

Histogram of oriented gradients
Encyclopedia
Histogram of Oriented Gradients (HOG) are feature descriptors used in computer vision
and image processing
for the purpose of object detection
. The technique counts occurrences of gradient orientation in localized portions of an image. This method is similar to that of edge orientation histograms, scale-invariant feature transform
descriptors, and shape context
s, but differs in that it is computed on a dense grid of uniformly spaced cells and uses overlapping local contrast normalization for improved accuracy.
Navneet Dalal and Bill Triggs, researchers for the French National Institute for Research in Computer Science and Control (INRIA), first described Histogram of Oriented Gradient descriptors in their June 2005 paper to the CVPR
. In this work they focused their algorithm on the problem of pedestrian detection in static images, although since then they expanded their tests to include human detection in film and video, as well as to a variety of common animals and vehicles in static imagery.
The HOG descriptor maintains a few key advantages over other descriptor methods. Since the HOG descriptor operates on localized cells, the method upholds invariance to geometric and photometric transformations, except for object orientation. Such changes would only appear in larger spatial regions. Moreover, as Dalal and Triggs discovered, coarse spatial sampling, fine orientation sampling, and strong local photometric normalization permits the individual body movement of pedestrians to be ignored so long as they maintain a roughly upright position. The HOG descriptor is thus particularly suited for human detection in images.
Dalal and Triggs tested other, more complex masks, such as 3x3 Sobel masks (Sobel operator) or diagonal masks, but these masks generally exhibited poorer performance in human image detection experiments. They also experimented with Gaussian smoothing before applying the derivative mask, but similarly found that omission of any smoothing performed better in practice.
descriptors; however, despite their similar formation, R-HOG blocks are computed in dense grids at some single scale without orientation alignment, whereas SIFT descriptors are computed at sparse, scale-invariant key image points and are rotated to align orientation. In addition, the R-HOG blocks are used in conjunction to encode spatial form information, while SIFT descriptors are used singly.
C-HOG blocks can be found in two variants: those with a single, central cell and those with an angularly-divided central cell. In addition, these C-HOG blocks can be described with four parameters: the number of angular and radial bins, the radius of the center bin, and the expansion factor for the radius of additional radial bins. Dalal and Triggs found that the two main variants provided equal performance, and that two radial bins with four angular bins, a center radius of 4 pixels, and an expansion factor of 2 provided the best performance in their experimentation. Also, Gaussian weighting provided no benefit when used in conjunction with the C-HOG blocks. C-HOG blocks appear similar to Shape Contexts
, but differ strongly in that C-HOG blocks contain cells with several orientation channels, while Shape Contexts only make use of a single edge presence count in their formulation.
 be the non-normalized vector containing all histograms in a given block,
be the non-normalized vector containing all histograms in a given block, 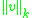 be its k-norm for
be its k-norm for 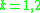 and
and  be some small constant (the exact value, hopefully, is unimportant). Then the normalization factor can be one of the following:
be some small constant (the exact value, hopefully, is unimportant). Then the normalization factor can be one of the following:
In addition, the scheme L2-Hys can be computed by first taking the L2-norm, clipping the result, and then renormalizing. In their experiments, Dalal and Triggs found the L2-Hys, L2-norm, and L1-sqrt schemes provide similar performance, while the L1-norm provides slightly less reliable performance; however, all four methods showed very significant improvement over the non-normalized data.
classifier is a binary classifier which looks for an optimal hyperplane as a decision function. Once trained on images containing some particular object, the SVM classifier can make decisions regarding the presence of an object, such as a human being, in additional test images. In the Dalal and Triggs human recognition tests, they used the freely available SVMLight software package in conjunction with their HOG descriptors to find human figures in test images.
. Generalized Haar wavelets are oriented Haar wavelets, and were used in 2001 by Mohan, Papageorgiou, and Poggio in their own object detection experiments. PCA-SIFT descriptors are similar to SIFT descriptors, but differ in that principal component analysis is applied to the normalized gradient patches. PCA-SIFT descriptors were first used in 2004 by Ke and Sukthankar and were claimed to outperform regular SIFT descriptors. Finally, Shape Contexts use circular bins, similar to those used in C-HOG blocks, but only tabulate votes on the basis of edge presence, making no distinction with regards to orientation. Shape Contexts were originally used in 2001 by Belongie, Malik, and Puzicha.
