

String Kernel
Encyclopedia
A string kernel
is a mathematical tool used in large scale data analysis
and mining
,
where sequence data are to be clustered or classified (concerning especially the popular research fields of text
and gene analysis
). Kernels are often used in with support vector machines to transform data from its original space
to one where it can be more easily separated and grouped. This may enable non-linear classification.
For many applications, it might be sufficient to find some keywords which match exactly.
One example where exact matching is not always enough is found in spam
detection; another would be in computational gene analysis, where homologous genes
have mutated,
resulting in common subsequences along with deleted, inserted or replaced symbols.
methods (for example support vector machines) are designed to work on vectors
(i.e. data are elements of a vector space), using a string kernel allows the extension of these methods to handle sequence data.
The string kernel method is to be contrasted with earlier approaches for text classification where feature vectors only indicated
the presence or absence of a word.
Not only does it improve on these approaches, but it is an example for a whole class of kernels adapted to data structures, which
began to appear at the turn of the 21st century. A survey of such methods has been compiled by Gärtner.
on a domain is a function
is a function 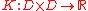
satisfying some conditions (being symmetric in the arguments, continuous
and positive semidefinite in a certain sense).
Mercer's theorem
asserts that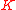 can then be expressed as
can then be expressed as 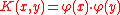 with
with  mapping the arguments into an inner product space
mapping the arguments into an inner product space
.
We can now reproduce the definition of a string subsequence kernel
on strings over an alphabet . Coordinate-wise, the mapping is defined as follows:
. Coordinate-wise, the mapping is defined as follows:
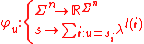
The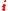 are multiindices and
are multiindices and  is a string of length
is a string of length  :
:
subsequences can occur in a non-contiguous manner, but gaps are penalized.
The parameter may be set to any value between
may be set to any value between  (gaps are not allowed) and
(gaps are not allowed) and 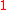
(even widely-spread "occurrences" are weighted the same as appearances as a contiguous substring).
For several relevant algorithms, data enters into the algorithm only in expressions involving an inner product of feature vectors,
hence the name kernel methods
. A desirable consequence of this is that one does not need to explicitly calculate the transformation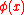 , only the inner product via the kernel, which may be a lot quicker, especially when approximated
, only the inner product via the kernel, which may be a lot quicker, especially when approximated
.
Kernel trick
For machine learning algorithms, the kernel trick is a way of mapping observations from a general set S into an inner product space V , without ever having to compute the mapping explicitly, in the hope that the observations will gain meaningful linear structure in V...
is a mathematical tool used in large scale data analysis
Data analysis
Analysis of data is a process of inspecting, cleaning, transforming, and modeling data with the goal of highlighting useful information, suggesting conclusions, and supporting decision making...
and mining
Data mining
Data mining , a relatively young and interdisciplinary field of computer science is the process of discovering new patterns from large data sets involving methods at the intersection of artificial intelligence, machine learning, statistics and database systems...
,
where sequence data are to be clustered or classified (concerning especially the popular research fields of text
Text mining
Text mining, sometimes alternately referred to as text data mining, roughly equivalent to text analytics, refers to the process of deriving high-quality information from text. High-quality information is typically derived through the devising of patterns and trends through means such as...
and gene analysis
Bioinformatics
Bioinformatics is the application of computer science and information technology to the field of biology and medicine. Bioinformatics deals with algorithms, databases and information systems, web technologies, artificial intelligence and soft computing, information and computation theory, software...
). Kernels are often used in with support vector machines to transform data from its original space
Vector space
A vector space is a mathematical structure formed by a collection of vectors: objects that may be added together and multiplied by numbers, called scalars in this context. Scalars are often taken to be real numbers, but one may also consider vector spaces with scalar multiplication by complex...
to one where it can be more easily separated and grouped. This may enable non-linear classification.
Informal Introduction
Suppose one wants to compare some text passages automatically and indicate their relative similarity.For many applications, it might be sufficient to find some keywords which match exactly.
One example where exact matching is not always enough is found in spam
Spam (electronic)
Spam is the use of electronic messaging systems to send unsolicited bulk messages indiscriminately...
detection; another would be in computational gene analysis, where homologous genes
Gênes
Gênes is the name of a département of the First French Empire in present Italy, named after the city of Genoa. It was formed in 1805, when Napoleon Bonaparte occupied the Republic of Genoa. Its capital was Genoa, and it was divided in the arrondissements of Genoa, Bobbio, Novi Ligure, Tortona and...
have mutated,
resulting in common subsequences along with deleted, inserted or replaced symbols.
Motivation
Since several well-proven data clustering, classification and information retrievalmethods (for example support vector machines) are designed to work on vectors
(i.e. data are elements of a vector space), using a string kernel allows the extension of these methods to handle sequence data.
The string kernel method is to be contrasted with earlier approaches for text classification where feature vectors only indicated
the presence or absence of a word.
Not only does it improve on these approaches, but it is an example for a whole class of kernels adapted to data structures, which
began to appear at the turn of the 21st century. A survey of such methods has been compiled by Gärtner.
Definition
A kernelKernel trick
For machine learning algorithms, the kernel trick is a way of mapping observations from a general set S into an inner product space V , without ever having to compute the mapping explicitly, in the hope that the observations will gain meaningful linear structure in V...
on a domain
is a function satisfying some conditions (being symmetric in the arguments, continuous
Continuous function
In mathematics, a continuous function is a function for which, intuitively, "small" changes in the input result in "small" changes in the output. Otherwise, a function is said to be "discontinuous". A continuous function with a continuous inverse function is called "bicontinuous".Continuity of...
and positive semidefinite in a certain sense).
Mercer's theorem
Mercer's theorem
In mathematics, specifically functional analysis, Mercer's theorem is a representation of a symmetric positive-definite function on a square as a sum of a convergent sequence of product functions. This theorem, presented in , is one of the most notable results of the work of James Mercer...
asserts that
can then be expressed as with mapping the arguments into an inner product spaceInner product space
In mathematics, an inner product space is a vector space with an additional structure called an inner product. This additional structure associates each pair of vectors in the space with a scalar quantity known as the inner product of the vectors...
.
We can now reproduce the definition of a string subsequence kernel
on strings over an alphabet
. Coordinate-wise, the mapping is defined as follows:The
are multiindices and is a string of length :subsequences can occur in a non-contiguous manner, but gaps are penalized.
The parameter
may be set to any value between (gaps are not allowed) and (even widely-spread "occurrences" are weighted the same as appearances as a contiguous substring).
For several relevant algorithms, data enters into the algorithm only in expressions involving an inner product of feature vectors,
hence the name kernel methods
Kernel methods
In computer science, kernel methods are a class of algorithms for pattern analysis, whose best known elementis the support vector machine...
. A desirable consequence of this is that one does not need to explicitly calculate the transformation
, only the inner product via the kernel, which may be a lot quicker, especially when approximatedApproximation
An approximation is a representation of something that is not exact, but still close enough to be useful. Although approximation is most often applied to numbers, it is also frequently applied to such things as mathematical functions, shapes, and physical laws.Approximations may be used because...
.