

Long short term memory
Encyclopedia
Long short term memory or LSTM is a recurrent neural network
(RNN) architecture (an artificial neural network
) published in 1997 by Sepp Hochreiter
and Jürgen Schmidhuber
. Like most RNNs, an LSTM network is universal in the sense that given enough network units it can compute anything a conventional computer can compute, provided it has the proper weight
matrix
, which may be viewed as its program. (Of course, finding such a weight matrix is more challenging with some problems than with others.) Unlike traditional RNNs, an LSTM network is well-suited to learn from experience to classify and process and predict time series
when there are very long time lags of unknown size between important events. This is one of the main reasons why LSTM outperforms alternative RNNs and Hidden Markov Models and other sequence learning methods in numerous applications. For example, LSTM achieved the best known results in unsegmented connected handwriting recognition
, and in 2009 won the ICDAR handwriting competition.
A typical implementation of an LSTM block is shown to the right. The four units shown at the bottom of the figure are sigmoid units. (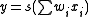 , where s is some squashing function, such as the logistic function
, where s is some squashing function, such as the logistic function
.) The left-most of these units computes a value which is conditionally fed as an input value to the block's memory. The other three units serve as gates to determine when values are allowed to flow into or out of the block's memory. The second unit from the left (on the bottom row) is the "input gate". When it outputs a value close to zero, it zeros out the value from the left-most unit, effectively blocking that value from entering into the next layer. The second unit from the right is the "forget gate". When it outputs a value close to zero, the block will effectively forget whatever value it was remembering. The right-most unit (on the bottom row) is the "output gate". It determines when the unit should output the value in its memory. The units containing the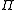 symbol compute the product of their inputs (
symbol compute the product of their inputs (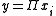 ). These units have no weights. The unit with the
). These units have no weights. The unit with the 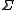 symbol computes a linear function of its inputs (
symbol computes a linear function of its inputs (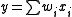 .) The output of this unit is not squashed so that it can remember the same value for many time-steps without the value decaying. This value is fed back in so that the block can "remember" it (as long as the forget gate allows). Typically, this value is also fed into the 3 gating units to help them make gating decisions.
.) The output of this unit is not squashed so that it can remember the same value for many time-steps without the value decaying. This value is fed back in so that the block can "remember" it (as long as the forget gate allows). Typically, this value is also fed into the 3 gating units to help them make gating decisions.
such as backpropagation through time
can be used to change each weight in proportion to its derivative with respect to the error. A major problem with gradient descent for standard RNNs is that error gradients vanish exponentially quickly with the size of the time lag between important events, as first realized in 1991. With LSTM blocks, however, when error values are back-propagated from the output, the error becomes trapped in the memory portion of the block. This is referred to as an "error carousel", which continuously feeds error back to each of the gates until they become trained to cut off the value. Thus, regular backpropagation is effective at training an LSTM block to remember values for very long durations.
LSTM can also be trained by a combination of artificial evolution for weights to the hidden units, and pseudo-inverse or support vector machine
s for weights to the output units. In reinforcement learning
applications LSTM can be trained by policy
gradient methods or evolution strategies or genetic algorithms.
Recurrent neural network
A recurrent neural network is a class of neural network where connections between units form a directed cycle. This creates an internal state of the network which allows it to exhibit dynamic temporal behavior. Unlike feedforward neural networks, RNNs can use their internal memory to process...
(RNN) architecture (an artificial neural network
Artificial neural network
An artificial neural network , usually called neural network , is a mathematical model or computational model that is inspired by the structure and/or functional aspects of biological neural networks. A neural network consists of an interconnected group of artificial neurons, and it processes...
) published in 1997 by Sepp Hochreiter
Sepp Hochreiter
Sepp Hochreiter is acomputer scientist working in the fields of bioinformatics andmachine learning. Since 2006 he has been head of the at theJohannes Kepler University ofLinz. Before, he was at the...
and Jürgen Schmidhuber
Jürgen Schmidhuber
Jürgen Schmidhuber is a computer scientist and artist known for his work on machine learning, universal Artificial Intelligence , artificial neural networks, digital physics, and low-complexity art. His contributions also include generalizations of Kolmogorov complexity and the Speed Prior...
. Like most RNNs, an LSTM network is universal in the sense that given enough network units it can compute anything a conventional computer can compute, provided it has the proper weight
Weight
In science and engineering, the weight of an object is the force on the object due to gravity. Its magnitude , often denoted by an italic letter W, is the product of the mass m of the object and the magnitude of the local gravitational acceleration g; thus:...
matrix
Matrix (mathematics)
In mathematics, a matrix is a rectangular array of numbers, symbols, or expressions. The individual items in a matrix are called its elements or entries. An example of a matrix with six elements isMatrices of the same size can be added or subtracted element by element...