The testing commenced on two different data sets. The Massachusetts Institute of Technology pedestrian database contains 509 training images and 200 test images of pedestrians on city streets. The set only contains images featuring the front or back of human figures and contains little variety in human pose. The set is well-known and has been used in a variety of human detection experiments, such as those conducted by Papageorgiou and Poggio in 2000. The MIT database is currently available for research at http://cbcl.mit.edu/cbcl/software-datasets/PedestrianData.html. The second set was developed by Dalal and Triggs exclusively for their human detection experiment due to the fact that the HOG descriptors performed near-perfectly on the MIT set. Their set, known as INRIA, contains 1805 images of humans taken from personal photographs. The set contains images of humans in a wide variety of poses and includes difficult backgrounds, such as crowd scenes, thus rendering it more complex than the MIT set. The INRIA database is currently available for research at http://lear.inrialpes.fr/data.
The above site has an image showing examples from the INRIA human detection database.
As for the results, the C-HOG and R-HOG block descriptors perform comparatively, with the C-HOG descriptors maintaining a slight advantage in the detection miss rate at fixed false positive rates across both data sets. On the MIT set, the C-HOG and R-HOG descriptors produced a detection miss rate of essentially zero at a 10−4 false positive rate. On the INRIA set, the C-HOG and R-HOG descriptors produced a detection miss rate of roughly 0.1 at a 10−4 false positive rate. The Generalized Haar Wavelets represent the next highest performing approach: the wavelets produced roughly a 0.01 miss rate at a 10−4 false positive rate on the MIT set, and roughly a 0.3 miss rate on the INRIA set. The PCA-SIFT descriptors and Shape Contexts both performed fairly poorly on both data sets. Both methods produced a miss rate of 0.1 at a 10−4 false positive rate on the MIT set and nearly a miss rate of 0.5 at a 10−4 false positive rate on the INRIA set. The image below contains the result data from the original Dalal and Triggs experiment. The curves represent the Detection Error Tradeoff
on a log-log scale, which equates to the miss rate versus the false positive rate.
Visual Object Classes 2006 Workshop, Dalal and Triggs presented results on applying Histogram of Oriented Gradient descriptors to image objects other than human beings, such as cars, buses, and bicycles, as well as common animals such as dogs, cats, and cows. They included with their results the optimal parameters for block formulation and normalization in each case. The image in the below reference shows some of their detection examples for motorbikes.
Then as part of the 2006 European Conference on Computer Vision
, Dalal and Triggs teamed up with Cordelia Schmid to apply Histogram of Oriented Gradient detectors to the problem of human detection in films and videos. Essentially their technique involves the combination of regular HOG descriptors on individual video frames with new Internal Motion Histograms (IMH) on pairs of subsequent video frames. These Internal Motion Histograms use the gradient magnitudes from optical flow fields obtained from two consecutive frames. These gradient magnitudes are then used in the same manner as those produced from static image data within the HOG descriptor approach. When testing on two large datasets taken from several movie DVDs, the combined HOG-IMH method yielded a miss rate of approximately 0.1 at a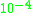 false positive rate.
false positive rate.
At the Intelligent Vehicles Symposium in 2006, F. Suard, A. Rakotomamonjy, and A. Bensrhair introduced a complete system for pedestrian detection based on HOG descriptors. Their system operates using two infrared cameras. Since human beings appear brighter than their surroundings on infrared images, the system first locates positions of interest within the larger view field where humans could possibly be located. Then normal Support Vector Machine classifiers operate on the HOG descriptors taken from these smaller positions of interest to formulate a decision regarding the presence of a pedestrian. Once pedestrians are located within the view field, the actual position of the pedestrian is estimated using stereovision.
At the IEEE Conference on Computer Vision and Pattern Recognition
in 2006, Qiang Zhu, Shai Avidan, Mei-Chen Yeh, and Kwang-Ting Cheng presented an algorithm to significantly speed up human detection using HOG descriptor methods. Their method uses HOG descriptors in combination with the cascade of rejecters algorithm normally applied with great success to the problem of face detection. Also, rather than relying on blocks of uniform size, they introduce blocks that vary in size, location, and aspect ratio. In order to isolate the blocks best suited for human detection, they applied the AdaBoost
algorithm to select those blocks to be included in the rejecter cascade. In their experimentation, their algorithm achieved comparable performance to the original Dalal and Triggs algorithm, but operated at speeds up to 70 times faster. In April 2006, the Mitsubishi Electric Research Laboratories applied for the U.S. Patent of this algorithm under application number 20070237387.
