

Speedup
Encyclopedia
In parallel computing
, speedup refers to how much a parallel algorithm
is faster than a corresponding sequential algorithm
.
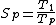
where:
Linear speedup or ideal speedup is obtained when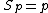 . When running an algorithm with linear speedup, doubling the number of processors doubles the speed. As this is ideal, it is considered very good scalability
. When running an algorithm with linear speedup, doubling the number of processors doubles the speed. As this is ideal, it is considered very good scalability
.
Efficiency is a performance metric defined as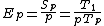 .
.
It is a value, typically between zero and one, estimating how well-utilized the processors are in solving the problem, compared to how much effort is wasted in communication and synchronization. Algorithms with linear speedup and algorithms running on a single processor have an efficiency of 1, while many difficult-to-parallelize algorithms have efficiency such as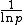 that approaches zero as the number of processors increases.
that approaches zero as the number of processors increases.
When attempting to understand parallel performance, efficiency is generally a better metric to plot than speedup, since
Engineers therefore tend to prefer it. On the other hand, marketing people prefer speedup curves because they go up and to the right.
, which is called super linear speedup. Super linear speedup rarely happens and often confuses beginners, who believe the theoretical maximum speedup should be p when p processors are used.
One possible reason for a super linear speedup is the cache
effect resulting from the different memory hierarchies
of a modern computer: In parallel computing, not only do the numbers of processors change, but so does the size of accumulated caches from different processors. With the larger accumulated cache size, more or even all of the core data set can fit into caches and the memory access time reduces dramatically, which causes the extra speedup in addition to that from the actual computation.
An analogous situation occurs when searching large datasets, such as the genomic data searched by BLAST
implementations. There the accumulated RAM from each of the nodes in a cluster enables the dataset to move from disk into RAM thereby drastically reducing the time required by e.g. mpiBLAST to search it.
Super linear speedups can also occur when performing backtracking
in parallel: One thread can prune a branch of the exhaustive search that another thread would have taken otherwise.
Parallel computing
Parallel computing is a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently . There are several different forms of parallel computing: bit-level,...
, speedup refers to how much a parallel algorithm
Parallel algorithm
In computer science, a parallel algorithm or concurrent algorithm, as opposed to a traditional sequential algorithm, is an algorithm which can be executed a piece at a time on many different processing devices, and then put back together again at the end to get the correct result.Some algorithms...
is faster than a corresponding sequential algorithm
Algorithm
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
.
Definition
Speedup is defined by the following formula:where:
- p is the number of processorCentral processing unitThe central processing unit is the portion of a computer system that carries out the instructions of a computer program, to perform the basic arithmetical, logical, and input/output operations of the system. The CPU plays a role somewhat analogous to the brain in the computer. The term has been in...
s 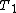 is the execution time of the sequential algorithmAlgorithmIn mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
is the execution time of the sequential algorithmAlgorithmIn mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...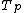 is the execution time of the parallel algorithmParallel algorithmIn computer science, a parallel algorithm or concurrent algorithm, as opposed to a traditional sequential algorithm, is an algorithm which can be executed a piece at a time on many different processing devices, and then put back together again at the end to get the correct result.Some algorithms...
is the execution time of the parallel algorithmParallel algorithmIn computer science, a parallel algorithm or concurrent algorithm, as opposed to a traditional sequential algorithm, is an algorithm which can be executed a piece at a time on many different processing devices, and then put back together again at the end to get the correct result.Some algorithms...
with p processorCentral processing unitThe central processing unit is the portion of a computer system that carries out the instructions of a computer program, to perform the basic arithmetical, logical, and input/output operations of the system. The CPU plays a role somewhat analogous to the brain in the computer. The term has been in...
s
Linear speedup or ideal speedup is obtained when
. When running an algorithm with linear speedup, doubling the number of processors doubles the speed. As this is ideal, it is considered very good scalabilityScalability
In electronics scalability is the ability of a system, network, or process, to handle growing amount of work in a graceful manner or its ability to be enlarged to accommodate that growth...
.
Efficiency is a performance metric defined as
.It is a value, typically between zero and one, estimating how well-utilized the processors are in solving the problem, compared to how much effort is wasted in communication and synchronization. Algorithms with linear speedup and algorithms running on a single processor have an efficiency of 1, while many difficult-to-parallelize algorithms have efficiency such as
that approaches zero as the number of processors increases.When attempting to understand parallel performance, efficiency is generally a better metric to plot than speedup, since
- all of the area in the graph is useful (whereas in a speedup curve 1/2 of the space is wasted)
- it is easy to see how well parallelization is working
- there is no need to plot a "perfect speedup" line
Engineers therefore tend to prefer it. On the other hand, marketing people prefer speedup curves because they go up and to the right.
Super linear speedup
Sometimes a speedup of more than p when using p processors is observed in parallel computingParallel computing
Parallel computing is a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently . There are several different forms of parallel computing: bit-level,...
, which is called super linear speedup. Super linear speedup rarely happens and often confuses beginners, who believe the theoretical maximum speedup should be p when p processors are used.
One possible reason for a super linear speedup is the cache
CPU cache
A CPU cache is a cache used by the central processing unit of a computer to reduce the average time to access memory. The cache is a smaller, faster memory which stores copies of the data from the most frequently used main memory locations...
effect resulting from the different memory hierarchies
Memory hierarchy
The term memory hierarchy is used in the theory of computation when discussing performance issues in computer architectural design, algorithm predictions, and the lower level programming constructs such as involving locality of reference. A 'memory hierarchy' in computer storage distinguishes each...
of a modern computer: In parallel computing, not only do the numbers of processors change, but so does the size of accumulated caches from different processors. With the larger accumulated cache size, more or even all of the core data set can fit into caches and the memory access time reduces dramatically, which causes the extra speedup in addition to that from the actual computation.
An analogous situation occurs when searching large datasets, such as the genomic data searched by BLAST
BLAST
In bioinformatics, Basic Local Alignment Search Tool, or BLAST, is an algorithm for comparing primary biological sequence information, such as the amino-acid sequences of different proteins or the nucleotides of DNA sequences...
implementations. There the accumulated RAM from each of the nodes in a cluster enables the dataset to move from disk into RAM thereby drastically reducing the time required by e.g. mpiBLAST to search it.
Super linear speedups can also occur when performing backtracking
Backtracking
Backtracking is a general algorithm for finding all solutions to some computational problem, that incrementally builds candidates to the solutions, and abandons each partial candidate c as soon as it determines that c cannot possibly be completed to a valid solution.The classic textbook example...
in parallel: One thread can prune a branch of the exhaustive search that another thread would have taken otherwise.
See also
- Amdahl's lawAmdahl's lawAmdahl's law, also known as Amdahl's argument, is named after computer architect Gene Amdahl, and is used to find the maximum expected improvement to an overall system when only part of the system is improved...
- Gustafson's lawGustafson's lawGustafson's Law is a law in computer science which says that problems with large, repetitive data sets can be efficiently parallelized. Gustafson's Law contradicts Amdahl's law, which describes a limit on the speed-up that parallelization can provide. Gustafson's law was first described by John...
- Karp-Flatt MetricKarp-Flatt metricThe Karp–Flatt metric is a measure of parallelization of code in parallel processor systems. This metric exists in addition to Amdahl's law and the Gustafson's law as an indication of the extent to which a particular computer code is parallelized. It was proposed by Alan H. Karp and Horace P...
- ScalabilityScalabilityIn electronics scalability is the ability of a system, network, or process, to handle growing amount of work in a graceful manner or its ability to be enlarged to accommodate that growth...
- Brooks's law