The General Matrix Multiply (GEMM) is a subroutine
Subroutine
In computer science, a subroutine is a portion of code within a larger program that performs a specific task and is relatively independent of the remaining code....
Basic Linear Algebra Subprograms is a de facto application programming interface standard for publishing libraries to perform basic linear algebra operations such as vector and matrix multiplication. They were first published in 1979, and are used to build larger packages such as LAPACK...
In mathematics, matrix multiplication is a binary operation that takes a pair of matrices, and produces another matrix. If A is an n-by-m matrix and B is an m-by-p matrix, the result AB of their multiplication is an n-by-p matrix defined only if the number of columns m of the left matrix A is the...
, that is the multiplication of two matrices. This includes:
A complex number is a number consisting of a real part and an imaginary part. Complex numbers extend the idea of the one-dimensional number line to the two-dimensional complex plane by using the number line for the real part and adding a vertical axis to plot the imaginary part...
single precision, and
ZGEMM for complex double precision.
GEMM is often tuned by High Performance Computing vendors to run as fast as possible, because it is the building block for so many other routines. It is also the most important routine in the LINPACK
LINPACK
LINPACK is a software library for performing numerical linear algebra on digital computers. It was written in Fortran by Jack Dongarra, Jim Bunch, Cleve Moler, and Gilbert Stewart, and was intended for use on supercomputers in the 1970s and early 1980s...
benchmark. For this reason, implementations of fast BLAS library typically focus first on GEMM performance.
Operation
The xGEMM routine calculates the new value of matrix C based on the matrix-product of matrices A and B, and the old value of matrix C
where and values are scalar coefficients.
Fortran is a general-purpose, procedural, imperative programming language that is especially suited to numeric computation and scientific computing...
interface for these procedures are:
SUBROUTINE xGEMM ( TRANSA, TRANSB, M, N, K, ALPHA, A, LDA, B, LDB, BETA, C, LDC )
where TRANSA and TRANSB determines if the matrices A and B are to be transposed. M is the number of rows in matrix C and, depending on TRANSA, the number of rows in the original matrix A or its transpose. N is the number of columns in matrix C and, depending on TRANSB, the number of columns in the matrix B or its transpose. K is the number of columns in matrix A (or its transpose) and rows in matrix B (or its transpose). LDA, LDB and LDC specifies the size of the first dimension of the matrices, as laid out in memory; meaning the memory distance between the start of each row/column, depending on the memory structure .
C is a general-purpose computer programming language developed between 1969 and 1973 by Dennis Ritchie at the Bell Telephone Laboratories for use with the Unix operating system....
interface for these procedures are similar:
void cblas_xgemm (
const enum CBLAS_ORDER Order,
const enum CBLAS_TRANSPOSE TransA,
const enum CBLAS_TRANSPOSE TransB,
const int M,
const int N,
const int K,
const SCALAR alpha,
const TYPE * A,
const int lda,
const TYPE * B,
const int ldb,
const SCALAR beta,
TYPE * C,
const int ldc)
where 'x' in name is s,d,c, or z meaning single precision real, double precision real, single precision complex, or double precision complex, and other types have similar meanings as in Fortran
Fortran
Fortran is a general-purpose, procedural, imperative programming language that is especially suited to numeric computation and scientific computing...
C is a general-purpose computer programming language developed between 1969 and 1973 by Dennis Ritchie at the Bell Telephone Laboratories for use with the Unix operating system....
In computing, the GNU Scientific Library is a software library written in the C programming language for numerical calculations in applied mathematics and science...
, a corresponding interface is (take the double precision real case for instance):
int gsl_blas_dgemm(
CBLAS_TRANSPOSE_t TransA,
CBLAS_TRANSPOSE_t TransB,
double alpha,
const gsl_matrix * A,
const gsl_matrix * B,
double beta,
gsl_matrix * C)
where TransA is CblasNoTrans or CblasTrans for A or transposed A respectively, and TransB has similar choices .
Optimization
Not only is GEMM an important building block of other numeric software, it is often an important building block for calls to GEMM for larger matrices.
By decomposing one or both of the input matrices into block matrices
Block matrix
In the mathematical discipline of matrix theory, a block matrix or a partitioned matrix is a matrix broken into sections called blocks. Looking at it another way, the matrix is written in terms of smaller matrices. We group the rows and columns into adjacent 'bunches'. A partition is the rectangle...
, GEMM can be used repeatedly on the smaller blocks to build up
a result for the full matrix. This is one of the motivations for including the parameter, so the results of previous blocks can be accumulated.
Note that this decomposition requires the special case which many implementations optimize for, thereby eliminating one multiplication for each value of C.
In computer science, locality of reference, also known as the principle of locality, is the phenomenon of the same value or related storage locations being frequently accessed. There are two basic types of reference locality. Temporal locality refers to the reuse of specific data and/or resources...
both in space and time of the data used in the product.
This, in turn, takes advantage of the cache
CPU cache
A CPU cache is a cache used by the central processing unit of a computer to reduce the average time to access memory. The cache is a smaller, faster memory which stores copies of the data from the most frequently used main memory locations...
on the system . For systems with more than one level of cache,
the blocking can be applied a second time to the order in which the blocks are used in the computation.
Both of these levels of optimization are used in implementations such as ATLAS
Automatically Tuned Linear Algebra Software
Automatically Tuned Linear Algebra Software is a software library for linear algebra. It provides a mature open source implementation of BLAS APIs for C and Fortran77....
was a research associate at the Texas Advanced Computing Center at the University of Texas at Austin when he famously hand-optimized assembly routines for supercomputing and PC platforms that outperform the best compiler generated code. Several of the fastest supercomputers in the world still use...
have shown that blocking only for the L2 cache, combined with careful amortizing of copying to contiguous memory to reduce TLB misses, is superior to ATLAS
Automatically Tuned Linear Algebra Software
Automatically Tuned Linear Algebra Software is a software library for linear algebra. It provides a mature open source implementation of BLAS APIs for C and Fortran77....
. A highly tuned implementation based on these ideas are part of the GotoBLAS.
The source of this article is wikipedia, the free encyclopedia. The text of this article is licensed under the GFDL.



 and
and 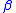 values are scalar coefficients.
values are scalar coefficients.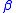 parameter, so the results of previous blocks can be accumulated.
parameter, so the results of previous blocks can be accumulated.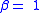 which many implementations optimize for, thereby eliminating one multiplication for each value of C.
which many implementations optimize for, thereby eliminating one multiplication for each value of C.