

.
Background
Many filtering and control methods represent estimates of the state of a system in the form of a mean vector and an associated error covariance matrix. As an example, the estimated 2-dimensional position of an object of interest might be represented by a mean position vector,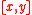 , with an uncertainty given in the form of a 2x2 covariance matrix giving the variance in
, with an uncertainty given in the form of a 2x2 covariance matrix giving the variance in  , the variance in
, the variance in 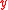 , and the cross covariance between the two. A covariance that is zero implies that there is no uncertainty or error and that the position of the object is exactly what is specified by the mean vector.
, and the cross covariance between the two. A covariance that is zero implies that there is no uncertainty or error and that the position of the object is exactly what is specified by the mean vector.The mean and covariance representation only gives the first two moments of an underlying, but otherwise unknown, probability distribution. In the case of a moving object, the unknown probability distribution might represent the uncertainty of the object's position at a given time. The mean and covariance representation of uncertainty is mathematically convenient because any linear transformation
 can be applied to a mean vector
can be applied to a mean vector  and covariance matrix
and covariance matrix 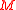 as
as  and
and 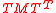 . This linearity property does not hold for moments beyond the first central moment (the mean) and the second central moment (the covariance), so it is not generally possible to determine the mean and covariance resulting from a nonlinear transformation because the result depends on all the moments, and only the first two are given.
. This linearity property does not hold for moments beyond the first central moment (the mean) and the second central moment (the covariance), so it is not generally possible to determine the mean and covariance resulting from a nonlinear transformation because the result depends on all the moments, and only the first two are given.Although the covariance matrix is often treated as being the expected squared error associated with the mean, in practice the matrix is maintained as an upper bound on the actual squared error. Specifically, a mean and covariance estimate
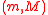 is conservatively maintained so that the covariance matrix
is conservatively maintained so that the covariance matrix 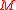 is greater than or equal to the actual squared error associated with
is greater than or equal to the actual squared error associated with  . Mathematically this means that the result of subtracting the expected squared error (which is not usually known) from
. Mathematically this means that the result of subtracting the expected squared error (which is not usually known) from 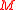 is a semidefinite or positive-definite matrix
is a semidefinite or positive-definite matrix. The reason for maintaining a conservative covariance estimate is that most filtering and control algorithms will tend to diverge (fail) if the covariance is underestimated. This is because a spuriously small covariance implies less uncertainty and leads the filter to place more weight (confidence) than is justified in the accuracy of the mean.
Returning to the example above, when the covariance is zero it is trivial to determine the location of the object after it moves according to an arbitrary nonlinear function
 : just apply the function to the mean vector. When the covariance is not zero the transformed mean will not generally be equal to
: just apply the function to the mean vector. When the covariance is not zero the transformed mean will not generally be equal to  and it is not even possible to determine the mean of the transformed probability distribution from only its prior mean and covariance. Given this indeterminacy, the nonlinearly transformed mean and covariance can only be approximated. The earliest such approximation was to linearize the nonlinear function and apply the resulting Jacobian matrix to the given mean and covariance. This is the basis of the Extended Kalman Filter
and it is not even possible to determine the mean of the transformed probability distribution from only its prior mean and covariance. Given this indeterminacy, the nonlinearly transformed mean and covariance can only be approximated. The earliest such approximation was to linearize the nonlinear function and apply the resulting Jacobian matrix to the given mean and covariance. This is the basis of the Extended Kalman Filter(EKF), and although it was known to yield poor results in many circumstances, there was no practical alternative for many decades.
Motivation for the Unscented Transform
In 1994 Jeffrey Uhlmannnoted that the EKF takes a nonlinear function and partial distribution information (in the form of a mean and covariance estimate) of the state of a system but applies an approximation to the known function rather than to the imprecisely-known probability distribution. He suggested that a better approach would be to use the exact nonlinear function applied to an approximating probability distribution. The motivation for this approach is given in his doctoral dissertation, where the term Unscented Transform was first defined:
Consider the following intuition: With a fixed number of parameters it should be easier to approximate a given distribution than it is to approximate an arbitrary nonlinear function/transformation. Following this intuition, the goal is to find a parameterization that captures the mean and covariance information while at the same time permitting the direct propagation of the information through an arbitrary set of nonlinear equations. This can be accomplished by generating a discrete distribution having the same first and second (and possibly higher) moments, where each point in the discrete approximation can be directly transformed. The mean and covariance of the transformed ensemble can then be computed as the estimate of the nonlinear transformation of the original distribution. More generally, the application of a given nonlinear transformation to a discrete distribution of points, computed so as to capture a set of known statistics of an unknown distribution, is referred to as an unscented transformation.
