

Vector space model
Encyclopedia
Vector space model is an algebraic model for representing text documents (and any objects, in general) as vectors
of identifiers, such as, for example, index terms. It is used in information filtering, information retrieval
, indexing and relevancy rankings. Its first use was in the SMART Information Retrieval System
.
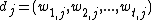
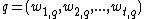
Each dimension
corresponds to a separate term. If a term occurs in the document, its value in the vector is non-zero. Several different ways of computing these values, also known as (term) weights, have been developed. One of the best known schemes is tf-idf weighting (see the example below).
The definition of term depends on the application. Typically terms are single words, keyword
s, or longer phrases. If the words are chosen to be the terms, the dimensionality of the vector is the number of words in the vocabulary (the number of distinct words occurring in the corpus
).
Vector operations can be used to compare documents with queries.
ranking
s of documents in a keyword search can be calculated, using the assumptions of document similarities
theory, by comparing the deviation of angles between each document vector and the original query vector where the query is represented as same kind of vector as the documents.
In practice, it is easier to calculate the cosine of the angle between the vectors, instead of the angle itself:
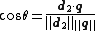
Where is the intersection (i.e. that dot product
is the intersection (i.e. that dot product
) of the document (d2 in the figure to the right) and the query (q in the figure) vectors, is the norm of vector d2, and
is the norm of vector d2, and 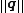 is the norm of vector q. The norm
is the norm of vector q. The norm
of a vector is calculated as such:
As all vectors under consideration by this model are elementwise nonnegative, a cosine value of zero means that the query and document vector are orthogonal and have no match (i.e. the query term does not exist in the document being considered). See cosine similarity
for further information.
, Wong and Yang the term specific weights in the document vectors are products of local and global parameters. The model is known as term frequency-inverse document frequency model. The weight vector for document d is , where
, where

and
Using the cosine the similarity between document dj and query q can be calculated as:
In a simpler Term Count Model the term specific weights do not include the global parameter. Instead the weights are just the counts of term occurrences: .
.
:
Many of these difficulties can, however, be overcome by the integration of various tools, including mathematical techniques such as singular value decomposition
and lexical database
s such as WordNet
.
Vector space
A vector space is a mathematical structure formed by a collection of vectors: objects that may be added together and multiplied by numbers, called scalars in this context. Scalars are often taken to be real numbers, but one may also consider vector spaces with scalar multiplication by complex...
of identifiers, such as, for example, index terms. It is used in information filtering, information retrieval
Information retrieval
Information retrieval is the area of study concerned with searching for documents, for information within documents, and for metadata about documents, as well as that of searching structured storage, relational databases, and the World Wide Web...
, indexing and relevancy rankings. Its first use was in the SMART Information Retrieval System
SMART Information Retrieval System
The SMART Information Retrieval System is an information retrieval system developed at Cornell University in the 1960s...
.
Definitions
Documents and queries are represented as vectors.Each dimension
Dimension (vector space)
In mathematics, the dimension of a vector space V is the cardinality of a basis of V. It is sometimes called Hamel dimension or algebraic dimension to distinguish it from other types of dimension...
corresponds to a separate term. If a term occurs in the document, its value in the vector is non-zero. Several different ways of computing these values, also known as (term) weights, have been developed. One of the best known schemes is tf-idf weighting (see the example below).
The definition of term depends on the application. Typically terms are single words, keyword
Keyword (linguistics)
In corpus linguistics a key word is a word which occurs in a text more often than we would expect to occur by chance alone. Key words are calculated by carrying out a statistical test which compares the word frequencies in a text against their expected frequencies derived in a much larger corpus,...
s, or longer phrases. If the words are chosen to be the terms, the dimensionality of the vector is the number of words in the vocabulary (the number of distinct words occurring in the corpus
Text corpus
In linguistics, a corpus or text corpus is a large and structured set of texts...
).
Vector operations can be used to compare documents with queries.
