

Prime-factor FFT algorithm
Encyclopedia
The prime-factor algorithm (PFA), also called the Good–Thomas algorithm (1958/1963), is a fast Fourier transform
(FFT) algorithm that re-expresses the discrete Fourier transform
(DFT) of a size N = N1N2 as a two-dimensional N1×N2 DFT, but only for the case where N1 and N2 are relatively prime. These smaller transforms of size N1 and N2 can then be evaluated by applying PFA recursively
or by using some other FFT algorithm.
PFA should not be confused with the mixed-radix generalization of the popular Cooley–Tukey algorithm, which also subdivides a DFT of size N = N1N2 into smaller transforms of size N1 and N2. The latter algorithm can use any factors (not necessarily relatively prime), but it has the disadvantage that it also requires extra multiplications by roots of unity called twiddle factor
s, in addition to the smaller transforms. On the other hand, PFA has the disadvantages that it only works for relatively prime factors (e.g. it is useless for power-of-two
sizes) and that it requires a more complicated re-indexing of the data based on the Chinese remainder theorem
(CRT). Note, however, that PFA can be combined with mixed-radix Cooley–Tukey, with the former factorizing N into relatively prime components and the latter handling repeated factors.
PFA is also closely related to the nested Winograd FFT algorithm, where the latter performs the decomposed N1 by N2 transform via more sophisticated two-dimensional convolution techniques. Some older papers therefore also call Winograd's algorithm a PFA FFT.
(Although the PFA is distinct from the Cooley–Tukey algorithm, Good's 1958 work on the PFA was cited as inspiration by Cooley and Tukey in their famous 1965 paper, and there was initially some confusion about whether the two algorithms were different. In fact, it was the only prior FFT work cited by them, as they were not then aware of the earlier research by Gauss and others.)
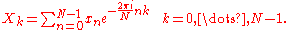
The PFA involves a re-indexing of the input and output arrays, which when substituted into the DFT formula transforms it into two nested DFTs (a two-dimensional DFT).
re-indexing of the input n and output k by:
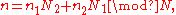
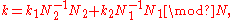
where N1−1 denotes the modular multiplicative inverse of N1 modulo
N2 and vice-versa for N2−1; the indices ka and na run from 0,...,Na−1 (for a = 1, 2). These inverses only exist for relatively prime N1 and N2, and that condition is also required for the first mapping to be bijective.
This re-indexing of n is called the Ruritanian mapping (also Good's mapping), while this re-indexing of k is called the CRT mapping. The latter refers to the fact that k is the solution to the Chinese remainder problem k = k1 mod N1 and k = k2 mod N2.
(One could instead use the Ruritanian mapping for the output k and the CRT mapping for the input n, or various intermediate choices.)
A great deal of research has been devoted to schemes for evaluating this re-indexing efficiently, ideally in-place
, while minimizing the number of costly modulo (remainder) operations (Chan, 1991, and references).
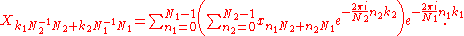
The inner and outer sums are simply DFTs of size N2 and N1, respectively.
(Here, we have used the fact that N1−1N1 is unity when evaluated modulo N2 in the inner sum's exponent, and vice-versa for the outer sum's exponent.)
Fast Fourier transform
A fast Fourier transform is an efficient algorithm to compute the discrete Fourier transform and its inverse. "The FFT has been called the most important numerical algorithm of our lifetime ." There are many distinct FFT algorithms involving a wide range of mathematics, from simple...
(FFT) algorithm that re-expresses the discrete Fourier transform
Discrete Fourier transform
In mathematics, the discrete Fourier transform is a specific kind of discrete transform, used in Fourier analysis. It transforms one function into another, which is called the frequency domain representation, or simply the DFT, of the original function...
(DFT) of a size N = N1N2 as a two-dimensional N1×N2 DFT, but only for the case where N1 and N2 are relatively prime. These smaller transforms of size N1 and N2 can then be evaluated by applying PFA recursively
Recursion
Recursion is the process of repeating items in a self-similar way. For instance, when the surfaces of two mirrors are exactly parallel with each other the nested images that occur are a form of infinite recursion. The term has a variety of meanings specific to a variety of disciplines ranging from...
or by using some other FFT algorithm.
