
Kademlia
Encyclopedia
Kademlia is a distributed hash table
for decentralized peer-to-peer
computer network
s designed by Petar Maymounkov and David Mazières in 2002. It specifies the structure of the network and the exchange of information through node
lookups. Kademlia nodes communicate among themselves using UDP
. A virtual or overlay network
is formed by the participant nodes. Each node is identified by a number or node ID. The node ID serves not only as identification, but the Kademlia algorithm uses the node ID to locate values (usually file hashes
or keywords). In fact, the node ID provides a direct map to file hashes and that node stores information on where to obtain the file or resource.
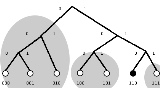
When searching for some value, the algorithm needs to know the associated key and explores the network in several steps. Each step will find nodes that are closer to the key until the contacted node returns the value or no more closer nodes are found. This is very efficient: Like many other DHTs
, Kademlia contacts only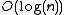
nodes during the search out of a total of nodes in the system.
nodes in the system.
Further advantages are found particularly in the decentralized structure, which increases the resistance against a denial of service attack. Even if a whole set of nodes is flooded, this will have limited effect on network availability, since the network will recover itself by knitting the network around these "holes".
, relied on a central database to co-ordinate look ups on the network. Second generation peer-to-peer networks, such as Gnutella
, used flooding to locate files, searching every node on the network. Third generation peer-to-peer networks use Distributed hash table
s to look up files in the network. Distributed hash tables store resource locations throughout the network. A major criterion for these protocols is locating the desired nodes quickly.
Kademlia uses a "distance" calculation between two nodes. This distance is computed as the exclusive or of the two node IDs, taking the result as an integer number
. Keys and Node IDs have the same format and length, so distance can be calculated among them in exactly the same way. The node ID is typically a large random number that is chosen with the goal of being unique for a particular node (see UUID
). It can and does happen that geographically widely separated nodes -- from Germany and Australia, for instance -- can be "neighbors" if they have chosen similar random node IDs.
Exclusive Or was chosen because it shares some properties with the geometric distance formula
. Specifically:
These properties provide most of the important behaviors of measuring a real distance with a significantly lower amount of computation to calculate it.
Each Kademlia search iteration comes one bit closer to the target. A basic Kademlia network with 2n nodes will only take n steps (in the worst case) to find that node.
, see the section accelerated lookups for more information on real routing tables.
Kademlia routing tables consist of a list for each bit of the node ID. (e.g. if a node ID consists of 128 bits, a node will keep 128 such lists.) A list has many entries. Every entry in a list holds the necessary data to locate another node. The data in each list entry is typically the IP address, port, and node ID of another node. Every list corresponds to a specific distance from the node. Nodes that can go in the nth list must have a differing nth bit from the node's ID; the first n-1 bits of the candidate ID must match those of the node's ID. This means that it is very easy to fill the first list as 1/2 of the nodes in the network are far away candidates. The next list can use only 1/4 of the nodes in the network (one bit closer than the first), etc.
With an ID of 128 bits, every node in the network will classify other nodes in one of 128 different distances, one specific distance per bit.
As nodes are encountered on the network, they are added to the lists. This includes store and retrieval operations and even when helping other nodes to find a key. Every node encountered will be considered for inclusion in the lists. Therefore the knowledge that a node has of the network is very dynamic. This keeps the network constantly updated and adds resilience to failures or attacks.
In the Kademlia literature, the lists are referred to as k-buckets. k is a system wide number, like 20. Every k-bucket is a list having up to k entries inside; i.e. for a network with k=20, each node will have lists containing up to 20 nodes for a particular bit (a particular distance from itself).
Since the possible nodes for each k-bucket decreases quickly (because there will be very few nodes that are that close), the lower bit k-buckets will fully map all nodes in that section of the network. Since the quantity of possible IDs is much larger than any node population can ever be, some of the k-buckets corresponding to very short distances will remain empty.
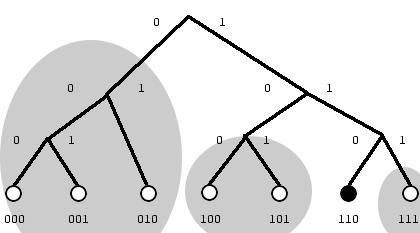 Consider the simple network to the right. The network size is 2^3 or eight maximum keys and nodes. There are seven nodes participating; the small circles at the bottom. The node under consideration is node six (binary 110) in black. There are three k-buckets for each node in this network. Nodes zero, one and two (binary 000, 001, and 010) are candidates for the farthest k-bucket . Node three (binary 011) is not participating in the network. In the middle k-bucket, nodes four and five (binary 100 and 101) are placed. Finally, the third k-bucket can only contain node seven (binary 111). Each of the three k-buckets is enclosed in a gray circle. If the size of the k-bucket was two, then the farthest 2-bucket can only contain two of the three nodes. For example if node six has node one and two in the farthest 2-bucket, it would have to request a node ID lookup to these nodes to find the location (ip address) of node zero. Each node knows its neighbourhood well and has contact with a few nodes far away which can help locate other nodes far away.
