

Trip distribution
Encyclopedia
Trip distribution is the second component (after trip generation
, but before mode choice
and route assignment
) in the traditional four-step transportation forecasting
model. This step matches tripmakers’ origins and destinations to develop a “trip table” a matrix that displays the number of trips going from each origin to each destination. Historically, this component has been the least developed component of the transportation planning model.
Where: T ij = trips from origin i to destination j. Note that the practical value of trips on the diagonal, e.g. from zone 1 to zone 1, is zero since no inter-zonal trip occurs.
Work trip distribution is the way that travel demand models understand how people take jobs. There are trip distribution models for other (non-work) activities, which follow the same structure.
The next models developed were the gravity model and the intervening opportunities model. The most widely used formulation is still the gravity model.
While studying traffic in Baltimore, Maryland, Alan Voorhees
developed a mathematical formula to predict traffic patterns based on land use. This formula has been instrumental in the design of numerous transportation and public works projects around the world. He wrote "A General Theory of Traffic Movement," (Voorhees, 1956) which applied the gravity model to trip distribution, which translates trips generated
in an area to a matrix that identifies the number of trips from each origin to each destination, which can then be loaded onto the network.
Evaluation of several model forms in the 1960s concluded that "the gravity model and intervening opportunity model proved of about equal reliability and utility in simulating the 1948 and 1955 trip distribution for Washington, D.C." (Heanue and Pyers 1966). The Fratar model was shown to have weakness in areas experiencing land use changes. As comparisons between the models showed that either could be calibrated equally well to match observed conditions, because of computational ease, gravity models became more widely spread than intervening opportunities models. Some theoretical problems with the intervening opportunities model were discussed by Whitaker and West (1968) concerning its inability to account for all trips generated in a zone which makes it more difficult to calibrate, although techniques for dealing with the limitations have been developed by Ruiter (1967).
With the development of logit and other discrete choice techniques, new, demographically disaggregate approaches to travel demand were attempted. By including variables other than travel time in determining the probability of making a trip, it is expected to have a better prediction of travel behavior. The logit model
and gravity model have been shown by Wilson (1967) to be of essentially the same form as used in statistical mechanics, the entropy maximization model. The application of these models differs in concept in that the gravity model uses impedance by travel time, perhaps stratified by socioeconomic variables, in determining the probability of trip making, while a discrete choice approach brings those variables inside the utility or impedance function. Discrete choice models require more information to estimate and more computational time.
Ben-Akiva and Lerman (1985) have developed combination destination choice and mode choice models using a logit formulation for work and non-work trips. Because of computational intensity, these formulations tended to aggregate traffic zones into larger districts or rings in estimation. In current application, some models, including for instance the transportation planning model used in Portland, Oregon, use a logit formulation for destination choice. Allen (1984) used utilities from a logit based mode choice model in determining composite impedance for trip distribution. However, that approach, using mode choice log-sums implies that destination choice depends on the same variables as mode choice. Levinson and Kumar (1995) employ mode choice probabilities as a weighting factor and develop a specific impedance function or “f-curve” for each mode for work and non-work trip purposes.
Each cell in our table is to contain the number of trips from zone i to zone j. We do not have these within cell numbers yet, although we have the row and column totals. With data organized this way, our task is to fill in the cells for tables headed t = 1 through say t = n.
Actually, from home interview travel survey data and attraction analysis we have the cell information for t = 1. The data are a sample, so we generalize the sample to the universe. The techniques used for zonal interchange analysis explore the empirical rule that fits the t = 1 data. That rule is then used to generate cell data for t = 2, t = 3, t = 4, etc., to t = n.
The first technique developed to model zonal interchange involves a model such as this:
Trip generation
Trip generation is the first step in the conventional four-step transportation forecasting process , widely used for forecasting travel demands...
, but before mode choice
Mode choice
Mode choice analysis is the third step in the conventional four-step transportation forecasting model, following trip generation and trip distribution but before route assignment. Trip distribution's zonal interchange analysis yields a set of origin destination tables which tells where the trips...
and route assignment
Route assignment
Route assignment, route choice, or traffic assignment concerns the selection of routes between origins and destinations in transportation networks. It is the fourth step in the conventional transportation forecasting model, following trip generation, trip distribution, and mode choice...
) in the traditional four-step transportation forecasting
Transportation forecasting
Transportation forecasting is the process of estimating the number of vehicles or people that will use a specific transportation facility in the future. For instance, a forecast may estimate the number of vehicles on a planned road or bridge, the ridership on a railway line, the number of...
model. This step matches tripmakers’ origins and destinations to develop a “trip table” a matrix that displays the number of trips going from each origin to each destination. Historically, this component has been the least developed component of the transportation planning model.
| Origin \ Destination | 1 | 2 | 3 | Z |
|---|---|---|---|---|
| 1 | T11 | T12 | T13 | T1Z |
| 2 | T21 | |||
| 3 | T31 | |||
| Z | TZ1 | TZZ | ||
