
Binary classification
Encyclopedia
Binary classification is the task of classifying the members of a given set of objects into two groups on the basis of whether they have some property
or not. Some typical binary classification tasks are
Statistical classification in general is one of the problems studied in computer science
, in order to automatically learn classification systems; some methods suitable for learning binary classifiers include the decision trees
, Bayesian network
s, support vector machine
s, and neural network
s.
Sometimes, classification tasks are trivial. Given 100 balls, some of them red and some blue, a human with normal color vision can easily separate them into red ones and blue ones. However, some tasks, like those in practical medicine, and those interesting from the computer science point-of-view, are far from trivial, and may produce faulty results if executed imprecisely.
, the tester starts with a null hypothesis
and an alternative hypothesis, performs an experiment, and then decides whether to reject the null hypothesis in favour of the alternative. Hypothesis testing is therefore a binary classification of the hypothesis under study.
A positive or statistically significant result is one which rejects the null hypothesis. Doing this when the null hypothesis is in fact true - a false positive - is a type I error; doing this when the null hypothesis is false results in a true positive. A negative or not statistically significant result is one which does not reject the null hypothesis. Doing this when the null hypothesis is in fact false - a false negative - is a type II error; doing this when the null hypothesis is true results in a true negative.
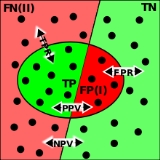
 To measure the performance of a medical test, the concepts sensitivity and specificity are often used; these concepts are readily usable for the evaluation of any binary classifier. Say we test some people for the presence of a disease. Some of these people have the disease, and our test says they are positive. They are called true positives (TP). Some have the disease, but the test claims they don't. They are called false negatives (FN). Some don't have the disease, and the test says they don't - true negatives (TN). Finally, we might have healthy people who have a positive test result - false positives (FP). Thus, the number of true positives, false negatives, true negatives, and false positives add up to 100% of the set.
To measure the performance of a medical test, the concepts sensitivity and specificity are often used; these concepts are readily usable for the evaluation of any binary classifier. Say we test some people for the presence of a disease. Some of these people have the disease, and our test says they are positive. They are called true positives (TP). Some have the disease, but the test claims they don't. They are called false negatives (FN). Some don't have the disease, and the test says they don't - true negatives (TN). Finally, we might have healthy people who have a positive test result - false positives (FP). Thus, the number of true positives, false negatives, true negatives, and false positives add up to 100% of the set.
Specificity (TNR) is the proportion of people that tested negative (TN) of all the people that actually are negative (TN+FP). As with sensitivity, it can be looked at as the probability that the test result is negative given that the patient is not sick. With higher specificity, fewer healthy people are labeled as sick (or, in the factory case, the less money the factory loses by discarding good products instead of selling them).
Sensitivity (TPR) is the proportion of people that tested positive (TP) of all the people that actually are positive (TP+FN). It can be seen as the probability that the test is positive given that the patient is sick. With higher sensitivity, fewer actual cases of disease go undetected (or, in the case of the factory quality control, the fewer faulty products go to the market).
The relationship between sensitivity and specificity, as well as the performance of the classifier, can be visualized and studied using the ROC curve
.
In theory, sensitivity and specificity are independent in the sense that it is possible to achieve 100% in both (such as in the red/blue ball example given above). In more practical, less contrived instances, however, there is usually a trade-off, such that they are inversely proportional to one another to some extent. This is because we rarely measure the actual thing we would like to classify; rather, we generally measure an indicator of the thing we would like to classify, referred to as a surrogate marker
. The reason why 100% is achievable in the ball example is because one measures redness and blueness by detecting redness and blueness. However, indicators are sometimes compromised, such as when non-indicators mimic indicators or when indicators are time-dependent, only becoming evident after a certain lag time. The following example of a pregnancy test will make use of such an indicator.