Consider the simple network to the right. The network size is 2^3 or eight maximum keys and nodes. There are seven nodes participating; the small circles at the bottom. The node under consideration is node six (binary 110) in black. There are three k-buckets for each node in this network. Nodes zero, one and two (binary 000, 001, and 010) are candidates for the farthest k-bucket . Node three (binary 011) is not participating in the network. In the middle k-bucket, nodes four and five (binary 100 and 101) are placed. Finally, the third k-bucket can only contain node seven (binary 111). Each of the three k-buckets is enclosed in a gray circle. If the size of the k-bucket was two, then the farthest 2-bucket can only contain two of the three nodes. For example if node six has node one and two in the farthest 2-bucket, it would have to request a node ID lookup to these nodes to find the location (ip address) of node zero. Each node knows its neighbourhood well and has contact with a few nodes far away which can help locate other nodes far away.
It is known that nodes that have been connected for a long time in a network will probably remain connected for a long time in the future. Because of this statistical distribution, Kademlia selects long connected nodes to remain stored in the k-buckets. This increases the number of known valid nodes at some time in the future and provides for a more stable network.
When a k-bucket is full and a new node is discovered for that k-bucket, the least recently seen node in the k-bucket is PINGed. If the node is found to be still alive, the new node is place in a secondary list, a replacement cache. The replacement cache is used only if a node in the k-bucket stops responding. In other words: new nodes are used only when older nodes disappear.
Each RPC
message includes a random value from the initiator. This ensures that when the response is received it corresponds to the request previously sent. (see Magic cookie
)
The node information can be augmented with round trip times
, or RTT
. This information will be used to choose a time-out specific for every consulted node. When a query times out, another query can be initiated, never surpassing α queries at the same time.
is typically used for the map. The storer nodes will have information due to a previous STORE message. Locating a value follows the same procedure as locating the closest nodes to a key, except the search terminates when a node has the requested value in his store and returns this value.
The values are stored at several nodes (k of them) to allow for nodes to come and go and still have the value available in some node. Periodically, a node that stores a value will explore the network to find the k nodes that are close to the key value and replicate the value onto them. This compensates for disappeared nodes.
Also, for popular values that might have many requests, the load in the storer nodes is diminished by having a retriever store this value in some node near, but outside of, the k closest ones. This new storing is called a cache. In this way the value is stored farther and farther away from the key, depending on the quantity of requests. This allows popular searches to find a storer quicker. Because the value is returned from nodes farther away from the key, this alleviates possible "hot spots". Caching nodes will drop the value after a certain time depending on their distance from the key.
Some implementations (eg. Kad
) do not have replication nor caching. The purpose of this is to remove old information quickly from the system. The node that is providing the file will periodically refresh the information onto the network (perform NODE-LOOKUP and STORE messages). When all of the nodes having the file go offline, nobody will be refreshing its values (sources and keywords) and the information will eventually disappear from the network.
process. In this phase, the joining node needs to know the IP address
and port of another node -- a bootstrap node (obtained from the user, or from a stored list) -- that is already participating in the Kademlia network. If the joining node has not yet participated in the network, it computes a random
ID number that is supposed not to be already assigned to any other node. It uses this ID until leaving the network.
The joining node inserts the bootstrap node into one of its k-buckets. The joining node then does a NODE_LOOKUP of its own ID against the bootstrap node (the only other node it knows). The "self-lookup" will populate other nodes' k-buckets with the new node ID, and will populate the joining node's k-buckets with the nodes in the path between it and the bootstrap node. After this, the joining node refreshes all k-buckets further away than the k-bucket the bootstrap node falls in. This refresh is just a lookup of a random key that is within that k-bucket range.
