

Bag of words model in computer vision
Encyclopedia
This is an article introducing the "Bag of words model" (BoW) in computer vision
, especially for object categorization. From now, the "BoW" model refers to the BoW model in computer vision unless explicitly declared. This technique is also known as "Bag of Features model".
Before introducing the BoW model, the BoW in natural language processing
(NLP) is briefly reviewed. The BoW in NLP is a popular method for representing documents, which ignores the word orders. For example, "a good book" and "book good a" are the same under this model. The BoW model allows a dictionary-based modeling, and each document looks like a "bag" (thus the order is not considered), which contains some words from the dictionary. Computer vision researchers use a similar idea for image representation (Here an image may refer to a particular object, such as an image of a car). For example, an image can be treated as a document, and features extracted from the image are considered as the "words" (Usually some manipulations are needed, which are described below). The BoW representation serves as the basic element for further processing, such as object categorization.
Based on these two text documents, a dictionary is constructed as:
which has 10 distinct words. And using the indexes of the dictionary, each document is represented by a 10-entry vector:
where each entry of the vectors refers to count of the corresponding entry in the dictionary (This is also the histogram
representation). As we can see, this vector representation does not preserve the order of the words in the original sentences. This kind of representation has several successful applications, for example latent Dirichlet allocation
.
Regular grid is probably the most simple yet effective method for feature detection. In this method, the image is evenly segmented by some horizontal and vertical lines and some local patches are obtained. This method shows very promising results for natural scene categorization. The limitation of this method is that it uses little information of an image itself.
Interest point detectors try to detect salient patches, such as edges, corners and blobs in an image. These salient patches are considered more important than other patches, such as the regions attracting human attentions, which might be more useful for object categorization. Some famous detectors are Harris affine region detector
detector, Lowe’s DoG (Difference of Gaussians
) detector and Kadir Brady saliency detector
.
In addition, researchers also use random sampling and segmentation methods (such as Normalized Cut) for feature detection.
(SIFT). SIFT converts each patch to 128-dimensional vector. After this step, each image is a collection of vectors of the same dimension (128 for SIFT), where the order of different vectors is of no importance.
Thus, each patch in an image is mapped to a certain codeword through the clustering process and the image can be represented by the histogram
of the codewords.
can be used as an evaluation metric.
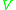 .
.
Since the BoW model is an analogy to the BoW model in NLP, generative models developed in text domains can also be adapted in computer vision. Simple Naïve Bayes model and hierarchical Bayesian models are discussed.
Since the Naïve Bayes classifier is simple yet effective, it is usually used as a baseline method for comparison.
Probabilistic latent semantic analysis
(pLSA) and latent Dirichlet allocation
(LDA) are two popular topic models from text domains to tackle the similar multiple "theme" problem. Take LDA for an example. To model natural scene images using LDA, an analogy is made like this (Figure 9):
This method shows very promising results in natural scene categorization on 13 Natural Scene Categories.
(SVM) and AdaBoost
. Kernel trick
is also applicable when kernel based classifier is used, such as SVM. Pyramid match kernel is newly developed one based on the BoW model. The local feature approach of using BoW model representation learnt by machine learning classifiers with different kernels (e.g., EMD-kernel and kernel) has been vastly tested in the area of texture and object recognition. Very promising results on a number of datasets have been reported.
kernel) has been vastly tested in the area of texture and object recognition. Very promising results on a number of datasets have been reported.
This approach has achieved very impressive result in the the PASCAL Visual Object Classes Challenge
) which maps the BoW features, or set of features in high dimension, to multi-dimensional multi-resolution histograms. One of the advantages of the multi-resolution histograms is the ability to capture the co-occurring features. The pyramid match kernel builds the multi-resolution histograms by binning data points into discrete regions of increasing larger size. Thus, points do not match at high resolutions have the chance to match at low resolutions (Figure 9). Pyramid match kernel performs approximate similarity match, without explicit search without explicit distance computing but do an histogram intersection instead to give an approximation of optimal matching, and the computation time is only linear in the number of features. Compared with other kernel approaches, pyramid match kernel is much faster, yet provides competitively accurate results. Pyramid match kernel was applied to ETH-80 database and Caltech 101 database and showed promising results.
) between the mixture proportion and the BoW features, which captures the spatial relationships among parts in the layer. For discriminative models, spatial pyramid match performs pyramid matching by partitioning the image into increasingly fine sub-regions and compute histograms of local features inside each sub-region.