, which may be viewed as its program. (Of course, finding such a weight matrix is more challenging with some problems than with others.) Unlike traditional RNNs, an LSTM network is well-suited to learn from experience to classify and process and predict time series
Time series
In statistics, signal processing, econometrics and mathematical finance, a time series is a sequence of data points, measured typically at successive times spaced at uniform time intervals. Examples of time series are the daily closing value of the Dow Jones index or the annual flow volume of the...
when there are very long time lags of unknown size between important events. This is one of the main reasons why LSTM outperforms alternative RNNs and Hidden Markov Models and other sequence learning methods in numerous applications. For example, LSTM achieved the best known results in unsegmented connected handwriting recognition
Handwriting recognition
Handwriting recognition is the ability of a computer to receive and interpret intelligible handwritten input from sources such as paper documents, photographs, touch-screens and other devices. The image of the written text may be sensed "off line" from a piece of paper by optical scanning or...
, and in 2009 won the ICDAR handwriting competition.
Architecture
An LSTM network is an artificial neural network that contains LSTM blocks instead of, or in addition to, regular network units. An LSTM block may be described as a "smart" network unit that can remember a value for an arbitrary length of time. An LSTM block contains gates that determine when the input is significant enough to remember, when it should continue to remember or forget the value, and when it should output the value.A typical implementation of an LSTM block is shown to the right. The four units shown at the bottom of the figure are sigmoid units. (
, where s is some squashing function, such as the logistic functionLogistic function
A logistic function or logistic curve is a common sigmoid curve, given its name in 1844 or 1845 by Pierre François Verhulst who studied it in relation to population growth. It can model the "S-shaped" curve of growth of some population P...
.) The left-most of these units computes a value which is conditionally fed as an input value to the block's memory. The other three units serve as gates to determine when values are allowed to flow into or out of the block's memory. The second unit from the left (on the bottom row) is the "input gate". When it outputs a value close to zero, it zeros out the value from the left-most unit, effectively blocking that value from entering into the next layer. The second unit from the right is the "forget gate". When it outputs a value close to zero, the block will effectively forget whatever value it was remembering. The right-most unit (on the bottom row) is the "output gate". It determines when the unit should output the value in its memory. The units containing the
symbol compute the product of their inputs (). These units have no weights. The unit with the symbol computes a linear function of its inputs (.) The output of this unit is not squashed so that it can remember the same value for many time-steps without the value decaying. This value is fed back in so that the block can "remember" it (as long as the forget gate allows). Typically, this value is also fed into the 3 gating units to help them make gating decisions.Training
To minimize LSTM's total error on a set of training sequences, iterative gradient descentGradient descent
Gradient descent is a first-order optimization algorithm. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient of the function at the current point...
such as backpropagation through time
Backpropagation through time
Backpropagation through time is a gradient-based technique for training certain types of recurrent neural networks. It can be used to train Elman networks. The algorithm was independently derived by numerous researchers-Algorithm:...
can be used to change each weight in proportion to its derivative with respect to the error. A major problem with gradient descent for standard RNNs is that error gradients vanish exponentially quickly with the size of the time lag between important events, as first realized in 1991. With LSTM blocks, however, when error values are back-propagated from the output, the error becomes trapped in the memory portion of the block. This is referred to as an "error carousel", which continuously feeds error back to each of the gates until they become trained to cut off the value. Thus, regular backpropagation is effective at training an LSTM block to remember values for very long durations.
LSTM can also be trained by a combination of artificial evolution for weights to the hidden units, and pseudo-inverse or support vector machine
Support vector machine
A support vector machine is a concept in statistics and computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis...
s for weights to the output units. In reinforcement learning
Reinforcement learning
Inspired by behaviorist psychology, reinforcement learning is an area of machine learning in computer science, concerned with how an agent ought to take actions in an environment so as to maximize some notion of cumulative reward...
applications LSTM can be trained by policy
Policy
A policy is typically described as a principle or rule to guide decisions and achieve rational outcome. The term is not normally used to denote what is actually done, this is normally referred to as either procedure or protocol...
gradient methods or evolution strategies or genetic algorithms.
Applications
Applications of LSTM include:- Robot control
- Time series prediction
- Speech recognition
- Rhythm learning
- Music composition
- Grammar learning
- Handwriting recognition
See also
- Artificial neural networkArtificial neural networkAn artificial neural network , usually called neural network , is a mathematical model or computational model that is inspired by the structure and/or functional aspects of biological neural networks. A neural network consists of an interconnected group of artificial neurons, and it processes...
- Prefrontal Cortex Basal Ganglia Working Memory (PBWM)
- Recurrent neural networkRecurrent neural networkA recurrent neural network is a class of neural network where connections between units form a directed cycle. This creates an internal state of the network which allows it to exhibit dynamic temporal behavior. Unlike feedforward neural networks, RNNs can use their internal memory to process...
- Time seriesTime seriesIn statistics, signal processing, econometrics and mathematical finance, a time series is a sequence of data points, measured typically at successive times spaced at uniform time intervals. Examples of time series are the daily closing value of the Dow Jones index or the annual flow volume of the...
External links
- Recurrent Neural Networks with over 30 LSTM papers by Jürgen SchmidhuberJürgen SchmidhuberJürgen Schmidhuber is a computer scientist and artist known for his work on machine learning, universal Artificial Intelligence , artificial neural networks, digital physics, and low-complexity art. His contributions also include generalizations of Kolmogorov complexity and the Speed Prior...
's group at IDSIAIDSIAThe Swiss institute for Artificial Intelligence IDSIA was founded in 1988 by the private Dalle Molle foundation...