Initially, nodes have one k-bucket. When the k-bucket becomes full, it can be split. The split occurs if the range of nodes in the k-bucket spans the node's own id (values to the left and right in a binary tree). Kademlia relaxes even this rule for the one "closest nodes" k-bucket, because typically one single bucket will correspond to the distance where all the nodes that are the closest to this node are, they may be more than k, and we want it to know them all. It may turn out that a highly unbalanced binary sub-tree exists near the node. If k is 20, and there are 21+ nodes with a prefix "xxx0011....." and the new node is "xxx000011001", the new node can contain multiple k-buckets for the other 21+ nodes. This is to guarantee that the network knows about all nodes in the closest region.
to define distance. Two node ID's or a node ID and a key are XORed and the result is the distance between them. For each bit, the XOR function returns zero if the two bits are equal and one if the two bits are different. XOR metric distances hold the triangle inequality
: The distance from "A" to "B" is shorter than (or equal to) the distance from "A" to "C" plus the distance from "C" to "B".
The XOR metric allows Kademlia to extend routing tables beyond single bits. Groups of bits can be placed in k-buckets. The group of bits are termed a prefix. For an m-bit prefix, there will be 2m-1 k-buckets. The missing k-bucket is a further extension of the routing tree that contains the node ID. An m-bit prefix reduces the maximum number of lookups from log2 n to log2b n. These are maximum values and the average value will be far less, increasing the chance of finding a node in a k-bucket that shares more bits than just the prefix with the target key.
Nodes can use mixtures of prefixes in their routing table, such as the Kad Network
used by eMule
. The Kademlia network could even be heterogeneous in routing table implementations, at the expense of complicating the analysis of lookups.
allowing closed analysis. Other DHT protocols and algorithms required simulation
or complicated formal analysis in order to predict network behavior and correctness. Using groups of bits as routing information also simplifies the algorithms.
networks. By making Kademlia keyword searches, one can find information in the file-sharing network so it can be downloaded.
Since there is no central instance to store an index of existing files, this task is divided evenly among all clients: If a node wants to share a file, it processes the contents of the file, calculating from it a number (hash
) that will identify this file within the file-sharing network. The hashes and the node IDs must be of the same length. It then searches for several nodes whose ID is close to the hash, and has his own IP address stored at those nodes. i.e. it publishes itself as a source for this file. A searching client will use Kademlia to search the network for the node whose ID has the smallest distance to the file hash, then will retrieve the sources list that is stored in that node.
Since a key can correspond to many values, e.g. many sources of the same file, every storing node may have different information. Then, the sources are requested from all k nodes close to the key.
The file hash is usually obtained from a specially formed Internet link found elsewhere, or included within an indexing file obtained from other sources.
Filename searches are implemented using keywords. The filename is divided into its constituent words. Each of these keywords is hashed and stored in the network, together with the corresponding filename and file hash. A search involves choosing one of the keywords, contacting the node with an ID closest to that keyword hash, and retrieving the list of filenames that contain the keyword. Since every filename in the list has its hash attached, the chosen file can then be obtained in the normal way.
. Petar Maymounkov, one of the original authors of Kademlia, has proposed a way to circumvent this weakness by incorporating social trust relationships into the system design. See http://pdos.csail.mit.edu/papers/sybil-dht-socialnets08.pdf, page 20 for social-network based approaches.
The new system, codenamed Tonika or also known by its domain name as 5ttt, is based on an algorithm design known as Electric routing and co-authored with the mathematician Jonathan Kelner. Maymounkov has now undertaken a comprehensive implementation effort of this new system, which is entirely based on the Go programming language
. However, research into effective defences against Sybil attacks is generally considered an open question, and wide variety of potential defences are proposed every year in top security research conferences.
Distributed hash table
A distributed hash table is a class of a decentralized distributed system that provides a lookup service similar to a hash table; pairs are stored in a DHT, and any participating node can efficiently retrieve the value associated with a given key...
for decentralized peer-to-peer
Peer-to-peer
Peer-to-peer computing or networking is a distributed application architecture that partitions tasks or workloads among peers. Peers are equally privileged, equipotent participants in the application...
computer network
Computer network
A computer network, often simply referred to as a network, is a collection of hardware components and computers interconnected by communication channels that allow sharing of resources and information....
s designed by Petar Maymounkov and David Mazières in 2002. It specifies the structure of the network and the exchange of information through node
Node (networking)
In communication networks, a node is a connection point, either a redistribution point or a communication endpoint . The definition of a node depends on the network and protocol layer referred to...
lookups. Kademlia nodes communicate among themselves using UDP
User Datagram Protocol
The User Datagram Protocol is one of the core members of the Internet Protocol Suite, the set of network protocols used for the Internet. With UDP, computer applications can send messages, in this case referred to as datagrams, to other hosts on an Internet Protocol network without requiring...
