
Transport Triggered Architectures
Encyclopedia
In computer architecture
, a transport triggered architecture (TTA) is a kind of CPU
design in which programs directly control the internal transport buses of a processor. Computation happens as a side effect of data transports: writing data into a triggering port of a functional unit triggers the functional unit to start computation. This is similar to what happens in a systolic array
. Due to its modular structure, TTA is an ideal processor template for application-specific instruction-set processor
s (ASIP) with customized datapath but without the inflexibility and design cost of fixed function hardware accelerators.
Typically a transport triggered processor has multiple transport buses and multiple functional units connected to the buses, which provides opportunities for instruction level parallelism
. The parallelism is statically defined by the programmer. In this respect (and obviously due to the large instruction word width), the TTA architecture resembles the Very Long Instruction Word
(VLIW) architecture. A TTA instruction word is composed of multiple slots, one slot per bus, and each slot determines the data transport that takes place on the corresponding bus. The fine-grained control allows some optimizations that are not possible in a conventional processor. For example, software can transfer data directly between functional units without using registers.
Transport triggering exposes some microarchitectural details that are normally hidden from programmers. This greatly simplifies the control logic of a processor, because many decisions normally done at run time are fixed at compile time
. However, it also means that a binary compiled for one TTA processor will not run on another one without recompilation if there is even a small difference in the architecture between the two. The binary incompatibility problem, in addition to the complexity of implementing a full context switch, makes TTAs more suitable for embedded system
s than for general purpose computing.
Of all the one instruction set computer
architectures, the TTA architecture is one of the few that has had CPUs based on it built, and the only one that has CPUs based on it sold commercially.
low level programming model enables several benefits in comparison to the standard VLIW. For example, a TTA architecture can provide more parallelism with simpler register files than with VLIW. As the programmer is in control of the timing of the operand and result data transports, the complexity (the number of input and output ports) of the register file (RF) need not be scaled according to the worst case issue/completion scenario of the multiple parallel instructions.
An important unique software optimization enabled by the transport programming is called software bypassing. In case of software bypassing, the programmer bypasses the register file write back by moving data directly to the next functional unit's operand ports. When this optimization is applied aggressively, the original move that transports the result to the register file can be eliminated completely, thus reducing both the register file port pressure and freeing a general purpose register for other temporary variables. The reduced RF pressure, in addition simplifying the required complexity of the RF hardware, can lead to significant energy savings, an important benefit especially in mobile embedded systems.
s, which are connected with transport buses and sockets.
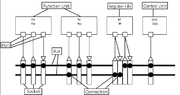
, which implement functionality ranging from a simple addition of integers to a complex and arbitrary user-defined application-specific computation. Operands for operations are transferred through function unit ports.
Each function unit may have an independent pipeline. In case a function unit is fully pipelined
, a new operation that takes multiple clock cycles to finish can be started in every clock cycle. On the other hand, a pipeline can be such that it does not always accept new operation start requests while an old one is still executing.
Data memory
access and communication to outside of the processor is handled by using special function units. Function units that implement memory accessing operations and connect to a memory module are often called load/store units.
of programs. Control unit has access to the instruction memory in order to fetch the instructions to be executed. In order to allow the executed programs to transfer the execution (jump) to an arbitrary position in the executed program, control unit provides control flow operations. A control unit usually has an instruction pipeline
, which consists of stages for fetching, decoding and executing program instructions.
which are connected to function unit ports by means of sockets. Due to expense of connectivity, it is usual to reduce the number of connections between units (function units and register files). A TTA is said to be fully connected in case there is a path from each unit output port to every unit's input ports.
Sockets provide means for programming TTA processors by allowing to select which bus-to-port connections of the socket are enabled at any time instant. Thus, data transports taking place in a clock cycle can be programmed by defining the source and destination socket/port connection to be enabled for each bus.
