
MPEG-1
Encyclopedia
MPEG-1 is a standard for lossy compression of video
and audio
. It is designed to compress VHS
-quality raw digital video and CD audio down to 1.5 Mbit/s (26:1 and 6:1 compression ratios respectively) without excessive quality loss, making video CD
s, digital cable
/satellite
TV and digital audio broadcasting
(DAB) possible.
Today, MPEG-1 has become the most widely compatible lossy audio/video format in the world, and is used in a large number of products and technologies. Perhaps the best-known part of the MPEG-1 standard is the MP3
audio format it introduced.
The MPEG-1 standard is published as ISO/IEC
11172 – Information technology—Coding of moving pictures and associated audio for digital storage media at up to about 1.5 Mbit/s. The standard consists of the following five Parts:
and CCITT's Experts Group on Telephony (creators of the JPEG
image compression standard and the H.261
standard for video conferencing respectively) the Moving Picture Experts Group
(MPEG) working group was established in January 1988. MPEG was formed to address the need for standard video and audio formats, and build on H.261 to get better quality through the use of more complex encoding methods.
Development of the MPEG-1 standard began in May 1988. 14 video and 14 audio codec proposals were submitted by individual companies and institutions for evaluation. The codecs were extensively tested for computational complexity
and subjective
(human perceived) quality, at data rates of 1.5 Mbit/s. This specific bitrate was chosen for transmission over T-1
/E-1
lines and as the approximate data rate of audio CDs
. The codecs that excelled in this testing were utilized as the basis for the standard and refined further, with additional features and other improvements being incorporated in the process.
After 20 meetings of the full group in various cities around the world, and 4½ years of development and testing, the final standard (for parts 1–3) was approved in early November 1992 and published a few months later. The reported completion date of the MPEG-1 standard, varies greatly: a largely complete draft standard was produced in September 1990, and from that point on, only minor changes were introduced. The draft standard was publicly available for purchase. The standard was finished with the 6 November 1992 meeting. The Berkeley Plateau Multimedia Research Group developed a MPEG-1 decoder in November 1992. In July 1990, before the first draft of the MPEG-1 standard had even been written, work began on a second standard, MPEG-2
, intended to extend MPEG-1 technology to provide full broadcast-quality video (as per CCIR 601
) at high bitrates (3–15 Mbit/s), and support for interlaced video. Due in part to the similarity between the two codecs, the MPEG-2 standard includes full backwards compatibility with MPEG-1 video, so any MPEG-2 decoder can play MPEG-1 videos.
Notably, the MPEG-1 standard very strictly defines the bitstream
, and decoder function, but does not define how MPEG-1 encoding is to be performed, although a reference implementation is provided in ISO/IEC-11172-5. This means that MPEG-1 coding efficiency can drastically vary depending on the encoder used, and generally means that newer encoders perform significantly better than their predecessors. The first three parts (Systems, Video and Audio) of ISO/IEC 11172 were published in August 1993.
as discussed in the MP3 article.
MPEG-1 Systems specifies the logical layout and methods used to store the encoded audio, video, and other data into a standard bitstream, and to maintain synchronization between the different contents. This file format
is specifically designed for storage on media, and transmission over data channels
, that are considered relatively reliable. Only limited error protection is defined by the standard, and small errors in the bitstream may cause noticeable defects.
This structure was later named an MPEG program stream: "The MPEG-1 Systems design is essentially identical to the MPEG-2 Program Stream structure." This terminology is more popular, precise (differentiates it from an MPEG transport stream) and will be used here.
Packetized Elementary Streams (PES) are elementary streams packetized into packets of variable lengths, i.e., divided ES into independent chunks where cyclic redundancy check
(CRC) checksum
was added to each packet for error detection.
System Clock Reference (SCR) is a timing value stored in a 33-bit header of each PES, at a frequency/precision of 90 kHz, with an extra 9-bit extension that stores additional timing data with a precision of 27 MHz. These are inserted by the encoder, derived from the system time clock (STC). Simultaneously encoded audio and video streams will not have identical SCR values, however, due to buffering, encoding, jitter, and other delay.
