

SimRank
Encyclopedia
SimRank is a general similarity measure
, based on a simple and intuitive graph-theoretic model
.
SimRank is applicable in any domain
with object-to-object relationships
, that measures similarity of the structural context in which objects occur, based on their relationships with other objects.
Effectively, SimRank is a measure that says "two objects are similar if they are related to similar objects."
require a measure of "similarity" between objects.
One obvious example is the "find-similar-document" query,
on traditional text corpora or the World-Wide Web
.
More generally, a similarity measure can be used to cluster objects, such as for collaborative filtering
in a recommender system, in which “similar” users and items are grouped based on the users’ preferences.
Various aspects of objects can be used to determine similarity, usually depending on the domain and the appropriate definition of similarity for that domain.
In a document corpus
, matching text may be used, and for collaborative filtering, similar users may be identified by common preferences.
SimRank is a general approach that exploits the object-to-object relationships found in many domains of interest.
On the Web
, for example, two pages are related if there are hyperlink
s between them.
A similar approach can be applied to scientific papers and their citations, or to any other document corpus with cross-reference
information.
In the case of recommender systems, a user’s preference for an item constitutes a relationship between the user and the item.
Such domains are naturally modeled as graphs
, with nodes
representing objects and edges representing relationships.
The intuition behind the SimRank algorithm is that, in many domains, similar objects are related to similar objects.
More precisely, objects and
and  are similar if they are related to objects
are similar if they are related to objects  and
and 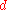 , respectively, and
, respectively, and  and
and 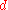 are themselves similar.
are themselves similar.
The base case is that objects are similar to themselves
.
It is important to note that SimRank is a general algorithm that determines only the similarity of structural context.
SimRank applies to any domain where there are enough relevant relationships between objects to base at least some notion of similarity on relationships.
Obviously, similarity of other domain-specific aspects are important as well; these can — and should be combined with relational structural-context similarity for an overall similarity measure.
For example, for Web page
s SimRank can be combined with traditional textual similarity; the same idea applies to scientific papers or other document corpora.
For recommender systems, there may be built-in known similarities between items (e.g., both computers, both clothing, etc.), as well as similarities between users (e.g., same gender, same spending level).
Again, these similarities can be combined with the similarity scores that are computed based on preference patterns, in order to produce an overall similarity measure.
 in a graph, we denote by
in a graph, we denote by 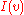 and
and 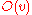 the set of in-neighbors and out-neighbors of
the set of in-neighbors and out-neighbors of  , respectively.
, respectively.
Individual in-neighbours are denoted as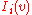 , for
, for  , and individual
, and individual
out-neighbors are denoted as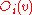 , for
, for 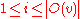 .
.
Let us denote the similarity between objects and
and  by
by 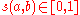 .
.
Following the earlier motivation, a recursive equation is written for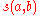 .
.
If then
then 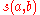 is defined to be
is defined to be 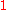 .
.
Otherwise,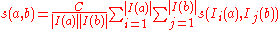
where is a constant between
is a constant between  and
and 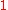 .
.
A slight technicality here is that either or
or  may not have any in-neighbors.
may not have any in-neighbors.
Since there is no way to infer any similarity between and
and  in this case, similarity is set to
in this case, similarity is set to 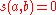 , so the summation in the above equation is defined to be
, so the summation in the above equation is defined to be  when
when 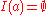 or
or 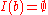 .
.
 can be reached by iteration
can be reached by iteration
to a fixed-point
.
Let be the number of nodes in
be the number of nodes in  .
.
For each iteration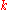 , we can keep
, we can keep 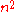 entries
entries 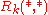 of length
of length 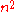 , where
, where 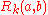 gives the score between
gives the score between  and
and  on iteration
on iteration 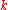 .
.
We successively compute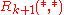 based on
based on 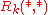 .
.
We start with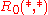 where each
where each 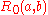 is a lower bound on the actual SimRank score
is a lower bound on the actual SimRank score 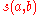 :
: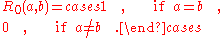
To compute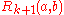 from
from 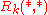 , we use the basic SimRank equation to get:
, we use the basic SimRank equation to get: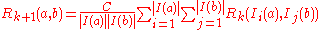
for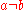 , and
, and 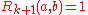 for
for  .
.
That is, on each iteration , we update the similarity of
, we update the similarity of 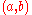 using the similarity scores of the neighbours of
using the similarity scores of the neighbours of 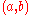 from the previous iteration
from the previous iteration 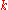 according to the basic SimRank equation.
according to the basic SimRank equation.