Computer vision
Computer vision is a field that includes methods for acquiring, processing, analysing, and understanding images and, in general, high-dimensional data from the real world in order to produce numerical or symbolic information, e.g., in the forms of decisions...
and image processing
Image processing
In electrical engineering and computer science, image processing is any form of signal processing for which the input is an image, such as a photograph or video frame; the output of image processing may be either an image or, a set of characteristics or parameters related to the image...
for the purpose of object detection
Object detection
Object detection is a computer technology related to computer vision and image processing that deals with detecting instances of semantic objects of a certain class in digital images and videos. Well-researched domains of object detection include face detection and pedestrian detection...
. The technique counts occurrences of gradient orientation in localized portions of an image. This method is similar to that of edge orientation histograms, scale-invariant feature transform
Scale-invariant feature transform
Scale-invariant feature transform is an algorithm in computer vision to detect and describe local features in images. The algorithm was published by David Lowe in 1999....
descriptors, and shape context
Shape context
Shape context is the term given by Serge Belongie and Jitendra Malik to the feature descriptor they first proposed in their paper "Matching with Shape Contexts" in 2000. Shape context can be used in object recognition.-Theory:...
s, but differs in that it is computed on a dense grid of uniformly spaced cells and uses overlapping local contrast normalization for improved accuracy.
Navneet Dalal and Bill Triggs, researchers for the French National Institute for Research in Computer Science and Control (INRIA), first described Histogram of Oriented Gradient descriptors in their June 2005 paper to the CVPR
Conference on Computer Vision and Pattern Recognition
The Conference on Computer Vision and Pattern Recognition is the IEEE annual conference on computer vision and pattern recognition. It has an 'A' rating from the Australian Ranking of ICT Conferences....
. In this work they focused their algorithm on the problem of pedestrian detection in static images, although since then they expanded their tests to include human detection in film and video, as well as to a variety of common animals and vehicles in static imagery.
Theory
The essential thought behind the Histogram of Oriented Gradient descriptors is that local object appearance and shape within an image can be described by the distribution of intensity gradients or edge directions. The implementation of these descriptors can be achieved by dividing the image into small connected regions, called cells, and for each cell compiling a histogram of gradient directions or edge orientations for the pixels within the cell. The combination of these histograms then represents the descriptor. For improved accuracy, the local histograms can be contrast-normalized by calculating a measure of the intensity across a larger region of the image, called a block, and then using this value to normalize all cells within the block. This normalization results in better invariance to changes in illumination or shadowing.The HOG descriptor maintains a few key advantages over other descriptor methods. Since the HOG descriptor operates on localized cells, the method upholds invariance to geometric and photometric transformations, except for object orientation. Such changes would only appear in larger spatial regions. Moreover, as Dalal and Triggs discovered, coarse spatial sampling, fine orientation sampling, and strong local photometric normalization permits the individual body movement of pedestrians to be ignored so long as they maintain a roughly upright position. The HOG descriptor is thus particularly suited for human detection in images.
Gradient computation
The first step of calculation in many feature detectors in image pre-processing is to ensure normalized color and gamma values. As Dalal and Triggs point out, however, this step can be omitted in HOG descriptor computation, as the ensuing descriptor normalization essentially achieves the same result. Image pre-processing thus provides little impact on performance. Instead, the first step of calculation is the computation of the gradient values. The most common method is to simply apply the 1-D centered, point discrete derivative mask in one or both of the horizontal and vertical directions. Specifically, this method requires filtering the color or intensity data of the image with the following filter kernels: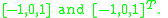
Dalal and Triggs tested other, more complex masks, such as 3x3 Sobel masks (Sobel operator) or diagonal masks, but these masks generally exhibited poorer performance in human image detection experiments. They also experimented with Gaussian smoothing before applying the derivative mask, but similarly found that omission of any smoothing performed better in practice.
