

Kadir brady saliency detector
Encyclopedia
The Kadir–Brady saliency detector extracts features of objects in images that are distinct and representative. It was invented by Timor Kadir and Michael Brady in 2001 and an affine invariant version was introduced by Kadir and Brady in 2004.
The detector uses the algorithms to more efficiently remove background noise and so more easily identify features which can be used in a 3D model. As the detector scans images it uses the three basics of global transformation, local perturbations and intra-class variations to define the areas of search, and identifies unique regions of those images rather than using the more traditional corner or blob searches. It attempts to be invariant to affine transformations and illumination changes.
This leads to a more object oriented search than previous methods and outperforms other detectors due to non blurring of the images, an ability to ignore slowly changing regions and a broader definition of surface geometry properties. As a result the Kadir–Brady saliency detector is more capable at object recognition than other detectors whose main focus is on whole image correspondence.
and image processing
applications work directly with the features extracted from an image, rather than the raw image; for example, for computing image correspondences [2, 17, 19,20, 22], or for learning object
categories [1, 3, 4, 23]. Depending on the applications, different characteristics are preferred. However there are three broad classes of image change under which good performance may be required:
Global transformation: Features should be repeatable across the expected class of global image transformations. These include both geometric and photometric transformations that arise due to changes in the imaging conditions. For example, region detection should be covariant with viewpoint as illustrated in Figure 1. In short, we require the segmentation to commute with viewpoint change. This property will be evaluated on the repeatability and accuracy of localization and region estimation.
Local perturbations: Features should be insensitive to classes of semi-local image disturbances. For example a feature responding to the eye of a human face should be unaffected by any motion of the mouth. A second class of disturbance is where a region neighbours a foreground/background boundary. The detector can be required to detect the foreground region despite changes in the background.
Intra-class variations: Features should capture corresponding object parts under intra-class variations in objects. For example the headlight of a car for different brands of car (imaged from the same viewpoint).
All Feature detection
algorithms are trying to detect regions which is stable under three types of image change described above. Instead of finding corner[7 21], or blob[17 22], or any specific shape of regions Kadir–Brady saliency detector looks for regions which are locally complex, and globally discriminative. Such regions usually correspond to regions more stable under these types of image change.
Shannon entropy
is defined to quantify the complexity of a distribution p as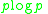 . Therefore higher entropy means p is more complex hence more unpredictable.
. Therefore higher entropy means p is more complex hence more unpredictable.
To measure the complexity of an image region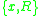 around point
around point  with shape
with shape 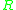 ,
,
a descriptor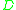 that takes on values
that takes on values 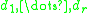
(e.g., in an 8 bit
grey level image, D would range from 0 to 255 for each pixel) is defined
so that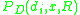 , the probability of descriptor value
, the probability of descriptor value 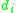
occurs in region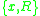 can be computed.
can be computed.
Further, the entropy of image region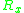 can compute as
can compute as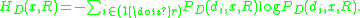
Using this entropy equation we can further calculate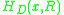 for every point
for every point 
and region shape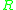 . A more complex region, like the eye region, has a more complex distributor and hence higher entropy.
. A more complex region, like the eye region, has a more complex distributor and hence higher entropy.
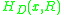 is a good measure for local complexity. Entropy only measures the statistic of local attribute. It does not measure the spatial arrangement of the local attribute. However, these four regions are not equally discriminative under scale change. This observation is used to define measure on discriminative in subsections.
is a good measure for local complexity. Entropy only measures the statistic of local attribute. It does not measure the spatial arrangement of the local attribute. However, these four regions are not equally discriminative under scale change. This observation is used to define measure on discriminative in subsections.
The following subsections will discuss different methods to select regions with high local complexity and more discriminative across different region.
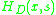 , where s is the scale parameter
, where s is the scale parameter
of a circle region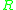 , the algorithm selects a set of circle region,
, the algorithm selects a set of circle region,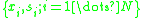 .
.
The method consists of three steps:
The final saliency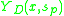 is the product of
is the product of 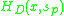 and
and 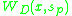 .
.
For each x the method picks a scale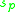 and calculates salient score
and calculates salient score 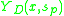 .
.
By comparing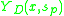 of different points
of different points  the detector can rank the saliency of points and pick the most representative ones.
the detector can rank the saliency of points and pick the most representative ones.
To detect affine invariant region, the detector need to detect ellipse as in figure 4.
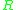 now is parameterized by three parameter (s, "ρ", "θ"), where "ρ" is the axis ratio and "θ" the orientation of the ellipse.
now is parameterized by three parameter (s, "ρ", "θ"), where "ρ" is the axis ratio and "θ" the orientation of the ellipse.