Modern pregnancy tests do not use the pregnancy itself to determine pregnancy status; rather, they use human chorionic gonadotropin
, or hCG, present in the urine of gravid females, as a surrogate marker to indicate that a woman is pregnant. Because hCG can also be produced by a tumor, the specificity of modern pregnancy tests cannot be 100% (in that false positives are possible). And because hCG is present in the urine in such small concentrations after fertilization and early embryogenesis
, the sensitivity of modern pregnancy tests cannot be 100% (in that false negatives are possible).
In addition to sensitivity and specificity, the performance of a binary classification test can be measured with positive
(PPV) and negative predictive value
s (NPV). The positive prediction value answers the question "If the test result is positive, how well does that predict an actual presence of disease?". It is calculated as (true positives) / (true positives + false positives); that is, it is the proportion of true positives out of all positive results. (The negative prediction value is the same, but for negatives, naturally.)
One should note, though, one important difference between the two concepts. That is, sensitivity and specificity are independent from the population in the sense that they don't change depending on what the proportion of positives and negatives tested are. Indeed, you can determine the sensitivity of the test by testing only positive cases. However, the prediction values are dependent on the population.
Say, however, that of the 2000 people only 100 are really sick. Now you are likely to get 99 true positives, 1 false negative, 1881 true negatives and 19 false positives. Of the 19+99 people tested positive, only 99 really have the disease - that means, intuitively, that given that your test result is positive, there's only 84% chance that you really have the disease. On the other hand, given that your test result is negative, you can really be reassured: there's only 1 chance in 1882, or 0.05% probability, that you have the disease despite your test result.
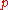 and the probability that they do not is
and the probability that they do not is 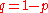 . Suppose then that we have a random classifier that guesses that you have the disease with that same probability
. Suppose then that we have a random classifier that guesses that you have the disease with that same probability 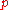 and guesses you do not with the same probability
and guesses you do not with the same probability 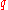 .
.
The probability of a true positive is the probability that you have the disease and the random classifier guesses that you do, or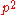 . With similar reasoning, the probability of a false negative is
. With similar reasoning, the probability of a false negative is 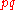 . From the definitions above, the sensitivity of this classifier is
. From the definitions above, the sensitivity of this classifier is  . With more similar reasoning, we can calculate the specificity as
. With more similar reasoning, we can calculate the specificity as  .
.
So, while the measure itself is independent of disease prevalence, the performance of this random classifier depends on disease prevalence. Your classifier may have performance that is like this random classifier, but with a better-weighted coin (higher sensitivity and specificity). So, these measures may be influenced by disease prevalence. An alternative measure of performance is the Matthews correlation coefficient
, for which any random classifier will get an average score of 0.
Tests whose results are of continuous values, such as most blood values, can artificially be made binary by defining a cutoff value, with test results being designated as positive or negative depending on whether the resultant value is higher or lower than the cutoff.
However, such conversion causes a loss of information, as the resultant binary classification does not tell how much above or below the cutoff a value is. As a result, when converting a continuous value that is close to the cutoff to a binary one, the resultant positive
or negative predictive value
is generally higher than the predictive value given directly from the continuous value. In such cases, the designation of the test of being either positive or negative gives the appearance of an inappropriately high certainty, while the value is in fact in an interval of uncertainty. For example, with the urine concentration of hCG
as a continuous value, a urine pregnancy test
that measured 52 mIU/ml of hCG may show as "positive" with 50 mIU/ml as cutoff, but is in fact in an interval of uncertainty, which may be apparent only by knowing the original continuous value. On the other hand, a test result very far from the cutoff generally has a resultant positive or negative predictive value that is lower than the predictive value given from the continuous value. For example, a urine hCG value of 200,000 mIU/ml confers a very high probability of pregnancy, but conversion to binary values results in that it shows just as "positive" as the one of 52 mIU/ml.
Property
Property is any physical or intangible entity that is owned by a person or jointly by a group of people or a legal entity like a corporation...
or not. Some typical binary classification tasks are
- medical testing to determine if a patient has certain disease or not (the classification property is the disease)
- quality control in factories; i.e. deciding if a new product is good enough to be sold, or if it should be discarded (the classification property is being good enough)
- deciding whether a page or an article should be in the result set of a search or not (the classification property is the relevance of the article - typically the presence of a certain word in it)
Statistical classification in general is one of the problems studied in computer science
Computer science
Computer science or computing science is the study of the theoretical foundations of information and computation and of practical techniques for their implementation and application in computer systems...
