

Unrolled linked list
Encyclopedia
In computer programming, an unrolled linked list is a variation on the linked list
which stores multiple elements in each node. It can drastically increase cache
performance, while decreasing the memory overhead associated with storing list metadata such as reference
s. It is related to the B-tree
.
record
node {
node next // reference to next node in list
int numElements // number of elements in this node, up to maxElements
array elements // an array of numElements elements, with space allocated for maxElements elements
}
Each node holds up to a certain maximum number of elements, typically just large enough so that the node fills a single cache line or a small multiple thereof. A position in the list is indicated by both a reference to the node and a position in the elements array. It is also possible to include a previous pointer for an unrolled doubly linked list.
To insert a new element, we simply find the node the element should be in and insert the element into the
To remove an element, similarly, we simply find the node it is in and delete it from the
Then, the space used for n elements varies between and
and 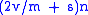 . For comparison, ordinary linked lists require
. For comparison, ordinary linked lists require  space, although v may be smaller, and arrays, one of the most compact data structures, require
space, although v may be smaller, and arrays, one of the most compact data structures, require  space. Unrolled linked lists effectively spread the overhead v over a number of elements of the list. Thus, we see the most significant space gain when overhead is large,
space. Unrolled linked lists effectively spread the overhead v over a number of elements of the list. Thus, we see the most significant space gain when overhead is large,
If the elements are particularly small, such as bits, the overhead can be as much as 64 times larger than the data on many machines. Moreover, many popular memory allocators will keep a small amount of metadata for each node allocated, increasing the effective overhead v. Both these make unrolled linked lists more attractive.
Because unrolled linked list nodes each store a count next to the next field, retrieving the kth element of an unrolled linked list (indexing) can be done in n/m + 1 cache misses, up to a factor of m better than ordinary linked lists. Additionally, if the size of each element is small compared to the cache line size, the list can be iterated over in order with fewer cache misses than ordinary linked lists. In either case, operation time still increases linearly with the size of the list.
Linked list
In computer science, a linked list is a data structure consisting of a group of nodes which together represent a sequence. Under the simplest form, each node is composed of a datum and a reference to the next node in the sequence; more complex variants add additional links...
which stores multiple elements in each node. It can drastically increase cache
CPU cache
A CPU cache is a cache used by the central processing unit of a computer to reduce the average time to access memory. The cache is a smaller, faster memory which stores copies of the data from the most frequently used main memory locations...
performance, while decreasing the memory overhead associated with storing list metadata such as reference
Reference
Reference is derived from Middle English referren, from Middle French rèférer, from Latin referre, "to carry back", formed from the prefix re- and ferre, "to bear"...
s. It is related to the B-tree
B-tree
In computer science, a B-tree is a tree data structure that keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree is a generalization of a binary search tree in that a node can have more than two children...
.
Overview
A typical unrolled linked list node looks like this:record
Record (computer science)
In computer science, a record is an instance of a product of primitive data types called a tuple. In C it is the compound data in a struct. Records are among the simplest data structures. A record is a value that contains other values, typically in fixed number and sequence and typically indexed...
node {
node next // reference to next node in list
int numElements // number of elements in this node, up to maxElements
array elements // an array of numElements elements, with space allocated for maxElements elements
}
Each node holds up to a certain maximum number of elements, typically just large enough so that the node fills a single cache line or a small multiple thereof. A position in the list is indicated by both a reference to the node and a position in the elements array. It is also possible to include a previous pointer for an unrolled doubly linked list.
To insert a new element, we simply find the node the element should be in and insert the element into the
elements array, incrementing numElements. If the array is already full, we first insert a new node either preceding or following the current one and move half of the elements in the current node into it.To remove an element, similarly, we simply find the node it is in and delete it from the
elements array, decrementing numElements. If numElements falls below maxElements ÷ 2 then we pull elements from adjacent nodes to fill it back up to this level. If both adjacent nodes are too low, we combine it with one adjacent node and then move some values into the other. This is necessary to avoid wasting space.Performance
One of the primary benefits of unrolled linked lists is decreased storage requirements. All nodes (except at most one) are at least half-full. If many random inserts and deletes are done, the average node will be about three-quarters full, and if inserts and deletes are only done at the beginning and end, almost all nodes will be full. Assume that:- m =
maxElements, the maximum number of elements in eachelementsarray; - v = the overhead per node for references and element counts;
- s = the size of a single element.
Then, the space used for n elements varies between
and . For comparison, ordinary linked lists require space, although v may be smaller, and arrays, one of the most compact data structures, require space. Unrolled linked lists effectively spread the overhead v over a number of elements of the list. Thus, we see the most significant space gain when overhead is large, maxElements is large, or elements are small.If the elements are particularly small, such as bits, the overhead can be as much as 64 times larger than the data on many machines. Moreover, many popular memory allocators will keep a small amount of metadata for each node allocated, increasing the effective overhead v. Both these make unrolled linked lists more attractive.
Because unrolled linked list nodes each store a count next to the next field, retrieving the kth element of an unrolled linked list (indexing) can be done in n/m + 1 cache misses, up to a factor of m better than ordinary linked lists. Additionally, if the size of each element is small compared to the cache line size, the list can be iterated over in order with fewer cache misses than ordinary linked lists. In either case, operation time still increases linearly with the size of the list.
See also
- CDR codingCDR codingIn computer science CDR coding is a compressed data representation for Lisp linked lists. It was developed and patented by the MIT Artificial Intelligence Laboratory, and implemented in computer hardware in a number of Lisp machines derived from the MIT CADR....
, another technique for decreasing overhead and improving cache locality in linked lists similar to unrolled linked lists. - the skip listSkip listA skip list is a data structure for storing a sorted list of items using a hierarchy of linked lists that connect increasingly sparse subsequences of the items...
, a similar variation on the linked list, offers fast lookup and hurts the advantages of linked lists (quick insert/deletion) less than an unrolled linked list - the B-treeB-treeIn computer science, a B-tree is a tree data structure that keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree is a generalization of a binary search tree in that a node can have more than two children...
and T-treeT-treeIn computer science a T-tree is a type of binary treedata structure that is used by main-memory databases, such asDatablitz, eXtremeDB, MySQL Cluster, Oracle TimesTen and MobileLite....
, data structures that are similar to unrolled linked lists in the sense that each of them could be viewed as an "unrolled binary tree" - XOR linked listXOR linked listAn XOR linked list is a data structure used in computer programming. They take advantage of the bitwise exclusive disjunction operation, here denoted by ⊕, to decrease storage requirements for doubly linked lists. An ordinary doubly linked list stores addresses of the previous and next list items...
, a doubly linked list that uses one XORed pointer per node instead of two ordinary pointers. - Hashed array treeHashed array treeIn computer science, a hashed array tree is a dynamic array algorithm published by Edward Sitarski in 1996. Whereas simple dynamic array data structures based on geometric expansion waste linear space, where n is the number of elements in the array, hashed array trees waste only order n1/2...
, where pointers to the chunks of data are held in a higher-level, separate array.