

Sensitivity and specificity
Encyclopedia
Sensitivity and specificity are statistical measures of the performance of a binary classification
test
, also known in statistics as classification function. Sensitivity (also called recall rate in some fields) measures the proportion of actual positives which are correctly identified as such (e.g. the percentage of sick people who are correctly identified as having the condition). Specificity measures the proportion of negatives which are correctly identified (e.g. the percentage of healthy people who are correctly identified as not having the condition). These two measures are closely related to the concepts of type I and type II errors
. A theoretical, optimal prediction aims to achieve 100% sensitivity (i.e. predict all people from the sick group as sick) and 100% specificity (i.e. not predict anyone from the healthy group as sick), however theoretically any predictor will possess a minimum error bound known as the Bayes error rate.
For any test, there is usually a trade-off between the measures. For example: in an airport security
setting in which one is testing for potential threats to safety, scanners may be set to trigger on low-risk items like belt buckles and keys (low specificity), in order to reduce the risk of missing objects that do pose a threat to the aircraft and those aboard (high sensitivity). This trade-off can be represented graphically as an ROC curve
.
Again, consider the example of the medical test used to identify a disease. The sensitivity of a test is the proportion of people who have the disease who test positive for it. This can also be written as:

If a test has high sensitivity then a negative result would suggest the absence of disease. For example, a sensitivity of 100% means that the test recognizes all actual positives – i.e. all sick people are recognized as being ill. Thus, in contrast to a high specificity test, negative results in a high sensitivity test are used to rule out the disease.
From a theoretical point of view, a 'bogus' test kit which always indicates positive, regardless of the disease status of the patient, will achieve 100% sensitivity. Therefore the sensitivity alone cannot be used to determine whether a test is useful in practice.
Sensitivity is not the same as the precision
or positive predictive value
(ratio of true positives to combined true and false positives), which is as much a statement about the proportion of actual positives in the population being tested as it is about the test.
The calculation of sensitivity does not take into account indeterminate test results. If a test cannot be repeated, the options are to exclude indeterminate samples from analysis (but the number of exclusions should be stated when quoting sensitivity), or, alternatively, indeterminate samples can be treated as false negatives (which gives the worst-case value for sensitivity and may therefore underestimate it).
A test with a high sensitivity has a low type II error rate.
Consider the example of the medical test used to identify a disease. The specificity of a test is defined as the proportion of patients who do not have the disease who will test negative for it. This can also be written as:
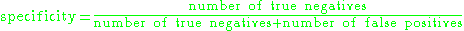
If a test has high specificity, a positive result from the test means a high probability of the presence of disease.
From a theoretical point of view, a 'bogus' test kit which always indicates negative, regardless of the disease status of the patient, will achieve 100% specificity. Therefore the specificity alone cannot be used to determine whether a test is useful in practice.
A test with a high specificity has a low type I error
rate.
If 100 patients known to have a disease were tested, and 43 test positive, then the test has 43% sensitivity. If 100 with no disease are tested and 96 return a negative result, then the test has 96% specificity.
A highly specific test is unlikely to give a false positive result: a positive result should thus be regarded as a true positive. A sign or symptom with very high specificity is often termed pathognomonic
. An example of such a test is the inspection for erythema chronicum migrans
to diagnose lyme disease
. In contrast, a sensitive test rarely misses a condition, so a negative result should be reassuring (the disease tested for is absent). A sign or symptom with very high sensitivity is often termed sine qua non
. An example of such test is a genetic test to find an underlying mutation in certain types of hereditary colon cancer.
SPIN and SNOUT are commonly used mnemonics which says: A highly SPecific test, when Positive, rules IN disease (SP-P-IN), and a highly 'SeNsitive' test, when Negative rules OUT disease (SN-N-OUT).
positive predictive value is called precision, and sensitivity is called recall.
The F-measure can be used as a single measure of performance of the test. The F-measure is the harmonic mean
of precision and recall:
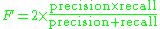
In the traditional language of statistical hypothesis testing
, the sensitivity of a test is called the statistical power
of the test, although the word power in that context has a more general usage that is not applicable in the present context. A sensitive test will have fewer Type II error
s.
