
Speech perception
Encyclopedia
Speech
perception is the process by which the sounds of language
are heard, interpreted and understood. The study of speech perception is closely linked to the fields of phonetics
and phonology
in linguistics
and cognitive psychology
and perception
in psychology
. Research in speech perception seeks to understand how human listeners recognize speech sounds and use this information to understand spoken language. Speech perception research has applications in building computer systems that can recognize speech, in improving speech recognition for hearing- and language-impaired listeners, as well as in foreign-language teaching.
.) After processing the initial auditory signal, speech sounds are further processed to extract acoustic cues and phonetic information. This speech information can then be used for higher-level language processes, such as word recognition.
 The speech sound signal contains a number of acoustic cues that are used in speech perception. The cues differentiate speech sounds belonging to different phonetic categories. For example, one of the most studied cues in speech is voice onset time
The speech sound signal contains a number of acoustic cues that are used in speech perception. The cues differentiate speech sounds belonging to different phonetic categories. For example, one of the most studied cues in speech is voice onset time
or VOT. VOT is a primary cue signaling the difference between voiced and voiceless stop consonants, such as "b" and "p". Other cues differentiate sounds that are produced at different places of articulation
or manners of articulation
. The speech system must also combine these cues to determine the category of a specific speech sound. This is often thought of in terms of abstract representations of phonemes. These representations can then be combined for use in word recognition and other language processes.
It is not easy to identify what acoustic cues listeners are sensitive to when perceiving a particular speech sound:
If a specific aspect of the acoustic waveform indicated one linguistic unit, a series of tests using speech synthesizers would be sufficient to determine such a cue or cues. However, there are two significant obstacles:
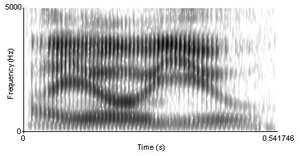 Although listeners perceive speech as a stream of discrete units (phonemes, syllables, and words), this linearity is difficult to be seen in the physical speech signal (see Figure 2 for an example). Speech sounds do not strictly follow one another, rather, they overlap. A speech sound is influenced by the ones that precede and the ones that follow. This influence can even be exerted at a distance of two or more segments (and across syllable- and word-boundaries).
Although listeners perceive speech as a stream of discrete units (phonemes, syllables, and words), this linearity is difficult to be seen in the physical speech signal (see Figure 2 for an example). Speech sounds do not strictly follow one another, rather, they overlap. A speech sound is influenced by the ones that precede and the ones that follow. This influence can even be exerted at a distance of two or more segments (and across syllable- and word-boundaries).
Having disputed the linearity of the speech signal, the problem of segmentation arises: one encounters serious difficulties trying to delimit a stretch of speech signal as belonging to a single perceptual unit. This can be again illustrated by the fact that the acoustic properties of the phoneme /d/ will depend on the production of the following vowel (because of coarticulation
).
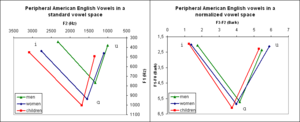 Despite the great variety of different speakers and different conditions, listeners perceive vowels and consonants as constant categories. It has been proposed that this is achieved by means of the perceptual normalization process in which listeners filter out the noise (i.e. variation) to arrive at the underlying category. Vocal-tract-size differences result in formant-frequency variation across speakers; therefore a listener has to adjust his/her perceptual system to the acoustic characteristics of a particular speaker. This may be accomplished by considering the ratios of formants rather than their absolute values. This process has been called vocal tract normalization (see Figure 3 for an example). Similarly, listeners are believed to adjust the perception of duration to the current tempo of the speech they are listening to – this has been referred to as speech rate normalization.
Despite the great variety of different speakers and different conditions, listeners perceive vowels and consonants as constant categories. It has been proposed that this is achieved by means of the perceptual normalization process in which listeners filter out the noise (i.e. variation) to arrive at the underlying category. Vocal-tract-size differences result in formant-frequency variation across speakers; therefore a listener has to adjust his/her perceptual system to the acoustic characteristics of a particular speaker. This may be accomplished by considering the ratios of formants rather than their absolute values. This process has been called vocal tract normalization (see Figure 3 for an example). Similarly, listeners are believed to adjust the perception of duration to the current tempo of the speech they are listening to – this has been referred to as speech rate normalization.
Whether or not normalization actually takes place and what is its exact nature is a matter of theoretical controversy (see theories below). Perceptual constancy is a phenomenon not specific to speech perception only; it exists in other types of perception too.
 Categorical perception is involved in processes of perceptual differentiation. People perceive speech sounds categorically, that is to say, they are more likely to notice the differences between categories (phonemes) than within categories. The perceptual space between categories is therefore warped, the centers of categories (or "prototypes") working like a sieve or like magnets for incoming speech sounds.
Categorical perception is involved in processes of perceptual differentiation. People perceive speech sounds categorically, that is to say, they are more likely to notice the differences between categories (phonemes) than within categories. The perceptual space between categories is therefore warped, the centers of categories (or "prototypes") working like a sieve or like magnets for incoming speech sounds.
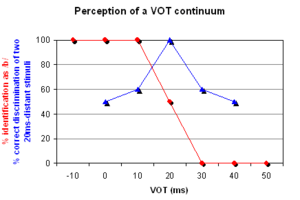
In an artificial continuum between a voiceless and a voiced bilabial stop
, each new step differs from the preceding one in the amount of VOT
. The first sound is a pre-voiced
[b], i.e. it has a negative VOT. Then, increasing the VOT, it reaches zero, i.e. the stop is a plain unaspirated
voiceless [p]. Gradually, adding the same amount of VOT at a time, the stop is eventually a strongly aspirated voiceless bilabial [pʰ]. (Such a continuum was used in an experiment by Lisker
and Abramson
in 1970. The sounds they used are available online.) In this continuum of, for example, seven sounds, native English listeners will identify the first three sounds as /b/ and the last three sounds as /p/ with a clear boundary between the two categories. A two-alternative identification (or categorization) test will yield a discontinuous categorization function (see red curve in Figure 4).