Orientation binning
The second step of calculation involves creating the cell histograms. Each pixel within the cell casts a weighted vote for an orientation-based histogram channel based on the values found in the gradient computation. The cells themselves can either be rectangular or radial in shape, and the histogram channels are evenly spread over 0 to 180 degrees or 0 to 360 degrees, depending on whether the gradient is “unsigned” or “signed”. Dalal and Triggs found that unsigned gradients used in conjunction with 9 histogram channels performed best in their human detection experiments. As for the vote weight, pixel contribution can either be the gradient magnitude itself, or some function of the magnitude; in actual tests the gradient magnitude itself generally produces the best results. Other options for the vote weight could include the square root or square of the gradient magnitude, or some clipped version of the magnitude.Descriptor blocks
In order to account for changes in illumination and contrast, the gradient strengths must be locally normalized, which requires grouping the cells together into larger, spatially-connected blocks. The HOG descriptor is then the vector of the components of the normalized cell histograms from all of the block regions. These blocks typically overlap, meaning that each cell contributes more than once to the final descriptor. Two main block geometries exist: rectangular R-HOG blocks and circular C-HOG blocks. R-HOG blocks are generally square grids, represented by three parameters: the number of cells per block, the number of pixels per cell, and the number of channels per cell histogram. In the Dalal and Triggs human detection experiment, the optimal parameters were found to be 3x3 cell blocks of 6x6 pixel cells with 9 histogram channels. Moreover, they found that some minor improvement in performance could be gained by applying a Gaussian spatial window within each block before tabulating histogram votes in order to weight pixels around the edge of the blocks less. The R-HOG blocks appear quite similar to the scale-invariant feature transformScale-invariant feature transform
Scale-invariant feature transform is an algorithm in computer vision to detect and describe local features in images. The algorithm was published by David Lowe in 1999....
descriptors; however, despite their similar formation, R-HOG blocks are computed in dense grids at some single scale without orientation alignment, whereas SIFT descriptors are computed at sparse, scale-invariant key image points and are rotated to align orientation. In addition, the R-HOG blocks are used in conjunction to encode spatial form information, while SIFT descriptors are used singly.
C-HOG blocks can be found in two variants: those with a single, central cell and those with an angularly-divided central cell. In addition, these C-HOG blocks can be described with four parameters: the number of angular and radial bins, the radius of the center bin, and the expansion factor for the radius of additional radial bins. Dalal and Triggs found that the two main variants provided equal performance, and that two radial bins with four angular bins, a center radius of 4 pixels, and an expansion factor of 2 provided the best performance in their experimentation. Also, Gaussian weighting provided no benefit when used in conjunction with the C-HOG blocks. C-HOG blocks appear similar to Shape Contexts
Shape context
Shape context is the term given by Serge Belongie and Jitendra Malik to the feature descriptor they first proposed in their paper "Matching with Shape Contexts" in 2000. Shape context can be used in object recognition.-Theory:...
, but differ strongly in that C-HOG blocks contain cells with several orientation channels, while Shape Contexts only make use of a single edge presence count in their formulation.
Block normalization
Dalal and Triggs explore four different methods for block normalization. Let be the non-normalized vector containing all histograms in a given block, be its k-norm for and be some small constant (the exact value, hopefully, is unimportant). Then the normalization factor can be one of the following:- L2-norm:
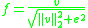
- L2-hys: L2-norm followed by clipping (limiting the maxi-mum values of v to 0.2) and renormalizing, as in
- L1-norm:
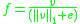
- L1-sqrt:
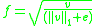
In addition, the scheme L2-Hys can be computed by first taking the L2-norm, clipping the result, and then renormalizing. In their experiments, Dalal and Triggs found the L2-Hys, L2-norm, and L1-sqrt schemes provide similar performance, while the L1-norm provides slightly less reliable performance; however, all four methods showed very significant improvement over the non-normalized data.
SVM classifier
The final step in object recognition using Histogram of Oriented Gradient descriptors is to feed the descriptors into some recognition system based on supervised learning. The Support Vector MachineSupport vector machine
A support vector machine is a concept in statistics and computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis...
classifier is a binary classifier which looks for an optimal hyperplane as a decision function. Once trained on images containing some particular object, the SVM classifier can make decisions regarding the presence of an object, such as a human being, in additional test images. In the Dalal and Triggs human recognition tests, they used the freely available SVMLight software package in conjunction with their HOG descriptors to find human figures in test images.