Binary classification
Binary classification is the task of classifying the members of a given set of objects into two groups on the basis of whether they have some property or not. Some typical binary classification tasks are...
test
Classification rule
Given a population whose members can be potentially separated into a number of different sets or classes, a classification rule is a procedure in which the elements of the population set are each assigned to one of the classes. A perfect test is such that every element in the population is assigned...
, also known in statistics as classification function. Sensitivity (also called recall rate in some fields) measures the proportion of actual positives which are correctly identified as such (e.g. the percentage of sick people who are correctly identified as having the condition). Specificity measures the proportion of negatives which are correctly identified (e.g. the percentage of healthy people who are correctly identified as not having the condition). These two measures are closely related to the concepts of type I and type II errors
Type I and type II errors
In statistical test theory the notion of statistical error is an integral part of hypothesis testing. The test requires an unambiguous statement of a null hypothesis, which usually corresponds to a default "state of nature", for example "this person is healthy", "this accused is not guilty" or...
. A theoretical, optimal prediction aims to achieve 100% sensitivity (i.e. predict all people from the sick group as sick) and 100% specificity (i.e. not predict anyone from the healthy group as sick), however theoretically any predictor will possess a minimum error bound known as the Bayes error rate.
For any test, there is usually a trade-off between the measures. For example: in an airport security
Airport security
Airport security refers to the techniques and methods used in protecting airports and aircraft from crime.Large numbers of people pass through airports. This presents potential targets for terrorism and other forms of crime due to the number of people located in a particular location...
setting in which one is testing for potential threats to safety, scanners may be set to trigger on low-risk items like belt buckles and keys (low specificity), in order to reduce the risk of missing objects that do pose a threat to the aircraft and those aboard (high sensitivity). This trade-off can be represented graphically as an ROC curve
Receiver operating characteristic
In signal detection theory, a receiver operating characteristic , or simply ROC curve, is a graphical plot of the sensitivity, or true positive rate, vs. false positive rate , for a binary classifier system as its discrimination threshold is varied...
.
Definitions
Imagine a study evaluating a new test that screens people for a disease. Each person taking the test either has or does not have the disease. The test outcome can be positive (predicting that the person has the disease) or negative (predicting that the person does not have the disease). The test results for each subject may or may not match the subject's actual status. In that setting:- True positive: Sick people correctly diagnosed as sick
- False positive: Healthy people incorrectly identified as sick
- True negative: Healthy people correctly identified as healthy
- False negative: Sick people incorrectly identified as healthy.
Sensitivity
Sensitivity relates to the test's ability to identify positive results.Again, consider the example of the medical test used to identify a disease. The sensitivity of a test is the proportion of people who have the disease who test positive for it. This can also be written as:
If a test has high sensitivity then a negative result would suggest the absence of disease. For example, a sensitivity of 100% means that the test recognizes all actual positives – i.e. all sick people are recognized as being ill. Thus, in contrast to a high specificity test, negative results in a high sensitivity test are used to rule out the disease.
From a theoretical point of view, a 'bogus' test kit which always indicates positive, regardless of the disease status of the patient, will achieve 100% sensitivity. Therefore the sensitivity alone cannot be used to determine whether a test is useful in practice.
Sensitivity is not the same as the precision
Precision and recall
In pattern recognition and information retrieval, precision is the fraction of retrieved instances that are relevant, while recall is the fraction of relevant instances that are retrieved. Both precision and recall are therefore based on an understanding and measure of relevance...
or positive predictive value
Positive predictive value
In statistics and diagnostic testing, the positive predictive value, or precision rate is the proportion of subjects with positive test results who are correctly diagnosed. It is a critical measure of the performance of a diagnostic method, as it reflects the probability that a positive test...
(ratio of true positives to combined true and false positives), which is as much a statement about the proportion of actual positives in the population being tested as it is about the test.
The calculation of sensitivity does not take into account indeterminate test results. If a test cannot be repeated, the options are to exclude indeterminate samples from analysis (but the number of exclusions should be stated when quoting sensitivity), or, alternatively, indeterminate samples can be treated as false negatives (which gives the worst-case value for sensitivity and may therefore underestimate it).