In tests of the ability to discriminate between two sounds with varying VOT values but having a constant VOT distance from each other (20 ms for instance), listeners are likely to perform at chance level if both sounds fall within the same category and at nearly 100% level if each sound falls in a different category (see the blue discrimination curve in Figure 4).
The conclusion to make from both the identification and the discrimination test is that listeners will have different sensitivity to the same relative increase in VOT depending on whether or not the boundary between categories was crossed. Similar perceptual adjustment is attested for other acoustic cues as well.
, syntax
, or semantics
may interact with basic speech perception processes to aid in recognition of speech sounds. It may be the case that it is not necessary and maybe even not possible for a listener to recognize phonemes before recognizing higher units, like words for example. After obtaining at least a fundamental piece of information about phonemic structure of the perceived entity from the acoustic signal, listeners are able to compensate for missing or noise-masked phonemes using their knowledge of the spoken language.
In a classic experiment, Richard M. Warren (1970) replaced one phoneme of a word with a cough-like sound. His subjects restored the missing speech sound perceptually without any difficulty and what is more, they were not able to identify accurately which phoneme had been disturbed. This is known as the phonemic restoration effect. Another basic experiment compares recognition of naturally spoken words presented in a sentence (or at least a phrase) and the same words presented in isolation. Perception accuracy usually drops in the latter condition. Garnes and Bond (1976) also used carrier sentences when researching the influence of semantic knowledge on perception. They created series of words differing in one phoneme (bay/day/gay, for example). The quality of the first phoneme changed along a continuum. All these stimuli were put into different sentences each of which made sense with one of the words only. Listeners had a tendency to judge the ambiguous words (when the first segment was at the boundary between categories) according to the meaning of the whole sentence.
If day-old babies are presented with their mother's voice speaking normally, abnormally (in monotone), and a stranger's voice, they react only to their mother's voice speaking normally. When a human and a non-human sound is played, babies turn their head only to the source of human sound. It has been suggested that auditory learning begins already in the pre-natal period.
How do researchers know if infants can distinguish between speech sounds? One of the techniques used to examine how infants perceive speech, besides the head-turn procedure mentioned above, is measuring their sucking rate. In such an experiment, a baby is sucking a special nipple while presented with sounds. First, the baby's normal sucking rate is established. Then a stimulus is played repeatedly. When the baby hears the stimulus for the first time the sucking rate increases but as the baby becomes habituated to the stimulation the sucking rate decreases and levels off. Then, a new stimulus is played to the baby. If the baby perceives the newly introduced stimulus as different from the background stimulus the sucking rate will show an increase. The sucking-rate and the head-turn method are some of the more traditional, behavioral methods for studying speech perception. Among the new methods (see Research methods below) that help us to study speech perception, near-infrared spectroscopy is widely used in infants.
speech (referred to as cross-language speech perception) or second-language
speech (second-language speech perception). The latter falls within the domain of second language acquisition
.
Languages differ in their phonemic inventories. Naturally, this creates difficulties when a foreign language is encountered. For example, if two foreign-language sounds are assimilated to a single mother-tongue category the difference between them will be very difficult to discern. A classic example of this situation is the observation that Japanese learners of English will have problems with identifying or distinguishing English liquid consonant
s /l/ and /r/.
Best (1995) proposed a Perceptual Assimilation Model which describes possible cross-language category assimilation patterns and predicts their consequences. Flege (1995) formulated a Speech Learning Model which combines several hypotheses about second-language (L2) speech acquisition and which predicts, in simple words, that an L2 sound that is not too similar to a native-language (L1) sound will be easier to acquire than an L2 sound that is relatively similar to an L1 sound (because it will be perceived as more obviously "different" by the learner).
systems have with recognizing human speech. These programs can do well at recognizing speech when they have been trained on a specific speaker's voice, and under quiet conditions. However, these systems often do poorly in more realistic listening situations where humans are able to understand speech without difficulty.
Conversely, some research has revealed that, rather than music affecting our perception of speech, our native speech can affect our perception of music. One example is the tritone paradox
. The tritone paradox is where a listener is presented with two computer-generated tones (such as C and C-Sharp) that are half an octave (or a tritone) apart and are then asked to determine whether the pitch of the sequence is descending or ascending. One such study, performed by Ms. Diana Deutsch, found that the listeners interpretation of ascending or descending pitch was influenced by the listeners language or dialect, showing variation between those raised in the south of England and those in California or from those in Vietnam and those in California whose native language was English. A second study, performed in 2006 on a group of English speakers and 3 groups of East Asian students at University of Southern California, discovered that English speakers who had begun musical training at or before age 5 had a 8% chance of having perfect pitch. For the East Asian students that were fluent in their native tone language, 92 percent of the students had perfect pitch.
Computational modeling has also been used to simulate how speech may be processed by the brain to produce behaviors that are observed. Computer models have been used to address several questions in speech perception, including how the sound signal itself is processed to extract the acoustic cues used in speech, as well as how speech information is used for higher-level processes, such as word recognition.
Neurophysiological methods rely on utilizing information stemming from more direct and not necessarily conscious (pre-attentative) processes. Subjects are presented with speech stimuli in different types of tasks and the responses of the brain are measured. The brain itself can be more sensitive than it appears to be through behavioral responses. For example, the subject may not show sensitivity to the difference between two speech sounds in a discrimination test, but brain responses may reveal sensitivity to these differences. Methods used to measure neural responses to speech include event-related potential
s, magnetoencephalography
, and near infrared spectroscopy
. One important response used with event-related potential
s is the mismatch negativity
, which occurs when speech stimuli are acoustically different from a stimulus that the subject heard previously.