, in order to automatically learn classification systems; some methods suitable for learning binary classifiers include the decision trees
Decision tree learning
Decision tree learning, used in statistics, data mining and machine learning, uses a decision tree as a predictive model which maps observations about an item to conclusions about the item's target value. More descriptive names for such tree models are classification trees or regression trees...
, Bayesian network
Bayesian network
A Bayesian network, Bayes network, belief network or directed acyclic graphical model is a probabilistic graphical model that represents a set of random variables and their conditional dependencies via a directed acyclic graph . For example, a Bayesian network could represent the probabilistic...
s, support vector machine
Support vector machine
A support vector machine is a concept in statistics and computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis...
s, and neural network
Neural network
The term neural network was traditionally used to refer to a network or circuit of biological neurons. The modern usage of the term often refers to artificial neural networks, which are composed of artificial neurons or nodes...
s.
Sometimes, classification tasks are trivial. Given 100 balls, some of them red and some blue, a human with normal color vision can easily separate them into red ones and blue ones. However, some tasks, like those in practical medicine, and those interesting from the computer science point-of-view, are far from trivial, and may produce faulty results if executed imprecisely.
Hypothesis testing
In traditional statistical hypothesis testingStatistical hypothesis testing
A statistical hypothesis test is a method of making decisions using data, whether from a controlled experiment or an observational study . In statistics, a result is called statistically significant if it is unlikely to have occurred by chance alone, according to a pre-determined threshold...
, the tester starts with a null hypothesis
Null hypothesis
The practice of science involves formulating and testing hypotheses, assertions that are capable of being proven false using a test of observed data. The null hypothesis typically corresponds to a general or default position...
and an alternative hypothesis, performs an experiment, and then decides whether to reject the null hypothesis in favour of the alternative. Hypothesis testing is therefore a binary classification of the hypothesis under study.
A positive or statistically significant result is one which rejects the null hypothesis. Doing this when the null hypothesis is in fact true - a false positive - is a type I error; doing this when the null hypothesis is false results in a true positive. A negative or not statistically significant result is one which does not reject the null hypothesis. Doing this when the null hypothesis is in fact false - a false negative - is a type II error; doing this when the null hypothesis is true results in a true negative.
Evaluation of binary classifiers
- See also: sensitivity and specificitySensitivity and specificitySensitivity and specificity are statistical measures of the performance of a binary classification test, also known in statistics as classification function. Sensitivity measures the proportion of actual positives which are correctly identified as such Sensitivity and specificity are statistical...
Specificity (TNR) is the proportion of people that tested negative (TN) of all the people that actually are negative (TN+FP). As with sensitivity, it can be looked at as the probability that the test result is negative given that the patient is not sick. With higher specificity, fewer healthy people are labeled as sick (or, in the factory case, the less money the factory loses by discarding good products instead of selling them).
Sensitivity (TPR) is the proportion of people that tested positive (TP) of all the people that actually are positive (TP+FN). It can be seen as the probability that the test is positive given that the patient is sick. With higher sensitivity, fewer actual cases of disease go undetected (or, in the case of the factory quality control, the fewer faulty products go to the market).
The relationship between sensitivity and specificity, as well as the performance of the classifier, can be visualized and studied using the ROC curve
Receiver operating characteristic
In signal detection theory, a receiver operating characteristic , or simply ROC curve, is a graphical plot of the sensitivity, or true positive rate, vs. false positive rate , for a binary classifier system as its discrimination threshold is varied...
.
In theory, sensitivity and specificity are independent in the sense that it is possible to achieve 100% in both (such as in the red/blue ball example given above). In more practical, less contrived instances, however, there is usually a trade-off, such that they are inversely proportional to one another to some extent. This is because we rarely measure the actual thing we would like to classify; rather, we generally measure an indicator of the thing we would like to classify, referred to as a surrogate marker
Surrogate endpoint
In clinical trials, a surrogate endpoint is a measure of effect of a certain treatment that may correlate with a real clinical endpoint but doesn't necessarily have a guaranteed relationship...