Conditional execution is implemented with the aid of guards. Each data transport can be conditionalized by a guard, which is connected to a register (often a 1-bit conditional register) and to a bus. In case the value of the guarded register evaluates to false (zero), the data transport programmed for the bus the guard is connected to is squashed, that is, not written to its destination. Unconditional data transports are not connected to any guard and are always executed.
This example operation adds the values of general-purpose registers r1 and r2 and stores the result in
register r3. Coarsely, the execution of the instruction in the processor probably results in translating the instruction to control signals which control the interconnection network connections and function units. The interconnection network is used to transfer the current values of registers r1 and r2 to the function unit that is capable of executing the add operation, often called ALU as in Arithmetic-Logic Unit. Finally, a control signal selects and triggers the addition operation in ALU, of which result is transferred back to the register r3.
TTA programs do not define the operations, but only the data transports needed to write and read the operand values. Operation itself is triggered by writing data to a triggering operand of an operation. Thus, an operation is executed as a side effect of the triggering data transport. Therefore, executing an addition operation in TTA requires three data transport definitions, also called moves. A move defines endpoints for a data transport taking place in a transport bus. For instance, a move can state that
a data transport from function unit F, port 1, to register file R, register index 2, should take place in bus B1. In case there
are multiple buses in the target processor, each bus can be utilized in parallel in the same clock cycle. Thus, it is possible to
exploit data transport level level parallelism by scheduling several data transports in the same instruction.
An addition operation can be executed in a TTA processor as follows:
The second move, a write to the second operand of the function unit called ALU, triggers the addition operation, which makes
result of addition available in the output port 'result' after the execution latency of the 'add'.
Reading a result too early results in reading the result of a previously triggered operation, or in case
no operation was triggered previously in the function unit, the read value is undefined. On the other hand,
result must be read early enough to make sure the next operation result does not overwrite the yet unread
result in the output port.
Due to the abundance of programmer-visible processor context which practically includes, in addition to
register file contents, also function unit pipeline register contents and/or function unit
input and output ports, context saves required for external interrupt support can become complex and expensive
to implement in a TTA processor. Therefore, interrupts are usually not supported by TTA processors, but their
task is delegated to an external hardware (e.g., an I/O processor) or their need is avoided by using
an alternative synchronization/communication mechanism such as polling.
Computer architecture
In computer science and engineering, computer architecture is the practical art of selecting and interconnecting hardware components to create computers that meet functional, performance and cost goals and the formal modelling of those systems....
, a transport triggered architecture (TTA) is a kind of CPU
Central processing unit
The central processing unit is the portion of a computer system that carries out the instructions of a computer program, to perform the basic arithmetical, logical, and input/output operations of the system. The CPU plays a role somewhat analogous to the brain in the computer. The term has been in...
design in which programs directly control the internal transport buses of a processor. Computation happens as a side effect of data transports: writing data into a triggering port of a functional unit triggers the functional unit to start computation. This is similar to what happens in a systolic array
Systolic array
In computer architecture, a systolic array is a pipe network arrangement of processing units called cells. It is a specialized form of parallel computing, where cells , compute data and store it independently of each other.thumb|240px...
. Due to its modular structure, TTA is an ideal processor template for application-specific instruction-set processor
Application-specific instruction-set processor
An application-specific instruction-set processor is a component used in system-on-a-chip design. The instruction set of an ASIP is tailored to benefit a specific application. This specialization of the core provides a tradeoff between the flexibility of a general purpose CPU and the performance...
s (ASIP) with customized datapath but without the inflexibility and design cost of fixed function hardware accelerators.
Typically a transport triggered processor has multiple transport buses and multiple functional units connected to the buses, which provides opportunities for instruction level parallelism
Instruction level parallelism
Instruction-level parallelism is a measure of how many of the operations in a computer program can be performed simultaneously. Consider the following program: 1. e = a + b 2. f = c + d 3. g = e * f...