Neurophysiological methods were introduced into speech perception research for several reasons:
Without the necessity of taking an active part in the test, even infants can be tested; this feature is crucial in research into acquisition processes. The possibility to observe low-level auditory processes independently from the higher-level ones makes it possible to address long-standing theoretical issues such as whether or not humans possess a specialized module for perceiving speech or whether or not some complex acoustic invariance (see lack of invariance above) underlies the recognition of a speech sound.
and his colleagues at Haskins Laboratories
. Using a speech synthesizer, they constructed speech sounds that varied in place of articulation
along a continuum from /bɑ/ to /dɑ/ to /ɡɑ/. Listeners were asked to identify which sound they heard and to discriminate between two different sounds. The results of the experiment showed that listeners grouped sounds into discrete categories, even though the sounds they were hearing were varying continuously. Based on these results, they proposed the notion of categorical perception
as a mechanism by which humans are able to identify speech sounds.
More recent research using different tasks and methodologies suggests that listeners are highly sensitive to acoustic differences within a single phonetic category, contrary to a strict categorical account of speech perception.
In order to provide a theoretical account of the categorical perception
data, Liberman and colleagues worked out the motor theory of speech perception, where "the complicated articulatory encoding was assumed to be decoded in the perception of speech by the same processes that are involved in production" (this is referred to as analysis-by-synthesis). For instance, the English consonant /d/ may vary in its acoustic details across different phonetic contexts (see above), yet all /d/'s as perceived by a listener fall within one category (voiced alveolar stop) and that is because "lingustic representations are abstract, canonical, phonetic segments or the gestures that underlie these segments." When describing units of perception, Liberman later abandoned articulatory movements and proceeded to the neural commands to the articulators and even later to intended articulatory gestures, thus "the neural representation of the utterance that determines the speaker's production is the distal object the lister perceives". The theory is closely related to the modularity
hypothesis, which proposes the existence of a special-purpose module, which is supposed to be innate and probably human-specific.
The theory has been criticized in terms of not being able to "provide an account of just how acoustic signals are translated into intended gestures" by listeners. Furthermore, it is unclear how indexical information (e.g. talker-identity) is encoded/decoded along with linguistically relevant information.
) is a part of the more general theory of direct realism, which postulates that perception allows us to have direct awareness of the world because it involves direct recovery of the distal source of the event that is perceived. For speech perception, the theory asserts that the objects of perception are actual vocal tract movements, or gestures, and not abstract phonemes or (as in the Motor Theory) events that are causally antecedent to these movements, i.e. intended gestures. Listeners perceive gestures not by means of a specialized decoder (as in the Motor Theory) but because information in the acoustic signal specifies the gestures that form it. By claiming that the actual articulatory gestures that produce different speech sounds are themselves the units of speech perception, the theory bypasses the problem of lack of invariance.
proposes that people remember speech sounds in a probabilistic, or graded, way. It suggests that people remember descriptions of the perceptual units of language, called prototypes. Within each prototype various features may combine. However, features are not just binary (true or false), there is a fuzzy
value corresponding to how likely it is that a sound belongs to a particular speech category. Thus, when perceiving a speech signal our decision about what we actually hear is based on the relative goodness of the match between the stimulus information and values of particular prototypes. The final decision is based on multiple features or sources of information, even visual information (this explains the McGurk effect
). Computer models of the fuzzy logical theory have been used to demonstrate that the theory's predictions of how speech sounds are categorized correspond to the behavior of human listeners.
proposed another kind of relation: between phonological features and auditory properties. According to this view, listeners are inspecting the incoming signal for the so-called acoustic landmarks which are particular events in the spectrum carrying information about gestures which produced them. Since these gestures are limited by the capacities of humans' articulators and listeners are sensitive to their auditory correlates, the lack of invariance simply does not exist in this model. The acoustic properties of the landmarks constitute the basis for establishing the distinctive features. Bundles of them uniquely specify phonetic segments (phonemes, syllables, words).
The exemplar-based approaches claim listeners store information for word- as well as talker-recognition. According to this theory, particular instances of speech sounds are stored in the memory of a listener. In the process of speech perception, the remembered instances of e.g. a syllable stored in the listener's memory are compared with the incoming stimulus so that the stimulus can be categorized. Similarly, when recognizing a talker, all the memory traces of utterances produced by that talker are activated and the talker's identity is determined. Supporting this theory are several experiments reported by Johnson that suggest that our signal identification is more accurate when we are familiar with the talker or when we have visual representation of the talker's gender. When the talker is unpredictable or the sex misidentified, the error rate in word-identification is much higher.
The exemplar models have to face several objections, two of which are (1) insufficient memory capacity to store every utterance ever heard and, concerning the ability to produce what was heard, (2) whether also the talker's own articulatory gestures are stored or computed when producing utterances that would sound as the auditory memories.
Speech
Speech is the human faculty of speaking.It may also refer to:* Public speaking, the process of speaking to a group of people* Manner of articulation, how the body parts involved in making speech are manipulated...
perception is the process by which the sounds of language
Language
Language may refer either to the specifically human capacity for acquiring and using complex systems of communication, or to a specific instance of such a system of complex communication...
are heard, interpreted and understood. The study of speech perception is closely linked to the fields of phonetics
Phonetics
Phonetics is a branch of linguistics that comprises the study of the sounds of human speech, or—in the case of sign languages—the equivalent aspects of sign. It is concerned with the physical properties of speech sounds or signs : their physiological production, acoustic properties, auditory...
and phonology
Phonology
Phonology is, broadly speaking, the subdiscipline of linguistics concerned with the sounds of language. That is, it is the systematic use of sound to encode meaning in any spoken human language, or the field of linguistics studying this use...
in linguistics
Linguistics
Linguistics is the scientific study of human language. Linguistics can be broadly broken into three categories or subfields of study: language form, language meaning, and language in context....
and cognitive psychology
Cognitive psychology
Cognitive psychology is a subdiscipline of psychology exploring internal mental processes.It is the study of how people perceive, remember, think, speak, and solve problems.Cognitive psychology differs from previous psychological approaches in two key ways....
and perception
Perception
Perception is the process of attaining awareness or understanding of the environment by organizing and interpreting sensory information. All perception involves signals in the nervous system, which in turn result from physical stimulation of the sense organs...
in psychology
Psychology
Psychology is the study of the mind and behavior. Its immediate goal is to understand individuals and groups by both establishing general principles and researching specific cases. For many, the ultimate goal of psychology is to benefit society...