. A virtual or overlay network
Overlay network
An overlay network is a computer network which is built on the top of another network. Nodes in the overlay can be thought of as being connected by virtual or logical links, each of which corresponds to a path, perhaps through many physical links, in the underlying network...
is formed by the participant nodes. Each node is identified by a number or node ID. The node ID serves not only as identification, but the Kademlia algorithm uses the node ID to locate values (usually file hashes
Hash function
A hash function is any algorithm or subroutine that maps large data sets to smaller data sets, called keys. For example, a single integer can serve as an index to an array...
or keywords). In fact, the node ID provides a direct map to file hashes and that node stores information on where to obtain the file or resource.
When searching for some value, the algorithm needs to know the associated key and explores the network in several steps. Each step will find nodes that are closer to the key until the contacted node returns the value or no more closer nodes are found. This is very efficient: Like many other DHTs
Distributed hash table
A distributed hash table is a class of a decentralized distributed system that provides a lookup service similar to a hash table; pairs are stored in a DHT, and any participating node can efficiently retrieve the value associated with a given key...
, Kademlia contacts only
Big O notation
In mathematics, big O notation is used to describe the limiting behavior of a function when the argument tends towards a particular value or infinity, usually in terms of simpler functions. It is a member of a larger family of notations that is called Landau notation, Bachmann-Landau notation, or...
nodes during the search out of a total of
nodes in the system.Further advantages are found particularly in the decentralized structure, which increases the resistance against a denial of service attack. Even if a whole set of nodes is flooded, this will have limited effect on network availability, since the network will recover itself by knitting the network around these "holes".
System details
The first generation peer-to-peer file sharing networks, such as NapsterNapster
Napster is an online music store and a Best Buy company. It was originally founded as a pioneering peer-to-peer file sharing Internet service that emphasized sharing audio files that were typically digitally encoded music as MP3 format files...
, relied on a central database to co-ordinate look ups on the network. Second generation peer-to-peer networks, such as Gnutella
Gnutella
Gnutella is a large peer-to-peer network which, at the time of its creation, was the first decentralized peer-to-peer network of its kind, leading to other, later networks adopting the model...
, used flooding to locate files, searching every node on the network. Third generation peer-to-peer networks use Distributed hash table
Distributed hash table
A distributed hash table is a class of a decentralized distributed system that provides a lookup service similar to a hash table; pairs are stored in a DHT, and any participating node can efficiently retrieve the value associated with a given key...
s to look up files in the network. Distributed hash tables store resource locations throughout the network. A major criterion for these protocols is locating the desired nodes quickly.
Kademlia uses a "distance" calculation between two nodes. This distance is computed as the exclusive or of the two node IDs, taking the result as an integer number
Integer
The integers are formed by the natural numbers together with the negatives of the non-zero natural numbers .They are known as Positive and Negative Integers respectively...
. Keys and Node IDs have the same format and length, so distance can be calculated among them in exactly the same way. The node ID is typically a large random number that is chosen with the goal of being unique for a particular node (see UUID
Universally Unique Identifier
A universally unique identifier is an identifier standard used in software construction, standardized by the Open Software Foundation as part of the Distributed Computing Environment ....
). It can and does happen that geographically widely separated nodes -- from Germany and Australia, for instance -- can be "neighbors" if they have chosen similar random node IDs.
Exclusive Or was chosen because it shares some properties with the geometric distance formula
Distance
Distance is a numerical description of how far apart objects are. In physics or everyday discussion, distance may refer to a physical length, or an estimation based on other criteria . In mathematics, a distance function or metric is a generalization of the concept of physical distance...
. Specifically:
- the distance between a node and itself is zero
- it is symmetric: the "distance" calculated from A to B and from B to A are the same
- it follows the triangle inequalityTriangle inequalityIn mathematics, the triangle inequality states that for any triangle, the sum of the lengths of any two sides must be greater than or equal to the length of the remaining side ....
: given three points A < B < C, the "distance" from A to C is less than or equal to the sum of the "distance" from A to B and the "distance" from B to C
These properties provide most of the important behaviors of measuring a real distance with a significantly lower amount of computation to calculate it.
Each Kademlia search iteration comes one bit closer to the target. A basic Kademlia network with 2n nodes will only take n steps (in the worst case) to find that node.
Routing tables
This section is simplified to use a single bitBit
A bit is the basic unit of information in computing and telecommunications; it is the amount of information stored by a digital device or other physical system that exists in one of two possible distinct states...