. The reason why 100% is achievable in the ball example is because one measures redness and blueness by detecting redness and blueness. However, indicators are sometimes compromised, such as when non-indicators mimic indicators or when indicators are time-dependent, only becoming evident after a certain lag time. The following example of a pregnancy test will make use of such an indicator.
Modern pregnancy tests do not use the pregnancy itself to determine pregnancy status; rather, they use human chorionic gonadotropin
Human chorionic gonadotropin
Human chorionic gonadotropin or human chorionic gonadotrophin is a glycoprotein hormone produced during pregnancy that is made by the developing embryo after conception and later by the syncytiotrophoblast .. Some tumors make this hormone; measured elevated levels when the patient is not...
, or hCG, present in the urine of gravid females, as a surrogate marker to indicate that a woman is pregnant. Because hCG can also be produced by a tumor, the specificity of modern pregnancy tests cannot be 100% (in that false positives are possible). And because hCG is present in the urine in such small concentrations after fertilization and early embryogenesis
Embryogenesis
Embryogenesis is the process by which the embryo is formed and develops, until it develops into a fetus.Embryogenesis starts with the fertilization of the ovum by sperm. The fertilized ovum is referred to as a zygote...
, the sensitivity of modern pregnancy tests cannot be 100% (in that false negatives are possible).
In addition to sensitivity and specificity, the performance of a binary classification test can be measured with positive
Positive predictive value
In statistics and diagnostic testing, the positive predictive value, or precision rate is the proportion of subjects with positive test results who are correctly diagnosed. It is a critical measure of the performance of a diagnostic method, as it reflects the probability that a positive test...
(PPV) and negative predictive value
Negative predictive value
In statistics and diagnostic testing, the negative predictive value is a summary statistic used to describe the performance of a diagnostic testing procedure. It is defined as the proportion of subjects with a negative test result who are correctly diagnosed. A high NPV means that when the test...
s (NPV). The positive prediction value answers the question "If the test result is positive, how well does that predict an actual presence of disease?". It is calculated as (true positives) / (true positives + false positives); that is, it is the proportion of true positives out of all positive results. (The negative prediction value is the same, but for negatives, naturally.)
One should note, though, one important difference between the two concepts. That is, sensitivity and specificity are independent from the population in the sense that they don't change depending on what the proportion of positives and negatives tested are. Indeed, you can determine the sensitivity of the test by testing only positive cases. However, the prediction values are dependent on the population.
Example
As an example, say that you have a test for a disease with 99% sensitivity and 99% specificity. Say you test 2000 people, and 1000 of them are sick and 1000 of them are healthy. You are likely to get about 990 true positives, 990 true negatives, and 10 of false positives and negatives each. The positive and negative prediction values would be 99%, so the people can be quite confident about the result.Say, however, that of the 2000 people only 100 are really sick. Now you are likely to get 99 true positives, 1 false negative, 1881 true negatives and 19 false positives. Of the 19+99 people tested positive, only 99 really have the disease - that means, intuitively, that given that your test result is positive, there's only 84% chance that you really have the disease. On the other hand, given that your test result is negative, you can really be reassured: there's only 1 chance in 1882, or 0.05% probability, that you have the disease despite your test result.
Measuring a classifier with sensitivity and specificity
Suppose you are training your own classifier, and you wish to measure its performance using the well-accepted metrics of sensitivity and specificity. It may be instructive to compare your classifier to a random classifier that flips a coin based on the prevalence of a disease. Suppose that the probability a person has the disease is and the probability that they do not is . Suppose then that we have a random classifier that guesses that you have the disease with that same probability and guesses you do not with the same probability .The probability of a true positive is the probability that you have the disease and the random classifier guesses that you do, or
. With similar reasoning, the probability of a false negative is . From the definitions above, the sensitivity of this classifier is . With more similar reasoning, we can calculate the specificity as .So, while the measure itself is independent of disease prevalence, the performance of this random classifier depends on disease prevalence. Your classifier may have performance that is like this random classifier, but with a better-weighted coin (higher sensitivity and specificity). So, these measures may be influenced by disease prevalence. An alternative measure of performance is the Matthews correlation coefficient
Matthews Correlation Coefficient
The Matthews correlation coefficient is used in machine learning as a measure of the quality of binary classifications. It takes into account true and false positives and negatives and is generally regarded as a balanced measure which can be used even if the classes are of very different sizes...