. Research in speech perception seeks to understand how human listeners recognize speech sounds and use this information to understand spoken language. Speech perception research has applications in building computer systems that can recognize speech, in improving speech recognition for hearing- and language-impaired listeners, as well as in foreign-language teaching.
Basics of speech perception
The process of perceiving speech begins at the level of the sound signal and the process of audition. (For a complete description of the process of audition see HearingHearing (sense)
Hearing is the ability to perceive sound by detecting vibrations through an organ such as the ear. It is one of the traditional five senses...
.) After processing the initial auditory signal, speech sounds are further processed to extract acoustic cues and phonetic information. This speech information can then be used for higher-level language processes, such as word recognition.
Acoustic cues
Voice onset time
In phonetics, voice onset time, commonly abbreviated VOT, is a feature of the production of stop consonants. It is defined as the length of time that passes between when a stop consonant is released and when voicing, the vibration of the vocal folds, or, according to the authors, periodicity begins...
or VOT. VOT is a primary cue signaling the difference between voiced and voiceless stop consonants, such as "b" and "p". Other cues differentiate sounds that are produced at different places of articulation
Place of articulation
In articulatory phonetics, the place of articulation of a consonant is the point of contact where an obstruction occurs in the vocal tract between an articulatory gesture, an active articulator , and a passive location...
or manners of articulation
Manner of articulation
In linguistics, manner of articulation describes how the tongue, lips, jaw, and other speech organs are involved in making a sound. Often the concept is only used for the production of consonants, even though the movement of the articulars will also greatly alter the resonant properties of the...
. The speech system must also combine these cues to determine the category of a specific speech sound. This is often thought of in terms of abstract representations of phonemes. These representations can then be combined for use in word recognition and other language processes.
It is not easy to identify what acoustic cues listeners are sensitive to when perceiving a particular speech sound:
At first glance, the solution to the problem of how we perceive speech seems deceptively simple. If one could identify stretches of the acoustic waveform that correspond to units of perception, then the path from sound to meaning would be clear. However, this correspondence or mapping has proven extremely difficult to find, even after some forty-five years of research on the problem.
If a specific aspect of the acoustic waveform indicated one linguistic unit, a series of tests using speech synthesizers would be sufficient to determine such a cue or cues. However, there are two significant obstacles:
- One acoustic aspect of the speech signal may cue different linguistically relevant dimensions. For example, the duration of a vowel in English can indicate whether or not the vowel is stressed, or whether it is in a syllable closed by a voiced or a voiceless consonant, and in some cases (like American English /ɛ/ and /æ/) it can distinguish the identity of vowels. Some experts even argue that duration can help in distinguishing of what is traditionally called short and long vowels in English.
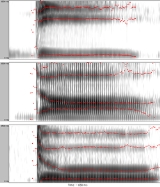
- One linguistic unit can be cued by several acoustic properties. For example in a classic experiment, Alvin LibermanAlvin LibermanAlvin Meyer Liberman was an American psychologist whose ideas set the agenda for fifty years of research in the psychology of speech perception and laid the groundwork for modern computer speech synthesis and the understanding of critical issues in cognitive science...
(1957) showed that the onset formant transitions of /d/ differ depending on the following vowel (see Figure 1) but they are all interpreted as the phoneme /d/ by listeners.
Linearity and the segmentation problem
Having disputed the linearity of the speech signal, the problem of segmentation arises: one encounters serious difficulties trying to delimit a stretch of speech signal as belonging to a single perceptual unit. This can be again illustrated by the fact that the acoustic properties of the phoneme /d/ will depend on the production of the following vowel (because of coarticulation
Coarticulation
Coarticulation in its general sense refers to a situation in which a conceptually isolated speech sound is influenced by, and becomes more like, a preceding or following speech sound...
).
Lack of invariance
The research and application of speech perception has to deal with several problems which result from what has been termed the lack of invariance. As was suggested above, reliable constant relations between a phoneme of a language and its acoustic manifestation in speech are difficult to find. There are several reasons for this:- Context-induced variation. Phonetic environment affects the acoustic properties of speech sounds. For example, /u/ in English is fronted when surrounded by coronal consonantCoronal consonantCoronal consonants are consonants articulated with the flexible front part of the tongue. Only the coronal consonants can be divided into apical , laminal , domed , or subapical , as well as a few rarer orientations, because only the front of the tongue has such...
s. Or, the VOT values marking the boundary between voiced and voiceless stops are different for labial, alveolar and velar stops and they shift under stress or depending on the position within a syllable.
- Variation due to differing speech conditions. One important factor that causes variation is differing speech rate. Many phonemic contrasts are constituted by temporal characteristics (short vs. long vowels or consonants, affricates vs. fricatives, stops vs. glides, voiced vs. voiceless stops, etc.) and they are certainly affected by changes in speaking tempo. Another major source of variation is articulatory carefulness vs. sloppiness which is typical for connected speech (articulatory "undershoot" is obviously reflected in the acoustic properties of the sounds produced).
- Variation due to different speaker identity. The resulting acoustic structure of concrete speech productions depends on the physical and psychological properties of individual speakers. Men, women, and children generally produce voices having different pitch. Because speakers have vocal tracts of different sizes (due to sex and age especially) the resonant frequencies (formants), which are important for recognition of speech sounds, will vary in their absolute values across individuals (see Figure 3 for an illustration of this). Dialect and foreign accent cause variation as well.
Perceptual constancy and normalization
Whether or not normalization actually takes place and what is its exact nature is a matter of theoretical controversy (see theories below). Perceptual constancy is a phenomenon not specific to speech perception only; it exists in other types of perception too.