A test with a high sensitivity has a low type II error rate.
Specificity
Specificity relates to the ability of the test to identify negative results.Consider the example of the medical test used to identify a disease. The specificity of a test is defined as the proportion of patients who do not have the disease who will test negative for it. This can also be written as:
If a test has high specificity, a positive result from the test means a high probability of the presence of disease.
From a theoretical point of view, a 'bogus' test kit which always indicates negative, regardless of the disease status of the patient, will achieve 100% specificity. Therefore the specificity alone cannot be used to determine whether a test is useful in practice.
A test with a high specificity has a low type I error
Type I and type II errors
In statistical test theory the notion of statistical error is an integral part of hypothesis testing. The test requires an unambiguous statement of a null hypothesis, which usually corresponds to a default "state of nature", for example "this person is healthy", "this accused is not guilty" or...
rate.
Medical examples
In medical diagnostics, test sensitivity is the ability of a test to correctly identify those with the disease (true +ve rate), whereas test specificity is the ability of the test to correctly identify those without the disease (true -ve rate).If 100 patients known to have a disease were tested, and 43 test positive, then the test has 43% sensitivity. If 100 with no disease are tested and 96 return a negative result, then the test has 96% specificity.
A highly specific test is unlikely to give a false positive result: a positive result should thus be regarded as a true positive. A sign or symptom with very high specificity is often termed pathognomonic
Pathognomonic
Pathognomonic is a term, often used in medicine, that means characteristic for a particular disease. A pathognomonic sign is a particular sign whose presence means that a particular disease is present beyond any doubt...
. An example of such a test is the inspection for erythema chronicum migrans
Erythema chronicum migrans
Erythema chronicum migrans refers to the rash often seen in the early stage of Lyme disease. It can appear anywhere from one day to one month after a tick bite. This rash does not represent an allergic reaction to the bite, but rather an actual skin infection with the Lyme bacteria, Borrelia...
to diagnose lyme disease
Lyme disease
Lyme disease, or Lyme borreliosis, is an emerging infectious disease caused by at least three species of bacteria belonging to the genus Borrelia. Borrelia burgdorferi sensu stricto is the main cause of Lyme disease in the United States, whereas Borrelia afzelii and Borrelia garinii cause most...
. In contrast, a sensitive test rarely misses a condition, so a negative result should be reassuring (the disease tested for is absent). A sign or symptom with very high sensitivity is often termed sine qua non
Sine qua non
Sine qua non or condicio sine qua non refers to an indispensable and essential action, condition, or ingredient...
. An example of such test is a genetic test to find an underlying mutation in certain types of hereditary colon cancer.
SPIN and SNOUT are commonly used mnemonics which says: A highly SPecific test, when Positive, rules IN disease (SP-P-IN), and a highly 'SeNsitive' test, when Negative rules OUT disease (SN-N-OUT).
Terminology in information retrieval
In information retrievalInformation retrieval
Information retrieval is the area of study concerned with searching for documents, for information within documents, and for metadata about documents, as well as that of searching structured storage, relational databases, and the World Wide Web...
positive predictive value is called precision, and sensitivity is called recall.
The F-measure can be used as a single measure of performance of the test. The F-measure is the harmonic mean
Harmonic mean
In mathematics, the harmonic mean is one of several kinds of average. Typically, it is appropriate for situations when the average of rates is desired....
of precision and recall:
In the traditional language of statistical hypothesis testing
Statistical hypothesis testing
A statistical hypothesis test is a method of making decisions using data, whether from a controlled experiment or an observational study . In statistics, a result is called statistically significant if it is unlikely to have occurred by chance alone, according to a pre-determined threshold...
, the sensitivity of a test is called the statistical power
Statistical power
The power of a statistical test is the probability that the test will reject the null hypothesis when the null hypothesis is actually false . The power is in general a function of the possible distributions, often determined by a parameter, under the alternative hypothesis...
of the test, although the word power in that context has a more general usage that is not applicable in the present context. A sensitive test will have fewer Type II error
Type I and type II errors
In statistical test theory the notion of statistical error is an integral part of hypothesis testing. The test requires an unambiguous statement of a null hypothesis, which usually corresponds to a default "state of nature", for example "this person is healthy", "this accused is not guilty" or...
s.
