
Gambling and information theory
Encyclopedia
Statistical inference
might be thought of as gambling theory applied to the world around. The myriad applications for logarithmic information measures
tell us precisely how to take the best guess in the face of partial information. In that sense, information theory
might be considered a formal expression of the theory of gambling. It is no surprise, therefore, that information theory has applications to games of chance.
to investing and gambling
. Its discoverer was John Larry Kelly Jr.
.
Part of Kelly's insight was to have the gambler maximize the expectation of the logarithm of his capital, rather than the expected profit from each bet. This is important, since in the latter case, one would be led to gamble all he had when presented with a favorable bet, and if he lost, would have no capital with which to place subsequent bets. Kelly realized that it was the logarithm of the gambler's capital which is additive in sequential bets, and "to which the law of large numbers applies."
is the amount of entropy in a bettable event with two possible outcomes and even odds. Obviously we could double our money if we knew beforehand for certain what the outcome of that event would be. Kelly's insight was that no matter how complicated the betting scenario is, we can use an optimum betting strategy, called the Kelly criterion
, to make our money grow exponentially with whatever side information we are able to obtain. The value of this "illicit" side information is measured as mutual information
relative to the outcome of the betable event:

where Y is the side information, X is the outcome of the betable event, and I is the state of the bookmaker's knowledge. This is the average Kullback–Leibler divergence
, or information gain, of the a posteriori
probability distribution of X given the value of Y relative to the a priori
distribution, or stated odds, on X. Notice that the expectation is taken over Y rather than X: we need to evaluate how accurate, in the long term, our side information Y is before we start betting real money on X. This is a straightforward application of Bayesian inference
. Note that the side information Y might affect not just our knowledge of the event X but also the event itself. For example, Y might be a horse that had too many oats or not enough water. The same mathematics applies in this case, because from the bookmaker's point of view, the occasional race fixing is already taken into account when he makes his odds.
The nature of side information is extremely finicky. We have already seen that it can affect the actual event as well as our knowledge of the outcome. Suppose we have an informer, who tells us that a certain horse is going to win. We certainly do not want to bet all our money on that horse just upon a rumor: that informer may be betting on another horse, and may be spreading rumors just so he can get better odds himself. Instead, as we have indicated, we need to evaluate our side information in the long term to see how it correlates with the outcomes of the races. This way we can determine exactly how reliable our informer is, and place our bets precisely to maximize the expected logarithm of our capital according to the Kelly criterion. Even if our informer is lying to us, we can still profit from his lies if we can find some reverse correlation between his tips and the actual race results.
is
where there are horses, the probability of the
horses, the probability of the 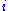 th horse winning being
th horse winning being 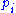 , the proportion of wealth bet on the horse being
, the proportion of wealth bet on the horse being 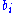 , and the odds
, and the odds
(payoff) being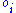 (e.g.,
(e.g., 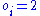 if the
if the 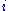 th horse winning pays double the amount bet). This quantity is maximized by proportional (Kelly) gambling:
th horse winning pays double the amount bet). This quantity is maximized by proportional (Kelly) gambling:
for which
where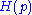 is information entropy
is information entropy
.
for an optimal betting strategy, where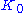 is the initial capital,
is the initial capital, 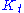 is the capital after the tth bet, and
is the capital after the tth bet, and 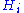 is the amount of side information obtained concerning the ith bet (in particular, the mutual information
is the amount of side information obtained concerning the ith bet (in particular, the mutual information
relative to the outcome of each betable event). This equation applies in the absence of any transaction costs or minimum bets. When these constraints apply (as they invariably do in real life), another important gambling concept comes into play: the gambler (or unscrupulous investor) must face a certain probability of ultimate ruin, which is known as the gambler's ruin
scenario. Note that even food, clothing, and shelter can be considered fixed transaction costs and thus contribute to the gambler's probability of ultimate ruin.
This equation was the first application of Shannon's theory of information outside its prevailing paradigm of data communications (Pierce).
 The logarithmic probability measure self-information
The logarithmic probability measure self-information
or surprisal, whose average is information entropy
/uncertainty and whose average difference is KL-divergence, has applications to odds-analysis all by itself. Its two primary strengths are that surprisals: (i) reduce minuscule probabilities to numbers of manageable size, and (ii) add whenever probabilities multiply.
For example, one might say that "the number of states equals two to the number of bits" i.e. #states = 2#bits. Here the quantity that's measured in bits is the logarithmic information measure mentioned above. Hence there are N bits of surprisal in landing all heads on one's first toss of N coins.
The additive nature of surprisals, and one's ability to get a feel for their meaning with a handful of coins, can help one put improbable events (like winning the lottery, or having an accident) into context. For example if one out of 17 million tickets is a winner, then the surprisal of winning from a single random selection is about 24 bits. Tossing 24 coins a few times might give you a feel for the surprisal of getting all heads on the first try.
The additive nature of this measure also comes in handy when weighing alternatives. For example, imagine that the surprisal of harm from a vaccination is 20 bits. If the surprisal of catching a disease without it is 16 bits, but the surprisal of harm from the disease if you catch it is 2 bits, then the surprisal of harm from NOT getting the vaccination is only 16+2=18 bits. Whether or not you decide to get the vaccination (e.g. the monetary cost of paying for it is not included in this discussion), you can in that way at least take responsibility for a decision informed to the fact that not getting the vaccination involves more than one bit of additional risk.