Categorical perception
In an artificial continuum between a voiceless and a voiced bilabial stop
Bilabial plosive
In phonetics and phonology, a bilabial stop is a type of consonantal sound, made with both lips , held tightly enough to block the passage of air . The most common sounds are the plosives and , as in English pit and bit...
, each new step differs from the preceding one in the amount of VOT
Voice onset time
In phonetics, voice onset time, commonly abbreviated VOT, is a feature of the production of stop consonants. It is defined as the length of time that passes between when a stop consonant is released and when voicing, the vibration of the vocal folds, or, according to the authors, periodicity begins...
. The first sound is a pre-voiced
Pre-voicing (phonetics)
In phonetics, prevoicing means that voicing begins before the release of a stop consonant. This means that the voice onset time has a negative value...
[b], i.e. it has a negative VOT. Then, increasing the VOT, it reaches zero, i.e. the stop is a plain unaspirated
Aspiration (phonetics)
In phonetics, aspiration is the strong burst of air that accompanies either the release or, in the case of preaspiration, the closure of some obstruents. To feel or see the difference between aspirated and unaspirated sounds, one can put a hand or a lit candle in front of one's mouth, and say pin ...
voiceless [p]. Gradually, adding the same amount of VOT at a time, the stop is eventually a strongly aspirated voiceless bilabial [pʰ]. (Such a continuum was used in an experiment by Lisker
Leigh Lisker
Leigh Lisker was an eminent American linguist and phonetician. Most of his career was spent at the University of Pennsylvania, where he was a professor and then emeritus professor of linguistics. Dr. Lisker received his A.B. in 1941, with a major in German, his M.A. in 1946, and a Ph.D. in 1949 in...
and Abramson
Arthur S. Abramson
Arthur S. Abramson is an American linguist, phonetician, and speech scientist. He is a Professor Emeritus of Linguistics at the University of Connecticut , where he was the founding chair, and a Senior Scientist at Haskins Laboratories in New Haven, Connecticut. He is also a member of the Board of...
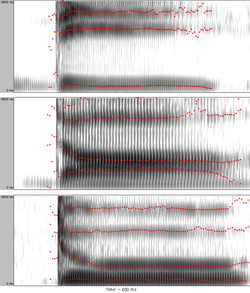
in 1970. The sounds they used are available online.) In this continuum of, for example, seven sounds, native English listeners will identify the first three sounds as /b/ and the last three sounds as /p/ with a clear boundary between the two categories. A two-alternative identification (or categorization) test will yield a discontinuous categorization function (see red curve in Figure 4).
In tests of the ability to discriminate between two sounds with varying VOT values but having a constant VOT distance from each other (20 ms for instance), listeners are likely to perform at chance level if both sounds fall within the same category and at nearly 100% level if each sound falls in a different category (see the blue discrimination curve in Figure 4).
The conclusion to make from both the identification and the discrimination test is that listeners will have different sensitivity to the same relative increase in VOT depending on whether or not the boundary between categories was crossed. Similar perceptual adjustment is attested for other acoustic cues as well.
Top-down influences
The process of speech perception is not necessarily uni-directional. That is, higher-level language processes connected with morphologyMorphology (linguistics)
In linguistics, morphology is the identification, analysis and description, in a language, of the structure of morphemes and other linguistic units, such as words, affixes, parts of speech, intonation/stress, or implied context...
, syntax
Syntax
In linguistics, syntax is the study of the principles and rules for constructing phrases and sentences in natural languages....
, or semantics
Semantics
Semantics is the study of meaning. It focuses on the relation between signifiers, such as words, phrases, signs and symbols, and what they stand for, their denotata....
may interact with basic speech perception processes to aid in recognition of speech sounds. It may be the case that it is not necessary and maybe even not possible for a listener to recognize phonemes before recognizing higher units, like words for example. After obtaining at least a fundamental piece of information about phonemic structure of the perceived entity from the acoustic signal, listeners are able to compensate for missing or noise-masked phonemes using their knowledge of the spoken language.
In a classic experiment, Richard M. Warren (1970) replaced one phoneme of a word with a cough-like sound. His subjects restored the missing speech sound perceptually without any difficulty and what is more, they were not able to identify accurately which phoneme had been disturbed. This is known as the phonemic restoration effect. Another basic experiment compares recognition of naturally spoken words presented in a sentence (or at least a phrase) and the same words presented in isolation. Perception accuracy usually drops in the latter condition. Garnes and Bond (1976) also used carrier sentences when researching the influence of semantic knowledge on perception. They created series of words differing in one phoneme (bay/day/gay, for example). The quality of the first phoneme changed along a continuum. All these stimuli were put into different sentences each of which made sense with one of the words only. Listeners had a tendency to judge the ambiguous words (when the first segment was at the boundary between categories) according to the meaning of the whole sentence.
Infant speech perception
Infants begin the process of language acquisition by being able to detect very small differences between speech sounds. They are able to discriminate all possible speech contrasts (phonemes). Gradually, as they are exposed to their native language, their perception becomes language-specific, i.e. they learn how to ignore the differences within phonemic categories of the language (differences that may well be contrastive in other languages – for example, English distinguishes two voicing categories of stop consonants, whereas Thai has three categories; infants must learn which differences are distinctive in their native language uses, and which are not). As infants learn how to sort incoming speech sounds into categories, ignoring irrelevant differences and reinforcing the contrastive ones, their perception becomes categorical. Infants learn to contrast different vowel phonemes of their native language by approximately 6 months of age. The native consonantal contrasts are acquired by 11 or 12 months of age. Some researchers have proposed that infants may be able to learn the sound categories of their native language through passive listening, using a process called statistical learning. Others even claim that certain sound categories are innate, that is, they are genetically specified (see discussion about innate vs. acquired categorical distinctiveness).If day-old babies are presented with their mother's voice speaking normally, abnormally (in monotone), and a stranger's voice, they react only to their mother's voice speaking normally. When a human and a non-human sound is played, babies turn their head only to the source of human sound. It has been suggested that auditory learning begins already in the pre-natal period.
