
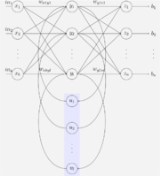
Recurrent neural network
Encyclopedia
A recurrent neural network (RNN) is a class of neural network
where connections between units form a directed cycle. This creates an internal state of the network which allows it to exhibit dynamic temporal behavior. Unlike feedforward neural networks
, RNNs can use their internal memory to process arbitrary sequences of inputs. This makes them applicable to tasks such as unsegmented connected handwriting recognition, where they have achieved the best known results.
For supervised learning
in discrete time settings, training sequences of real-valued input vectors become sequences of activations of the input nodes, one input vector at a time. At any given time step, each non-input unit computes its current activation as a nonlinear function of the weighted sum of the activations of all units from which it receives connections. There may be teacher-given target activations for some of the output units at certain time steps. For example, if the input sequence is a speech signal corresponding to a spoken digit, the final target output at the end of the sequence may be a label classifying the digit. For each sequence, its error is the sum of the deviations of all target signals from the corresponding activations computed by the network. For a training set of numerous sequences, the total error is the sum of the errors of all individual sequences. Algorithms for minimizing this error are mentioned in the section on training algorithms below.
In reinforcement learning
settings, there is no teacher providing target signals for the RNN, instead a fitness function
or reward function is occasionally used to evaluate the RNN's performance, which is influencing its input stream through output units connected to actuators affecting the environment. Again, compare the section on training algorithms below.
, resistant to connection alteration.
A variation on the Hopfield network is the bidirectional associative memory
(BAM). The BAM has two layers, either of which can be driven as an input, to recall an association and produce an output on the other layer.
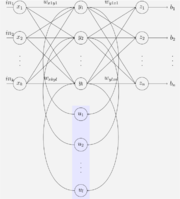 This special case of the basic architecture above was employed by Jeff Elman. A three-layer network is used, with the addition of a set of "context units" in the input layer. There are connections from the middle (hidden) layer to these context units fixed with a weight of one. At each time step, the input is propagated in a standard feed-forward fashion, and then a learning rule is applied. The fixed back connections result in the context units always maintaining a copy of the previous values of the hidden units (since they propagate over the connections before the learning rule is applied). Thus the network can maintain a sort of state, allowing it to perform such tasks as sequence-prediction that are beyond the power of a standard multilayer perceptron.
This special case of the basic architecture above was employed by Jeff Elman. A three-layer network is used, with the addition of a set of "context units" in the input layer. There are connections from the middle (hidden) layer to these context units fixed with a weight of one. At each time step, the input is propagated in a standard feed-forward fashion, and then a learning rule is applied. The fixed back connections result in the context units always maintaining a copy of the previous values of the hidden units (since they propagate over the connections before the learning rule is applied). Thus the network can maintain a sort of state, allowing it to perform such tasks as sequence-prediction that are beyond the power of a standard multilayer perceptron.
Jordan networks, due to Michael I. Jordan
, are similar to Elman networks. The context units are however fed from the output layer instead of the hidden layer. Elman and Jordan networks are also known as "simple recurrent networks" (SRN).
(ESN) is a recurrent neural network with a sparsely connected random hidden layer. The weights of output neurons are the only part of the network that can change and be trained. ESN are good at reproducing certain time series. A variant for spiking neurons is known as Liquid state machines.
(LSTM), developed by Hochreiter
& Schmidhuber
in 1997, is an artificial neural net structure that unlike traditional RNNs doesn't have the problem of vanishing gradients (compare the section on training algorithms below). It works even when there are long delays, and it can handle signals that have a mix of low and high frequency components. LSTM RNN outperformed other methods in numerous applications such as language learning and connected handwriting recognition.
For a neuron in the network with action potential
in the network with action potential  the rate of change of activation is given by:
the rate of change of activation is given by:
Where:
 instead of the standard
instead of the standard  weights, and inputs and states can be a product. This allows a direct mapping to a finite state machine
weights, and inputs and states can be a product. This allows a direct mapping to a finite state machine
both in training and in representation.
can be used to change each weight in proportion to its derivative with respect to the error, provided the non-linear activation functions are differentiable. Various methods for doing so were developed in the 1980s and early 1990s by Paul Werbos
, Ronald J. Williams
, Tony Robinson
, Jürgen Schmidhuber
,
Sepp Hochreiter
, Barak Pearlmutter, and others.