Testing
In their original human detection experiment, Dalal and Triggs compared their R-HOG and C-HOG descriptor blocks against generalized Haar wavelets, PCA-SIFT descriptors, and Shape ContextsShape context
Shape context is the term given by Serge Belongie and Jitendra Malik to the feature descriptor they first proposed in their paper "Matching with Shape Contexts" in 2000. Shape context can be used in object recognition.-Theory:...
. Generalized Haar wavelets are oriented Haar wavelets, and were used in 2001 by Mohan, Papageorgiou, and Poggio in their own object detection experiments. PCA-SIFT descriptors are similar to SIFT descriptors, but differ in that principal component analysis is applied to the normalized gradient patches. PCA-SIFT descriptors were first used in 2004 by Ke and Sukthankar and were claimed to outperform regular SIFT descriptors. Finally, Shape Contexts use circular bins, similar to those used in C-HOG blocks, but only tabulate votes on the basis of edge presence, making no distinction with regards to orientation. Shape Contexts were originally used in 2001 by Belongie, Malik, and Puzicha.
The testing commenced on two different data sets. The Massachusetts Institute of Technology pedestrian database contains 509 training images and 200 test images of pedestrians on city streets. The set only contains images featuring the front or back of human figures and contains little variety in human pose. The set is well-known and has been used in a variety of human detection experiments, such as those conducted by Papageorgiou and Poggio in 2000. The MIT database is currently available for research at http://cbcl.mit.edu/cbcl/software-datasets/PedestrianData.html. The second set was developed by Dalal and Triggs exclusively for their human detection experiment due to the fact that the HOG descriptors performed near-perfectly on the MIT set. Their set, known as INRIA, contains 1805 images of humans taken from personal photographs. The set contains images of humans in a wide variety of poses and includes difficult backgrounds, such as crowd scenes, thus rendering it more complex than the MIT set. The INRIA database is currently available for research at http://lear.inrialpes.fr/data.
The above site has an image showing examples from the INRIA human detection database.
As for the results, the C-HOG and R-HOG block descriptors perform comparatively, with the C-HOG descriptors maintaining a slight advantage in the detection miss rate at fixed false positive rates across both data sets. On the MIT set, the C-HOG and R-HOG descriptors produced a detection miss rate of essentially zero at a 10−4 false positive rate. On the INRIA set, the C-HOG and R-HOG descriptors produced a detection miss rate of roughly 0.1 at a 10−4 false positive rate. The Generalized Haar Wavelets represent the next highest performing approach: the wavelets produced roughly a 0.01 miss rate at a 10−4 false positive rate on the MIT set, and roughly a 0.3 miss rate on the INRIA set. The PCA-SIFT descriptors and Shape Contexts both performed fairly poorly on both data sets. Both methods produced a miss rate of 0.1 at a 10−4 false positive rate on the MIT set and nearly a miss rate of 0.5 at a 10−4 false positive rate on the INRIA set. The image below contains the result data from the original Dalal and Triggs experiment. The curves represent the Detection Error Tradeoff
Detection Error Tradeoff
A detection error tradeoff graph is a graphical plot of error rates for binary classification systems, plotting false reject rate vs. false accept rate...
on a log-log scale, which equates to the miss rate versus the false positive rate.
Further development
As part of the PascalPascal
Pascal or PASCAL may refer to:-People:* Pascal , a French given name* Pascal , a French and Italian surname* Adam Pascal , American actor and singer, best known for his role of Roger Davis in the Broadway musical Rent* Blaise Pascal , French mathematician and philosopher* Cleo Paskal, environmental...
Visual Object Classes 2006 Workshop, Dalal and Triggs presented results on applying Histogram of Oriented Gradient descriptors to image objects other than human beings, such as cars, buses, and bicycles, as well as common animals such as dogs, cats, and cows. They included with their results the optimal parameters for block formulation and normalization in each case. The image in the below reference shows some of their detection examples for motorbikes.
Then as part of the 2006 European Conference on Computer Vision
European Conference on Computer Vision
ECCV, the European Conference on Computer Vision, is a bi-annual research conference organised by the IEEE. Similar to ICCV in scope and quality, it is held those years which ICCV is not. Like ICCV, it is considered an important conference in computer vision, with an 'A' rating from the Australian...