Where: T ij = trips from origin i to destination j. Note that the practical value of trips on the diagonal, e.g. from zone 1 to zone 1, is zero since no inter-zonal trip occurs.
Work trip distribution is the way that travel demand models understand how people take jobs. There are trip distribution models for other (non-work) activities, which follow the same structure.
History
Over the years, modelers have used several different formulations of trip distribution. The first was the Fratar or Growth model (which did not differentiate trips by purpose). This structure extrapolated a base year trip table to the future based on growth, but took no account of changing spatial accessibility due to increased supply or changes in travel patterns and congestion. (Simple Growth factor model, Furness Model and Detroit model are models developed at the same time period)The next models developed were the gravity model and the intervening opportunities model. The most widely used formulation is still the gravity model.
While studying traffic in Baltimore, Maryland, Alan Voorhees
Alan Voorhees
Alan Manners Voorhees was a transportation engineer and urban planner who designed many large public works in the United States...
developed a mathematical formula to predict traffic patterns based on land use. This formula has been instrumental in the design of numerous transportation and public works projects around the world. He wrote "A General Theory of Traffic Movement," (Voorhees, 1956) which applied the gravity model to trip distribution, which translates trips generated
Trip generation
Trip generation is the first step in the conventional four-step transportation forecasting process , widely used for forecasting travel demands...
in an area to a matrix that identifies the number of trips from each origin to each destination, which can then be loaded onto the network.
Evaluation of several model forms in the 1960s concluded that "the gravity model and intervening opportunity model proved of about equal reliability and utility in simulating the 1948 and 1955 trip distribution for Washington, D.C." (Heanue and Pyers 1966). The Fratar model was shown to have weakness in areas experiencing land use changes. As comparisons between the models showed that either could be calibrated equally well to match observed conditions, because of computational ease, gravity models became more widely spread than intervening opportunities models. Some theoretical problems with the intervening opportunities model were discussed by Whitaker and West (1968) concerning its inability to account for all trips generated in a zone which makes it more difficult to calibrate, although techniques for dealing with the limitations have been developed by Ruiter (1967).
With the development of logit and other discrete choice techniques, new, demographically disaggregate approaches to travel demand were attempted. By including variables other than travel time in determining the probability of making a trip, it is expected to have a better prediction of travel behavior. The logit model
Logistic regression
In statistics, logistic regression is used for prediction of the probability of occurrence of an event by fitting data to a logit function logistic curve. It is a generalized linear model used for binomial regression...
and gravity model have been shown by Wilson (1967) to be of essentially the same form as used in statistical mechanics, the entropy maximization model. The application of these models differs in concept in that the gravity model uses impedance by travel time, perhaps stratified by socioeconomic variables, in determining the probability of trip making, while a discrete choice approach brings those variables inside the utility or impedance function. Discrete choice models require more information to estimate and more computational time.
Ben-Akiva and Lerman (1985) have developed combination destination choice and mode choice models using a logit formulation for work and non-work trips. Because of computational intensity, these formulations tended to aggregate traffic zones into larger districts or rings in estimation. In current application, some models, including for instance the transportation planning model used in Portland, Oregon, use a logit formulation for destination choice. Allen (1984) used utilities from a logit based mode choice model in determining composite impedance for trip distribution. However, that approach, using mode choice log-sums implies that destination choice depends on the same variables as mode choice. Levinson and Kumar (1995) employ mode choice probabilities as a weighting factor and develop a specific impedance function or “f-curve” for each mode for work and non-work trip purposes.
Mathematics
At this point in the transportation planning process, the information for zonal interchange analysis is organized in an origin-destination table. On the left is listed trips produced in each zone. Along the top are listed the zones, and for each zone we list its attraction. The table is n x n, where n = the number of zones.Each cell in our table is to contain the number of trips from zone i to zone j. We do not have these within cell numbers yet, although we have the row and column totals. With data organized this way, our task is to fill in the cells for tables headed t = 1 through say t = n.
Actually, from home interview travel survey data and attraction analysis we have the cell information for t = 1. The data are a sample, so we generalize the sample to the universe. The techniques used for zonal interchange analysis explore the empirical rule that fits the t = 1 data. That rule is then used to generate cell data for t = 2, t = 3, t = 4, etc., to t = n.
The first technique developed to model zonal interchange involves a model such as this:
-
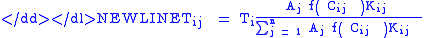
where:-
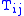 : trips from i to j.
: trips from i to j. -
 : trips from i, as per our generation analysis
: trips from i, as per our generation analysis -
 : trips attracted to j, as per our generation analysis
: trips attracted to j, as per our generation analysis -
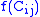 : travel cost friction factor, say =
: travel cost friction factor, say = 
-
 : Calibration parameter
: Calibration parameter
Zone i generates T i trips; how many will go to zone j? That depends on the attractiveness of j compared to the attractiveness of all places; attractiveness is tempered by the distance a zone is from zone i. We compute the fraction comparing j to all places and multiply T ;i by it.
The rule is often of a gravity form:
-