In other words, the given mean and covariance information can be exactly encoded in a set of points, referred to as sigma points, which if treated as elements of a discrete probability distribution has mean and covariance equal to the given mean and covariance. This distribution can be propagated exactly by applying the nonlinear function to each point. The mean and covariance of the transformed set of points then represents the desired transformed estimate. The principal advantage of the approach is that the nonlinear function is fully exploited, as opposed to the EKF which replaces it with a linear one. Eliminating the need for linearization also provides advantages independent of any improvement in estimation quality. One immediate advantage is that the UT can be applied with any given function whereas linearization may not be possible for functions that are not differentiable. A practical advantage is that the UT can be easier to implement because it avoids the need to derive and implement a linearizing Jacobian matrix.
Computing the Unscented Transform
Uhlmann noted that sigma points are necessary and sufficient in the general case to define a discrete distribution having a given mean and covariance in
sigma points are necessary and sufficient in the general case to define a discrete distribution having a given mean and covariance in  dimensions. Consider the following simplex of points in two dimensions:
dimensions. Consider the following simplex of points in two dimensions: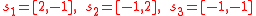
It can be verified that the above set of points has mean
 and covariance
and covariance  (the identity matrix). Given any 2-dimensional mean and covariance,
(the identity matrix). Given any 2-dimensional mean and covariance, 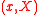 , the desired sigma points can be obtained by multiplying each point by the matrix square root of
, the desired sigma points can be obtained by multiplying each point by the matrix square root of  and adding
and adding  . A similar canonical set of sigma points can be generated in any number of dimensions
. A similar canonical set of sigma points can be generated in any number of dimensions  by taking the zero vector and the points comprising the rows of the identity matrix, computing the mean of the set of points, subtracting the mean from each point so that the resulting set has a mean of zero, then compute the covariance of the zero-mean set of points and apply its inverse to each point so that the covariance of the set will be equal to the identity.
by taking the zero vector and the points comprising the rows of the identity matrix, computing the mean of the set of points, subtracting the mean from each point so that the resulting set has a mean of zero, then compute the covariance of the zero-mean set of points and apply its inverse to each point so that the covariance of the set will be equal to the identity.Uhlmann showed that it is possible to conveniently generate a symmetric set of
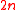 sigma points from the columns of
sigma points from the columns of 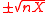 , where
, where  is the given covariance matrix, without having to compute a matrix inverse. It is computationally efficient and, because the points form a symmetric distribution, captures the third central moment (the skew) whenever the underlying distribution of the state estimate is known or can be assumed to be symmetric. He also showed that weights, including negative weights, can be used to affect the statistics of the set. He and Simon Julier published several papers showing that the use of the Unscented transformation in a Kalman filter, which is referred to as the Unscented Kalman Filter (UKF), provides significant performance improvements over the EKF in a variety of applications.
is the given covariance matrix, without having to compute a matrix inverse. It is computationally efficient and, because the points form a symmetric distribution, captures the third central moment (the skew) whenever the underlying distribution of the state estimate is known or can be assumed to be symmetric. He also showed that weights, including negative weights, can be used to affect the statistics of the set. He and Simon Julier published several papers showing that the use of the Unscented transformation in a Kalman filter, which is referred to as the Unscented Kalman Filter (UKF), provides significant performance improvements over the EKF in a variety of applications.Julier also developed and examined techniques for generating sigma points to capture the third moment (the skew) of an arbitrary distribution and the fourth moment (the kurtosis) of a symmetric distribution.
It should be noted that Julier and Uhlmann published papers using a particular parameterized form of the Unscented Transform in the context of the UKF which used negative weights to capture assumed distribution information. That form of the UT is susceptible to a variety of numerical errors that the original formulations (above) do not suffer. Julier has subsequently described parameterized forms which do not use negative weights and also are not subject to those issues.
Example
The Unscented Transform is defined for the application of a given function to any partial characterization of an otherwise unknown distribution, but its most common use is for the case in which only the mean and covariance is given. A common example is the conversion from one coordinate system to another, such as from a Cartesian coordinate frame to polar coordinates.Suppose a 2-dimensional mean and covariance estimate,
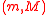 , is given in Cartesian coordinates with:
, is given in Cartesian coordinates with: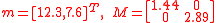
and the transformation function to polar coordinates,
 , is:
, is: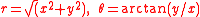
Multiplying each of the canonical simplex sigma points (given above) by
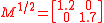 and adding the mean,
and adding the mean,  , gives:
, gives: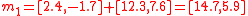
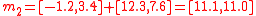
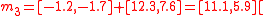
Applying the tranformation function
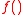 to each of the above points gives:
to each of the above points gives: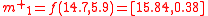
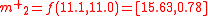
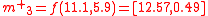
The mean of these three transformed points,
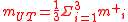 , is the UT estimate of the mean in polar coordinates:
, is the UT estimate of the mean in polar coordinates: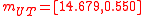
The UT estimate of the covariance is:
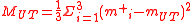
where the each squared term in the sum is a vector outer product. This gives:
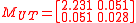
This can be compared to the linearized mean and covariance:
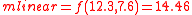

The absolute difference between the UT and linearized estimates in this case is relatively small, but in filtering applications the cumulative effect of small errors can lead to unrecoverable divergence of the estimate. The effect of the errors are exacerbated when the covariance is underestimated because this causes the filter to be overconfident in the accuracy of the mean. In the above example it can be seen that the linearized covariance estimate is smaller than that of the UT estimate, suggesting that linearization has likely produced an underestimate of the actual error in its mean.