Applications
RelevanceRelevance (information retrieval)
In information science and information retrieval, relevance denotes how well a retrieved document or set of documents meets the information need of the user.-Types:...
ranking
Ranking
A ranking is a relationship between a set of items such that, for any two items, the first is either 'ranked higher than', 'ranked lower than' or 'ranked equal to' the second....
s of documents in a keyword search can be calculated, using the assumptions of document similarities
Semantic similarity
Semantic similarity or semantic relatedness is a concept whereby a set of documents or terms within term lists are assigned a metric based on the likeness of their meaning / semantic content....
theory, by comparing the deviation of angles between each document vector and the original query vector where the query is represented as same kind of vector as the documents.
In practice, it is easier to calculate the cosine of the angle between the vectors, instead of the angle itself:
Where
is the intersection (i.e. that dot productDot product
In mathematics, the dot product or scalar product is an algebraic operation that takes two equal-length sequences of numbers and returns a single number obtained by multiplying corresponding entries and then summing those products...
) of the document (d2 in the figure to the right) and the query (q in the figure) vectors,
is the norm of vector d2, and is the norm of vector q. The normNorm (mathematics)
In linear algebra, functional analysis and related areas of mathematics, a norm is a function that assigns a strictly positive length or size to all vectors in a vector space, other than the zero vector...
of a vector is calculated as such:
As all vectors under consideration by this model are elementwise nonnegative, a cosine value of zero means that the query and document vector are orthogonal and have no match (i.e. the query term does not exist in the document being considered). See cosine similarity
Cosine similarity
Cosine similarity is a measure of similarity between two vectors by measuring the cosine of the angle between them. The cosine of 0 is 1, and less than 1 for any other angle. The cosine of the angle between two vectors thus determines whether two vectors are pointing in roughly the same...
for further information.
Example: tf-idf weights
In the classic vector space model proposed by SaltonGerard Salton
Gerard Salton , also known as Gerry Salton, was a Professor of Computer Science at Cornell University. Salton was perhaps the leading computer scientist working in the field of information retrieval during his time...
, Wong and Yang the term specific weights in the document vectors are products of local and global parameters. The model is known as term frequency-inverse document frequency model. The weight vector for document d is
, whereand
-
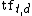 is term frequency of term t in document d (a local parameter)
is term frequency of term t in document d (a local parameter) -
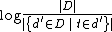 is inverse document frequency (a global parameter).
is inverse document frequency (a global parameter).  is the total number of documents in the document set;
is the total number of documents in the document set; 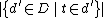 is the number of documents containing the term t.
is the number of documents containing the term t.
Using the cosine the similarity between document dj and query q can be calculated as:
In a simpler Term Count Model the term specific weights do not include the global parameter. Instead the weights are just the counts of term occurrences:
.Advantages
The vector space model has the following advantages over the Standard Boolean modelStandard Boolean model
The Boolean model of information retrieval is a classical information retrieval model and, at the same time, the first and most adopted one. It is used by virtually all commercial IR systems today.-Definitions:...
:
- Simple model based on linear algebra
- Term weights not binary
- Allows computing a continuous degree of similarity between queries and documents
- Allows ranking documents according to their possible relevance
- Allows partial matching
Limitations
The vector space model has the following limitations:- Long documents are poorly represented because they have poor similarity values (a small scalar product and a large dimensionalityCurse of dimensionalityThe curse of dimensionality refers to various phenomena that arise when analyzing and organizing high-dimensional spaces that do not occur in low-dimensional settings such as the physical space commonly modeled with just three dimensions.There are multiple phenomena referred to by this name in...
) - Search keywords must precisely match document terms; word substringSubstringA subsequence, substring, prefix or suffix of a string is a subset of the symbols in a string, where the order of the elements is preserved...
s might result in a "false positive match" - Semantic sensitivity; documents with similar context but different term vocabulary won't be associated, resulting in a "false negative match".
- The order in which the terms appear in the document is lost in the vector space representation.
- Assumes terms are statistically independent
- Weighting is intuitive but not very formal
Many of these difficulties can, however, be overcome by the integration of various tools, including mathematical techniques such as singular value decomposition
Singular value decomposition
In linear algebra, the singular value decomposition is a factorization of a real or complex matrix, with many useful applications in signal processing and statistics....
and lexical database
Lexical database
A lexical database is a lexical resource which has an associated software environment database which permits access to its contents. The database may be custom-designed for the lexical information or a general-purpose database into which lexical information has been entered.Information typically...
s such as WordNet
WordNet
WordNet is a lexical database for the English language. It groups English words into sets of synonyms called synsets, provides short, general definitions, and records the various semantic relations between these synonym sets...
