

Inverse Mills ratio
Encyclopedia
In statistics
, the inverse Mills ratio, named after John P. Mills, is the ratio
of the probability density function
to the cumulative distribution function
of a distribution.
Use of the inverse Mills ratio is often motivated by the following property of the truncated
normal distribution. If x is a random variable
distributed normally with mean μ and variance σ2, then
Statistics
Statistics is the study of the collection, organization, analysis, and interpretation of data. It deals with all aspects of this, including the planning of data collection in terms of the design of surveys and experiments....
, the inverse Mills ratio, named after John P. Mills, is the ratio
Ratio
In mathematics, a ratio is a relationship between two numbers of the same kind , usually expressed as "a to b" or a:b, sometimes expressed arithmetically as a dimensionless quotient of the two which explicitly indicates how many times the first number contains the second In mathematics, a ratio is...
of the probability density function
Probability density function
In probability theory, a probability density function , or density of a continuous random variable is a function that describes the relative likelihood for this random variable to occur at a given point. The probability for the random variable to fall within a particular region is given by the...
to the cumulative distribution function
Cumulative distribution function
In probability theory and statistics, the cumulative distribution function , or just distribution function, describes the probability that a real-valued random variable X with a given probability distribution will be found at a value less than or equal to x. Intuitively, it is the "area so far"...
of a distribution.
Use of the inverse Mills ratio is often motivated by the following property of the truncated
Truncation (statistics)
In statistics, truncation results in values that are limited above or below, resulting in a truncated sample. Truncation is similar to but distinct from the concept of statistical censoring. A truncated sample can be thought of as being equivalent to an underlying sample with all values outside the...
normal distribution. If x is a random variable
Random variable
In probability and statistics, a random variable or stochastic variable is, roughly speaking, a variable whose value results from a measurement on some type of random process. Formally, it is a function from a probability space, typically to the real numbers, which is measurable functionmeasurable...
distributed normally with mean μ and variance σ2, then
-
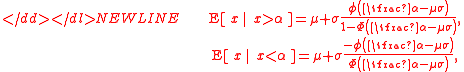
where α is a constant, ϕ denotes the standard normal density function, and Φ is the standard normal cumulative distribution function. The two fractions are the inverse Mills ratios.
A common application of the inverse Mills ratio (sometimes also called 'selection hazard') arises in regression analysisRegression analysisIn statistics, regression analysis includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables...
to take account of a possible selection biasSelection biasSelection bias is a statistical bias in which there is an error in choosing the individuals or groups to take part in a scientific study. It is sometimes referred to as the selection effect. The term "selection bias" most often refers to the distortion of a statistical analysis, resulting from the...
. If a dependent variable is censoredCensoring (statistics)In statistics, engineering, and medical research, censoring occurs when the value of a measurement or observation is only partially known.For example, suppose a study is conducted to measure the impact of a drug on mortality. In such a study, it may be known that an individual's age at death is at...
(i.e., not for all observations a positive outcome is observed) it causes a concentration of observations at zero values. This problem was first acknowledged by Tobin (1958), who showed that if this is not taken into consideration in the estimation procedure, an ordinary least squaresLeast squaresThe method of least squares is a standard approach to the approximate solution of overdetermined systems, i.e., sets of equations in which there are more equations than unknowns. "Least squares" means that the overall solution minimizes the sum of the squares of the errors made in solving every...
estimation (OLSLinear regressionIn statistics, linear regression is an approach to modeling the relationship between a scalar variable y and one or more explanatory variables denoted X. The case of one explanatory variable is called simple regression...
) will produce biasedBias (statistics)A statistic is biased if it is calculated in such a way that it is systematically different from the population parameter of interest. The following lists some types of, or aspects of, bias which should not be considered mutually exclusive:...
parameter estimates. With censored dependent variables there is a violation of the Gauss–Markov assumption of zero correlationCorrelationIn statistics, dependence refers to any statistical relationship between two random variables or two sets of data. Correlation refers to any of a broad class of statistical relationships involving dependence....
between independent variables and the error termErrors and residuals in statisticsIn statistics and optimization, statistical errors and residuals are two closely related and easily confused measures of the deviation of a sample from its "theoretical value"...
. Heckman (1976) proposed a two-stage estimation procedure using the inverse Mills' ratio to take account of the selection bias. In a first step, a regression for observing a positive outcome of the dependent variable is modeled with a probitProbitIn probability theory and statistics, the probit function is the inverse cumulative distribution function , or quantile function associated with the standard normal distribution...
model.
The inverse mills ratio must be generated from the estimation of a probit modelProbit modelIn statistics, a probit model is a type of regression where the dependent variable can only take two values, for example married or not married....
, a logitLogitThe logit function is the inverse of the sigmoidal "logistic" function used in mathematics, especially in statistics.Log-odds and logit are synonyms.-Definition:The logit of a number p between 0 and 1 is given by the formula:...
cannot be used. The probit modelProbit modelIn statistics, a probit model is a type of regression where the dependent variable can only take two values, for example married or not married....
assumes that the error term follows a standard normal distribution. The estimated parameters are used to calculate the inverse Mills ratio, which is then included as an additional explanatory variable in the OLS estimation. See Heckman correctionHeckman correctionThe Heckman correction is any of a number of related statistical methods developed by James Heckman in 1976 through 1979 which allow the researcher to correct for selection bias...
for more details.