, see the section accelerated lookups for more information on real routing tables.
Kademlia routing tables consist of a list for each bit of the node ID. (e.g. if a node ID consists of 128 bits, a node will keep 128 such lists.) A list has many entries. Every entry in a list holds the necessary data to locate another node. The data in each list entry is typically the IP address, port, and node ID of another node. Every list corresponds to a specific distance from the node. Nodes that can go in the nth list must have a differing nth bit from the node's ID; the first n-1 bits of the candidate ID must match those of the node's ID. This means that it is very easy to fill the first list as 1/2 of the nodes in the network are far away candidates. The next list can use only 1/4 of the nodes in the network (one bit closer than the first), etc.
With an ID of 128 bits, every node in the network will classify other nodes in one of 128 different distances, one specific distance per bit.
As nodes are encountered on the network, they are added to the lists. This includes store and retrieval operations and even when helping other nodes to find a key. Every node encountered will be considered for inclusion in the lists. Therefore the knowledge that a node has of the network is very dynamic. This keeps the network constantly updated and adds resilience to failures or attacks.
In the Kademlia literature, the lists are referred to as k-buckets. k is a system wide number, like 20. Every k-bucket is a list having up to k entries inside; i.e. for a network with k=20, each node will have lists containing up to 20 nodes for a particular bit (a particular distance from itself).
Since the possible nodes for each k-bucket decreases quickly (because there will be very few nodes that are that close), the lower bit k-buckets will fully map all nodes in that section of the network. Since the quantity of possible IDs is much larger than any node population can ever be, some of the k-buckets corresponding to very short distances will remain empty.
It is known that nodes that have been connected for a long time in a network will probably remain connected for a long time in the future. Because of this statistical distribution, Kademlia selects long connected nodes to remain stored in the k-buckets. This increases the number of known valid nodes at some time in the future and provides for a more stable network.
When a k-bucket is full and a new node is discovered for that k-bucket, the least recently seen node in the k-bucket is PINGed. If the node is found to be still alive, the new node is place in a secondary list, a replacement cache. The replacement cache is used only if a node in the k-bucket stops responding. In other words: new nodes are used only when older nodes disappear.
Protocol messages
Kademlia has four messages.- PING — used to verify that a node is still alive.
- STORE — Stores a (key, value) pair in one node.
- FIND_NODE — The recipient of the request will return the k nodes in his own buckets that are the closest ones to the requested key.
- FIND_VALUE — Same as FIND_NODE, but if the recipient of the request has the requested key in its store, it will return the corresponding value.
Each RPC
Remote procedure call
In computer science, a remote procedure call is an inter-process communication that allows a computer program to cause a subroutine or procedure to execute in another address space without the programmer explicitly coding the details for this remote interaction...
message includes a random value from the initiator. This ensures that when the response is received it corresponds to the request previously sent. (see Magic cookie
Magic cookie
A magic cookie or just cookie for short, is a token or short packet of data passed between communicating programs, where the data is typically not meaningful to the recipient program. The contents are opaque and not usually interpreted until the recipient passes the cookie data back to the sender...
)
Locating nodes
Node lookups can proceed asynchronously. The quantity of simultaneous lookups is denoted by α and is typically three. A node initiates a FIND_NODE request by querying to the α nodes in its own k-buckets that are the closest ones to the desired key. When these recipient nodes receive the request, they will look in their k-buckets and return the k closest nodes to the desired key that they know. The requester will update a results list with the results (node ID's) he receives, keeping the k best ones (the k nodes that are closer to the searched key) that respond to queries. Then the requester will select these k best results and issue the request to them, and iterate this process again and again. Because every node has a better knowledge of his own surroundings than any other node has, the received results will be other nodes that are every time closer and closer to the searched key. The iterations continue until no nodes are returned that are closer than the best previous results. When the iterations stop, the best k nodes in the results list are the ones in the whole network that are the closest to the desired key.The node information can be augmented with round trip times
Round-trip delay time
In telecommunications, the round-trip delay time or round-trip time is the length of time it takes for a signal to be sent plus the length of time it takes for an acknowledgment of that signal to be received...
, or RTT
Round-trip delay time
In telecommunications, the round-trip delay time or round-trip time is the length of time it takes for a signal to be sent plus the length of time it takes for an acknowledgment of that signal to be received...
. This information will be used to choose a time-out specific for every consulted node. When a query times out, another query can be initiated, never surpassing α queries at the same time.