How do researchers know if infants can distinguish between speech sounds? One of the techniques used to examine how infants perceive speech, besides the head-turn procedure mentioned above, is measuring their sucking rate. In such an experiment, a baby is sucking a special nipple while presented with sounds. First, the baby's normal sucking rate is established. Then a stimulus is played repeatedly. When the baby hears the stimulus for the first time the sucking rate increases but as the baby becomes habituated to the stimulation the sucking rate decreases and levels off. Then, a new stimulus is played to the baby. If the baby perceives the newly introduced stimulus as different from the background stimulus the sucking rate will show an increase. The sucking-rate and the head-turn method are some of the more traditional, behavioral methods for studying speech perception. Among the new methods (see Research methods below) that help us to study speech perception, near-infrared spectroscopy is widely used in infants.
Cross-language and second-language speech perception
A large amount of research has studied how users of a language perceive foreignForeign language
A foreign language is a language indigenous to another country. It is also a language not spoken in the native country of the person referred to, i.e. an English speaker living in Japan can say that Japanese is a foreign language to him or her...
speech (referred to as cross-language speech perception) or second-language
Second language
A second language or L2 is any language learned after the first language or mother tongue. Some languages, often called auxiliary languages, are used primarily as second languages or lingua francas ....
speech (second-language speech perception). The latter falls within the domain of second language acquisition
Second language acquisition
Second-language acquisition or second-language learning is the process by which people learn a second language. Second-language acquisition is also the name of the scientific discipline devoted to studying that process...
.
Languages differ in their phonemic inventories. Naturally, this creates difficulties when a foreign language is encountered. For example, if two foreign-language sounds are assimilated to a single mother-tongue category the difference between them will be very difficult to discern. A classic example of this situation is the observation that Japanese learners of English will have problems with identifying or distinguishing English liquid consonant
Liquid consonant
In phonetics, liquids or liquid consonants are a class of consonants consisting of lateral consonants together with rhotics.-Description:...
s /l/ and /r/.
Best (1995) proposed a Perceptual Assimilation Model which describes possible cross-language category assimilation patterns and predicts their consequences. Flege (1995) formulated a Speech Learning Model which combines several hypotheses about second-language (L2) speech acquisition and which predicts, in simple words, that an L2 sound that is not too similar to a native-language (L1) sound will be easier to acquire than an L2 sound that is relatively similar to an L1 sound (because it will be perceived as more obviously "different" by the learner).
Speech perception in language or hearing impairment
Research in how people with language or hearing impairment perceive speech is not only intended to discover possible treatments. It can provide insight into what principles underlie non-impaired speech perception. Two areas of research can serve as an example:- Listeners with aphasia. AphasiaAphasiaAphasia is an impairment of language ability. This class of language disorder ranges from having difficulty remembering words to being completely unable to speak, read, or write....
affects both the expression and reception of language. Both two most common types, Broca's and Wernike's aphasiaReceptive aphasiaReceptive aphasia, also known as Wernicke’s aphasia, fluent aphasia, or sensory aphasia, is a type of aphasia traditionally associated with neurological damage to Wernicke’s area in the brain,...
, affect speech perception to some extent. Broca's aphasia causes moderate difficulties for language understanding. The effect of Wernike's aphasia on understanding is much more severe. It is agreed upon, that aphasics suffer from perceptual deficits. They are usually unable to fully distinguish place of articulation and voicing. As for other features, the difficulties vary. It has not yet been proven whether low-level speech-perception skills are affected in aphasia sufferers or whether their difficulties are caused by higher-level impairment alone.
- Listeners with cochlear implants. Cochlear implantCochlear implantA cochlear implant is a surgically implanted electronic device that provides a sense of sound to a person who is profoundly deaf or severely hard of hearing...
ation restores access to the acoustic signal in individuals with sensorineural hearing loss. The acoustic information conveyed by an implant is usually sufficient for implant users to properly recognize speech of people they know even without visual clues. For cochlear implant users, it is more difficult to understand unknown speakers and sounds. The perceptual abilities of children that received an implant after the age of two are significantly better than of those who were implanted in adulthood. A number of factors have been shown to influence perceptual performance. These are especially duration of deafness prior to implantation, age of onset of deafness, age at implantation (such age affects may be related to the Critical period hypothesisCritical Period HypothesisThe critical period hypothesis is the subject of a long-standing debate in linguistics and language acquisition over the extent to which the ability to acquire language is biologically linked to age...
) and the duration of using an implant. There are differences between children with congenital and acquired deafness. Postlingually deaf children have better results than the prelingually deaf and adapt to a cochlear implant faster.
Noise
One of the basic problems in the study of speech is how to deal with the noise in the speech signal. This is shown by the difficulty that computer speech recognitionSpeech recognition
Speech recognition converts spoken words to text. The term "voice recognition" is sometimes used to refer to recognition systems that must be trained to a particular speaker—as is the case for most desktop recognition software...
systems have with recognizing human speech. These programs can do well at recognizing speech when they have been trained on a specific speaker's voice, and under quiet conditions. However, these systems often do poorly in more realistic listening situations where humans are able to understand speech without difficulty.
Music-Language Connection
Research into the relationship between music and cognition is an emerging field related to the study of speech perception. Originally it was theorized that the neural signals for music were processed in a specialized "module" in the right hemisphere of the brain. Conversely, the neural signals for language were to be processed by a similar "module" in the left hemisphere. However, utilizing technologies such as fMRI machines, research has shown that two regions of the brain traditionally considered exclusively to process speech, Broca's and Wernicke's areas, also become active during musical activities such as listening to a sequence of musical chords. Other studies, such as one performed by Marques et al. in 2006 showed that 8-year-olds that were given six months of musical training showed an increase in both their pitch detection performance as well as in their electrophysiological measures when made to listen to an unknown foreign languageConversely, some research has revealed that, rather than music affecting our perception of speech, our native speech can affect our perception of music. One example is the tritone paradox
Tritone paradox
The tritone paradox is an auditory illusion in which a sequentially played pair of Shepard tones separated by an interval of a tritone, or half octave, is heard as ascending by some people and as descending by others. Different populations tend to favor one of a limited set of different spots...