, or a container format.
Presentation time stamps (PTS) exist in PS to correct the inevitable disparity between audio and video SCR values (time-base correction). 90 kHz PTS values in the PS header tell the decoder which video SCR values match which audio SCR values. PTS determines when to display a portion of an MPEG program, and is also used by the decoder to determine when data can be discarded from the buffer. Either video or audio will be delayed by the decoder until the corresponding segment of the other arrives and can be decoded.
PTS handling can be problematic. Decoders must accept multiple program streams that have been concatenated (joined sequentially). This causes PTS values in the middle of the video to reset to zero, which then begin incrementing again. Such PTS wraparound disparities can cause timing issues that must be specially handled by the decoder.
Decoding Time Stamps (DTS), additionally, are required because of B-frames. With B-frames in the video stream, adjacent frames have to be encoded and decoded out-of-order (re-ordered frames). DTS is quite similar to PTS, but instead of just handling sequential frames, it contains the proper time-stamps to tell the decoder when to decode and display the next B-frame (types of frames explained below), ahead of its anchor (P- or I-) frame. Without B-frames in the video, PTS and DTS values are identical.
and are guaranteed to both arrive at the decoder at precisely the same time. This is a case of time-division multiplexing
.
Determining how much data from each stream should be in each interleaved segment (the size of the interleave) is complicated, yet an important requirement. Improper interleaving will result in buffer underflows or overflows, as the receiver gets more of one stream than it can store (eg. audio), before it gets enough data to decode the other simultaneous stream (eg. video). The MPEG Video Buffering Verifier
(VBV) assists in determining if a multiplexed PS can be decoded by a device with a specified data throughput rate and buffer size. This offers feedback to the muxer and the encoder, so that they can change the mux size or adjust bitrates as needed for compliance.
.
MPEG-1 Video exploits perceptual compression methods to significantly reduce the data rate required by a video stream. It reduces or completely discards information in certain frequencies and areas of the picture that the human eye has limited ability to fully perceive. It also exploits temporal (over time) and spatial (across a picture) redundancy common in video to achieve better data compression than would be possible otherwise. (See: Video compression)
 Before encoding video to MPEG-1, the color-space is transformed to Y'CbCr (Y'=Luma, Cb=Chroma Blue, Cr=Chroma Red). Luma
Before encoding video to MPEG-1, the color-space is transformed to Y'CbCr (Y'=Luma, Cb=Chroma Blue, Cr=Chroma Red). Luma
(brightness, resolution) is stored separately from chroma
(color, hue, phase) and even further separated into red and blue components. The chroma is also subsampled to 4:2:0, meaning it is reduced by one half vertically and one half horizontally, to just one quarter the resolution of the video.
This software algorithm also has analogies in hardware, such as the output from a Bayer pattern filter
, common in digital colour cameras.
Because the human eye is much less sensitive to small changes in color than in brightness, chroma subsampling
is a very effective way to reduce the amount of video data that needs to be compressed. On videos with fine detail (high spatial complexity) this can manifest as chroma aliasing
artifacts. Compared to other digital compression artifact
s, this issue seems to be very rarely a source of annoyance.
Because of subsampling, Y'CbCr video must always be stored using even dimensions (divisible by 2), otherwise chroma mismatch ("ghosts") will occur, and it will appear as if the color is ahead of, or behind the rest of the video, much like a shadow.
Y'CbCr is often inaccurately called YUV
which is only used in the domain of analog
video signals. Similarly, the terms luminance
and chrominance
are often used instead of the (more accurate) terms luma and chroma.