where:-
 : populations of i and j
: populations of i and j -
 : parameters
: parameters
But in the zonal interchange mode, we use numbers related to trip origins (T ;i) and trip destinations (T ;j) rather than populations.
There are lots of model forms because we may use weights and special calibration parameters, e.g., one could write say:
-

or
-

where:- a, b, c, d are parameters
-
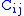 : travel cost (e.g. distance, money, time)
: travel cost (e.g. distance, money, time) -
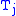 : inbound trips, destinations
: inbound trips, destinations -
 : outbound trips, origin
: outbound trips, origin
Gravity model
The gravity modelGravity modelGravity models are used in various social sciences to predict and describe certain behaviors that mimic gravitational interaction as described in Isaac Newton's law of gravity...
illustrates the macroscopic relationships between places (say homes and workplaces). It has long been posited that the interaction between two locations declines with increasing (distance, time, and cost) between them, but is positively associated with the amount of activity at each location (Isard, 1956). In analogy with physics, Reilly (1929) formulated Reilly's law of retail gravitationReilly's law of retail gravitationIn economics, Reilly's law of retail gravitation states that larger cities will have larger spheres of influence than smaller ones, meaning people travel farther to reach a larger city....
, and J. Q. Stewart (1948) formulated definitions of demographic gravitationDemographic GravitationDemographic gravitation is a concept of "social physics", introduced by Princeton University astrophysicist John Quincy Stewart in 1947. It is an attempt to use equations and notions of classical physics - such as gravity - to seek simplified insights and even laws of demographic behaviour for...
, force, energy, and potential, now called accessibility (Hansen, 1959). The distance decayDistance decayDistance decay is a geographical term which describes the effect of distance on cultural or spatial interactions. The distance decay effect states that the interaction between two locales declines as the distance between them increases...
factor of 1/distance has been updated to a more comprehensive function of generalized cost, which is not necessarily linear - a negative exponential tends to be the preferred form. In analogy with Newton’s law of gravity, a gravity model is often used in transportation planning.
The gravity model has been corroborated many times as a basic underlying aggregate relationship (Scott 1988, Cervero 1989, Levinson and Kumar 1995). The rate of decline of the interaction (called alternatively, the impedance or friction factor, or the utility or propensity function) has to be empirically measured, and varies by context.
Limiting the usefulness of the gravity model is its aggregate nature. Though policy also operates at an aggregate level, more accurate analyses will retain the most detailed level of information as long as possible. While the gravity model is very successful in explaining the choice of a large number of individuals, the choice of any given individual varies greatly from the predicted value. As applied in an urban travel demand context, the disutilities are primarily time, distance, and cost, although discrete choice models with the application of more expansive utility expressions are sometimes used, as is stratification by income or vehicle ownership.
Mathematically, the gravity model often takes the form:
-
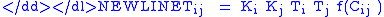
-
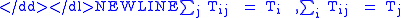
-