, for which any random classifier will get an average score of 0.
Converting continuous values to binary
Tests whose results are of continuous values, such as most blood values, can artificially be made binary by defining a cutoff value, with test results being designated as positive or negative depending on whether the resultant value is higher or lower than the cutoff.
However, such conversion causes a loss of information, as the resultant binary classification does not tell how much above or below the cutoff a value is. As a result, when converting a continuous value that is close to the cutoff to a binary one, the resultant positive
Positive predictive value
In statistics and diagnostic testing, the positive predictive value, or precision rate is the proportion of subjects with positive test results who are correctly diagnosed. It is a critical measure of the performance of a diagnostic method, as it reflects the probability that a positive test...
or negative predictive value
Negative predictive value
In statistics and diagnostic testing, the negative predictive value is a summary statistic used to describe the performance of a diagnostic testing procedure. It is defined as the proportion of subjects with a negative test result who are correctly diagnosed. A high NPV means that when the test...
is generally higher than the predictive value given directly from the continuous value. In such cases, the designation of the test of being either positive or negative gives the appearance of an inappropriately high certainty, while the value is in fact in an interval of uncertainty. For example, with the urine concentration of hCG
Human chorionic gonadotropin
Human chorionic gonadotropin or human chorionic gonadotrophin is a glycoprotein hormone produced during pregnancy that is made by the developing embryo after conception and later by the syncytiotrophoblast .. Some tumors make this hormone; measured elevated levels when the patient is not...
as a continuous value, a urine pregnancy test
Pregnancy test
A pregnancy test attempts to determine whether or not a woman is pregnant.These markers are found in urine and blood, and pregnancy tests require sampling one of these substances. The first of these markers to be discovered, human chorionic gonadotropin , was discovered in 1930 to be produced by...
that measured 52 mIU/ml of hCG may show as "positive" with 50 mIU/ml as cutoff, but is in fact in an interval of uncertainty, which may be apparent only by knowing the original continuous value. On the other hand, a test result very far from the cutoff generally has a resultant positive or negative predictive value that is lower than the predictive value given from the continuous value. For example, a urine hCG value of 200,000 mIU/ml confers a very high probability of pregnancy, but conversion to binary values results in that it shows just as "positive" as the one of 52 mIU/ml.
See also
- kernel methodsKernel methodsIn computer science, kernel methods are a class of algorithms for pattern analysis, whose best known elementis the support vector machine...
- prosecutor's fallacyProsecutor's fallacyThe prosecutor's fallacy is a fallacy of statistical reasoning made in law where the context in which the accused has been brought to court is falsely assumed to be irrelevant to judging how confident a jury can be in evidence against them with a statistical measure of doubt...
- Examples of Bayesian inference
- Receiver operating characteristicReceiver operating characteristicIn signal detection theory, a receiver operating characteristic , or simply ROC curve, is a graphical plot of the sensitivity, or true positive rate, vs. false positive rate , for a binary classifier system as its discrimination threshold is varied...
- Matthews correlation coefficientMatthews Correlation CoefficientThe Matthews correlation coefficient is used in machine learning as a measure of the quality of binary classifications. It takes into account true and false positives and negatives and is generally regarded as a balanced measure which can be used even if the classes are of very different sizes...
- Classification ruleClassification ruleGiven a population whose members can be potentially separated into a number of different sets or classes, a classification rule is a procedure in which the elements of the population set are each assigned to one of the classes. A perfect test is such that every element in the population is assigned...