. The parallelism is statically defined by the programmer. In this respect (and obviously due to the large instruction word width), the TTA architecture resembles the Very Long Instruction Word
Very long instruction word
Very long instruction word or VLIW refers to a CPU architecture designed to take advantage of instruction level parallelism . A processor that executes every instruction one after the other may use processor resources inefficiently, potentially leading to poor performance...
(VLIW) architecture. A TTA instruction word is composed of multiple slots, one slot per bus, and each slot determines the data transport that takes place on the corresponding bus. The fine-grained control allows some optimizations that are not possible in a conventional processor. For example, software can transfer data directly between functional units without using registers.
Transport triggering exposes some microarchitectural details that are normally hidden from programmers. This greatly simplifies the control logic of a processor, because many decisions normally done at run time are fixed at compile time
Compile time
In computer science, compile time refers to either the operations performed by a compiler , programming language requirements that must be met by source code for it to be successfully compiled , or properties of the program that can be reasoned about at compile time.The operations performed at...
. However, it also means that a binary compiled for one TTA processor will not run on another one without recompilation if there is even a small difference in the architecture between the two. The binary incompatibility problem, in addition to the complexity of implementing a full context switch, makes TTAs more suitable for embedded system
Embedded system
An embedded system is a computer system designed for specific control functions within a larger system. often with real-time computing constraints. It is embedded as part of a complete device often including hardware and mechanical parts. By contrast, a general-purpose computer, such as a personal...
s than for general purpose computing.
Of all the one instruction set computer
One instruction set computer
A one instruction set computer , sometimes called an ultimate reduced instruction set computer , is an abstract machine that uses only one instruction – obviating the need for a machine language opcode...
architectures, the TTA architecture is one of the few that has had CPUs based on it built, and the only one that has CPUs based on it sold commercially.
Benefits in Comparison to VLIW Architectures
TTAs can be seen as "exposed datapath" VLIW architectures. While VLIW is programmed using operations, TTA splits the operation execution to multiple move operations. Thelow level programming model enables several benefits in comparison to the standard VLIW. For example, a TTA architecture can provide more parallelism with simpler register files than with VLIW. As the programmer is in control of the timing of the operand and result data transports, the complexity (the number of input and output ports) of the register file (RF) need not be scaled according to the worst case issue/completion scenario of the multiple parallel instructions.
An important unique software optimization enabled by the transport programming is called software bypassing. In case of software bypassing, the programmer bypasses the register file write back by moving data directly to the next functional unit's operand ports. When this optimization is applied aggressively, the original move that transports the result to the register file can be eliminated completely, thus reducing both the register file port pressure and freeing a general purpose register for other temporary variables. The reduced RF pressure, in addition simplifying the required complexity of the RF hardware, can lead to significant energy savings, an important benefit especially in mobile embedded systems.
Structure
TTA processors are built of independent function units and register fileRegister file
A register file is an array of processor registers in a central processing unit . Modern integrated circuit-based register files are usually implemented by way of fast static RAMs with multiple ports...
s, which are connected with transport buses and sockets.
Function unit
Each function unit implements one or more operationsOperator (programming)
Programming languages typically support a set of operators: operations which differ from the language's functions in calling syntax and/or argument passing mode. Common examples that differ by syntax are mathematical arithmetic operations, e.g...
, which implement functionality ranging from a simple addition of integers to a complex and arbitrary user-defined application-specific computation. Operands for operations are transferred through function unit ports.
Each function unit may have an independent pipeline. In case a function unit is fully pipelined
Instruction pipeline
An instruction pipeline is a technique used in the design of computers and other digital electronic devices to increase their instruction throughput ....
, a new operation that takes multiple clock cycles to finish can be started in every clock cycle. On the other hand, a pipeline can be such that it does not always accept new operation start requests while an old one is still executing.
Data memory
Computer memory
In computing, memory refers to the physical devices used to store programs or data on a temporary or permanent basis for use in a computer or other digital electronic device. The term primary memory is used for the information in physical systems which are fast In computing, memory refers to the...
access and communication to outside of the processor is handled by using special function units. Function units that implement memory accessing operations and connect to a memory module are often called load/store units.