MPEG-1 videos are most commonly seen using Source Input Format
(SIF) resolution: 352x240, 352x288, or 320x240. These low resolutions, combined with a bitrate less than 1.5 Mbit/s, make up what is known as a constrained parameters bitstream (CPB), later renamed the "Low Level" (LL) profile in MPEG-2. This is the minimum video specifications any decoder
should be able to handle, to be considered MPEG-1 compliant. This was selected to provide a good balance between quality and performance, allowing the use of reasonably inexpensive hardware of the time.
s used in animation. I-frames can be considered effectively identical to baseline JPEG
images.
High-speed seeking through an MPEG-1 video is only possible to the nearest I-frame. When cutting a video it is not possible to start playback of a segment of video before the first I-frame in the segment (at least not without computationally intensive re-encoding). For this reason, I-frame-only MPEG videos are used in editing applications.
I-frame only compression is very fast, but produces very large file sizes: a factor of 3× (or more) larger than normally encoded MPEG-1 video, depending on how temporally complex a specific video is. I-frame only MPEG-1 video is very similar to MJPEG
video. So much so that very high-speed and theoretically lossless (in reality, there are rounding errors) conversion can be made from one format to the other, provided a couple of restrictions (color space and quantization matrix) are followed in the creation of the bitstream.
The length between I-frames is known as the group of pictures
(GOP) size. MPEG-1 most commonly uses a GOP size of 15-18. i.e. 1 I-frame for every 14-17 non-I-frames (some combination of P- and B- frames). With more intelligent encoders, GOP size is dynamically chosen, up to some pre-selected maximum limit.
Limits are placed on the maximum number of frames between I-frames due to decoding complexing, decoder buffer size, recovery time after data errors, seeking ability, and accumulation of IDCT errors in low-precision implementations most common in hardware decoders (See: IEEE-1180).
P-frames exist to improve compression by exploiting the temporal (over time) redundancy in a video. P-frames store only the difference in image from the frame (either an I-frame or P-frame) immediately preceding it (this reference frame is also called the anchor frame).
The difference between a P-frame and its anchor frame is calculated using motion vectors on each macroblock of the frame (see below). Such motion vector data will be embedded in the P-frame for use by the decoder.
A P-frame can contain any number of intra-coded blocks, in addition to any forward-predicted blocks.
If a video drastically changes from one frame to the next (such as a cut
), it is more efficient to encode it as an I-frame.
It is therefore necessary for the player to first decode the next I- or P- anchor frame sequentially after the B-frame, before the B-frame can be decoded and displayed. This means decoding B-frames requires larger data buffers and causes an increased delay on both decoding and during encoding. This also necessitates the decoding time stamps (DTS) feature in the container/system stream (see above). As such, B-frames have long been subject of much controversy, they are often avoided in videos, and are sometimes not fully supported by hardware decoders.
No other frames are predicted from a B-frame. Because of this, a very low bitrate B-frame can be inserted, where needed, to help control the bitrate. If this was done with a P-frame, future P-frames would be predicted from it and would lower the quality of the entire sequence. However, similarly, the future P-frame must still encode all the changes between it and the previous I- or P- anchor frame. B-frames can also be beneficial in videos where the background behind an object is being revealed over several frames, or in fading transitions, such as scene changes.
A B-frame can contain any number of intra-coded blocks and forward-predicted blocks, in addition to backwards-predicted, or bidirectionally predicted blocks.
Given moderately higher-performance decoding equipment, this feature can be approximated by decoding I-frames instead. This provides higher quality previews, and without the need for D-frames taking up space in the stream, yet not improving video quality.
A macroblock is the smallest independent unit of (color) video. Motion vectors (see below) operate solely at the macroblock level.
If the height and/or width of the video is not exact multiples of 16, a full row of macroblocks must still be encoded (though not displayed) to store the remainder of the picture (macroblock padding). This wastes a significant amount of data in the bitstream, and is to be strictly avoided.
Some decoders will also improperly handle videos with partial macroblocks, resulting in visible artifacts.