where-
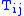 = Trips between origin i and destination j
= Trips between origin i and destination j -
 = Trips originating at i
= Trips originating at i -
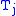 = Trips destined for j
= Trips destined for j -
 = travel cost between i and j
= travel cost between i and j -
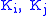 = balancing factors solved iteratively. See Iterative proportional fittingIterative proportional fittingThe iterative proportional fitting procedure is an iterative algorithm for estimating cell values of a contingency table such that the marginal totals remain fixed and the estimated table decomposes into an outer...
= balancing factors solved iteratively. See Iterative proportional fittingIterative proportional fittingThe iterative proportional fitting procedure is an iterative algorithm for estimating cell values of a contingency table such that the marginal totals remain fixed and the estimated table decomposes into an outer...
. -
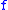 = distance decay factor, as in the accessibility model
= distance decay factor, as in the accessibility model
It is doubly constrained so that Trips from i to j equal number of origins and destinations:
Entropy analysis
Wilson (1970) gives us another way to think about zonal interchange problem. This section treats Wilson’s methodology to give a grasp of central ideas.
To start, consider some trips where we have seven people in origin zones commuting to seven jobs in destination zones. One configuration of such trips will be:
Table: Configuration of trips zone 1 2 3 1 2 1 1 2 0 2 1
-
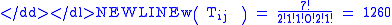
where 0! = 1.
That configuration can appear in 1,260 ways. We have calculated the number of ways that configuration of trips might have occurred, and to explain the calculation, let’s recall those coin tossing experiments talked about so much in elementary statistics.
The number of ways a two-sided coin can come up is 2n, where n is the number of times we toss the coin. If we toss the coin once, it can come up heads or tails, 21 = 2. If we toss it twice, it can come up HH, HT, TH, or TT, 4 ways, and 2 = 4. To ask the specific question about, say, four coins coming up all heads, we calculate 4!/4!0! =1 . Two heads and two tails would be 4!/(2!2!) = 6. We are solving the equation:
-

An important point is that as n gets larger, our distribution gets more and more peaked, and it is more and more reasonable to think of a most likely state.
However, the notion of most likely state comes not from this thinking; it comes from statistical mechanics, a field well known to Wilson and not so well known to transportation planners. The result from statistical mechanics is that a descending series is most likely. Think about the way the energy from lights in the classroom is affecting the air in the classroom. If the effect resulted in an ascending series, many of the atoms and molecules would be affected a lot and a few would be affected a little. The descending series would have a lot affected not at all or not much and only a few affected very much. We could take a given level of energy and compute excitation levels in ascending and descending series. Using the formula above, we would compute the ways particular series could occur, and we would concluded that descending series dominate.
That is more-or-less Boltzmann's Law,
-

That is, the particles at any particular excitation level j will be a negative exponential function of the particles in the ground state, p 0, the excitation level, e j, and a parameter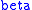 , which is a function of the (average) energy available to the particles in the system.
, which is a function of the (average) energy available to the particles in the system.
The two paragraphs above have to do with ensemble methods of calculation developed by Gibbs, a topic well beyond the reach of these notes.
Returning to our O-D matrix, note that we have not used as much information as we would have from an O and D survey and from our earlier work on trip generation. For the same travel pattern in the O-D matrix used before, we would have row and column totals, i.e.:Table: Illustrative O-D Matrix with row and column totals zone 1 2 3 zone Ti \Tj 2 3 2 1 4 2 1 1 2 3 0 2 1
Consider the way the four folks might travel, 4!/(2!1!1!) = 12; consider three folks, 3!/(0!2!1!) = 3. All travel can be combined in 12*3 = 36 ways. The possible configuration of trips is, thus, seen to be much constrained by the column and row totals.
We put this point together with the earlier work with our matrix and the notion of most likely state to say that we want to
-
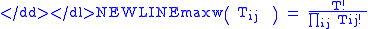
subject to
-
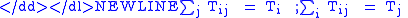
where:
-