This modification increases the search space of the previous algorithm from a scale to a set of parameters and therefore the complexity of the affine invariant saliency detector increases. In practice the affine invariant saliency detector starts with the set of points
and scales generated from the similarity invariant saliency detector then iteratively approximates the suboptimal parameters.
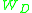 is measured over isotropic scale.
is measured over isotropic scale.
To summarize: Affine invariant saliency detector is invariant to affine transformation
and able to detect more generate salient regions.
which both act as randomisers and generally increase entropy, affecting previously low entropy values more than high entropy values.
A more robust method would be to pick regions rather than points in entropy space. Although the individual pixels within a salient region may be affected at any given instant, by the noise, it is unlikely to affect all of them in such a way that the region as a whole becomes non-salient.
It is also necessary to analyze the whole saliency space such that each salient feature is represented. A global threshold approach would result in highly salient features in one part of the image dominating the rest. A local threshold approach would require the setting of another scale parameter.
A simple clustering algorithm meets these two requirements are used at the end of the algorithm. It works by selecting highly salient points that have local support i.e. nearby points with similar saliency and scale. Each region must be sufficiently distant from all others (in R3) to qualify as a separate entity. For robustness we use a representation that includes all of the points in a selected region. The method works as follows:
The algorithm is implemented as GreedyCluster1.m in matlab by Dr. Timor Kadir
different feature detectors have been evaluated by several tests. The most profound evaluation is published in the International Journal of Computer Vision in 2006.
The following subsection discuss the performance of Kadir–Brady saliency detector on a subset of a test in the paper.
Firstly, overlap error of a pair of corresponding ellipses
of a pair of corresponding ellipses 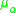 and
and 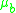 each on different images is defined:
each on different images is defined:
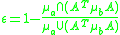
where A is the locally linearized affine transformation of the homography between the two images,
and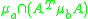 and
and 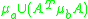
represent the area of intersection and union of the ellipses respectively.
Notice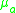 is scaled into a fix scale to take the count of size variation of different detected region. Only if
is scaled into a fix scale to take the count of size variation of different detected region. Only if  is smaller than certain
is smaller than certain 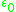 , the pair of ellipses are deemed to correspond.
, the pair of ellipses are deemed to correspond.
Then the repeatability score for a given pair of images is computed as the ratio between the number of region-to-region correspondences and the smaller of the number of regions in the pair of images, where only the regions located in the part of the scene present in both images are counted. In general we would like a detector to have a high repeatability score and a large number of correspondences.
The specific global transformations tested in the test dataset are:
The performance of Kadir–Brady saliency detector is inferior to most of other detectors mainly because the number of points detected is usually lower than other detectors.
The precise procedure is given in the Matlab code from Detector evaluation
#Software implementation.
Repeatability over intra-class variation is measuring the (average) number of correct correspondences over the set of images, where the correct correspondences is established by manual selection.
A region is matched if it fulfills three requirements:
In detail the average correspondence score S is measured as follows.
N regions are detected on each image of the M images in the dataset. Then for a particular reference image, i , the correspondence score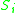 is given by the proportion of corresponding to detected regions for all the other images in the dataset, i.e.:
is given by the proportion of corresponding to detected regions for all the other images in the dataset, i.e.:

The score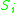 is computed for M/2 different selections of the reference image and averaged to give S. The score is evaluated as a function of the number of detected regions N.
is computed for M/2 different selections of the reference image and averaged to give S. The score is evaluated as a function of the number of detected regions N.
The Kadir–Brady saliency detector gives the highest score across three test classes which are motorbike, car and face.
The saliency detector indicates that most detections are near the object. In contrast, other detectors maps show a much more diffuse pattern over the entire area caused by poor localization and false responses to background clutter.
is split into two parts: the first contains images with a uniform background and the second images with varying degrees of background clutter. If the detector is robust to background clutter then the average correspondence score S should be similar for both subsets of images.
In this test saliency detector also outperforms other detectors due to three reasons:
The saliency detector is most useful in the task of object recognition, whereas several other detectors are more useful in the task of computing image correspondences. However, in the task of 3D object recognition where all three types of image change are combined, saliency detector might still be powerful.
interest points from Laplacian and determinant of Hessian blob detection
as well as more general mechanisms for automatic scale selection) (summary and review of a number of feature detectors formulated; based on a scale-space
representation) (theory for affine invariant interest points and shape descriptors from second-moment matrices)
The detector uses the algorithms to more efficiently remove background noise and so more easily identify features which can be used in a 3D model. As the detector scans images it uses the three basics of global transformation, local perturbations and intra-class variations to define the areas of search, and identifies unique regions of those images rather than using the more traditional corner or blob searches. It attempts to be invariant to affine transformations and illumination changes.