The standard method is called "backpropagation through time
" or BPTT, and is a generalization of back-propagation for feed-forward networks, and like that method, are an instance of Automatic differentiation
in the reverse accumulation mode or Pontryagin's minimum principle
. A more computationally expensive online variant is called "Real-Time Recurrent Learning" or RTRL, which is an instance of Automatic differentiation
in the forward accumulation mode with stacked tangent vectors. Unlike BPTT this algorithm is local in time but not local in space.
There also is an online hybrid between BPTT and RTRL with intermediate complexity, and there are variants for continuous time.
A major problem with gradient descent for standard RNN architectures is that error gradients vanish exponentially quickly with the size of the time lag between important events.
The Long short term memory
architecture together with a BPTT/RTRL hybrid learning method was introduced in an attempt to overcome these problems.
The most common global optimization
method for training RNNs is genetic algorithm
s, especially in unstructured networks.
Initially, the genetic algorithm is encoded with the neural network weights in a predefined manner where one gene in the chromosome represents one weight link, henceforth; the whole network is represented as a single chromosome.
The fitness function is evaluated as follows: 1) each weight encoded in the chromosome is assigned to the respective weight link of the network ; 2) the training set of examples is then presented to the network which propagates the input signals forward ; 3) the mean-squared-error is returned to the fitness function ; 4) this function will then drive the genetic selection process.
There are many chromosomes that make up the population; therefore, many different neural networks are evolved until a stopping criterion is satisfied. A common stopping scheme is: 1) when the neural network has learnt a certain percentage of the training data or 2) when the minimum value of the mean-squared-error is satisfied or 3) when the maximum number of training generations has been reached. The stopping criterion is evaluated by the fitness function as it gets the reciprocal of the mean-squared-error from each neural network during training. Therefore, the goal of the genetic algorithm is to maximize the fitness function, hence, reduce the mean-squared-error.
Other global (and/or evolutionary) optimization techniques may be used to seek a good set of weights such as Simulated annealing
or Particle swarm optimization
.
. In such cases, dynamical systems theory
may be used for analysis.
Neural network
The term neural network was traditionally used to refer to a network or circuit of biological neurons. The modern usage of the term often refers to artificial neural networks, which are composed of artificial neurons or nodes...
where connections between units form a directed cycle. This creates an internal state of the network which allows it to exhibit dynamic temporal behavior. Unlike feedforward neural networks
Feedforward neural networks
A feedforward neural network is an artificial neural network where connections between the units do not form a directed cycle. This is different from recurrent neural networks....
, RNNs can use their internal memory to process arbitrary sequences of inputs. This makes them applicable to tasks such as unsegmented connected handwriting recognition, where they have achieved the best known results.
Fully recurrent network
This is the basic architecture developed in the 1980s: a network of neuron-like units, each with a directed connection to every other unit. Each unit has a time-varying real-valued activation. Each connection has a modifiable real-valued weight. Some of the nodes are called input nodes, some output nodes, the rest hidden nodes. Most architectures below are special cases.For supervised learning
Supervised learning
Supervised learning is the machine learning task of inferring a function from supervised training data. The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value...
in discrete time settings, training sequences of real-valued input vectors become sequences of activations of the input nodes, one input vector at a time. At any given time step, each non-input unit computes its current activation as a nonlinear function of the weighted sum of the activations of all units from which it receives connections. There may be teacher-given target activations for some of the output units at certain time steps. For example, if the input sequence is a speech signal corresponding to a spoken digit, the final target output at the end of the sequence may be a label classifying the digit. For each sequence, its error is the sum of the deviations of all target signals from the corresponding activations computed by the network. For a training set of numerous sequences, the total error is the sum of the errors of all individual sequences. Algorithms for minimizing this error are mentioned in the section on training algorithms below.