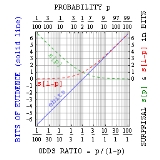
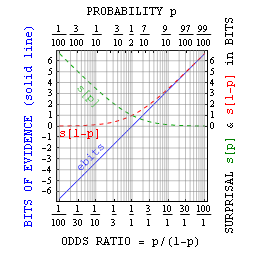
More generally, one can relate probability p to bits of surprisal sbits as probability = 1/2sbits. As suggested above, this is mainly useful with small probabilities. However, Jaynes pointed out that with true-false assertions one can also define bits of evidence ebits as the surprisal against minus the surprisal for. This evidence in bits relates simply to the odds ratio = p/(1-p) = 2ebits, and has advantages similar to those of self-information itself.
Bayesian inference
In statistics, Bayesian inference is a method of statistical inference. It is often used in science and engineering to determine model parameters, make predictions about unknown variables, and to perform model selection...
might be thought of as gambling theory applied to the world around. The myriad applications for logarithmic information measures
Quantities of information
The mathematical theory of information is based on probability theory and statistics, and measures information with several quantities of information. The choice of logarithmic base in the following formulae determines the unit of information entropy that is used. The most common unit of...
tell us precisely how to take the best guess in the face of partial information. In that sense, information theory
Information theory
Information theory is a branch of applied mathematics and electrical engineering involving the quantification of information. Information theory was developed by Claude E. Shannon to find fundamental limits on signal processing operations such as compressing data and on reliably storing and...
might be considered a formal expression of the theory of gambling. It is no surprise, therefore, that information theory has applications to games of chance.
Kelly Betting
Kelly betting or proportional betting is an application of information theoryInformation theory
Information theory is a branch of applied mathematics and electrical engineering involving the quantification of information. Information theory was developed by Claude E. Shannon to find fundamental limits on signal processing operations such as compressing data and on reliably storing and...
to investing and gambling
Gambling
Gambling is the wagering of money or something of material value on an event with an uncertain outcome with the primary intent of winning additional money and/or material goods...
. Its discoverer was John Larry Kelly Jr.
John Larry Kelly, Jr
John Larry Kelly, Jr. , was a scientist who worked at Bell Labs. He is best known for formulating the Kelly criterion, an algorithm for maximally investing money....
.
Part of Kelly's insight was to have the gambler maximize the expectation of the logarithm of his capital, rather than the expected profit from each bet. This is important, since in the latter case, one would be led to gamble all he had when presented with a favorable bet, and if he lost, would have no capital with which to place subsequent bets. Kelly realized that it was the logarithm of the gambler's capital which is additive in sequential bets, and "to which the law of large numbers applies."
Side information
A bitBit
A bit is the basic unit of information in computing and telecommunications; it is the amount of information stored by a digital device or other physical system that exists in one of two possible distinct states...
is the amount of entropy in a bettable event with two possible outcomes and even odds. Obviously we could double our money if we knew beforehand for certain what the outcome of that event would be. Kelly's insight was that no matter how complicated the betting scenario is, we can use an optimum betting strategy, called the Kelly criterion
Kelly criterion
In probability theory, the Kelly criterion, or Kelly strategy or Kelly formula, or Kelly bet, is a formula used to determine the optimal size of a series of bets. In most gambling scenarios, and some investing scenarios under some simplifying assumptions, the Kelly strategy will do better than any...
, to make our money grow exponentially with whatever side information we are able to obtain. The value of this "illicit" side information is measured as mutual information
Mutual information
In probability theory and information theory, the mutual information of two random variables is a quantity that measures the mutual dependence of the two random variables...
relative to the outcome of the betable event:
where Y is the side information, X is the outcome of the betable event, and I is the state of the bookmaker's knowledge. This is the average Kullback–Leibler divergence
Kullback–Leibler divergence
In probability theory and information theory, the Kullback–Leibler divergence is a non-symmetric measure of the difference between two probability distributions P and Q...
, or information gain, of the a posteriori
Posterior probability
In Bayesian statistics, the posterior probability of a random event or an uncertain proposition is the conditional probability that is assigned after the relevant evidence is taken into account...
probability distribution of X given the value of Y relative to the a priori
Prior probability
In Bayesian statistical inference, a prior probability distribution, often called simply the prior, of an uncertain quantity p is the probability distribution that would express one's uncertainty about p before the "data"...
distribution, or stated odds, on X. Notice that the expectation is taken over Y rather than X: we need to evaluate how accurate, in the long term, our side information Y is before we start betting real money on X. This is a straightforward application of Bayesian inference
Bayesian inference
In statistics, Bayesian inference is a method of statistical inference. It is often used in science and engineering to determine model parameters, make predictions about unknown variables, and to perform model selection...
. Note that the side information Y might affect not just our knowledge of the event X but also the event itself. For example, Y might be a horse that had too many oats or not enough water. The same mathematics applies in this case, because from the bookmaker's point of view, the occasional race fixing is already taken into account when he makes his odds.