Control unit
Control unit is a special case of function units which controls executionof programs. Control unit has access to the instruction memory in order to fetch the instructions to be executed. In order to allow the executed programs to transfer the execution (jump) to an arbitrary position in the executed program, control unit provides control flow operations. A control unit usually has an instruction pipeline
Instruction pipeline
An instruction pipeline is a technique used in the design of computers and other digital electronic devices to increase their instruction throughput ....
, which consists of stages for fetching, decoding and executing program instructions.
Register files
Register files contain general purpose registers, which are used to store variables in programs. Like function units, also register files have input and output ports. The number of read and write ports, that is, the capability of being able to read and write multiple registers in a same clock cycle, can vary in each register file.Transport buses and sockets
Interconnect architecture consists of transport busesComputer bus
In computer architecture, a bus is a subsystem that transfers data between components inside a computer, or between computers.Early computer buses were literally parallel electrical wires with multiple connections, but the term is now used for any physical arrangement that provides the same...
which are connected to function unit ports by means of sockets. Due to expense of connectivity, it is usual to reduce the number of connections between units (function units and register files). A TTA is said to be fully connected in case there is a path from each unit output port to every unit's input ports.
Sockets provide means for programming TTA processors by allowing to select which bus-to-port connections of the socket are enabled at any time instant. Thus, data transports taking place in a clock cycle can be programmed by defining the source and destination socket/port connection to be enabled for each bus.
Conditional execution is implemented with the aid of guards. Each data transport can be conditionalized by a guard, which is connected to a register (often a 1-bit conditional register) and to a bus. In case the value of the guarded register evaluates to false (zero), the data transport programmed for the bus the guard is connected to is squashed, that is, not written to its destination. Unconditional data transports are not connected to any guard and are always executed.
Programming
In more traditional processor architectures, a processor is usually programmed by defining the executed operations and their operands. For example, an addition instruction in a RISC architecture could look like the following.
add r3, r1, r2
This example operation adds the values of general-purpose registers r1 and r2 and stores the result in
register r3. Coarsely, the execution of the instruction in the processor probably results in translating the instruction to control signals which control the interconnection network connections and function units. The interconnection network is used to transfer the current values of registers r1 and r2 to the function unit that is capable of executing the add operation, often called ALU as in Arithmetic-Logic Unit. Finally, a control signal selects and triggers the addition operation in ALU, of which result is transferred back to the register r3.
TTA programs do not define the operations, but only the data transports needed to write and read the operand values. Operation itself is triggered by writing data to a triggering operand of an operation. Thus, an operation is executed as a side effect of the triggering data transport. Therefore, executing an addition operation in TTA requires three data transport definitions, also called moves. A move defines endpoints for a data transport taking place in a transport bus. For instance, a move can state that
a data transport from function unit F, port 1, to register file R, register index 2, should take place in bus B1. In case there
are multiple buses in the target processor, each bus can be utilized in parallel in the same clock cycle. Thus, it is possible to
exploit data transport level level parallelism by scheduling several data transports in the same instruction.
An addition operation can be executed in a TTA processor as follows:
r1 -> ALU.operand1
r2 -> ALU.add.trigger
ALU.result -> r3
The second move, a write to the second operand of the function unit called ALU, triggers the addition operation, which makes
result of addition available in the output port 'result' after the execution latency of the 'add'.
Programmer visible operation latency
The leading philosophy of TTAs is to move complexity from hardware to software. Due to this, several additional hazards are introduced to the programmer. One of them is the programmer visible operation latency of the function units. Timing is completely a responsibility of programmer. The programmer has to schedule the instructions such that the result is neither read too early nor too late. There is no hardware detection to lock up the processor in case a result is read too early. Consider, for example, an architecture that has an operation add with latency of 1, and operation mul with latency of 3. When triggering the add operation, it is possible to read the result in the next instruction (next clock cycle), but in case of mul, one has to wait for two instructions before the result can be read. The result is ready for the 3rd instruction after the triggering instruction.Reading a result too early results in reading the result of a previously triggered operation, or in case
no operation was triggered previously in the function unit, the read value is undefined. On the other hand,
result must be read early enough to make sure the next operation result does not overwrite the yet unread
result in the output port.