In reinforcement learning
Reinforcement learning
Inspired by behaviorist psychology, reinforcement learning is an area of machine learning in computer science, concerned with how an agent ought to take actions in an environment so as to maximize some notion of cumulative reward...
settings, there is no teacher providing target signals for the RNN, instead a fitness function
Fitness function
A fitness function is a particular type of objective function that is used to summarise, as a single figure of merit, how close a given design solution is to achieving the set aims....
or reward function is occasionally used to evaluate the RNN's performance, which is influencing its input stream through output units connected to actuators affecting the environment. Again, compare the section on training algorithms below.
Hopfield network
The Hopfield network is of historic interest although it is not a general RNN, as it is not designed to process sequences of patterns. Instead it requires stationary inputs. It is a RNN in which all connections are symmetric. Invented by John Hopfield in 1982, it guarantees that its dynamics will converge. If the connections are trained using Hebbian learning then the Hopfield network can perform as robust content-addressable memoryContent-addressable memory
Content-addressable memory is a special type of computer memory used in certain very high speed searching applications. It is also known as associative memory, associative storage, or associative array, although the last term is more often used for a programming data structure...
, resistant to connection alteration.
A variation on the Hopfield network is the bidirectional associative memory
Bidirectional Associative Memory
Bidirectional associative memory is a type of recurrent neural network. BAM was introduced by Bart Kosko in 1988. There are two types of associative memory, auto-associative and hetero-associative. BAM is hetero-associative, meaning given a pattern it can return another pattern which is...
(BAM). The BAM has two layers, either of which can be driven as an input, to recall an association and produce an output on the other layer.
Elman networks and Jordan networks
Jordan networks, due to Michael I. Jordan
Michael I. Jordan
Michael I. Jordan is a leading researcher in machine learning and artificial intelligence. Jordan was a prime mover behind popularising Bayesian networks in the machine learning community and is known for pointing out links between machine learning and statistics...
, are similar to Elman networks. The context units are however fed from the output layer instead of the hidden layer. Elman and Jordan networks are also known as "simple recurrent networks" (SRN).
Echo state network
The echo state networkEcho state network
The echo state network is a recurrent neural network with a sparsely connected hidden layer . The connectivity and weights of hidden neurons are randomly assigned and are fixed...
(ESN) is a recurrent neural network with a sparsely connected random hidden layer. The weights of output neurons are the only part of the network that can change and be trained. ESN are good at reproducing certain time series. A variant for spiking neurons is known as Liquid state machines.
Long short term memory network
The Long short term memoryLong short term memory
Long short term memory or LSTM is a recurrent neural network architecture published in 1997 by Sepp Hochreiter and Jürgen Schmidhuber...
(LSTM), developed by Hochreiter
Sepp Hochreiter
Sepp Hochreiter is acomputer scientist working in the fields of bioinformatics andmachine learning. Since 2006 he has been head of the at theJohannes Kepler University ofLinz. Before, he was at the...
& Schmidhuber
Jürgen Schmidhuber
Jürgen Schmidhuber is a computer scientist and artist known for his work on machine learning, universal Artificial Intelligence , artificial neural networks, digital physics, and low-complexity art. His contributions also include generalizations of Kolmogorov complexity and the Speed Prior...
in 1997, is an artificial neural net structure that unlike traditional RNNs doesn't have the problem of vanishing gradients (compare the section on training algorithms below). It works even when there are long delays, and it can handle signals that have a mix of low and high frequency components. LSTM RNN outperformed other methods in numerous applications such as language learning and connected handwriting recognition.