The nature of side information is extremely finicky. We have already seen that it can affect the actual event as well as our knowledge of the outcome. Suppose we have an informer, who tells us that a certain horse is going to win. We certainly do not want to bet all our money on that horse just upon a rumor: that informer may be betting on another horse, and may be spreading rumors just so he can get better odds himself. Instead, as we have indicated, we need to evaluate our side information in the long term to see how it correlates with the outcomes of the races. This way we can determine exactly how reliable our informer is, and place our bets precisely to maximize the expected logarithm of our capital according to the Kelly criterion. Even if our informer is lying to us, we can still profit from his lies if we can find some reverse correlation between his tips and the actual race results.
Doubling rate
Doubling rate in gambling on a horse raceHorse racing
Horse racing is an equestrian sport that has a long history. Archaeological records indicate that horse racing occurred in ancient Babylon, Syria, and Egypt. Both chariot and mounted horse racing were events in the ancient Greek Olympics by 648 BC...
is
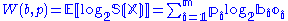
where there are
horses, the probability of the th horse winning being , the proportion of wealth bet on the horse being , and the oddsOdds
The odds in favor of an event or a proposition are expressed as the ratio of a pair of integers, which is the ratio of the probability that an event will happen to the probability that it will not happen...
(payoff) being
(e.g., if the th horse winning pays double the amount bet). This quantity is maximized by proportional (Kelly) gambling: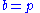
for which
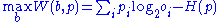
where
is information entropyInformation entropy
In information theory, entropy is a measure of the uncertainty associated with a random variable. In this context, the term usually refers to the Shannon entropy, which quantifies the expected value of the information contained in a message, usually in units such as bits...
.
Expected gains
An important but simple relation exists between the amount of side information a gambler obtains and the expected exponential growth of his capital (Kelly):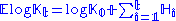
for an optimal betting strategy, where
is the initial capital, is the capital after the tth bet, and is the amount of side information obtained concerning the ith bet (in particular, the mutual informationMutual information
In probability theory and information theory, the mutual information of two random variables is a quantity that measures the mutual dependence of the two random variables...
relative to the outcome of each betable event). This equation applies in the absence of any transaction costs or minimum bets. When these constraints apply (as they invariably do in real life), another important gambling concept comes into play: the gambler (or unscrupulous investor) must face a certain probability of ultimate ruin, which is known as the gambler's ruin
Gambler's ruin
The term gambler's ruin is used for a number of related statistical ideas:* The original meaning is that a gambler who raises his bet to a fixed fraction of bankroll when he wins, but does not reduce it when he loses, will eventually go broke, even if he has a positive expected value on each bet.*...
scenario. Note that even food, clothing, and shelter can be considered fixed transaction costs and thus contribute to the gambler's probability of ultimate ruin.
This equation was the first application of Shannon's theory of information outside its prevailing paradigm of data communications (Pierce).
Applications for self-information
Self-information
In information theory, self-information is a measure of the information content associated with the outcome of a random variable. It is expressed in a unit of information, for example bits,nats,or...
or surprisal, whose average is information entropy
Information entropy
In information theory, entropy is a measure of the uncertainty associated with a random variable. In this context, the term usually refers to the Shannon entropy, which quantifies the expected value of the information contained in a message, usually in units such as bits...
/uncertainty and whose average difference is KL-divergence, has applications to odds-analysis all by itself. Its two primary strengths are that surprisals: (i) reduce minuscule probabilities to numbers of manageable size, and (ii) add whenever probabilities multiply.
For example, one might say that "the number of states equals two to the number of bits" i.e. #states = 2#bits. Here the quantity that's measured in bits is the logarithmic information measure mentioned above. Hence there are N bits of surprisal in landing all heads on one's first toss of N coins.
The additive nature of surprisals, and one's ability to get a feel for their meaning with a handful of coins, can help one put improbable events (like winning the lottery, or having an accident) into context. For example if one out of 17 million tickets is a winner, then the surprisal of winning from a single random selection is about 24 bits. Tossing 24 coins a few times might give you a feel for the surprisal of getting all heads on the first try.
The additive nature of this measure also comes in handy when weighing alternatives. For example, imagine that the surprisal of harm from a vaccination is 20 bits. If the surprisal of catching a disease without it is 16 bits, but the surprisal of harm from the disease if you catch it is 2 bits, then the surprisal of harm from NOT getting the vaccination is only 16+2=18 bits. Whether or not you decide to get the vaccination (e.g. the monetary cost of paying for it is not included in this discussion), you can in that way at least take responsibility for a decision informed to the fact that not getting the vaccination involves more than one bit of additional risk.
More generally, one can relate probability p to bits of surprisal sbits as probability = 1/2sbits. As suggested above, this is mainly useful with small probabilities. However, Jaynes pointed out that with true-false assertions one can also define bits of evidence ebits as the surprisal against minus the surprisal for. This evidence in bits relates simply to the odds ratio = p/(1-p) = 2ebits, and has advantages similar to those of self-information itself.