Furthermore, the BoW model has not been extensively tested yet for view point invariance and scale invariance, and the performance is unclear. Also the BoW model for object segmentation and localization is also lack of study.
Computer vision
Computer vision is a field that includes methods for acquiring, processing, analysing, and understanding images and, in general, high-dimensional data from the real world in order to produce numerical or symbolic information, e.g., in the forms of decisions...
, especially for object categorization. From now, the "BoW" model refers to the BoW model in computer vision unless explicitly declared. This technique is also known as "Bag of Features model".
Before introducing the BoW model, the BoW in natural language processing
Natural language processing
Natural language processing is a field of computer science and linguistics concerned with the interactions between computers and human languages; it began as a branch of artificial intelligence....
(NLP) is briefly reviewed. The BoW in NLP is a popular method for representing documents, which ignores the word orders. For example, "a good book" and "book good a" are the same under this model. The BoW model allows a dictionary-based modeling, and each document looks like a "bag" (thus the order is not considered), which contains some words from the dictionary. Computer vision researchers use a similar idea for image representation (Here an image may refer to a particular object, such as an image of a car). For example, an image can be treated as a document, and features extracted from the image are considered as the "words" (Usually some manipulations are needed, which are described below). The BoW representation serves as the basic element for further processing, such as object categorization.
Text Document Representation based on the BoW model
The text document representation based on the BoW model in NLP is reviewed first. Here are two simple text documents:- John likes to watch movies. Mary likes too.
- John also likes to watch football games.
Based on these two text documents, a dictionary is constructed as:
- dictionary={1:"John", 2:"likes", 3:"to", 4:"watch", 5:"movies", 6:"also", 7:"football", 8:"games", 9:"Mary", 10:"too"},
which has 10 distinct words. And using the indexes of the dictionary, each document is represented by a 10-entry vector:
- [1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
- [1, 1, 1, 1, 0, 1, 1, 1, 0, 0],
where each entry of the vectors refers to count of the corresponding entry in the dictionary (This is also the histogram
Histogram
In statistics, a histogram is a graphical representation showing a visual impression of the distribution of data. It is an estimate of the probability distribution of a continuous variable and was first introduced by Karl Pearson...
representation). As we can see, this vector representation does not preserve the order of the words in the original sentences. This kind of representation has several successful applications, for example latent Dirichlet allocation
Latent Dirichlet allocation
In statistics, latent Dirichlet allocation is a generative model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar...
.
Image Representation based on the BoW model
To represent an image using BoW model, an image can be treated as a document. Similarly, "words" in images need to be defined too. However, "word" in images is not the off-the-shelf thing like the word in text documents. To achieve this, it usually includes following three steps: feature detection, feature description and codebook generation. A definition of the BoW model can be the "histogram representation based on independent features". Content based image indexing and retrieval (CBIR) appears to be the early adopter of this image representation technique.Feature Detection
Given an image, feature detection is to extract several local patches (or regions), which are considered as candidates for basic elements, "words".Regular Grid
Regular grid is probably the most simple yet effective method for feature detection. In this method, the image is evenly segmented by some horizontal and vertical lines and some local patches are obtained. This method shows very promising results for natural scene categorization. The limitation of this method is that it uses little information of an image itself.
Interest Point Detector
Interest point detectors try to detect salient patches, such as edges, corners and blobs in an image. These salient patches are considered more important than other patches, such as the regions attracting human attentions, which might be more useful for object categorization. Some famous detectors are Harris affine region detector
Harris affine region detector
In the fields of computer vision and image analysis, the Harris affine region detector belongs to the category of feature detection. Feature detection is a preprocessing step of several algorithms that rely on identifying characteristic points or interest points so to make correspondences between...
detector, Lowe’s DoG (Difference of Gaussians
Difference of Gaussians
In computer vision, Difference of Gaussians is a grayscale image enhancement algorithm that involves the subtraction of one blurred version of an original grayscale image from another, less blurred version of the original. The blurred images are obtained by convolving the original grayscale image...
) detector and Kadir Brady saliency detector
Kadir brady saliency detector
The Kadir–Brady saliency detector extracts features of objects in images that are distinct and representative. It was invented by Timor Kadir and Michael Brady in 2001 and an affine invariant version was introduced by Kadir and Brady in 2004....
.
Other Methods
In addition, researchers also use random sampling and segmentation methods (such as Normalized Cut) for feature detection.