Locating resources
Information is located by mapping it to a key. A hashHash function
A hash function is any algorithm or subroutine that maps large data sets to smaller data sets, called keys. For example, a single integer can serve as an index to an array...
is typically used for the map. The storer nodes will have information due to a previous STORE message. Locating a value follows the same procedure as locating the closest nodes to a key, except the search terminates when a node has the requested value in his store and returns this value.
The values are stored at several nodes (k of them) to allow for nodes to come and go and still have the value available in some node. Periodically, a node that stores a value will explore the network to find the k nodes that are close to the key value and replicate the value onto them. This compensates for disappeared nodes.
Also, for popular values that might have many requests, the load in the storer nodes is diminished by having a retriever store this value in some node near, but outside of, the k closest ones. This new storing is called a cache. In this way the value is stored farther and farther away from the key, depending on the quantity of requests. This allows popular searches to find a storer quicker. Because the value is returned from nodes farther away from the key, this alleviates possible "hot spots". Caching nodes will drop the value after a certain time depending on their distance from the key.
Some implementations (eg. Kad
Kad Network
The Kad network is a peer-to-peer network which implements the Kademlia P2P overlay protocol. The majority of users on the Kad Network are also connected to servers on the eDonkey network, and Kad Network clients typically query known nodes on the eDonkey network in order to find an initial node...
) do not have replication nor caching. The purpose of this is to remove old information quickly from the system. The node that is providing the file will periodically refresh the information onto the network (perform NODE-LOOKUP and STORE messages). When all of the nodes having the file go offline, nobody will be refreshing its values (sources and keywords) and the information will eventually disappear from the network.
Joining the network
A node that would like to join the net must first go through a bootstrapBootstrapping node
A bootstrapping node, also known as a rendezvous host, is a node in an overlay network that provides initial configuration information to newly joining nodes so that they may successfully join the overlay network...
process. In this phase, the joining node needs to know the IP address
IP address
An Internet Protocol address is a numerical label assigned to each device participating in a computer network that uses the Internet Protocol for communication. An IP address serves two principal functions: host or network interface identification and location addressing...
and port of another node -- a bootstrap node (obtained from the user, or from a stored list) -- that is already participating in the Kademlia network. If the joining node has not yet participated in the network, it computes a random
Randomness
Randomness has somewhat differing meanings as used in various fields. It also has common meanings which are connected to the notion of predictability of events....
ID number that is supposed not to be already assigned to any other node. It uses this ID until leaving the network.
The joining node inserts the bootstrap node into one of its k-buckets. The joining node then does a NODE_LOOKUP of its own ID against the bootstrap node (the only other node it knows). The "self-lookup" will populate other nodes' k-buckets with the new node ID, and will populate the joining node's k-buckets with the nodes in the path between it and the bootstrap node. After this, the joining node refreshes all k-buckets further away than the k-bucket the bootstrap node falls in. This refresh is just a lookup of a random key that is within that k-bucket range.
Initially, nodes have one k-bucket. When the k-bucket becomes full, it can be split. The split occurs if the range of nodes in the k-bucket spans the node's own id (values to the left and right in a binary tree). Kademlia relaxes even this rule for the one "closest nodes" k-bucket, because typically one single bucket will correspond to the distance where all the nodes that are the closest to this node are, they may be more than k, and we want it to know them all. It may turn out that a highly unbalanced binary sub-tree exists near the node. If k is 20, and there are 21+ nodes with a prefix "xxx0011....." and the new node is "xxx000011001", the new node can contain multiple k-buckets for the other 21+ nodes. This is to guarantee that the network knows about all nodes in the closest region.
Accelerated lookups
Kademlia uses an XOR metricMetric (mathematics)
In mathematics, a metric or distance function is a function which defines a distance between elements of a set. A set with a metric is called a metric space. A metric induces a topology on a set but not all topologies can be generated by a metric...
to define distance. Two node ID's or a node ID and a key are XORed and the result is the distance between them. For each bit, the XOR function returns zero if the two bits are equal and one if the two bits are different. XOR metric distances hold the triangle inequality
Triangle inequality
In mathematics, the triangle inequality states that for any triangle, the sum of the lengths of any two sides must be greater than or equal to the length of the remaining side ....
: The distance from "A" to "B" is shorter than (or equal to) the distance from "A" to "C" plus the distance from "C" to "B".
