

Term Discrimination
Encyclopedia
Term Discrimination is a way to rank keywords in how useful they are for Information Retrieval
.
and ones that are not. Please refer to Vector Space Model
first.
This method uses the concept of Vector Space Density that the less dense an occurrence matrix is, the better an information retrieval query will be.
An optimal index term is one that can distinguish two different documents from each other and relate two similar documents. On the other hand, a sub-optimal index term can not distinguish two different document from two similar documents.
The discrimination value is the difference in the occurrence matrix's vector-space density versus the same matrix's vector-space without the index term's density.
Let:
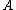 be the occurrence matrix
be the occurrence matrix
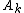 be the occurrence matrix without the index term
be the occurrence matrix without the index term 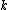
and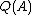 be density of
be density of 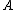 .
.
Then:
The discrimination value of the index term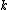 is:
is:
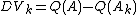
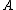 and one keyword:
and one keyword: 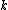
A higher value is better because including the keyword will result in better information retrieval.
should be poor discriminators because they have poor recall
,
where as
keywords that are frequent should be poor discriminators because they have poor precision
.
Information retrieval
Information retrieval is the area of study concerned with searching for documents, for information within documents, and for metadata about documents, as well as that of searching structured storage, relational databases, and the World Wide Web...
.
Overview
This is a method similar to tf-idf but it deals with finding keywords suitable for information retrievalInformation retrieval
Information retrieval is the area of study concerned with searching for documents, for information within documents, and for metadata about documents, as well as that of searching structured storage, relational databases, and the World Wide Web...
and ones that are not. Please refer to Vector Space Model
Vector space model
Vector space model is an algebraic model for representing text documents as vectors of identifiers, such as, for example, index terms. It is used in information filtering, information retrieval, indexing and relevancy rankings...
first.
This method uses the concept of Vector Space Density that the less dense an occurrence matrix is, the better an information retrieval query will be.
An optimal index term is one that can distinguish two different documents from each other and relate two similar documents. On the other hand, a sub-optimal index term can not distinguish two different document from two similar documents.
The discrimination value is the difference in the occurrence matrix's vector-space density versus the same matrix's vector-space without the index term's density.
Let:
be the occurrence matrix be the occurrence matrix without the index term and
be density of .Then:
The discrimination value of the index term
is:How to compute
Given an occurrency matrix: and one keyword:
- Find the global document centroidCentroidIn geometry, the centroid, geometric center, or barycenter of a plane figure or two-dimensional shape X is the intersection of all straight lines that divide X into two parts of equal moment about the line. Informally, it is the "average" of all points of X...
: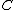 (this is just the average document vector)
(this is just the average document vector) - Find the average euclidean distanceEuclidean distanceIn mathematics, the Euclidean distance or Euclidean metric is the "ordinary" distance between two points that one would measure with a ruler, and is given by the Pythagorean formula. By using this formula as distance, Euclidean space becomes a metric space...
from every document vector,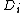 to
to 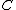
- Find the average euclidean distance from every document vector,
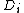 to
to 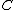 IGNORING
IGNORING 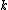
- The difference between the two values in the above step is the discrimination value for keyword
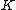
A higher value is better because including the keyword will result in better information retrieval.
Qualitative Observations
Keywords that are sparseSparse matrix
In the subfield of numerical analysis, a sparse matrix is a matrix populated primarily with zeros . The term itself was coined by Harry M. Markowitz....
should be poor discriminators because they have poor recall
Precision and recall
In pattern recognition and information retrieval, precision is the fraction of retrieved instances that are relevant, while recall is the fraction of relevant instances that are retrieved. Both precision and recall are therefore based on an understanding and measure of relevance...
,
where as
keywords that are frequent should be poor discriminators because they have poor precision
Precision and recall
In pattern recognition and information retrieval, precision is the fraction of retrieved instances that are relevant, while recall is the fraction of relevant instances that are retrieved. Both precision and recall are therefore based on an understanding and measure of relevance...
.