Feature Representation
After feature detection, each image is abstracted by several local patches. Feature representation methods deal with how to represent the patches as numerical vectors. These methods are called feature descriptors. A good descriptor should have the ability to handle intensity, rotation, scale and affine variations to some extent. One of the most famous descriptors is Scale-invariant feature transformScale-invariant feature transform
Scale-invariant feature transform is an algorithm in computer vision to detect and describe local features in images. The algorithm was published by David Lowe in 1999....
(SIFT). SIFT converts each patch to 128-dimensional vector. After this step, each image is a collection of vectors of the same dimension (128 for SIFT), where the order of different vectors is of no importance.
Codebook Generation
The final step for the BoW model is to convert vector represented patches to "codewords" (analogy to words in text documents), which also produces a "codebook" (analogy to a word dictionary). A codeword can be considered as a representative of several similar patches. One simple method is performing K-means clustering over all the vectors. Codewords are then defined as the centers of the learned clusters. The number of the clusters is the codebook size (analogy to the size of the word dictionary).Thus, each patch in an image is mapped to a certain codeword through the clustering process and the image can be represented by the histogram
Histogram
In statistics, a histogram is a graphical representation showing a visual impression of the distribution of data. It is an estimate of the probability distribution of a continuous variable and was first introduced by Karl Pearson...
of the codewords.
Learning and Recognition based on the BoW model
Computer vision researchers have developed several learning methods to leverage the BoW model for image related task, such as object categorization. These methods can roughly be divided into two categories, generative and discriminative models. For multiple label categorization problem, the confusion matrixConfusion matrix
In the field of artificial intelligence, a confusion matrix is a specific table layout that allows visualization of the performance of an algorithm, typically a supervised learning one . Each column of the matrix represents the instances in a predicted class, while each row represents the...
can be used as an evaluation metric.
Generative Models
Here are some notations for this section. Suppose the size of codebook is.
-
 : each patch
: each patch  is a V-dimensional vector that has a single component that equals to one and all other components equal to zero (For K-means clustering setting, the single component equal one indicates the cluster that
is a V-dimensional vector that has a single component that equals to one and all other components equal to zero (For K-means clustering setting, the single component equal one indicates the cluster that  belongs to). The
belongs to). The  th codeword in the codebook can be represented as
th codeword in the codebook can be represented as 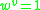 and
and  for
for 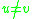 .
. -
 : each image is represented by
: each image is represented by 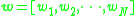 , all the patches in an image.
, all the patches in an image. -
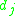 : the
: the 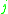 th image in an image collection.
th image in an image collection. -
 : category of the image.
: category of the image. -
 : theme or topic of the patch.
: theme or topic of the patch. -
 : mixture proportion.
: mixture proportion.
Since the BoW model is an analogy to the BoW model in NLP, generative models developed in text domains can also be adapted in computer vision. Simple Naïve Bayes model and hierarchical Bayesian models are discussed.
Naïve Bayes
The simplest one is Naïve Bayes classifier. Using the language of graphical models, the Naïve Bayes classifier is described by the equation below. The basic idea (or assumption) of this model is that each category has its own distribution over the codebooks, and that the distributions of each category are observably different. Take a face category and a car category for an example. The face category may emphasize the codewords which represent "nose", "eye" and "mouth", while the car category may emphasize the codewords which represent "wheel" and "window". Given a collection of training examples, the classifier learns different distributions for different categories. The categorization decision is made by
Since the Naïve Bayes classifier is simple yet effective, it is usually used as a baseline method for comparison.
Hierarchical Bayesian Models
The basic assumption of Naïve Bayes model does not hold sometimes. For example, a natural scene image (Figure 7) may contain several different themes.Probabilistic latent semantic analysis
Probabilistic latent semantic analysis
Probabilistic latent semantic analysis , also known as probabilistic latent semantic indexing is a statistical technique for the analysis of two-mode and co-occurrence data. PLSA evolved from latent semantic analysis, adding a sounder probabilistic model...
(pLSA) and latent Dirichlet allocation
Latent Dirichlet allocation
In statistics, latent Dirichlet allocation is a generative model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar...
(LDA) are two popular topic models from text domains to tackle the similar multiple "theme" problem. Take LDA for an example. To model natural scene images using LDA, an analogy is made like this (Figure 9):
- the image category is mapped to the document category;
- the mixture proportion of themes maps the mixture proportion of topics;
- the theme index is mapped to topic index;
- the codeword is mapped to the word.
This method shows very promising results in natural scene categorization on 13 Natural Scene Categories.
