

Database storage structures
Encyclopedia
Database tables/indexes are typically stored on hard disk in one of many forms, ordered/unordered Flat files
, ISAM
, Heaps
, Hash buckets
or B+ Trees
. These have various advantages and disadvantages discussed in this topic. The most commonly used are B+trees and ISAM.
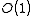 ), it may seem that it would have
), it may seem that it would have
inefficient retrieval times (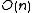 ), but this is usually never the case as most databases use indexes
), but this is usually never the case as most databases use indexes
on the primary keys, resulting in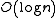 or
or 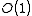 for keys that are the same as database row offsets within the database file storage system, efficient retrieval times.
for keys that are the same as database row offsets within the database file storage system, efficient retrieval times.
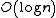 .
.
requires periodic reorganization if file is very volatile
Heap files are lists of unordered records of variable size. Although sharing a similar name, heap files are widely different from in-memory heaps
.
Flat file database
A flat file database describes any of various means to encode a database model as a single file .- Overview :...
, ISAM
ISAM
ISAM stands for Indexed Sequential Access Method, a method for indexing data for fast retrieval. ISAM was originally developed by IBM for mainframe computers...
, Heaps
Heap (data structure)
In computer science, a heap is a specialized tree-based data structure that satisfies the heap property: if B is a child node of A, then key ≥ key. This implies that an element with the greatest key is always in the root node, and so such a heap is sometimes called a max-heap...
, Hash buckets
Hash table
In computer science, a hash table or hash map is a data structure that uses a hash function to map identifying values, known as keys , to their associated values . Thus, a hash table implements an associative array...
or B+ Trees
B+ tree
In computer science, a B+ tree or B plus tree is a type of tree which represents sorted data in a way that allows for efficient insertion, retrieval and removal of records, each of which is identified by a key. It is a dynamic, multilevel index, with maximum and minimum bounds on the number of...
. These have various advantages and disadvantages discussed in this topic. The most commonly used are B+trees and ISAM.
Unordered
Unordered storage typically stores the records in the order they are inserted. While having good insertion efficiency (), it may seem that it would haveinefficient retrieval times (
), but this is usually never the case as most databases use indexesIndex (database)
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of slower writes and increased storage space...
on the primary keys, resulting in
or for keys that are the same as database row offsets within the database file storage system, efficient retrieval times.Ordered
Ordered storage typically stores the records in order and may have to rearrange or increase the file size in the case a record is inserted, this is very inefficient. However is better for retrieval as the records are pre-sorted, leading to a complexity of.Heap Files
- simplest and most basic method
- insert efficient, records added at end of file – ‘chronological’ order
- retrieval inefficient as searching has to be linear
- deletion – deleted records marked
requires periodic reorganization if file is very volatile
- advantages
- good for bulk loading data
- good for relatively small relations as indexing overheads are avoided
- good when retrievals involve large proportion of records
- disadvantages
- not efficient for selective retrieval using key values, especially if large
- sorting may be time-consuming
- not suitable for ‘volatile’ tables
Heap files are lists of unordered records of variable size. Although sharing a similar name, heap files are widely different from in-memory heaps
Heap (data structure)
In computer science, a heap is a specialized tree-based data structure that satisfies the heap property: if B is a child node of A, then key ≥ key. This implies that an element with the greatest key is always in the root node, and so such a heap is sometimes called a max-heap...
.
Hash buckets
- Hash functions calculate the address of the page in which the record is to be stored based on one or more fields in the record
- Hashing functions chosen to ensure that addresses are spread evenly across the address space
- ‘occupancy’ is generally 40% – 60% of total file size
- unique address not guaranteed so collision detection and collision resolution mechanisms are required
- open addressing
- chained/unchained overflow
- pros and cons
- efficient for exact matches on key field
- not suitable for range retrieval, which requires sequential storage
- calculates where the record is stored based on fields in the record
- hash functions ensure even spread of data
- collisions are possible, so collision detection and restoration is required
B+ trees
These are the most used in practice.- the time taken to access any tuple is the same because same number of nodes searched
- index is a full index so data file does not have to be ordered
- Pros and cons
- versatile data structure – sequential as well as random access
- access is fast
- supports exact, range, part key and pattern matches efficiently
- ‘volatile’ files are handled efficiently because index is dynamic – expands and contracts as table grows and shrinks
- less well suited to relatively stable files – in this case, ISAM is more efficient
See also
- ISAMISAMISAM stands for Indexed Sequential Access Method, a method for indexing data for fast retrieval. ISAM was originally developed by IBM for mainframe computers...
- B+tree
- Flat file databaseFlat file databaseA flat file database describes any of various means to encode a database model as a single file .- Overview :...
- Hash tables
- HeapsHeap (data structure)In computer science, a heap is a specialized tree-based data structure that satisfies the heap property: if B is a child node of A, then key ≥ key. This implies that an element with the greatest key is always in the root node, and so such a heap is sometimes called a max-heap...