The XOR metric allows Kademlia to extend routing tables beyond single bits. Groups of bits can be placed in k-buckets. The group of bits are termed a prefix. For an m-bit prefix, there will be 2m-1 k-buckets. The missing k-bucket is a further extension of the routing tree that contains the node ID. An m-bit prefix reduces the maximum number of lookups from log2 n to log2b n. These are maximum values and the average value will be far less, increasing the chance of finding a node in a k-bucket that shares more bits than just the prefix with the target key.
Nodes can use mixtures of prefixes in their routing table, such as the Kad Network
Kad Network
The Kad network is a peer-to-peer network which implements the Kademlia P2P overlay protocol. The majority of users on the Kad Network are also connected to servers on the eDonkey network, and Kad Network clients typically query known nodes on the eDonkey network in order to find an initial node...
used by eMule
EMule
eMule is a free peer-to-peer file sharing application for Microsoft Windows. Started in May 2002 as an alternative to eDonkey2000, eMule now connects to both the eDonkey network and the Kad network...
. The Kademlia network could even be heterogeneous in routing table implementations, at the expense of complicating the analysis of lookups.
Academic significance
While the XOR metric is not needed to understand Kademlia, it is critical in the analysis of the protocol. The XOR arithmetic forms a cyclic groupCyclic group
In group theory, a cyclic group is a group that can be generated by a single element, in the sense that the group has an element g such that, when written multiplicatively, every element of the group is a power of g .-Definition:A group G is called cyclic if there exists an element g...
allowing closed analysis. Other DHT protocols and algorithms required simulation
Computer simulation
A computer simulation, a computer model, or a computational model is a computer program, or network of computers, that attempts to simulate an abstract model of a particular system...
or complicated formal analysis in order to predict network behavior and correctness. Using groups of bits as routing information also simplifies the algorithms.
Use in file sharing networks
Kademlia is used in file sharingFile sharing
File sharing is the practice of distributing or providing access to digitally stored information, such as computer programs, multimedia , documents, or electronic books. It may be implemented through a variety of ways...
networks. By making Kademlia keyword searches, one can find information in the file-sharing network so it can be downloaded.
Since there is no central instance to store an index of existing files, this task is divided evenly among all clients: If a node wants to share a file, it processes the contents of the file, calculating from it a number (hash
Hash function
A hash function is any algorithm or subroutine that maps large data sets to smaller data sets, called keys. For example, a single integer can serve as an index to an array...
) that will identify this file within the file-sharing network. The hashes and the node IDs must be of the same length. It then searches for several nodes whose ID is close to the hash, and has his own IP address stored at those nodes. i.e. it publishes itself as a source for this file. A searching client will use Kademlia to search the network for the node whose ID has the smallest distance to the file hash, then will retrieve the sources list that is stored in that node.
Since a key can correspond to many values, e.g. many sources of the same file, every storing node may have different information. Then, the sources are requested from all k nodes close to the key.
The file hash is usually obtained from a specially formed Internet link found elsewhere, or included within an indexing file obtained from other sources.
Filename searches are implemented using keywords. The filename is divided into its constituent words. Each of these keywords is hashed and stored in the network, together with the corresponding filename and file hash. A search involves choosing one of the keywords, contacting the node with an ID closest to that keyword hash, and retrieving the list of filenames that contain the keyword. Since every filename in the list has its hash attached, the chosen file can then be obtained in the normal way.
Networks
Public networks using the Kademlia algorithm (these networks are incompatible with one another):- Kad NetworkKad NetworkThe Kad network is a peer-to-peer network which implements the Kademlia P2P overlay protocol. The majority of users on the Kad Network are also connected to servers on the eDonkey network, and Kad Network clients typically query known nodes on the eDonkey network in order to find an initial node...
— developed originally by the eMuleEMuleeMule is a free peer-to-peer file sharing application for Microsoft Windows. Started in May 2002 as an alternative to eDonkey2000, eMule now connects to both the eDonkey network and the Kad network...
community to replace the server-based architecture of the eDonkey2000 network. - Overnet networkOvernetOvernet was a decentralized peer-to-peer computer network, usually used for sharing large files . Overnet implements the Kademlia algorithm. In late 2006, Overnet and all Overnet-owned resources were taken down as a result of legal actions from the RIAA and others...
: With KadC a C library for handling its Kademlia is available. (development of Overnet is discontinued)
- BitTorrent Uses a DHT based on an implementation of the Kademlia algorithm, for trackerless torrents.
- Osiris spsOsiris (Serverless Portal System)Osiris Serverless Portal System is a freeware program used to create web portals distributed via peer-to-peer networking and autonomous from centralized servers...
