complicated application, marine animal researchers use data fusion to combine animal tracking data with bathymetric, meteorological, sea surface temperature
In a much more complicated application, marine animal researchers use data fusion to combine animal tracking data with bathymetric, meteorological, sea surface temperature
(SST) and animal habitat data to examine and understand habitat utilization and animal behavior in reaction to external forces such as weather or water temperature. Each of these data sets exhibit a different spatial grid and sampling rate so a simple combination would likely create erroneous assumptions and taint the results of the analysis. But through the use of data fusion, all data and attributes are brought together into a single view in which a more complete picture of the environment is created. This enables scientists to identify key locations and times and form new insights into the interactions between the environment and animal behaviors.
In the figure at right, rock lobsters are studied off the coast of Tasmania. Dr. Hugh Pederson of the University of Tasmania
used data fusion software to fuse southern rock lobster tracking data (color-coded for in yellow and black for day and night, respectively) with bathymetry and habitat data to create a unique 4D picture of rock lobster behavior.
and Data fusion apply. In areas such as business intelligence, for example, data integration is used to describe the combining of data, whereas data fusion is integration followed by reduction or replacement. Data integration might be viewed as set combination wherein the larger set is retained, whereas fusion is a set reduction technique with improved confidence.
Level 0: Source Preprocessing/subobject refinement
Level 1: Object refinement
Level 2: Situation refinement
Level 3: Impact Assessment (or Threat Refinement)
Level 4: Process Refinement
Level 5: User Refinement (or Cognitive Refinement)
Although the JDL Model is still in use today, it is often criticized for its implication that the levels necessarily happen in order from 0-5 and also for its lack of adequate representation of the potential for a human-in-the-loop. Despite these shortcomings, the JDL model is useful for visualizing the data fusion process and also for facilitating discussion and common understanding (Hall et al. 2007).
Data fusion processes are often categorized as low, intermediate or high, depending on the processing stage at which fusion takes place. Low level fusion, (Data fusion) combines several sources of raw data to produce new raw data. The expectation is that fused data is more informative and synthetic than the original inputs.
For example, sensor fusion
Sensor fusion
Sensor fusion is the combining of sensory data or data derived from sensory data from disparate sources such that the resulting information is in some sense better than would be possible when these sources were used individually...
is also known as (multi-sensor) data fusion and is a subset of information fusion.
Data Fusion in Geospatial Applications
In the geospatial (GIS) domain, data fusion is often synonymous with data integrationData integration
Data integration involves combining data residing in different sources and providing users with a unified view of these data.This process becomes significant in a variety of situations, which include both commercial and scientific domains...
. In these applications, there is often a need to combine diverse data sets into a unified (fused) data set which includes all of the data points and time steps from the input data sets. The fused data set is different from a simple combined superset in that the points in the fused data set contain attributes and metadata which might not have been included for these points in the original data set.
A simplified example of this process is shown below where data set "α" is fused with data set β to form the fused data set δ. Data points in set "α" have spatial coordinates X and Y and attributes A1 and A2. Data points in set β have spatial coordinates X and Y and attributes B1 and B2. The fused data set contains all points and attributes
Input Data Set α
| Point | X | Y | A1 | A2 |
|---|---|---|---|---|
| α1 | 10 | 10 | M | N |
| α2 | 10 | 30 | M | N |
| α3 | 30 | 10 | M | N |
| α4 | 30 | 30 | M | N |
Input Data Set β
| Point | X | Y | B1 | B2 |
|---|---|---|---|---|
| β1 | 20 | 20 | Q | R |
| β2 | 20 | 40 | Q | R |
| β3 | 40 | 20 | Q | R |
| β4 | 40 | 40 | Q | R |
Fused Data Set δ
| Point | X | Y | A1 | A2 | B1 | B2 |
|---|---|---|---|---|---|---|
| δ1 | 10 | 10 | M | N | Q | R |
| δ2 | 10 | 30 | M | N | Q | R |
| δ3 | 30 | 10 | M | N | Q | R |
| δ4 | 30 | 30 | M | N | Q | R |
| δ5 | 20 | 20 | M | N | Q | R |
| δ6 | 20 | 40 | M | N | Q | R |
| δ7 | 40 | 20 | M | N | Q | R |
| δ8 | 40 | 40 | M | N | Q | R |
In this simple case all attributes are uniform across the entire analysis domain, so attributes may be simply assigned. In more realistic applications, attributes are rarely uniform and some type of interpolation is usually required to properly assign attributes to the data points in the fused set.