. The tritone paradox is where a listener is presented with two computer-generated tones (such as C and C-Sharp) that are half an octave (or a tritone) apart and are then asked to determine whether the pitch of the sequence is descending or ascending. One such study, performed by Ms. Diana Deutsch, found that the listeners interpretation of ascending or descending pitch was influenced by the listeners language or dialect, showing variation between those raised in the south of England and those in California or from those in Vietnam and those in California whose native language was English. A second study, performed in 2006 on a group of English speakers and 3 groups of East Asian students at University of Southern California, discovered that English speakers who had begun musical training at or before age 5 had a 8% chance of having perfect pitch. For the East Asian students that were fluent in their native tone language, 92 percent of the students had perfect pitch.
Research methods
The methods used in speech perception research can be roughly divided into three groups: behavioral, computational, and, more recently, neurophysiological methods. Behavioral experiments are based on an active role of a participant, i.e. subjects are presented with stimuli and asked to make conscious decisions about them. This can take the form of an identification test, a discrimination test, similarity rating, etc. These types of experiments help to provide a basic description of how listeners perceive and categorize speech sounds.Computational modeling has also been used to simulate how speech may be processed by the brain to produce behaviors that are observed. Computer models have been used to address several questions in speech perception, including how the sound signal itself is processed to extract the acoustic cues used in speech, as well as how speech information is used for higher-level processes, such as word recognition.
Neurophysiological methods rely on utilizing information stemming from more direct and not necessarily conscious (pre-attentative) processes. Subjects are presented with speech stimuli in different types of tasks and the responses of the brain are measured. The brain itself can be more sensitive than it appears to be through behavioral responses. For example, the subject may not show sensitivity to the difference between two speech sounds in a discrimination test, but brain responses may reveal sensitivity to these differences. Methods used to measure neural responses to speech include event-related potential
Event-related potential
An event-related potential is any measured brain response that is directly the result of a thought or perception. More formally, it is any stereotyped electrophysiological response to an internal or external stimulus....
s, magnetoencephalography
Magnetoencephalography
Magnetoencephalography is a technique for mapping brain activity by recording magnetic fields produced by electrical currents occurring naturally in the brain, using arrays of SQUIDs...
, and near infrared spectroscopy
Near infrared spectroscopy
Near-infrared spectroscopy is a spectroscopic method that uses the near-infrared region of the electromagnetic spectrum...
. One important response used with event-related potential
Event-related potential
An event-related potential is any measured brain response that is directly the result of a thought or perception. More formally, it is any stereotyped electrophysiological response to an internal or external stimulus....
s is the mismatch negativity
Mismatch negativity
The mismatch negativity or mismatch field is a component of the event-related potential to an odd stimulus in a sequence of stimuli. It arises from electrical activity in the brain and is studied within the field of cognitive neuroscience and psychology. It can occur in any sensory system, but...
, which occurs when speech stimuli are acoustically different from a stimulus that the subject heard previously.
Neurophysiological methods were introduced into speech perception research for several reasons:
Behavioral responses may reflect late, conscious processes and be affected by other systems such as orthography, and thus they may mask speaker’s ability to recognize sounds based on lower-level acoustic distributions.
Without the necessity of taking an active part in the test, even infants can be tested; this feature is crucial in research into acquisition processes. The possibility to observe low-level auditory processes independently from the higher-level ones makes it possible to address long-standing theoretical issues such as whether or not humans possess a specialized module for perceiving speech or whether or not some complex acoustic invariance (see lack of invariance above) underlies the recognition of a speech sound.
Theories
Research into speech perception (SP) has by no means explained every aspect of the processes involved. A lot of what has been said about SP is a matter of theory. Several theories have been devised to develop some of the above mentioned and other unclear issues. Not all of them give satisfactory explanations of all problems, however the research they inspired has yielded a lot of useful data.Motor theory
Some of the earliest work in the study of how humans perceive speech sounds was conducted by Alvin LibermanAlvin Liberman
Alvin Meyer Liberman was an American psychologist whose ideas set the agenda for fifty years of research in the psychology of speech perception and laid the groundwork for modern computer speech synthesis and the understanding of critical issues in cognitive science...
and his colleagues at Haskins Laboratories
Haskins Laboratories
Haskins Laboratories is an independent, international, multidisciplinary community of researchers conducting basic research on spoken and written language. Founded in 1935 and located in New Haven, Connecticut since 1970, Haskins Laboratories is a private, non-profit research institute with a...
. Using a speech synthesizer, they constructed speech sounds that varied in place of articulation
Place of articulation
In articulatory phonetics, the place of articulation of a consonant is the point of contact where an obstruction occurs in the vocal tract between an articulatory gesture, an active articulator , and a passive location...
along a continuum from /bɑ/ to /dɑ/ to /ɡɑ/. Listeners were asked to identify which sound they heard and to discriminate between two different sounds. The results of the experiment showed that listeners grouped sounds into discrete categories, even though the sounds they were hearing were varying continuously. Based on these results, they proposed the notion of categorical perception
Categorical perception
Categorical perception is the experience of percept invariances in sensory phenomena that can be varied along a continuum. Multiple views of a face, for example, are mapped onto a common identity, visually distinct objects such as cars are mapped into the same category and distinct speech tokens...
as a mechanism by which humans are able to identify speech sounds.
More recent research using different tasks and methodologies suggests that listeners are highly sensitive to acoustic differences within a single phonetic category, contrary to a strict categorical account of speech perception.