Due to the abundance of programmer-visible processor context which practically includes, in addition to
register file contents, also function unit pipeline register contents and/or function unit
input and output ports, context saves required for external interrupt support can become complex and expensive
to implement in a TTA processor. Therefore, interrupts are usually not supported by TTA processors, but their
task is delegated to an external hardware (e.g., an I/O processor) or their need is avoided by using
an alternative synchronization/communication mechanism such as polling.
Implementations
- MAXQ
- Currently, the only commercially available microcontroller built upon (though not "featuring") Transport Triggered Architecture is from Dallas SemiconductorDallas SemiconductorDallas Semiconductor, now a subsidiary of Maxim Integrated Products, designs and manufactures analog, digital, and mixed-signal semiconductors...
. However, it is an OISC or "one instruction set computerOne instruction set computerA one instruction set computer , sometimes called an ultimate reduced instruction set computer , is an abstract machine that uses only one instruction – obviating the need for a machine language opcode...
", offering but a single though flexible MOVE instruction, which can then function as various virtual instructions by moving values directly to the program counterProgram counterThe program counter , commonly called the instruction pointer in Intel x86 microprocessors, and sometimes called the instruction address register, or just part of the instruction sequencer in some computers, is a processor register that indicates where the computer is in its instruction sequence...
.
- The "move project" has designed and fabricated several experimental TTA microprocessors.
- The TCE project is a re-implementation of the MOVE tools. The tools are available as open source, and the compiler is built around the LLVM compiler framework.
- The architecture of the Amiga Copper has all the basic features of a transport triggered architecture.
- The Able processor developed by New England Digital.
- The WireWorld based computer.
- Dr. Dobb's published One-Der a 32-bit TTA in Verilog with a matching cross assembler and Forth compiler.
See also
- Application-specific instruction-set processorApplication-specific instruction-set processorAn application-specific instruction-set processor is a component used in system-on-a-chip design. The instruction set of an ASIP is tailored to benefit a specific application. This specialization of the core provides a tradeoff between the flexibility of a general purpose CPU and the performance...
(ASIP) - Very long instruction wordVery long instruction wordVery long instruction word or VLIW refers to a CPU architecture designed to take advantage of instruction level parallelism . A processor that executes every instruction one after the other may use processor resources inefficiently, potentially leading to poor performance...
(VLIW) - Explicitly parallel instruction computingExplicitly Parallel Instruction ComputingExplicitly parallel instruction computing is a term coined in 1997 by the HP–Intel alliance to describe a computing paradigm that researchers had been investigating since the early 1980s. This paradigm is also called Independence architectures...
(EPIC) - Dataflow architectureDataflow architectureDataflow architecture is a computer architecture that directly contrasts the traditional von Neumann architecture or control flow architecture. Dataflow architectures do not have a program counter, or the executability and execution of instructions is solely determined based on the availability of...
External links
- MOVE project: Automatic Synthesis of Application Specific Processors
- Microprocessor Architectures from VLIW to TTA
- TTA Codesign Environment, an open source (MIT licensed) toolset for design of application specific TTA processors.
- BYTE overview article
- Dr. Dobb's article with 32-bit FPGA CPU in Verilog
- Web site with more details on the Dr. Dobb's CPU
- Article about TTAs, explaining how the TTA-based Codesign Environment project uses LLVMLow Level Virtual MachineThe Low Level Virtual Machine is a compiler infrastructure written in C++ that is designed for compile-time, link-time, run-time, and "idle-time" optimization of programs written in arbitrary programming languages...
- Introduction to the MAXQ Architecture – Includes transfer map diagram