Bi-directional RNN
Invented by Schuster & Paliwal in 1997, bi-directional RNN or BRNN use a finite sequence to predict or label each element of the sequence based on both the past and the future context of the element. This is done by adding the outputs of two RNN, one processing the sequence from left to right, the other one from right to left. The combined outputs are the predictions of the teacher-given target signals. This technique proved to be especially useful when combined with LSTM RNN.Continuous-time RNN
The term continuous time recurrent neural network (CTRNN) is used to refer to a dynamic system intended to model a biological NN. The model uses a differential equation to model the effects on a neuron of the incoming spike train. It is considered to be more computationally efficient than directly simulating every spike in a network.For a neuron
in the network with action potential the rate of change of activation is given by:Where:
-
 : Time constant of postsynaptic node
: Time constant of postsynaptic node -
 : Activation of postsynaptic node
: Activation of postsynaptic node -
 : Rate of change of activation of postsynaptic node
: Rate of change of activation of postsynaptic node -
 : Weight of connection from pre to postsynaptic node
: Weight of connection from pre to postsynaptic node -
 : Sigmoid of x
: Sigmoid of x -
 : Activation of presynaptic node
: Activation of presynaptic node -
 : Bias of presynaptic node
: Bias of presynaptic node -
 : Input (if any) to node
: Input (if any) to node
Hierarchical RNN
There are many instances of hierarchical RNN whose elements are connected in various ways to decompose hierarchical behavior into useful subprograms.Second Order Recurrent Neural Network
Second order RNNs use higher order weights instead of the standard weights, and inputs and states can be a product. This allows a direct mapping to a finite state machineFinite state machine
A finite-state machine or finite-state automaton , or simply a state machine, is a mathematical model used to design computer programs and digital logic circuits. It is conceived as an abstract machine that can be in one of a finite number of states...
both in training and in representation.
Gradient descent
To minimize total error, gradient descentGradient descent
Gradient descent is a first-order optimization algorithm. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient of the function at the current point...
can be used to change each weight in proportion to its derivative with respect to the error, provided the non-linear activation functions are differentiable. Various methods for doing so were developed in the 1980s and early 1990s by Paul Werbos
Paul Werbos
Paul J. Werbos is a scientist best known for his 1974 Harvard University Ph.D. thesis, which first described the process of training artificial neural networks through backpropagation of errors. The thesis, and some supplementary information, can be found in his book, The Roots of Backpropagation...
, Ronald J. Williams
Ronald J. Williams
Ronald J. Williams is professor of computer science at Northeastern University, and one of the pioneers of neural networks. He co-authored a paper on the backpropagation algorithm which triggered a boom in neural network research. He also made fundamental contributions to the fields of recurrent...
, Tony Robinson
Tony Robinson
Tony Robinson is an English actor, comedian, author, broadcaster and political campaigner. He is best known for playing Baldrick in the BBC television series Blackadder, and for hosting Channel 4 programmes such as Time Team and The Worst Jobs in History. Robinson is a member of the Labour Party...
, Jürgen Schmidhuber
Jürgen Schmidhuber
Jürgen Schmidhuber is a computer scientist and artist known for his work on machine learning, universal Artificial Intelligence , artificial neural networks, digital physics, and low-complexity art. His contributions also include generalizations of Kolmogorov complexity and the Speed Prior...
,
Sepp Hochreiter
Sepp Hochreiter
Sepp Hochreiter is acomputer scientist working in the fields of bioinformatics andmachine learning. Since 2006 he has been head of the at theJohannes Kepler University ofLinz. Before, he was at the...
, Barak Pearlmutter, and others.
The standard method is called "backpropagation through time
Backpropagation through time
Backpropagation through time is a gradient-based technique for training certain types of recurrent neural networks. It can be used to train Elman networks. The algorithm was independently derived by numerous researchers-Algorithm:...
" or BPTT, and is a generalization of back-propagation for feed-forward networks, and like that method, are an instance of Automatic differentiation
Automatic differentiation
In mathematics and computer algebra, automatic differentiation , sometimes alternatively called algorithmic differentiation, is a set of techniques to numerically evaluate the derivative of a function specified by a computer program...
in the reverse accumulation mode or Pontryagin's minimum principle
Pontryagin's minimum principle
Pontryagin's maximum principle is used in optimal control theory to find the best possible control for taking a dynamical system from one state to another, especially in the presence of constraints for the state or input controls. It was formulated by the Russian mathematician Lev Semenovich...
. A more computationally expensive online variant is called "Real-Time Recurrent Learning" or RTRL, which is an instance of Automatic differentiation
Automatic differentiation
In mathematics and computer algebra, automatic differentiation , sometimes alternatively called algorithmic differentiation, is a set of techniques to numerically evaluate the derivative of a function specified by a computer program...
in the forward accumulation mode with stacked tangent vectors. Unlike BPTT this algorithm is local in time but not local in space.