The values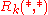 are nondecreasing
are nondecreasing
as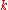 increases.
increases.
It was shown in that the values converge
to limits
satisfying the basic SimRank equation, the SimRank scores , i.e., for all
, i.e., for all  ,
, 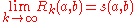 .
.
The original SimRank proposal suggested choosing the decay factor and a fixed number
and a fixed number  of iterations to perform.
of iterations to perform.
However, the recent research showed that the given values for and
and  generally imply relatively low accuracy
generally imply relatively low accuracy
of iteratively computed SimRank scores.
For guaranteeing more accurate computation results, the latter paper suggests either using a smaller decay factor (in particular, ) or taking more iterations.
) or taking more iterations.
Semantic similarity
Semantic similarity or semantic relatedness is a concept whereby a set of documents or terms within term lists are assigned a metric based on the likeness of their meaning / semantic content....
, based on a simple and intuitive graph-theoretic model
Graph theory
In mathematics and computer science, graph theory is the study of graphs, mathematical structures used to model pairwise relations between objects from a certain collection. A "graph" in this context refers to a collection of vertices or 'nodes' and a collection of edges that connect pairs of...
.
SimRank is applicable in any domain
Domain model
A domain model in problem solving and software engineering can be thought of as a conceptual model of a domain of interest which describes the various entities, their attributes, roles and relationships, plus the constraints that govern the integrity of the model elements comprising that problem...
with object-to-object relationships
Relation (mathematics)
In set theory and logic, a relation is a property that assigns truth values to k-tuples of individuals. Typically, the property describes a possible connection between the components of a k-tuple...
, that measures similarity of the structural context in which objects occur, based on their relationships with other objects.
Effectively, SimRank is a measure that says "two objects are similar if they are related to similar objects."
Introduction
Many applicationsApplication software
Application software, also known as an application or an "app", is computer software designed to help the user to perform specific tasks. Examples include enterprise software, accounting software, office suites, graphics software and media players. Many application programs deal principally with...
require a measure of "similarity" between objects.
One obvious example is the "find-similar-document" query,
on traditional text corpora or the World-Wide Web
World Wide Web
The World Wide Web is a system of interlinked hypertext documents accessed via the Internet...
.
More generally, a similarity measure can be used to cluster objects, such as for collaborative filtering
Collaborative filtering
Collaborative filtering is the process of filtering for information or patterns using techniques involving collaboration among multiple agents, viewpoints, data sources, etc. Applications of collaborative filtering typically involve very large data sets...
in a recommender system, in which “similar” users and items are grouped based on the users’ preferences.
Various aspects of objects can be used to determine similarity, usually depending on the domain and the appropriate definition of similarity for that domain.
In a document corpus
Text corpus
In linguistics, a corpus or text corpus is a large and structured set of texts...
, matching text may be used, and for collaborative filtering, similar users may be identified by common preferences.
SimRank is a general approach that exploits the object-to-object relationships found in many domains of interest.
On the Web
World Wide Web
The World Wide Web is a system of interlinked hypertext documents accessed via the Internet...
, for example, two pages are related if there are hyperlink
Hyperlink
In computing, a hyperlink is a reference to data that the reader can directly follow, or that is followed automatically. A hyperlink points to a whole document or to a specific element within a document. Hypertext is text with hyperlinks...
s between them.
A similar approach can be applied to scientific papers and their citations, or to any other document corpus with cross-reference
Cross-reference
A cross-reference is an instance within a document which refers to related or synonymous information elsewhere, usually within the same work. To cross-reference or to cross-refer is to make such connections. The term "cross-reference" is often abbreviated as x-ref, xref, or, in computer science,...
information.
In the case of recommender systems, a user’s preference for an item constitutes a relationship between the user and the item.
Such domains are naturally modeled as graphs
Graph (mathematics)
In mathematics, a graph is an abstract representation of a set of objects where some pairs of the objects are connected by links. The interconnected objects are represented by mathematical abstractions called vertices, and the links that connect some pairs of vertices are called edges...
, with nodes
Vertex (graph theory)
In graph theory, a vertex or node is the fundamental unit out of which graphs are formed: an undirected graph consists of a set of vertices and a set of edges , while a directed graph consists of a set of vertices and a set of arcs...
representing objects and edges representing relationships.
The intuition behind the SimRank algorithm is that, in many domains, similar objects are related to similar objects.