See also
true positive (TP)
true negative (TN)
false positive (FP)
false negative (FN)
sensitivity or true positive rate (TPR)
false positive rate (FPR)
accuracy (ACC) 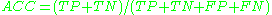 specificity (SPC) or True Negative Rate 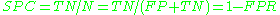 positive predictive value Positive predictive value In statistics and diagnostic testing, the positive predictive value, or precision rate is the proportion of subjects with positive test results who are correctly diagnosed. It is a critical measure of the performance of a diagnostic method, as it reflects the probability that a positive test... (PPV)
negative predictive value Negative predictive value In statistics and diagnostic testing, the negative predictive value is a summary statistic used to describe the performance of a diagnostic testing procedure. It is defined as the proportion of subjects with a negative test result who are correctly diagnosed. A high NPV means that when the test... (NPV) 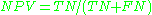 false discovery rate False discovery rate False discovery rate control is a statistical method used in multiple hypothesis testing to correct for multiple comparisons. In a list of rejected hypotheses, FDR controls the expected proportion of incorrectly rejected null hypotheses... (FDR) 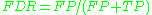 Matthews correlation coefficient Matthews Correlation Coefficient The Matthews correlation coefficient is used in machine learning as a measure of the quality of binary classifications. It takes into account true and false positives and negatives and is generally regarded as a balanced measure which can be used even if the classes are of very different sizes... (MCC) 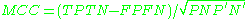 Source: Fawcett (2004). |
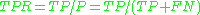
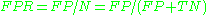
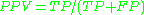
- Binary classificationBinary classificationBinary classification is the task of classifying the members of a given set of objects into two groups on the basis of whether they have some property or not. Some typical binary classification tasks are...
- Detection theoryDetection theoryDetection theory, or signal detection theory, is a means to quantify the ability to discern between information-bearing energy patterns and random energy patterns that distract from the information Detection theory, or signal detection theory, is a means to quantify the ability to discern between...
- Receiver operating characteristicReceiver operating characteristicIn signal detection theory, a receiver operating characteristic , or simply ROC curve, is a graphical plot of the sensitivity, or true positive rate, vs. false positive rate , for a binary classifier system as its discrimination threshold is varied...
- Statistical significanceStatistical significanceIn statistics, a result is called statistically significant if it is unlikely to have occurred by chance. The phrase test of significance was coined by Ronald Fisher....
- Type I and type II errorsType I and type II errorsIn statistical test theory the notion of statistical error is an integral part of hypothesis testing. The test requires an unambiguous statement of a null hypothesis, which usually corresponds to a default "state of nature", for example "this person is healthy", "this accused is not guilty" or...
- SelectivitySelectivitySelectivity may refer to:* Selectivity , in radio transmission* Binding selectivity, in pharmacology* Functional selectivity, in pharmacology* Socioemotional selectivity theory, in social psychology...
- Youden's J statisticYouden's J statisticYouden's J statistic is a single statistic that captures the performance of a diagnostic test. The use of such a single index is "not generally to be recommended". It is equal to the risk difference for a dichotomous test ....
- Matthews correlation coefficientMatthews Correlation CoefficientThe Matthews correlation coefficient is used in machine learning as a measure of the quality of binary classifications. It takes into account true and false positives and negatives and is generally regarded as a balanced measure which can be used even if the classes are of very different sizes...
- Gain (information retrieval)Gain (information retrieval)The gain, also called improvement over random can be specified for a classifier and is an important measure to describe the performance of it.- Definition :...
- Accuracy and precisionAccuracy and precisionIn the fields of science, engineering, industry and statistics, the accuracy of a measurement system is the degree of closeness of measurements of a quantity to that quantity's actual value. The precision of a measurement system, also called reproducibility or repeatability, is the degree to which...
- OpenEpiOpenEpiOpenEpi is a free, web-based, open source, operating system-independent series of programs for use in epidemiology, biostatistics, public health, and medicine, providing a number of epidemiologic and statistical tools for summary data. OpenEpi was developed in JavaScript and HTML, and can be run in...
software program
External links
- Calculators: