

Sulston score
Encyclopedia
The Sulston Score is an equation used in DNA mapping to numerically assess the likelihood that a given "fingerprint" similarity between two DNA clones is merely a result of chance. Used as such, it is a test of statistical significance
. That is, low values imply that similarity is significant, suggesting that two DNA clones overlap one another and that the given similarity is not just a chance event. The name is an eponym
that refers to John Sulston by virtue of his being the lead author of the paper that first proposed the equation's use.
classify overlap status.
and Binomial processes, as follows. Consider two clones, and
and 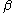 , having
, having  and
and  measured fragment lengths, respectively, where
measured fragment lengths, respectively, where  . That is, clone
. That is, clone  has at least as many fragments as clone
has at least as many fragments as clone 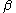 , but usually more. The Sulston score is the probability that at least
, but usually more. The Sulston score is the probability that at least 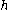 fragment lengths on clone
fragment lengths on clone  will be matched by any combination of lengths on
will be matched by any combination of lengths on  . Intuitively, we see that, at most, there can be
. Intuitively, we see that, at most, there can be  matches. Thus, for a given comparison between two clones, one can measure the statistical significance of a match of
matches. Thus, for a given comparison between two clones, one can measure the statistical significance of a match of 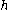 fragments, i.e. how likely it is that this match occurred simply as a result of random chance. Very low values would indicate a significant match that is highly unlikely to have arisen by pure chance, while higher values would suggest that the given match could be just a coincidence.
fragments, i.e. how likely it is that this match occurred simply as a result of random chance. Very low values would indicate a significant match that is highly unlikely to have arisen by pure chance, while higher values would suggest that the given match could be just a coincidence.
, it is not actually the distribution characteristic of the fingerprint problem. Wendl went on to give the general solution for this problem in terms of the Bell polynomials, showing the traditional score overpredicts P-values by orders of magnitude. (P-values are very small in this problem, so we are talking, for example, about probabilities on the order of 10e-14 versus 10e-12, the latter Sulston value being 2 orders of magnitude too high.) This solution provides a basis for determining when a problem has sufficient information content to be treated by the probabilistic approach and is also a general solution to the birthday problem of 2 types.
A disadvantage of the exact solution is that its evaluation is computationally intensive and, in fact, is not feasible for comparing large clones. Some fast approximations for this problem have been proposed.
Statistical significance
In statistics, a result is called statistically significant if it is unlikely to have occurred by chance. The phrase test of significance was coined by Ronald Fisher....
. That is, low values imply that similarity is significant, suggesting that two DNA clones overlap one another and that the given similarity is not just a chance event. The name is an eponym
Eponym
An eponym is the name of a person or thing, whether real or fictitious, after which a particular place, tribe, era, discovery, or other item is named or thought to be named...
that refers to John Sulston by virtue of his being the lead author of the paper that first proposed the equation's use.
The Overlap Problem in Mapping
Each clone in a DNA mapping project has a "fingerprint", i.e. a set of DNA fragment lengths inferred from (1) enzymatically digesting the clone, (2) separating these fragments on a gel, and (3) estimating their lengths based on gel location. For each pairwise clone comparison, one can establish how many lengths from each set match-up. Cases having at least 1 match indicate that the clones might overlap because matches may represent the same DNA. However, the underlying sequences for each match are not known. Consequently, two fragments whose lengths match may still represent different sequences. In other words, matches do not conclusively indicate overlaps. The problem is instead one of using matches to probabilisticallyProbability
Probability is ordinarily used to describe an attitude of mind towards some proposition of whose truth we arenot certain. The proposition of interest is usually of the form "Will a specific event occur?" The attitude of mind is of the form "How certain are we that the event will occur?" The...
classify overlap status.
Mathematical Scores in Overlap Assessment
Biologists have used a variety of means (often in combination) to discern clone overlaps in DNA mapping projects. While many are biological, i.e. looking for shared markers, others are basically mathematical, usually adopting probabilistic and/or statistical approaches.Sulston Score Exposition
The Sulston Score is rooted in the concepts of BernoulliBernoulli process
In probability and statistics, a Bernoulli process is a finite or infinite sequence of binary random variables, so it is a discrete-time stochastic process that takes only two values, canonically 0 and 1. The component Bernoulli variables Xi are identical and independent...
and Binomial processes, as follows. Consider two clones,
and , having and measured fragment lengths, respectively, where . That is, clone has at least as many fragments as clone , but usually more. The Sulston score is the probability that at least fragment lengths on clone will be matched by any combination of lengths on . Intuitively, we see that, at most, there can be matches. Thus, for a given comparison between two clones, one can measure the statistical significance of a match of fragments, i.e. how likely it is that this match occurred simply as a result of random chance. Very low values would indicate a significant match that is highly unlikely to have arisen by pure chance, while higher values would suggest that the given match could be just a coincidence.| Derivation of the Sulston Score |
|---|
One of the basic assumptions is that fragments are uniformly distributed on a gel, i.e. a fragment has an equal likelihood of appearing anywhere on the gel. Since gel position is an indicator of fragment length, this assumption is equivalent to presuming that the fragment lengths are uniformly distributed. The measured location of any fragment  , has an associated error tolerance of , has an associated error tolerance of  , so that its true location is only known to lie within the segment , so that its true location is only known to lie within the segment 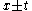 . .In what follows, let us refer to individual fragment lengths simply as lengths. Consider a specific length 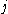 on clone on clone  and a specific length and a specific length 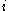 on clone on clone  . These two lengths are arbitrarily selected from their respective sets . These two lengths are arbitrarily selected from their respective sets 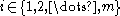 and and 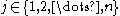 . We assume that the gel location of fragment . We assume that the gel location of fragment 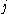 has been determined and we want has been determined and we wantthe probability of the event 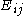 that the location of fragment that the location of fragment 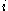 will match that of will match that of  . Geometrically, . Geometrically, 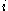 will be declared to match will be declared to match 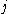 if it falls inside the window of size if it falls inside the window of size 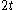 around around 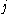 . Since fragment . Since fragment 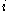 could occur anywhere in the gel of length could occur anywhere in the gel of length 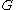 , we have , we have 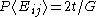 . The probability that . The probability that 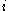 does not match does not match 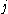 is simply the complement, i.e. is simply the complement, i.e. 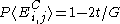 , since it must either match or not match. , since it must either match or not match.Now, let us expand this to compute the probability that no length on clone  matches the single particular length matches the single particular length 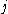 on clone on clone  . This is simply the intersection of all individual trials . This is simply the intersection of all individual trials 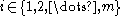 where the event where the event 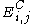 occurs, i.e. occurs, i.e.  . This can be restated verbally as: length 1 on clone . This can be restated verbally as: length 1 on clone  does not match length does not match length 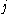 on clone on clone 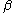 and length 2 does not match length and length 2 does not match length 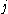 and length 3 does not match, etc. Since each of these trials is assumed to be independent, the probability is simply and length 3 does not match, etc. Since each of these trials is assumed to be independent, the probability is simply . .Of course, the actual event of interest is the complement: i.e. there is not "no matches". In other words, the probability of one or more matches is 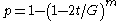 . Formally, . Formally,  is the probability that at least one band on clone is the probability that at least one band on clone  matches band matches band  on clone on clone 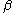 . .This event is taken as a Bernoulli trial Bernoulli trial In the theory of probability and statistics, a Bernoulli trial is an experiment whose outcome is random and can be either of two possible outcomes, "success" and "failure".... having a "success" (matching) probability of  for band for band  . However, we want to describe the process over all the bands on clone . However, we want to describe the process over all the bands on clone 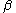 . Since . Since 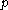 is constant, the number of matches is distributed binomially. Given is constant, the number of matches is distributed binomially. Given 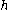 observed matches, the Sulston score observed matches, the Sulston score 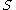 is simply the probability of obtaining at least is simply the probability of obtaining at least 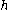 matches by chance according to matches by chance according to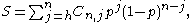 where 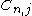 are binomial coefficient are binomial coefficientBinomial coefficient In mathematics, binomial coefficients are a family of positive integers that occur as coefficients in the binomial theorem. They are indexed by two nonnegative integers; the binomial coefficient indexed by n and k is usually written \tbinom nk , and it is the coefficient of the x k term in... s. |
Mathematical Refinement
In a 2005 paper, Michael Wendl gave an example showing that the assumption of independent trials is not valid. So, although the traditional Sulston score does indeed represent a Probability distributionProbability distribution
In probability theory, a probability mass, probability density, or probability distribution is a function that describes the probability of a random variable taking certain values....
, it is not actually the distribution characteristic of the fingerprint problem. Wendl went on to give the general solution for this problem in terms of the Bell polynomials, showing the traditional score overpredicts P-values by orders of magnitude. (P-values are very small in this problem, so we are talking, for example, about probabilities on the order of 10e-14 versus 10e-12, the latter Sulston value being 2 orders of magnitude too high.) This solution provides a basis for determining when a problem has sufficient information content to be treated by the probabilistic approach and is also a general solution to the birthday problem of 2 types.
A disadvantage of the exact solution is that its evaluation is computationally intensive and, in fact, is not feasible for comparing large clones. Some fast approximations for this problem have been proposed.
See also
- FPC: a widely-used fingerprint mapping program that utilizes the Sulston Score