More precisely, objects
and are similar if they are related to objects and , respectively, and and are themselves similar.The base case is that objects are similar to themselves
.
It is important to note that SimRank is a general algorithm that determines only the similarity of structural context.
SimRank applies to any domain where there are enough relevant relationships between objects to base at least some notion of similarity on relationships.
Obviously, similarity of other domain-specific aspects are important as well; these can — and should be combined with relational structural-context similarity for an overall similarity measure.
For example, for Web page
Web page
A web page or webpage is a document or information resource that is suitable for the World Wide Web and can be accessed through a web browser and displayed on a monitor or mobile device. This information is usually in HTML or XHTML format, and may provide navigation to other web pages via hypertext...
s SimRank can be combined with traditional textual similarity; the same idea applies to scientific papers or other document corpora.
For recommender systems, there may be built-in known similarities between items (e.g., both computers, both clothing, etc.), as well as similarities between users (e.g., same gender, same spending level).
Again, these similarities can be combined with the similarity scores that are computed based on preference patterns, in order to produce an overall similarity measure.
Basic SimRank equation
For a node in a graph, we denote by and the set of in-neighbors and out-neighbors of , respectively.Individual in-neighbours are denoted as
, for , and individualout-neighbors are denoted as
, for .Let us denote the similarity between objects
and by .Following the earlier motivation, a recursive equation is written for
.If
then is defined to be .Otherwise,
where
is a constant between and .A slight technicality here is that either
or may not have any in-neighbors.Since there is no way to infer any similarity between
and in this case, similarity is set to , so the summation in the above equation is defined to be when or .Computing SimRank
A solution to the SimRank equations for a graph can be reached by iterationIterative method
In computational mathematics, an iterative method is a mathematical procedure that generates a sequence of improving approximate solutions for a class of problems. A specific implementation of an iterative method, including the termination criteria, is an algorithm of the iterative method...
to a fixed-point
Fixed point (mathematics)
In mathematics, a fixed point of a function is a point that is mapped to itself by the function. A set of fixed points is sometimes called a fixed set...
.
Let
be the number of nodes in .For each iteration
, we can keep entries of length , where gives the score between and on iteration .We successively compute
based on .We start with
where each is a lower bound on the actual SimRank score :To compute
from , we use the basic SimRank equation to get:for
, and for .That is, on each iteration
, we update the similarity of using the similarity scores of the neighbours of from the previous iteration according to the basic SimRank equation.The values
are nondecreasingMonotonic function
In mathematics, a monotonic function is a function that preserves the given order. This concept first arose in calculus, and was later generalized to the more abstract setting of order theory....
as
increases.It was shown in that the values converge
Limit of a sequence
The limit of a sequence is, intuitively, the unique number or point L such that the terms of the sequence become arbitrarily close to L for "large" values of n...
to limits
Limit of a sequence
The limit of a sequence is, intuitively, the unique number or point L such that the terms of the sequence become arbitrarily close to L for "large" values of n...
satisfying the basic SimRank equation, the SimRank scores
, i.e., for all , .The original SimRank proposal suggested choosing the decay factor
and a fixed number of iterations to perform.However, the recent research showed that the given values for
and generally imply relatively low accuracyAccuracy and precision
In the fields of science, engineering, industry and statistics, the accuracy of a measurement system is the degree of closeness of measurements of a quantity to that quantity's actual value. The precision of a measurement system, also called reproducibility or repeatability, is the degree to which...
of iteratively computed SimRank scores.
For guaranteeing more accurate computation results, the latter paper suggests either using a smaller decay factor (in particular,
) or taking more iterations.Further research on SimRank
- Fogaras and Racz suggested speeding up SimRank computation through probabilisticProbability theoryProbability theory is the branch of mathematics concerned with analysis of random phenomena. The central objects of probability theory are random variables, stochastic processes, and events: mathematical abstractions of non-deterministic events or measured quantities that may either be single...
computation using the Monte Carlo methodMonte Carlo methodMonte Carlo methods are a class of computational algorithms that rely on repeated random sampling to compute their results. Monte Carlo methods are often used in computer simulations of physical and mathematical systems...
.
- Antonellis et al. extended SimRank equations to take into consideration (i) evidence factor for incident nodes and (ii) link weights.
- Lizorkin et al. proposed several optimizationOptimization (computer science)In computer science, program optimization or software optimization is the process of modifying a software system to make some aspect of it work more efficiently or use fewer resources...
techniques for speeding up SimRank iterative computation.