Sea surface temperature
Sea surface temperature is the water temperature close to the oceans surface. The exact meaning of surface varies according to the measurement method used, but it is between and below the sea surface. Air masses in the Earth's atmosphere are highly modified by sea surface temperatures within a...
(SST) and animal habitat data to examine and understand habitat utilization and animal behavior in reaction to external forces such as weather or water temperature. Each of these data sets exhibit a different spatial grid and sampling rate so a simple combination would likely create erroneous assumptions and taint the results of the analysis. But through the use of data fusion, all data and attributes are brought together into a single view in which a more complete picture of the environment is created. This enables scientists to identify key locations and times and form new insights into the interactions between the environment and animal behaviors.
In the figure at right, rock lobsters are studied off the coast of Tasmania. Dr. Hugh Pederson of the University of Tasmania
University of Tasmania
The University of Tasmania is a medium-sized public Australian university based in Tasmania, Australia. Officially founded on 1 January 1890, it was the fourth university to be established in nineteenth-century Australia...
used data fusion software to fuse southern rock lobster tracking data (color-coded for in yellow and black for day and night, respectively) with bathymetry and habitat data to create a unique 4D picture of rock lobster behavior.
Data fusion vs. Data integration
In applications outside of the geospatial domain, differences in the usage of the terms Data integrationData integration
Data integration involves combining data residing in different sources and providing users with a unified view of these data.This process becomes significant in a variety of situations, which include both commercial and scientific domains...
and Data fusion apply. In areas such as business intelligence, for example, data integration is used to describe the combining of data, whereas data fusion is integration followed by reduction or replacement. Data integration might be viewed as set combination wherein the larger set is retained, whereas fusion is a set reduction technique with improved confidence.
Data Fusion and the JDL Model
In the mid-1980s, the Joint Directors of Laboratories formed the Data Fusion Subpanel (which later became known as the Data Fusion Group). The JDL/DFG introduced a model of data fusion that divided the various processes into 6 levels:Level 0: Source Preprocessing/subobject refinement
Level 1: Object refinement
Level 2: Situation refinement
Level 3: Impact Assessment (or Threat Refinement)
Level 4: Process Refinement
Level 5: User Refinement (or Cognitive Refinement)
Although the JDL Model is still in use today, it is often criticized for its implication that the levels necessarily happen in order from 0-5 and also for its lack of adequate representation of the potential for a human-in-the-loop. Despite these shortcomings, the JDL model is useful for visualizing the data fusion process and also for facilitating discussion and common understanding (Hall et al. 2007).
See also
- Data integrationData integrationData integration involves combining data residing in different sources and providing users with a unified view of these data.This process becomes significant in a variety of situations, which include both commercial and scientific domains...
- DataspacesDataspacesDataspaces are an abstraction in data management that aim to overcome some of the problems encountered in data integration system. The aim is to reduce the effort required to set up a data integration system by relying on existing matching and mapping generation techniques, and to improve the...
- Artificial intelligenceArtificial intelligenceArtificial intelligence is the intelligence of machines and the branch of computer science that aims to create it. AI textbooks define the field as "the study and design of intelligent agents" where an intelligent agent is a system that perceives its environment and takes actions that maximize its...
- Bayesian networkBayesian networkA Bayesian network, Bayes network, belief network or directed acyclic graphical model is a probabilistic graphical model that represents a set of random variables and their conditional dependencies via a directed acyclic graph . For example, a Bayesian network could represent the probabilistic...
- CRISP-DMCRISP-DMCRISP-DM stands for Cross Industry Standard Process for Data Mining. It is a data mining process model that describes commonly used approaches that expert data miners use to tackle problems. Polls conducted in 2002, 2004, and 2007 show that it is the leading methodology used by data miners...
- Data analysisData analysisAnalysis of data is a process of inspecting, cleaning, transforming, and modeling data with the goal of highlighting useful information, suggesting conclusions, and supporting decision making...
- Data farmingData farmingData Farming is the process of using a high performance computer or computing grid to run a simulation thousands or millions of times across a large parameter and value space...
- Data miningData miningData mining , a relatively young and interdisciplinary field of computer science is the process of discovering new patterns from large data sets involving methods at the intersection of artificial intelligence, machine learning, statistics and database systems...
- Descriptive statisticsDescriptive statisticsDescriptive statistics quantitatively describe the main features of a collection of data. Descriptive statistics are distinguished from inferential statistics , in that descriptive statistics aim to summarize a data set, rather than use the data to learn about the population that the data are...
- Fuzzy logicFuzzy logicFuzzy logic is a form of many-valued logic; it deals with reasoning that is approximate rather than fixed and exact. In contrast with traditional logic theory, where binary sets have two-valued logic: true or false, fuzzy logic variables may have a truth value that ranges in degree between 0 and 1...
- Hypothesis testing
- k-nearest neighbor algorithmK-nearest neighbor algorithmIn pattern recognition, the k-nearest neighbor algorithm is a method for classifying objects based on closest training examples in the feature space. k-NN is a type of instance-based learning, or lazy learning where the function is only approximated locally and all computation is deferred until...
- Machine learningMachine learningMachine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
- Image fusionImage fusionIn computer vision, Multisensor Image fusion is the process of combining relevant information from two or more images into a single image. The resulting image will be more informative than any of the input images....
- Pattern recognitionPattern recognitionIn machine learning, pattern recognition is the assignment of some sort of output value to a given input value , according to some specific algorithm. An example of pattern recognition is classification, which attempts to assign each input value to one of a given set of classes...
- Predictive analyticsPredictive analyticsPredictive analytics encompasses a variety of statistical techniques from modeling, machine learning, data mining and game theory that analyze current and historical facts to make predictions about future events....
- Preprocessing
- Sensor FusionSensor fusionSensor fusion is the combining of sensory data or data derived from sensory data from disparate sources such that the resulting information is in some sense better than would be possible when these sources were used individually...
- StatisticsStatisticsStatistics is the study of the collection, organization, analysis, and interpretation of data. It deals with all aspects of this, including the planning of data collection in terms of the design of surveys and experiments....
Application areas
- Geospatial Information Systems
- Business intelligenceBusiness intelligenceBusiness intelligence mainly refers to computer-based techniques used in identifying, extracting, and analyzing business data, such as sales revenue by products and/or departments, or by associated costs and incomes....
- OceanographyOceanographyOceanography , also called oceanology or marine science, is the branch of Earth science that studies the ocean...
- Discovery scienceDiscovery ScienceDiscovery science is a scientific methodology which emphasizes analysis of large volumes of experimental data with the goal of finding new patterns or correlations, leading to hypothesis formation and other scientific methodologies.Discovery-based methodologies are often viewed in contrast to...
- Business performance managementBusiness performance managementBusiness performance management is a set of management and analytic processes that enable the management of an organization's performance to achieve one or more pre-selected goals...
- Intelligent transport systems
- Loyalty card
- CheminformaticsCheminformaticsCheminformatics is the use of computer and informational techniques, applied to a range of problems in the field of chemistry. These in silico techniques are used in pharmaceutical companies in the process of drug discovery...
- Quantitative structure-activity relationshipQuantitative structure-activity relationshipQuantitative structure–activity relationship or QSPR is the process by which chemical structure is quantitatively correlated with a well defined process, such as biological activity or chemical reactivity.For example, biological activity can be expressed quantitatively as the concentration of a...
- Quantitative structure-activity relationship
- BioinformaticsBioinformaticsBioinformatics is the application of computer science and information technology to the field of biology and medicine. Bioinformatics deals with algorithms, databases and information systems, web technologies, artificial intelligence and soft computing, information and computation theory, software...
- Intelligence services
- Wireless sensor networks
General references
- Dave L. Hall and James Llinas, “Introduction to Multisensor Data Fusion”, Proc. of IEEE , Vol. 85, No. 1, pp. 6 – 23, Jan 1997.
- Erik Blasch, Ivan Kadar, John Salerno, Mieczyslaw Kokar, Subrata Dase, Gerald Powell, Daniel Corkill, and E. Euspini (2006), Issues and Challenges in Situation Assessment (Level 2 Fusion), Journal of Advances in Information Fusion, Vol 1, No 2, Dec. 2006.
Books
- Liggins, Martin E., David L. Hall, and James Llinas. Multisensor Data Fusion, Second Edition Theory and Practice (Multisensor Data Fusion). CRC, 2008. ISBN 978-1-4200-5308-1
- David L. Hall, Sonya A. H. McMullen, Mathematical Techniques in Multisensor Data Fusion (2004), ISBN 1580533353
- Springer, Information Fusion in Data Mining (2003), ISBN 3540006761
- H. B. Mitchell, Multi-sensor Data Fusion – An Introduction (2007) Springer-Verlag, Berlin, ISBN 9783540714637
- S. Das, High-Level Data Fusion (2008), Artech House Publishers, Norwood, MA, ISBN 9781596932814 and 1596932813