Discriminative Models
Since images are represented based on the BoW model, any discriminative model suitable for text document categorization can be tried, such as support vector machineSupport vector machine
A support vector machine is a concept in statistics and computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis...
(SVM) and AdaBoost
AdaBoost
AdaBoost, short for Adaptive Boosting, is a machine learning algorithm, formulated by Yoav Freund and Robert Schapire. It is a meta-algorithm, and can be used in conjunction with many other learning algorithms to improve their performance. AdaBoost is adaptive in the sense that subsequent...
. Kernel trick
Kernel trick
For machine learning algorithms, the kernel trick is a way of mapping observations from a general set S into an inner product space V , without ever having to compute the mapping explicitly, in the hope that the observations will gain meaningful linear structure in V...
is also applicable when kernel based classifier is used, such as SVM. Pyramid match kernel is newly developed one based on the BoW model. The local feature approach of using BoW model representation learnt by machine learning classifiers with different kernels (e.g., EMD-kernel and
kernel) has been vastly tested in the area of texture and object recognition. Very promising results on a number of datasets have been reported.This approach has achieved very impressive result in the the PASCAL Visual Object Classes Challenge
Pyramid Match Kernel
Pyramid match kernel is a fast algorithm (linear complexity instead of classic one in quadratic complexity) kernel function (satisfying Mercer's conditionMercer's condition
In mathematics, a real-valued function K is said to fulfill Mercer's condition if for all square integrable functions g one has \iint Kgg\,dx dy \geq 0...
) which maps the BoW features, or set of features in high dimension, to multi-dimensional multi-resolution histograms. One of the advantages of the multi-resolution histograms is the ability to capture the co-occurring features. The pyramid match kernel builds the multi-resolution histograms by binning data points into discrete regions of increasing larger size. Thus, points do not match at high resolutions have the chance to match at low resolutions (Figure 9). Pyramid match kernel performs approximate similarity match, without explicit search without explicit distance computing but do an histogram intersection instead to give an approximation of optimal matching, and the computation time is only linear in the number of features. Compared with other kernel approaches, pyramid match kernel is much faster, yet provides competitively accurate results. Pyramid match kernel was applied to ETH-80 database and Caltech 101 database and showed promising results.
Limitations and recent Developments
One of notorious disadvantages of BoW is that it ignores the spatial relationships among the patches, which is very important in image representation. Researchers have proposed several methods to incorporate the spatial information. For feature level improvements, correlogram features can capture spatial co-occurrences of features. For generative models, relative positions of codewords are also taken into account. The hierarchical shape and appearance model for human action introduces a new part layer (Constellation modelConstellation model
The constellation model is a probabilistic, generative model for category-level object recognition in computer vision. Like other part-based models, the constellation model attempts to represent an object class by a set of N parts under mutual geometric constraints...
) between the mixture proportion and the BoW features, which captures the spatial relationships among parts in the layer. For discriminative models, spatial pyramid match performs pyramid matching by partitioning the image into increasingly fine sub-regions and compute histograms of local features inside each sub-region.
Furthermore, the BoW model has not been extensively tested yet for view point invariance and scale invariance, and the performance is unclear. Also the BoW model for object segmentation and localization is also lack of study.
External links
- A demo for two bag-of-words classifiers by L. Fei-Fei, R. Fergus, and A. Torralba.
- Caltech Large Scale Image Search Toolbox: a Matlab/C++ toolbox implementing Inverted File search for Bag of Words model. It also contains implementations for fast approximate nearest neighbor search using randomized Kd-TreeKd-treeIn computer science, a k-d tree is a space-partitioning data structure for organizing points in a k-dimensional space. k-d trees are a useful data structure for several applications, such as searches involving a multidimensional search key...
, Locality Sensitive HashingLocality sensitive hashingLocality-sensitive hashing is a method of performing probabilistic dimension reduction of high-dimensional data. The basic idea is to hash the input items so that similar items are mapped to the same buckets with high probability .-Definition:An LSH family \mathcal F is defined fora...
, and Hierarchical K-Means.
See also
- Part-based modelsPart-based modelsPart based models refers to a broad class of detection algorithms used on images, in which various parts of the image are used separately in order to determine if and where an object of interest exists...
- Segmentation based object categorizationSegmentation based object categorizationThe image segmentation problem is concerned with partitioning an image into multiple regions according to some homogeneity criterion. This article is primarily concerned with graph theoretic approaches to image segmentation....