In order to provide a theoretical account of the categorical perception
Categorical perception
Categorical perception is the experience of percept invariances in sensory phenomena that can be varied along a continuum. Multiple views of a face, for example, are mapped onto a common identity, visually distinct objects such as cars are mapped into the same category and distinct speech tokens...
data, Liberman and colleagues worked out the motor theory of speech perception, where "the complicated articulatory encoding was assumed to be decoded in the perception of speech by the same processes that are involved in production" (this is referred to as analysis-by-synthesis). For instance, the English consonant /d/ may vary in its acoustic details across different phonetic contexts (see above), yet all /d/'s as perceived by a listener fall within one category (voiced alveolar stop) and that is because "lingustic representations are abstract, canonical, phonetic segments or the gestures that underlie these segments." When describing units of perception, Liberman later abandoned articulatory movements and proceeded to the neural commands to the articulators and even later to intended articulatory gestures, thus "the neural representation of the utterance that determines the speaker's production is the distal object the lister perceives". The theory is closely related to the modularity
Modularity of mind
Modularity of mind is the notion that a mind may, at least in part, be composed of separate innate structures which have established evolutionarily developed functional purposes...
hypothesis, which proposes the existence of a special-purpose module, which is supposed to be innate and probably human-specific.
The theory has been criticized in terms of not being able to "provide an account of just how acoustic signals are translated into intended gestures" by listeners. Furthermore, it is unclear how indexical information (e.g. talker-identity) is encoded/decoded along with linguistically relevant information.
Direct realist theory
The direct realist theory of speech perception (mostly associated with Carol FowlerCarol Fowler
Carol A. Fowler is an American experimental psychologist. She was a former President and Director of Research at Haskins Laboratories in New Haven, Connecticut from 1992 to 2008. She is also a Professor of Psychology at the University of Connecticut and an Adjunct Professor of Linguistics and...
) is a part of the more general theory of direct realism, which postulates that perception allows us to have direct awareness of the world because it involves direct recovery of the distal source of the event that is perceived. For speech perception, the theory asserts that the objects of perception are actual vocal tract movements, or gestures, and not abstract phonemes or (as in the Motor Theory) events that are causally antecedent to these movements, i.e. intended gestures. Listeners perceive gestures not by means of a specialized decoder (as in the Motor Theory) but because information in the acoustic signal specifies the gestures that form it. By claiming that the actual articulatory gestures that produce different speech sounds are themselves the units of speech perception, the theory bypasses the problem of lack of invariance.
Fuzzy-logical model
The fuzzy logical theory of speech perception developed by Dominic MassaroDominic W. Massaro
Dominic W. Massaro is Professor of Psychology and Computer Engineering at the University of California, Santa Cruz. He is best known for his fuzzy logical model of perception, and more recently, for his development of the computer animated talking head Baldi...
proposes that people remember speech sounds in a probabilistic, or graded, way. It suggests that people remember descriptions of the perceptual units of language, called prototypes. Within each prototype various features may combine. However, features are not just binary (true or false), there is a fuzzy
Fuzzy logic
Fuzzy logic is a form of many-valued logic; it deals with reasoning that is approximate rather than fixed and exact. In contrast with traditional logic theory, where binary sets have two-valued logic: true or false, fuzzy logic variables may have a truth value that ranges in degree between 0 and 1...
value corresponding to how likely it is that a sound belongs to a particular speech category. Thus, when perceiving a speech signal our decision about what we actually hear is based on the relative goodness of the match between the stimulus information and values of particular prototypes. The final decision is based on multiple features or sources of information, even visual information (this explains the McGurk effect
McGurk effect
The McGurk effect is a perceptual phenomenon which demonstrates an interaction between hearing and vision in speech perception. "It is a compelling illusion in which humans perceive mismatched audiovisual speech as a completely different syllable". The visual information a person gets from seeing a...
). Computer models of the fuzzy logical theory have been used to demonstrate that the theory's predictions of how speech sounds are categorized correspond to the behavior of human listeners.
Acoustic landmarks and distinctive features
In addition to the proposals of Motor Theory and Direct Realism about the relation between phonological features and articulatory gestures, Kenneth N. StevensKenneth N. Stevens
Kenneth N. Stevens is Clarence J. LeBel Professor of Electrical Engineering and Computer Science, and Professor of Health Sciences and Technology at MIT. Stevens heads the Speech Communication Group in MIT's Research Laboratory of Electronics , and is one of the world's leading scientists in...
proposed another kind of relation: between phonological features and auditory properties. According to this view, listeners are inspecting the incoming signal for the so-called acoustic landmarks which are particular events in the spectrum carrying information about gestures which produced them. Since these gestures are limited by the capacities of humans' articulators and listeners are sensitive to their auditory correlates, the lack of invariance simply does not exist in this model. The acoustic properties of the landmarks constitute the basis for establishing the distinctive features. Bundles of them uniquely specify phonetic segments (phonemes, syllables, words).
Exemplar theory
Exemplar models of speech perception differ from the four theories mentioned above which suppose that there is no connection between word- and talker-recognition and that the variation across talkers is "noise" to be filtered out.The exemplar-based approaches claim listeners store information for word- as well as talker-recognition. According to this theory, particular instances of speech sounds are stored in the memory of a listener. In the process of speech perception, the remembered instances of e.g. a syllable stored in the listener's memory are compared with the incoming stimulus so that the stimulus can be categorized. Similarly, when recognizing a talker, all the memory traces of utterances produced by that talker are activated and the talker's identity is determined. Supporting this theory are several experiments reported by Johnson that suggest that our signal identification is more accurate when we are familiar with the talker or when we have visual representation of the talker's gender. When the talker is unpredictable or the sex misidentified, the error rate in word-identification is much higher.
The exemplar models have to face several objections, two of which are (1) insufficient memory capacity to store every utterance ever heard and, concerning the ability to produce what was heard, (2) whether also the talker's own articulatory gestures are stored or computed when producing utterances that would sound as the auditory memories.