There also is an online hybrid between BPTT and RTRL with intermediate complexity, and there are variants for continuous time.
A major problem with gradient descent for standard RNN architectures is that error gradients vanish exponentially quickly with the size of the time lag between important events.
The Long short term memory
Long short term memory
Long short term memory or LSTM is a recurrent neural network architecture published in 1997 by Sepp Hochreiter and Jürgen Schmidhuber...
architecture together with a BPTT/RTRL hybrid learning method was introduced in an attempt to overcome these problems.
Global optimization methods
Training the weights in a neural network is a non-linear global optimization problem. A target function can be formed to evaluate the fitness or error of a particular weight vector as follows: First, the weights in the network are set according to the weight vector. Next, the network is evaluated against the training sequence. Typically, the sum-squared-difference between the predictions and the target values specified in the training sequence is used to represent the error of the current weight vector. Arbitrary global optimization techniques may then be used to minimize this target function.The most common global optimization
Global optimization
Global optimization is a branch of applied mathematics and numerical analysis that deals with the optimization of a function or a set of functions to some criteria.- General :The most common form is the minimization of one real-valued function...
method for training RNNs is genetic algorithm
Genetic algorithm
A genetic algorithm is a search heuristic that mimics the process of natural evolution. This heuristic is routinely used to generate useful solutions to optimization and search problems...
s, especially in unstructured networks.
Initially, the genetic algorithm is encoded with the neural network weights in a predefined manner where one gene in the chromosome represents one weight link, henceforth; the whole network is represented as a single chromosome.
The fitness function is evaluated as follows: 1) each weight encoded in the chromosome is assigned to the respective weight link of the network ; 2) the training set of examples is then presented to the network which propagates the input signals forward ; 3) the mean-squared-error is returned to the fitness function ; 4) this function will then drive the genetic selection process.
There are many chromosomes that make up the population; therefore, many different neural networks are evolved until a stopping criterion is satisfied. A common stopping scheme is: 1) when the neural network has learnt a certain percentage of the training data or 2) when the minimum value of the mean-squared-error is satisfied or 3) when the maximum number of training generations has been reached. The stopping criterion is evaluated by the fitness function as it gets the reciprocal of the mean-squared-error from each neural network during training. Therefore, the goal of the genetic algorithm is to maximize the fitness function, hence, reduce the mean-squared-error.
Other global (and/or evolutionary) optimization techniques may be used to seek a good set of weights such as Simulated annealing
Simulated annealing
Simulated annealing is a generic probabilistic metaheuristic for the global optimization problem of locating a good approximation to the global optimum of a given function in a large search space. It is often used when the search space is discrete...
or Particle swarm optimization
Particle swarm optimization
In computer science, particle swarm optimization is a computational method that optimizes a problem by iteratively trying to improve a candidate solution with regard to a given measure of quality...
.
Related fields
RNNs may behave chaoticallyChaos theory
Chaos theory is a field of study in mathematics, with applications in several disciplines including physics, economics, biology, and philosophy. Chaos theory studies the behavior of dynamical systems that are highly sensitive to initial conditions, an effect which is popularly referred to as the...
. In such cases, dynamical systems theory
Dynamical systems theory
Dynamical systems theory is an area of applied mathematics used to describe the behavior of complex dynamical systems, usually by employing differential equations or difference equations. When differential equations are employed, the theory is called continuous dynamical systems. When difference...
may be used for analysis.
Issues with recurrent neural networks
Most RNNs have had scaling issues. In particular, RNNs cannot be easily trained for large numbers of neuron units nor for large numbers of inputs units. Successful training has been mostly in time series problems with few inputs.External links
- Recurrent Neural Networks with over 60 RNN papers by Jürgen SchmidhuberJürgen SchmidhuberJürgen Schmidhuber is a computer scientist and artist known for his work on machine learning, universal Artificial Intelligence , artificial neural networks, digital physics, and low-complexity art. His contributions also include generalizations of Kolmogorov complexity and the Speed Prior...
's group at IDSIAIDSIAThe Swiss institute for Artificial Intelligence IDSIA was founded in 1988 by the private Dalle Molle foundation... - Elman Neural Network implementation for WEKA