This leads to a more object oriented search than previous methods and outperforms other detectors due to non blurring of the images, an ability to ignore slowly changing regions and a broader definition of surface geometry properties. As a result the Kadir–Brady saliency detector is more capable at object recognition than other detectors whose main focus is on whole image correspondence.
Introduction
Many computer visionComputer vision
Computer vision is a field that includes methods for acquiring, processing, analysing, and understanding images and, in general, high-dimensional data from the real world in order to produce numerical or symbolic information, e.g., in the forms of decisions...
and image processing
Image processing
In electrical engineering and computer science, image processing is any form of signal processing for which the input is an image, such as a photograph or video frame; the output of image processing may be either an image or, a set of characteristics or parameters related to the image...
applications work directly with the features extracted from an image, rather than the raw image; for example, for computing image correspondences [2, 17, 19,20, 22], or for learning object
Learning object
A learning object is "a collection of content items, practice items, and assessment items that are combined based on a single learning objective". The term is credited to Wayne Hogins when he created a working group in 1994 bearing the name though the concept was first described by Gerard in 1967...
categories [1, 3, 4, 23]. Depending on the applications, different characteristics are preferred. However there are three broad classes of image change under which good performance may be required:
Global transformation: Features should be repeatable across the expected class of global image transformations. These include both geometric and photometric transformations that arise due to changes in the imaging conditions. For example, region detection should be covariant with viewpoint as illustrated in Figure 1. In short, we require the segmentation to commute with viewpoint change. This property will be evaluated on the repeatability and accuracy of localization and region estimation.
Local perturbations: Features should be insensitive to classes of semi-local image disturbances. For example a feature responding to the eye of a human face should be unaffected by any motion of the mouth. A second class of disturbance is where a region neighbours a foreground/background boundary. The detector can be required to detect the foreground region despite changes in the background.
Intra-class variations: Features should capture corresponding object parts under intra-class variations in objects. For example the headlight of a car for different brands of car (imaged from the same viewpoint).
All Feature detection
Feature detection
In computer vision and image processing the concept of feature detection refers to methods that aim at computing abstractions of image information and making local decisions at every image point whether there is an image feature of a given type at that point or not...
algorithms are trying to detect regions which is stable under three types of image change described above. Instead of finding corner[7 21], or blob[17 22], or any specific shape of regions Kadir–Brady saliency detector looks for regions which are locally complex, and globally discriminative. Such regions usually correspond to regions more stable under these types of image change.
Information-theoretic saliency
In the field of Information theoryInformation theory
Information theory is a branch of applied mathematics and electrical engineering involving the quantification of information. Information theory was developed by Claude E. Shannon to find fundamental limits on signal processing operations such as compressing data and on reliably storing and...
Shannon entropy
Information entropy
In information theory, entropy is a measure of the uncertainty associated with a random variable. In this context, the term usually refers to the Shannon entropy, which quantifies the expected value of the information contained in a message, usually in units such as bits...
is defined to quantify the complexity of a distribution p as
. Therefore higher entropy means p is more complex hence more unpredictable.To measure the complexity of an image region
around point with shape ,a descriptor
that takes on values (e.g., in an 8 bit
8-bit
The first widely adopted 8-bit microprocessor was the Intel 8080, being used in many hobbyist computers of the late 1970s and early 1980s, often running the CP/M operating system. The Zilog Z80 and the Motorola 6800 were also used in similar computers...
grey level image, D would range from 0 to 255 for each pixel) is defined
so that
, the probability of descriptor value occurs in region
can be computed.Further, the entropy of image region
can compute as Using this entropy equation we can further calculate
for every point and region shape
. A more complex region, like the eye region, has a more complex distributor and hence higher entropy. is a good measure for local complexity. Entropy only measures the statistic of local attribute. It does not measure the spatial arrangement of the local attribute. However, these four regions are not equally discriminative under scale change. This observation is used to define measure on discriminative in subsections.The following subsections will discuss different methods to select regions with high local complexity and more discriminative across different region.