.
Models based on and extending the vector space model
Models based on and extending the vector space model include:- Generalized vector space modelGeneralized vector space modelThe Generalized vector space model is a generalization of the vector space model used in information retrieval. Wong et al. presented an analysis of the problems that the pairwise orthogonality assumption of the Vector space model creates...
- (enhanced) Topic-based Vector Space ModelTopic-based vector space modelThe Topic-based Vector Space Model extends the Vector space model by removing the constraint that the term-vectors be orthogonal. The assumption of orthogonal terms is incorrect regarding natural languages which causes problems with synonyms and strong related terms...
- Latent semantic analysisLatent semantic analysisLatent semantic analysis is a technique in natural language processing, in particular in vectorial semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close...
- Latent semantic indexingLatent semantic indexingLatent Semantic Indexing is an indexing and retrieval method that uses a mathematical technique called Singular value decomposition to identify patterns in the relationships between the terms and concepts contained in an unstructured collection of text. LSI is based on the principle that words...
- DSIR model
- Term DiscriminationTerm DiscriminationTerm Discrimination is a way to rank keywords in how useful they are for Information Retrieval.- Overview :This is a method similar to tf-idf but it deals with finding keywords suitable for information retrieval and ones that are not...
- Rocchio ClassificationRocchio ClassificationRocchio Classification is based on a method of relevance feedback found in information retrieval systems which stemmed from the SMART Information Retrieval System around the year 1970. Like many other retrieval systems, the Rocchio feedback approach was developed using the Vector Space Model...
Software that implements the vector space model
The following software packages may be of interest to those wishing to experiment with vector models and implement search services based upon them.Free open source software
- Apache Lucene. Apache Lucene is a high-performance, full-featured text search engine library written entirely in Java.
- SemanticVectors. Semantic Vector indexes, created by applying a Random Projection algorithm (similar to Latent semantic analysisLatent semantic analysisLatent semantic analysis is a technique in natural language processing, in particular in vectorial semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close...
) to term-document matrices created using Apache Lucene. - Gensim is a Python+NumPy framework for Vector Space modelling. It contains incremental (memory-efficient) algorithms for Tf–idfTf–idfThe tf–idf weight is a weight often used in information retrieval and text mining. This weight is a statistical measure used to evaluate how important a word is to a document in a collection or corpus...
, Latent Semantic IndexingLatent semantic indexingLatent Semantic Indexing is an indexing and retrieval method that uses a mathematical technique called Singular value decomposition to identify patterns in the relationships between the terms and concepts contained in an unstructured collection of text. LSI is based on the principle that words...
, Random Projections and Latent Dirichlet AllocationLatent Dirichlet allocationIn statistics, latent Dirichlet allocation is a generative model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar...
. - Compressed vector space in C++ by Antonio Gulli
- Text to Matrix Generator (TMG) MATLAB toolbox that can be used for various tasks in text mining specifically i) indexing, ii) retrieval, iii) dimensionality reduction, iv) clustering, v) classification. Most of TMG is written in MATLAB and parts in Perl. It contains implementations of LSI, clustered LSI, NMF and other methods.
- SenseClusters, an open source package that supports context and word clustering using Latent Semantic Analysis and word co-occurrence matrices.
- S-Space Package, a collection of algorithms for exploring and working with statistical semanticsStatistical semanticsStatistical semantics is the study of "how the statistical patterns of human word usage can be used to figure out what people mean, at least to a level sufficient for information access"...
.
Further reading
- G. SaltonGerard SaltonGerard Salton , also known as Gerry Salton, was a Professor of Computer Science at Cornell University. Salton was perhaps the leading computer scientist working in the field of information retrieval during his time...
, A. Wong, and C. S. Yang (1975), "A Vector Space Model for Automatic Indexing," Communications of the ACM, vol. 18, nr. 11, pages 613–620. (Article in which a vector space model was presented) - David Dubin (2004), The Most Influential Paper Gerard Salton Never Wrote (Explains the history of the Vector Space Model and the non-existence of a frequently cited publication)
- Description of the vector space model
- Description of the classic vector space model by Dr E Garcia