In this example there is no way to determine the absolute accuracy of the UT and linearized estimates without ground truth in the form of the actual probability distribution associated with the original estimate and the mean and covariance of that distribution after application of the nonlinear transformation (e.g., as determined analytically or through numerical integration). Such analyses have been performed for coordinate transformations under the assumption of Gaussianity for the underlying distributions, and the UT estimates tend to be significantly more accurate than those obtained from linearization.
Empirical analysis has shown that the use of the minimal simplex set of
 sigma points is significantly less accurate than the use of the symmetric set of
sigma points is significantly less accurate than the use of the symmetric set of 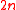 points when the underlying distribution is Gaussian. This suggests that the use of the simplex set in the above example would not be the best choice if the underlying distribution associated with
points when the underlying distribution is Gaussian. This suggests that the use of the simplex set in the above example would not be the best choice if the underlying distribution associated with 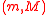 is symmetric. Even if the underlying distribution is not symmetric, the simplex set is still likely to be less accurate than the symmetric set because the asymmetry of the simplex set is not matched to the asymmetry of the actual distribution.
is symmetric. Even if the underlying distribution is not symmetric, the simplex set is still likely to be less accurate than the symmetric set because the asymmetry of the simplex set is not matched to the asymmetry of the actual distribution.Returning to the example, the minimal symmetric set of sigma points can be obtained from the covariance matrix
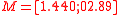 simply as the mean vector,
simply as the mean vector, 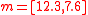 plus and minus the columns of
plus and minus the columns of 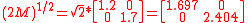 :
: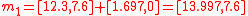
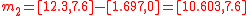
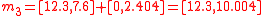
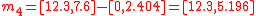
This construction guarantees that the mean and covariance of the above four sigma points is
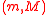 , which is directly verifiable. Applying the nonlinear function
, which is directly verifiable. Applying the nonlinear function 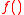 to each of the sigma points gives:
to each of the sigma points gives: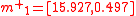
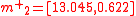

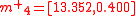
The mean of these four transformed sigma points,
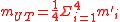 , is the UT estimate of the mean in polar coordinates:
, is the UT estimate of the mean in polar coordinates: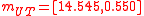
The UT estimate of the covariance is:
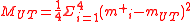
where the each squared term in the sum is a vector outer product. This gives:
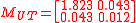
The difference between the UT and linearized mean estimates gives a measure of the effect of the nonlinearity of the transformation. When the transformation is linear, for instance, the UT and linearized estimates will be identical. This motivates the use of the square of this difference to be added to the UT covariance to guard against underestimating of the actual error in the mean. This approach does not improve the accuracy of the mean but can significantly improve the accuracy of a filter over time by reducing the likelihood that the covariance is underestimated.
Optimality of the Unscented Transform
Uhlmann noted that given only the mean and covariance of an otherwise unknown probability distribution, the transformation problem is ill-defined because there are an infinite number of possible underlying distributions with the same first two moments. Without any a priori information or assumptions about the characteristics of the underlying distribution, any choice of distribution used to compute the transformed mean and covariance is as reasonable as any other. In other words, there is no choice of distribution with a given mean and covariance that is superior to that provided by the set of sigma points, therefore the Unscented Transform is trivially optimal.This general statement of optimality is of course useless for making any quantitative statements about the performance of the UT, e.g., compared to linearization; consequently he, Julier, and others have performed analyses under various assumptions about the characteristics of the distribution and/or the form of the nonlinear transformation function. For example, if the function is differentiable, which is essential for linearization, these analyses validate the expected and empirically-corroborated superiority of the Unscented Transform.
Applications
The Unscented Transform, especially as part of the UKF, has largely replaced the EKF in many nonlinear filtering and control applications, including for underwater, ground and air navigation,, and spacecraft.See also
- Kalman filterKalman filterIn statistics, the Kalman filter is a mathematical method named after Rudolf E. Kálmán. Its purpose is to use measurements observed over time, containing noise and other inaccuracies, and produce values that tend to be closer to the true values of the measurements and their associated calculated...
- Covariance IntersectionCovariance intersectionCovariance intersection is an algorithm for combining two or more estimates of state variables in a Kalman filter when the correlation between them is unknown.-Specification:...
- Ensemble Kalman filterEnsemble Kalman filterThe ensemble Kalman filter is a recursive filter suitable for problems with a large number of variables, such as discretizations of partial differential equations in geophysical models...
- Extended Kalman filterExtended Kalman filterIn estimation theory, the extended Kalman filter is the nonlinear version of the Kalman filter which linearizes about the current mean and covariance...
- Non-linear filterNon-linear filterA nonlinear filter is a signal-processing device whose output is not a linear function of its input. Terminology concerning the filtering problem may refer to the time domain showing of the signal or to the frequency domain representation of the signal. When referring to filters with adjectives...