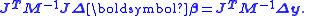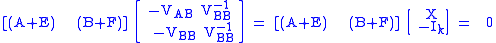Total least squares, also known as errors in variables, rigorous least squares, or (in a special case) orthogonal regression, is a least squares
Least squares
The method of least squares is a standard approach to the approximate solution of overdetermined systems, i.e., sets of equations in which there are more equations than unknowns. "Least squares" means that the overall solution minimizes the sum of the squares of the errors made in solving every...
data modeling technique in which observational errors on both dependent and independent variables are taken into account. It is a generalization of Deming regression
Deming regression
In statistics, Deming regression, named after W. Edwards Deming, is an errors-in-variables model which tries to find the line of best fit for a two-dimensional dataset...
, and can be applied to both linear and non-linear models.
The method of least squares is a standard approach to the approximate solution of overdetermined systems, i.e., sets of equations in which there are more equations than unknowns. "Least squares" means that the overall solution minimizes the sum of the squares of the errors made in solving every...
method of data modeling, the objective function, S,
is minimized, where r is the vector of residuals
Errors and residuals in statistics
In statistics and optimization, statistical errors and residuals are two closely related and easily confused measures of the deviation of a sample from its "theoretical value"...
and W is a weighting matrix. In linear least squares the model contains equations which are linear in the parameters appearing in the parameter vector , so the residuals are given by
There are m observations in y and n parameters in β with m>n. X is a m×n matrix whose elements are either constants or functions of the independent variables, x. The weight matrix, W, is, ideally, the inverse of the variance-covariance matrix, , of the observations, y. The independent variables are assumed to be error-free. The parameter estimates are found by setting the gradient equations to zero, which results in the normal equations An alternative form is , where is the parameter shift from some starting estimate of and is the difference between y and the value calculated using the starting value of
Allowing observation errors in all variables
Now, suppose that both x and y are observed subject to error, with variance-covariance matrices and respectively. In this case the objective function can be written as
where and are the residuals in x and y respectively. Clearly these residuals cannot be independent of each other, but they must be constrained by some kind of relationship. Writing the model function as , the constraints are expressed by m condition equations.
Thus, the problem is to minimize the objective function subject to the m constraints. It is solved by the use of Lagrange multipliers
Lagrange multipliers
In mathematical optimization, the method of Lagrange multipliers provides a strategy for finding the maxima and minima of a function subject to constraints.For instance , consider the optimization problem...
. After some algebraic manipulations, the result is obtained., or alternatively
Where M is the variance-covariance matrix relative to both independent and dependent variables.
Example
In practice these equations are easy to use. When the data errors are uncorrelated, all matrices M and W are diagonal. Then, take the example of straight line fitting.
It is easy to show that, in this case
showing how the variance at the ith point is determined by the variances of both independent and dependent variables and by the model being used to fit the data. The expression may be generalized by noting that the parameter is the slope of the line.
An expression of this type is used in fitting pH titration data where a small error on x translates to a large error on y when the slope is large.
Algebraic point of view
First of all it is necessary to note that the TLS problem does not have a solution in general, which was already shown in The following considers the simple case where a unique solution exists without making any particular assumptions.
In linear algebra, the singular value decomposition is a factorization of a real or complex matrix, with many useful applications in signal processing and statistics....
is described in standard texts. We can solve the equation
for X where A is m-by-n and B is m-by-k.
That is, we seek to find X that minimizes error matrices E and F for A and B respectively. That is,
where is the augmented matrix
Augmented matrix
In linear algebra, an augmented matrix is a matrix obtained by appending the columns of two given matrices, usually for the purpose of performing the same elementary row operations on each of the given matrices.Given the matrices A and B, where:A =...
with E and F side by side and is the Frobenius norm, the square root of the sum of the squares of all entries in a matrix and so equivalently the square root of the sum of squares of the lengths of the rows or columns of the matrix.
This can be rewritten as.
where is the identity matrix.
The goal is then to find that reduces the rank of by k. Define to be the singular value decomposition of the augmented matrix .
where V is partitioned into blocks corresponding to the shape of A and B.
The rank is reduced by setting some of the singular values to zero. That is, we want
so by linearity,.
We can then remove blocks from the U and Σ matrices, simplifying to.
This provides E and F so that.
Now if is nonsingular, which is not always the case (note that the behavior of TLS when is singular is not well understood yet), we can then right multiply both sides by to bring the bottom block of the right matrix to the negative identity.
GNU Octave is a high-level language, primarily intended for numerical computations. It provides a convenient command-line interface for solving linear and nonlinear problems numerically, and for performing other numerical experiments using a language that is mostly compatible with MATLAB...
implementation of this is:
function X = tls(xdata,ydata)
m = length(ydata) %number of x,y data pairs
A = [ones(m,1) xdata];
B = ydata;
n = size(A,2); % n is the width of A (A is m by n)
C = [A B]; % C is A augmented with B.
[U S V] = svd(C,0); % find the SVD of C.