, Dalal and Triggs teamed up with Cordelia Schmid to apply Histogram of Oriented Gradient detectors to the problem of human detection in films and videos. Essentially their technique involves the combination of regular HOG descriptors on individual video frames with new Internal Motion Histograms (IMH) on pairs of subsequent video frames. These Internal Motion Histograms use the gradient magnitudes from optical flow fields obtained from two consecutive frames. These gradient magnitudes are then used in the same manner as those produced from static image data within the HOG descriptor approach. When testing on two large datasets taken from several movie DVDs, the combined HOG-IMH method yielded a miss rate of approximately 0.1 at a
false positive rate. At the Intelligent Vehicles Symposium in 2006, F. Suard, A. Rakotomamonjy, and A. Bensrhair introduced a complete system for pedestrian detection based on HOG descriptors. Their system operates using two infrared cameras. Since human beings appear brighter than their surroundings on infrared images, the system first locates positions of interest within the larger view field where humans could possibly be located. Then normal Support Vector Machine classifiers operate on the HOG descriptors taken from these smaller positions of interest to formulate a decision regarding the presence of a pedestrian. Once pedestrians are located within the view field, the actual position of the pedestrian is estimated using stereovision.
At the IEEE Conference on Computer Vision and Pattern Recognition
Conference on Computer Vision and Pattern Recognition
The Conference on Computer Vision and Pattern Recognition is the IEEE annual conference on computer vision and pattern recognition. It has an 'A' rating from the Australian Ranking of ICT Conferences....
in 2006, Qiang Zhu, Shai Avidan, Mei-Chen Yeh, and Kwang-Ting Cheng presented an algorithm to significantly speed up human detection using HOG descriptor methods. Their method uses HOG descriptors in combination with the cascade of rejecters algorithm normally applied with great success to the problem of face detection. Also, rather than relying on blocks of uniform size, they introduce blocks that vary in size, location, and aspect ratio. In order to isolate the blocks best suited for human detection, they applied the AdaBoost
AdaBoost
AdaBoost, short for Adaptive Boosting, is a machine learning algorithm, formulated by Yoav Freund and Robert Schapire. It is a meta-algorithm, and can be used in conjunction with many other learning algorithms to improve their performance. AdaBoost is adaptive in the sense that subsequent...
algorithm to select those blocks to be included in the rejecter cascade. In their experimentation, their algorithm achieved comparable performance to the original Dalal and Triggs algorithm, but operated at speeds up to 70 times faster. In April 2006, the Mitsubishi Electric Research Laboratories applied for the U.S. Patent of this algorithm under application number 20070237387.
See also
- Corner detectionCorner detectionCorner detection is an approach used within computer vision systems to extract certain kinds of features and infer the contents of an image. Corner detection is frequently used in motion detection, image registration, video tracking, image mosaicing, panorama stitching, 3D modelling and object...
- Feature (computer vision)Feature (Computer vision)In computer vision and image processing the concept of feature is used to denote a piece of information which is relevant for solving the computational task related to a certain application...
- Feature detection (computer vision)
- Feature extractionFeature extractionIn pattern recognition and in image processing, feature extraction is a special form of dimensionality reduction.When the input data to an algorithm is too large to be processed and it is suspected to be notoriously redundant then the input data will be transformed into a reduced representation...
- Interest point detectionInterest point detectionInterest point detection is a recent terminology in computer vision that refers to the detection of interest points for subsequent processing...
- Object recognitionObject recognitionObject recognition in computer vision is the task of finding a given object in an image or video sequence. Humans recognize a multitude of objects in images with little effort, despite the fact that the image of the objects may vary somewhat in different view points, in many different sizes / scale...
- Scale-invariant feature transformScale-invariant feature transformScale-invariant feature transform is an algorithm in computer vision to detect and describe local features in images. The algorithm was published by David Lowe in 1999....
External links
- http://www.mathworks.com/matlabcentral/fileexchange/33863 An implementation for Matlab (mex file)
- http://www.cs.cmu.edu/~yke/pcasift/ - Code for PCA-SIFT Object Detection
- http://lear.inrialpes.fr/software/ - Software Toolkit for HOG Object Detection (Research Team homepage)
- http://www.navneetdalal.com/software/ - Software Toolkit for HOG Object Detection (Navneet Dalal homepage)
- http://pascal.inrialpes.fr/data/human/ - INRIA Human Image Dataset
- http://cbcl.mit.edu/software-datasets/PedestrianData.html - MIT Pedestrian Image Dataset