and this is the problem that we have solved above.
Wilson adds another consideration; he constrains the system to the amount of energy available (i.e., money), and we have the additional constraint,
-

where C is the quantity of resources available and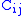 is the travel cost from i to j.
is the travel cost from i to j.
The discussion thus far contains the central ideas in Wilson’s work, but we are not yet to the place where the reader will recognize the model as it is formulated by Wilson.
First, writing the function to be maximized using Lagrangian multipliers, we have:
-
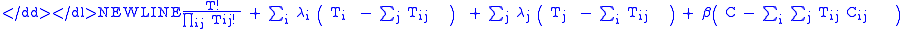
where are the Lagrange multipliers,
are the Lagrange multipliers, 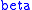 having an energy sense.
having an energy sense.
Second, it is convenient to maximize the natural log (ln) rather than w(Tij), for then we may use Stirling's approximationStirling's approximationIn mathematics, Stirling's approximation is an approximation for large factorials. It is named after James Stirling.The formula as typically used in applications is\ln n! = n\ln n - n +O\...
.
-
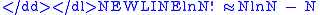
so
-

Third, evaluating the maximum, we have
-

with solution
-

-
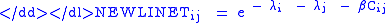
Finally, substituting this value of back into our constraint equations, we have:
back into our constraint equations, we have:
-
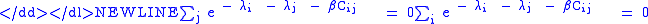
and, taking the constant multiples outside of the summation sign
-
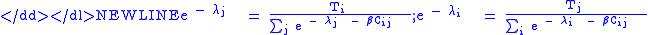
Let
-
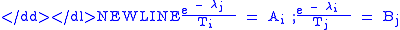
we have
-

which says that the most probable distribution of trips has a gravity model form, is proportional to trip origins and destinations. A i, B j, and
is proportional to trip origins and destinations. A i, B j, and 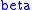 ensure constraints are met.
ensure constraints are met.
Turning now to computation, we have a large problem. First, we do not know the value of C, which earlier on we said had to do with the money available, it was a cost constraint. Consequently, we have to set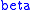 to different values and then find the best set of values for
to different values and then find the best set of values for  and
and 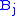 . We know what
. We know what 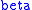 means – the greater the value of
means – the greater the value of 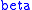 , the less the cost of average distance traveled. (Compare
, the less the cost of average distance traveled. (Compare 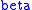 in Boltzmann's Law noted earlier.) Second, the values of
in Boltzmann's Law noted earlier.) Second, the values of 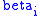 and
and 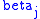 depend on each other. So for each value of
depend on each other. So for each value of 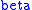 , we must use an iterative solution. There are computer programs to do this.
, we must use an iterative solution. There are computer programs to do this.
Wilson's method has been applied to the Lowry model.
Issues
One of the key drawbacks to the application of many early models was the inability to take account of congested travel time on the road network in determining the probability of making a trip between two locations. Although Wohl noted as early as 1963 research into the feedback mechanism or the “interdependencies among assigned or distributed volume, travel time (or travel ‘resistance’) and route or system capacity”, this work has yet to be widely adopted with rigorous tests of convergence, or with a so-called “equilibrium” or “combined” solution (Boyce et al. 1994). Haney (1972) suggests internal assumptions about travel time used to develop demand should be consistent with the output travel times of the route assignment of that demand. While small methodological inconsistencies are necessarily a problem for estimating base year conditions, forecasting becomes even more tenuous without an understanding of the feedback between supply and demand. Initially heuristic methods were developed by Irwin and Von Cube (as quoted in Florian et al. (1975) ) and others, and later formal mathematical programming techniques were established by Evans (1976).
A key point in analyzing feedback is the finding in earlier research by Levinson and Kumar (1994) that commuting times have remained stable over the past thirty years in the Washington Metropolitan Region, despite significant changes in household income, land use pattern, family structure, and labor force participation. Similar results have been found in the Twin Cities by Barnes and Davis (2000).
The stability of travel times and distribution curves over the past three decades gives a good basis for the application of aggregate trip distribution models for relatively long term forecasting. This is not to suggest that there exists a constant travel time budget.
External links
- Transportation Systems Analysis Model — TSAM is a nationwide transportation planning model to forecast intercity travel behavior in the United States.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-