PFA should not be confused with the mixed-radix generalization of the popular Cooley–Tukey algorithm, which also subdivides a DFT of size N = N1N2 into smaller transforms of size N1 and N2. The latter algorithm can use any factors (not necessarily relatively prime), but it has the disadvantage that it also requires extra multiplications by roots of unity called twiddle factor
Twiddle factor
A twiddle factor, in fast Fourier transform algorithms, is any of the trigonometric constant coefficients that are multiplied by the data in the course of the algorithm...
s, in addition to the smaller transforms. On the other hand, PFA has the disadvantages that it only works for relatively prime factors (e.g. it is useless for power-of-two
Power of two
In mathematics, a power of two means a number of the form 2n where n is an integer, i.e. the result of exponentiation with as base the number two and as exponent the integer n....
sizes) and that it requires a more complicated re-indexing of the data based on the Chinese remainder theorem
Chinese remainder theorem
The Chinese remainder theorem is a result about congruences in number theory and its generalizations in abstract algebra.In its most basic form it concerned with determining n, given the remainders generated by division of n by several numbers...
(CRT). Note, however, that PFA can be combined with mixed-radix Cooley–Tukey, with the former factorizing N into relatively prime components and the latter handling repeated factors.
PFA is also closely related to the nested Winograd FFT algorithm, where the latter performs the decomposed N1 by N2 transform via more sophisticated two-dimensional convolution techniques. Some older papers therefore also call Winograd's algorithm a PFA FFT.
(Although the PFA is distinct from the Cooley–Tukey algorithm, Good's 1958 work on the PFA was cited as inspiration by Cooley and Tukey in their famous 1965 paper, and there was initially some confusion about whether the two algorithms were different. In fact, it was the only prior FFT work cited by them, as they were not then aware of the earlier research by Gauss and others.)
Algorithm
Recall that the DFT is defined by the formula:The PFA involves a re-indexing of the input and output arrays, which when substituted into the DFT formula transforms it into two nested DFTs (a two-dimensional DFT).
Re-indexing
Suppose that N = N1N2, where N1 and N2 are relatively prime. In this case, we can define a bijectiveBijection
A bijection is a function giving an exact pairing of the elements of two sets. A bijection from the set X to the set Y has an inverse function from Y to X. If X and Y are finite sets, then the existence of a bijection means they have the same number of elements...
re-indexing of the input n and output k by:
where N1−1 denotes the modular multiplicative inverse of N1 modulo
Modular arithmetic
In mathematics, modular arithmetic is a system of arithmetic for integers, where numbers "wrap around" after they reach a certain value—the modulus....
N2 and vice-versa for N2−1; the indices ka and na run from 0,...,Na−1 (for a = 1, 2). These inverses only exist for relatively prime N1 and N2, and that condition is also required for the first mapping to be bijective.
This re-indexing of n is called the Ruritanian mapping (also Good's mapping), while this re-indexing of k is called the CRT mapping. The latter refers to the fact that k is the solution to the Chinese remainder problem k = k1 mod N1 and k = k2 mod N2.
(One could instead use the Ruritanian mapping for the output k and the CRT mapping for the input n, or various intermediate choices.)
A great deal of research has been devoted to schemes for evaluating this re-indexing efficiently, ideally in-place
In-place algorithm
In computer science, an in-place algorithm is an algorithm which transforms input using a data structure with a small, constant amount of extra storage space. The input is usually overwritten by the output as the algorithm executes...
, while minimizing the number of costly modulo (remainder) operations (Chan, 1991, and references).
DFT re-expression
The above re-indexing is then substituted into the formula for the DFT, and in particular into the product nk in the exponent. Because e2πi = 1, this exponent is evaluated modulo N: any N1N2 = N cross term in the nk product can be set to zero. (Similarly, Xk and xn are implicitly periodic in N, so their subscripts are evaluated modulo N.) The remaining terms give:The inner and outer sums are simply DFTs of size N2 and N1, respectively.
(Here, we have used the fact that N1−1N1 is unity when evaluated modulo N2 in the inner sum's exponent, and vice-versa for the outer sum's exponent.)