Similarity-invariant saliency
The first version of Kadir–Brady saliency detector[10] only finds Salient regions invariant under similarity transformation. The algorithm finds circle regions with different scales. In other words given, where s is the scale parameterScale parameter
In probability theory and statistics, a scale parameter is a special kind of numerical parameter of a parametric family of probability distributions...
of a circle region
, the algorithm selects a set of circle region,.The method consists of three steps:
- Calculation of Shannon entropy of local image attributes for each x over a range of scales —
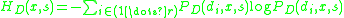 ;
; - Select scales at which the entropy over scale function exhibits a peak —
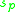 ;
; - Calculate the magnitude change of the PDF as a function of scale at each peak —
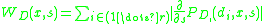 (s).
(s).
The final saliency
is the product of and .For each x the method picks a scale
and calculates salient score .By comparing
of different points the detector can rank the saliency of points and pick the most representative ones.Affine-invariant saliency
Previous method is invariant to the similarity group of geometric transformations and to photometric shifts. However, as mentioned in the opening remarks, the ideal detector should detect region invariant up to viewpoint change. There are several detector [] can detect affine invariant region which is a better approximation of viewpoint change than similarity transformation.To detect affine invariant region, the detector need to detect ellipse as in figure 4.
now is parameterized by three parameter (s, "ρ", "θ"), where "ρ" is the axis ratio and "θ" the orientation of the ellipse.This modification increases the search space of the previous algorithm from a scale to a set of parameters and therefore the complexity of the affine invariant saliency detector increases. In practice the affine invariant saliency detector starts with the set of points
Railroad switch
A railroad switch, turnout or [set of] points is a mechanical installation enabling railway trains to be guided from one track to another at a railway junction....
and scales generated from the similarity invariant saliency detector then iteratively approximates the suboptimal parameters.
Comparison
Although similarity invariant saliency detector is faster than Affine invariant saliency detector it also has the drawback of favoring isotropic structure, since the discriminative measure is measured over isotropic scale.To summarize: Affine invariant saliency detector is invariant to affine transformation
Affine transformation
In geometry, an affine transformation or affine map or an affinity is a transformation which preserves straight lines. It is the most general class of transformations with this property...
and able to detect more generate salient regions.
Salient volume
It is intuitive to pick points from a higher salient score directly and stop when a certain number of threshold on "number of points" or "salient score" is satisfied. Natural images contain noise and motion blurMotion blur
Motion blur is the apparent streaking of rapidly moving objects in a still image or a sequence of images such as a movie or animation. It results when the image being recorded changes during the recording of a single frame, either due to rapid movement or long exposure.- Photography :When a camera...
which both act as randomisers and generally increase entropy, affecting previously low entropy values more than high entropy values.
A more robust method would be to pick regions rather than points in entropy space. Although the individual pixels within a salient region may be affected at any given instant, by the noise, it is unlikely to affect all of them in such a way that the region as a whole becomes non-salient.
It is also necessary to analyze the whole saliency space such that each salient feature is represented. A global threshold approach would result in highly salient features in one part of the image dominating the rest. A local threshold approach would require the setting of another scale parameter.
A simple clustering algorithm meets these two requirements are used at the end of the algorithm. It works by selecting highly salient points that have local support i.e. nearby points with similar saliency and scale. Each region must be sufficiently distant from all others (in R3) to qualify as a separate entity. For robustness we use a representation that includes all of the points in a selected region. The method works as follows:
- Apply a global threshold.
- Choose the highest salient point in saliency-space (Y).
- Find the K nearest neighbours (K is a pre-set constant).
- Test the support of these using variance of the centre points.
- Find distance, D, in R3 from salient regions already clustered.
- Accept, if D > scalemean of the region and if sufficiently clustered (variance is less than pre-set threshold Vth ).
- Store as the mean scale and spatial location of K points.
- Repeat from step 2 with next highest salient point.
The algorithm is implemented as GreedyCluster1.m in matlab by Dr. Timor Kadir
Performance evaluation
In the field of computer visionComputer vision
Computer vision is a field that includes methods for acquiring, processing, analysing, and understanding images and, in general, high-dimensional data from the real world in order to produce numerical or symbolic information, e.g., in the forms of decisions...
different feature detectors have been evaluated by several tests. The most profound evaluation is published in the International Journal of Computer Vision in 2006.
The following subsection discuss the performance of Kadir–Brady saliency detector on a subset of a test in the paper.
Performance under global transformation
In order to measure the consistency of a region detected on the same object or scene across images under global transformation, repeatability score, which is first proposed by Mikolajczyk and Cordelia Schmid in [18, 19] is calculated as follows:Firstly, overlap error
of a pair of corresponding ellipses and each on different images is defined:where A is the locally linearized affine transformation of the homography between the two images,
and
and represent the area of intersection and union of the ellipses respectively.