VAB = V(1:n,1+n:end); % Take the block of V consisting of the first n rows and the n+1 to last column
VBB = V(1+n:end,1+n:end); % Take the bottom-right block of V.
X = -VAB/VBB;
end
The above described way of solving the problem, provided by nonsingularity of matrix , can be slightly extended by so called classical TLS algorithm.
Computation
The standard implemenation of classical TLS algorithm is available through Netlib, see also. All modern implementations based, for example, on solving a sequence of ordinary least squares problems, approximate the matrix introduced by Van Huffel and Vandewalle. It is worth noting, that this is, however, not the TLS solution in many cases.
Non-linear least squares is the form of least squares analysis which is used to fit a set of m observations with a model that is non-linear in n unknown parameters . It is used in some forms of non-linear regression. The basis of the method is to approximate the model by a linear one and to...
similar reasoning shows that the normal equations for an iteration cycle can be written as
Geometrical interpretation
When the independent variable is error-free a residual represents the "vertical" distance between the observed data point and the fitted curve (or surface). In total least squares a residual represents the distance between a data point and the fitted curve measured along some direction. In fact, if both variables are measured in the same units and the errors on both variables are the same, then the residual represents the shortest distance between the data point and the fitted curve, that is, the residual vector is perpendicular to the tangent of the curve. For this reason, this type of regression is sometimes called "two dimensional Euclidean regression" (Stein, 1983)
.
A serious difficulty arises if the variables are not measured in the same units. First consider measuring distance between a data point and the curve - what are the measurement units for this distance? If we consider measuring distance based on Pythagoras' Theorem then it is clear that we shall be adding quantities measured in different units, and so this leads to meaningless results. Secondly, if we rescale one of the variables e.g., measure in grams rather than kilograms, then we shall end up with different results (a different curve). To avoid this problem of incommensurability it is sometimes suggested that we convert to dimensionless variables—this may be called normalization or standardization. However there are various ways of doing this, and these lead to fitted models which are not equivalent to each other. One approach is to normalize by known ( or estimated ) measurement precision thereby minimizing the Mahalanobis distance
Mahalanobis distance
In statistics, Mahalanobis distance is a distance measure introduced by P. C. Mahalanobis in 1936. It is based on correlations between variables by which different patterns can be identified and analyzed. It gauges similarity of an unknown sample set to a known one. It differs from Euclidean...
from the points to the line, providing a maximum-likelihood solution.
Scale invariant methods
In short, total least squares does not have the property of units-invariance (it is not scale invariant). For a meaningful model we require this property to hold. A way forward is to realise that residuals (distances) measured in different units can be combined if multiplication is used instead of addition. Consider fitting a line: for each data point the product of the vertical and horizontal residuals equals twice the area of the triangle formed by the residual lines and the fitted line. We choose the line which minimizes the sum of these areas. Nobel laureate Paul Samuelson
Paul Samuelson
Paul Anthony Samuelson was an American economist, and the first American to win the Nobel Memorial Prize in Economic Sciences. The Swedish Royal Academies stated, when awarding the prize, that he "has done more than any other contemporary economist to raise the level of scientific analysis in...
proved that it is the only line which possesses a set of certain desirable properties which includes scale invariance and invariance under interchange of variables (Samuelson, 1942). This line has been rediscovered in different disciplines and is variously known as the reduced major axis, the geometric mean functional relationship (Draper and Smith, 1998), least products regression, diagonal regression, line of organic correlation, and the least areas line. Tofallis (2002) has extended this approach to deal with multiple variables.
In statistics, Deming regression, named after W. Edwards Deming, is an errors-in-variables model which tries to find the line of best fit for a two-dimensional dataset...
, a special case with two predictors and independent errors
Total least squares, also known as errors in variables, rigorous least squares, or orthogonal regression, is a least squares data modeling technique in which observational errors on both dependent and independent variables are taken into account...
In statistics, linear regression is an approach to modeling the relationship between a scalar variable y and one or more explanatory variables denoted X. The case of one explanatory variable is called simple regression...
The method of least squares is a standard approach to the approximate solution of overdetermined systems, i.e., sets of equations in which there are more equations than unknowns. "Least squares" means that the overall solution minimizes the sum of the squares of the errors made in solving every...
Others
I. Hnětynková, M. Plešinger, D. M. Sima, Z. Strakoš, and S. Van Huffel, The total least squares problem in AX ≈ B. A new classification with the relationship to the classical works. Submitted to SIMAX, 2010, [ftp://ftp.sam.math.ethz.ch/pub/sam-reports/reports/reports2010/2010-38.pdf preprint]
M. Plešinger, The Total Least Squares Problem and Reduction of Data in AX ≈ B. Doctoral Thesis, TU of Liberec and Institute of Computer Science, AS CR Prague, 2008. Ph.D. Thesis
I. Markovsky and S. Van Huffel, Overview of total least squares methods. Signal Processing, vol. 87, pp. 2283–2302, 2007. preprint
C. C. Paige, Z. Strakoš, Core problems in linear algebraic systems. SIAM J. Matrix Anal. Appl. 27, 2006, pp. 861–875.
S. Van Huffel and P. Lemmerling, Total Least Squares and Errors-in-Variables Modeling: Analysis, Algorithms and Applications. Dordrecht, The Netherlands: Kluwer Academic Publishers, 2002.