(all version): used to manage distributed and anonymous web portal. - GnutellaGnutellaGnutella is a large peer-to-peer network which, at the time of its creation, was the first decentralized peer-to-peer network of its kind, leading to other, later networks adopting the model...
DHT — Originally by LimeWireLimeWireLimeWire is a free peer-to-peer file sharing client program that runs on Windows, Mac OS X, Linux, and other operating systems supported by the Java software platform. LimeWire uses the gnutella network as well as the BitTorrent protocol. A free software version and a purchasable "enhanced"...
to augment the GnutellaGnutellaGnutella is a large peer-to-peer network which, at the time of its creation, was the first decentralized peer-to-peer network of its kind, leading to other, later networks adopting the model...
protocol for finding alternate file locations, now in use by other gnutella clients.
Libraries
- Khashmir — Python implementation of Kademlia. Used in the mainline BitTorrent, with some modifications.
- SharkyPy — another python implementation of a Kademlia Distributed Hash Table. LGPL licenced.
- Entangled — Python implementation of Kademlia, also providing a distributed tuple spaceTuple spaceA tuple space is an implementation of the associative memory paradigm for parallel/distributed computing. It provides a repository of tuples that can be accessed concurrently. As an illustrative example, consider that there are a group of processors that produce pieces of data and a group of...
. LGPL licenced - Mojito — a Java Kademlia library written for the LimeWireLimeWireLimeWire is a free peer-to-peer file sharing client program that runs on Windows, Mac OS X, Linux, and other operating systems supported by the Java software platform. LimeWire uses the gnutella network as well as the BitTorrent protocol. A free software version and a purchasable "enhanced"...
project. See the Class interface documentation for more information. - maidsafe-dht — c++ implementation of Kademlia (BSD license), with NAT traversal and crypto libraries.
- Plan-x — Java implementation.
- Daylight — C#/.NET implementation.
- BitDHT — C++ implementation of Kademlia. Uses BitTorrent DHT network (LGPL license)
- Ardverk-DHT — Java implementation (ASL 2.0 license)
- TomP2P - Java implementation with UPNP support for NAT traversal (ASL 2.0 license)
Next generation
During the years, the academic and practitioner communities have realized that all current DHT designs suffer from a security weakness, known as the Sybil AttackSybil attack
The Sybil attack in computer security is an attack wherein a reputation system is subverted by forging identities in peer-to-peer networks. It is named after the subject of the book Sybil, a fictional case study of a woman with multiple personality disorder...
. Petar Maymounkov, one of the original authors of Kademlia, has proposed a way to circumvent this weakness by incorporating social trust relationships into the system design. See http://pdos.csail.mit.edu/papers/sybil-dht-socialnets08.pdf, page 20 for social-network based approaches.
The new system, codenamed Tonika or also known by its domain name as 5ttt, is based on an algorithm design known as Electric routing and co-authored with the mathematician Jonathan Kelner. Maymounkov has now undertaken a comprehensive implementation effort of this new system, which is entirely based on the Go programming language
Go (programming language)
Go is a compiled, garbage-collected, concurrent programming language developed by Google Inc.The initial design of Go was started in September 2007 by Robert Griesemer, Rob Pike, and Ken Thompson. Go was officially announced in November 2009. In May 2010, Rob Pike publicly stated that Go was being...
. However, research into effective defences against Sybil attacks is generally considered an open question, and wide variety of potential defences are proposed every year in top security research conferences.
See also
- Content addressable networkContent addressable networkThe Content Addressable Network is a distributed, decentralized P2P infrastructure that provides hash table functionality on an Internet-like scale...
- Chord (DHT)
- Tapestry (DHT)Tapestry (DHT)Tapestry is a distributed hash table which provides a decentralized object location, routing, and multicasting infrastructure for distributed applications...
- Pastry (DHT)Pastry (DHT)Pastry is an overlay and routing network for the implementation of a distributed hash table similar to Chord. The key-value pairs are stored in a redundant peer-to-peer network of connected Internet hosts. The protocol is bootstrapped by supplying it with the IP address of a peer already in the...
- KoordeKoordeIn peer-to-peer networks, Koorde is a Distributed hash table system based on the Chord DHT and the De Bruijn graph . Inheriting the simplicity of Chord, Koorde meets O hops per node , and O hops per lookup request with O neighbors per node.The Chord concept is based on a wide range of...
External links
- Academic Home Page of Petar Maymounkov, co-designer of Kademlia.
- Xlattice projects Kademlia Specification and definitions.
- Yi Qiao and Fabian E. Bustamante USENIX 2006 paper that characterizes Overnet and Gnutella