Notice
is scaled into a fix scale to take the count of size variation of different detected region. Only if is smaller than certain , the pair of ellipses are deemed to correspond.Then the repeatability score for a given pair of images is computed as the ratio between the number of region-to-region correspondences and the smaller of the number of regions in the pair of images, where only the regions located in the part of the scene present in both images are counted. In general we would like a detector to have a high repeatability score and a large number of correspondences.
The specific global transformations tested in the test dataset are:
- Viewpoint change
- Zoom+rotation
- Image blur
- JPEG compression
- Light change
The performance of Kadir–Brady saliency detector is inferior to most of other detectors mainly because the number of points detected is usually lower than other detectors.
The precise procedure is given in the Matlab code from Detector evaluation
#Software implementation.
Performance under intra-class variation and image perturbations
In the task of object class categorization, the ability of detecting similar regions given intra-class variation and image perturbations across object instance is very critical. Repeatability measures over intra-class variation and image perturbations is proposed. The following subsection will introduce the definition and discuss the performance.Intra-class variation test
Suppose there are a set of images of the same object class e.g., motorbikes. A region detection operator which is unaffected by intra-class variation will reliably select regions on corresponding parts of all the objects — say the wheels, engine or seat for motorbikes.Repeatability over intra-class variation is measuring the (average) number of correct correspondences over the set of images, where the correct correspondences is established by manual selection.
A region is matched if it fulfills three requirements:
- Its position matches within 10 pixels.
- Its scale is within 20%.
- Normalized mutual informationMutual informationIn probability theory and information theory, the mutual information of two random variables is a quantity that measures the mutual dependence of the two random variables...
between the appearances is > 0.4.
In detail the average correspondence score S is measured as follows.
N regions are detected on each image of the M images in the dataset. Then for a particular reference image, i , the correspondence score
is given by the proportion of corresponding to detected regions for all the other images in the dataset, i.e.:The score
is computed for M/2 different selections of the reference image and averaged to give S. The score is evaluated as a function of the number of detected regions N.The Kadir–Brady saliency detector gives the highest score across three test classes which are motorbike, car and face.
The saliency detector indicates that most detections are near the object. In contrast, other detectors maps show a much more diffuse pattern over the entire area caused by poor localization and false responses to background clutter.
Image perturbations test
In order to test insensitivity to image perturbation the data setData set
A data set is a collection of data, usually presented in tabular form. Each column represents a particular variable. Each row corresponds to a given member of the data set in question. Its values for each of the variables, such as height and weight of an object or values of random numbers. Each...
is split into two parts: the first contains images with a uniform background and the second images with varying degrees of background clutter. If the detector is robust to background clutter then the average correspondence score S should be similar for both subsets of images.
In this test saliency detector also outperforms other detectors due to three reasons:
- Several detection methods blur the image, hence causing a greater degree of similarity between objects and background.
- In most images the objects of interest tend to be in focus while backgrounds are out of focus and hence blurred. Blurred regions tend to exhibit slowly varying statistics which result in a relatively low entropy and inter-scale saliency in the saliency detector.
- Other detectors define saliency with respect to specific propertiesSpecific propertiesSpecific properties of a substance are derived from other intrinsic and extrinsic properties of that substance. For example, the density of steel can be derived from measurements of the mass of a steel bar divided by the volume of the bar...
of the local surface geometry. In contrast the saliency detector uses a much broader definition.
The saliency detector is most useful in the task of object recognition, whereas several other detectors are more useful in the task of computing image correspondences. However, in the task of 3D object recognition where all three types of image change are combined, saliency detector might still be powerful.
Software implementation
- Scale Saliency and Scale Descriptors by Timor Kadir
- Affine Invariant Scale Saliency by Timor Kadir
- Comparison of Affine Region Detectors
Further reading
(scale-adaptive and scale invariantScale invariance
In physics and mathematics, scale invariance is a feature of objects or laws that do not change if scales of length, energy, or other variables, are multiplied by a common factor...
interest points from Laplacian and determinant of Hessian blob detection
Blob detection
In the area of computer vision, blob detection refers to visual modules that are aimed at detecting points and/or regions in the image that differ in properties like brightness or color compared to the surrounding...
as well as more general mechanisms for automatic scale selection) (summary and review of a number of feature detectors formulated; based on a scale-space
Scale space
Scale-space theory is a framework for multi-scale signal representation developed by the computer vision, image processing and signal processing communities with complementary motivations from physics and biological vision...
representation) (theory for affine invariant interest points and shape descriptors from second-moment matrices)