S. Jo and S. W. Kim, Consistent normalized least mean square filtering with noisy data matrix. IEEE Trans. Signal Processing, vol. 53, no. 6, pp. 2112–2123, Jun. 2005.
R. D. DeGroat and E. M. Dowling, The data least squares problem and channel equalization. IEEE Trans. Signal Processing, vol. 41, no. 1, pp. 407–411, Jan. 1993.
S. Van Huffel and J. Vandewalle, The Total Least Squares Problems: Compational Aspects and Analysis. SIAM Pulications, Philadelphia PA, 1991.
T. Abatzoglou and J. Mendel, Constrained total least squares, in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP’87), Apr. 1987, vol. 12, pp. 1485–1488.
P. de Groen An introduction to total least squares, in Nieuw Archief voor Wiskunde, Vierde serie, deel 14, 1996, pp. 237–253 arxiv.org.
G. H. Golub and C. F. Van Loan, An analysis of the total least squares problem. SIAM J. on Numer. Anal., 17, 1980, pp. 883–893.


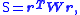
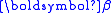 , so the residuals are given by
, so the residuals are given by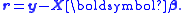
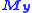 , of the observations, y. The independent variables are assumed to be error-free. The parameter estimates are found by setting the gradient equations to zero, which results in the normal equations
, of the observations, y. The independent variables are assumed to be error-free. The parameter estimates are found by setting the gradient equations to zero, which results in the normal equations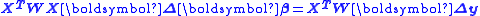 , where
, where 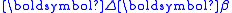 is the parameter shift from some starting estimate of
is the parameter shift from some starting estimate of 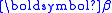 and
and  is the difference between y and the value calculated using the starting value of
is the difference between y and the value calculated using the starting value of 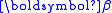
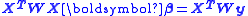
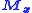 and
and 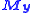 respectively. In this case the objective function can be written as
respectively. In this case the objective function can be written as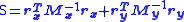
 and
and 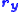 are the residuals in x and y respectively. Clearly these residuals cannot be independent of each other, but they must be constrained by some kind of relationship. Writing the model function as
are the residuals in x and y respectively. Clearly these residuals cannot be independent of each other, but they must be constrained by some kind of relationship. Writing the model function as 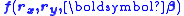 , the constraints are expressed by m condition equations.
, the constraints are expressed by m condition equations.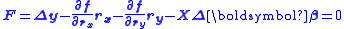
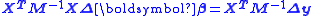 , or alternatively
, or alternatively 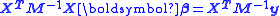
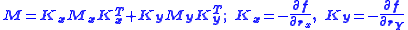
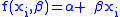
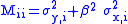
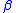 is the slope of the line.
is the slope of the line.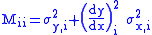
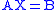
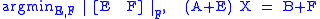
 is the augmented matrix
is the augmented matrix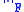 is the Frobenius norm, the square root of the sum of the squares of all entries in a matrix and so equivalently the square root of the sum of squares of the lengths of the rows or columns of the matrix.
is the Frobenius norm, the square root of the sum of the squares of all entries in a matrix and so equivalently the square root of the sum of squares of the lengths of the rows or columns of the matrix.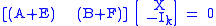 .
.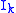 is the
is the 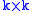 identity matrix.
identity matrix. that reduces the rank of
that reduces the rank of  by k. Define
by k. Define 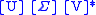 to be the singular value decomposition of the augmented matrix
to be the singular value decomposition of the augmented matrix  .
.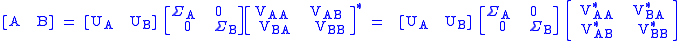
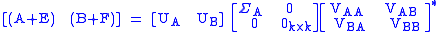
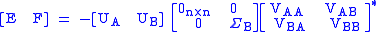 .
.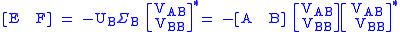 .
.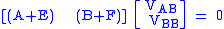 .
.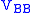 is nonsingular, which is not always the case (note that the behavior of TLS when
is nonsingular, which is not always the case (note that the behavior of TLS when 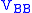 is singular is not well understood yet), we can then right multiply both sides by
is singular is not well understood yet), we can then right multiply both sides by 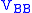 to bring the bottom block of the right matrix to the negative identity.
to bring the bottom block of the right matrix to the negative identity.
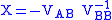 .
.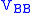 , can be slightly extended by so called classical TLS algorithm.
, can be slightly extended by so called classical TLS algorithm. introduced by Van Huffel and Vandewalle. It is worth noting, that this
introduced by Van Huffel and Vandewalle. It is worth noting, that this  is, however, not the TLS solution in many cases.
is, however, not the TLS solution in many cases.