The encoder compares the current frame with adjacent parts of the video from the anchor frame (previous I- or P- frame) in a diamond pattern, up to a (encoder-specific) predefined radius
limit from the area of the current macroblock. If a match is found, only the direction and distance (i.e. the vector of the motion) from the previous video area to the current macroblock need to be encoded into the inter-frame (P- or B- frame). The reverse of this process, performed by the decoder to reconstruct the picture, is called motion compensation.
A predicted macroblock rarely matches the current picture perfectly, however. The differences between the estimated matching area, and the real frame/macroblock is called the prediction error. The larger the error, the more data must be additionally encoded in the frame. For efficient video compression, it is very important that the encoder is capable of effectively and precisely performing motion estimation.
Motion vectors record the distance between two areas on screen based on the number of pixels (called pels). MPEG-1 video uses a motion vector (MV) precision of one half of one pixel, or half-pel. The finer the precision of the MVs, the more accurate the match is likely to be, and the more efficient the compression. There are trade-offs to higher precision, however. Finer MVs result in larger data size, as larger numbers must be stored in the frame for every single MV, increased coding complexity as increasing levels of interpolation on the macroblock are required for both the encoder and decoder, and diminishing returns (minimal gains) with higher precision MVs. Half-pel was chosen as the ideal trade-off. (See: qpel
)
Because neighboring macroblocks are likely to have very similar motion vectors, this redundant information can be compressed quite effectively by being stored DPCM-encoded. Only the (smaller) amount of difference between the MVs for each macroblock needs to be stored in the final bitstream.
P-frames have 1 motion vector per macroblock, relative to the previous anchor frame. B-frames, however, can use 2 motion vectors; one from the previous anchor frame, and one from the future anchor frame.
Partial macroblocks, and black borders/bars encoded into the video that do not fall exactly on a macroblock boundary, cause havoc with motion prediction. The block padding/border information prevents the macroblock from closely matching with any other area of the video, and so, significantly larger prediction error information must be encoded for every one of the several dozen partial macroblocks along the screen border. DCT encoding and quantization (see below) also isn't nearly as effective when there is large/sharp picture contrast in a block.
An even more serious problem exists with macroblocks that contain significant, random, edge noise, where the picture transitions to (typically) black. All the above problems also apply to edge noise. In addition, the added randomness is simply impossible to compress significantly. All of these effects will lower the quality (or increase the bitrate) of the video substantially.
(FDCT) and then a quantization process. The FDCT process (by itself) is theoretically lossless, and can be reversed by applying an Inverse DCT (IDCT) to reproduce the original values (in the absence of any quantization and rounding errors). In reality, there are some (sometimes large) rounding errors introduced both by quantization in the encoder (as described in the next section) and by IDCT approximation error in the decoder. The minimum allowed accuracy of a decoder IDCT approximation is defined by ISO/IEC 23002-1. (Prior to 2006, it was specified by IEEE 1180-1990.)
The FDCT process converts the 8x8 block of uncompressed pixel values (brightness or color difference values) into an 8x8 indexed array of frequency coefficient values. One of these is the (statistically high in variance) DC coefficient, which represents the average value of the entire 8x8 block. The other 63 coefficients are the statistically smaller AC coefficients, which are positive or negative values each representing sinusoidal deviations from the flat block value represented by the DC coefficient.
An example of an encoded 8x8 FDCT block:
Since the DC coefficient value is statistically correlated from one block to the next, it is compressed using DPCM encoding. Only the (smaller) amount of difference between each DC value and the value of the DC coefficient in the block to its left needs to be represented in the final bitstream.
Additionally, the frequency conversion performed by applying the DCT provides a statistical decorrelation function to efficiently concentrate the signal into fewer high-amplitude values prior to applying quantization (see below).
(of digital data) is, essentially, the process of reducing the accuracy of a signal, by dividing it into some larger step size (i.e. finding the nearest multiple, and discarding the remainder/modulus).
The frame-level quantizer is a number from 0 to 31 (although encoders will usually omit/disable some of the extreme values) which determines how much information will be removed from a given frame. The frame-level quantizer is either dynamically selected by the encoder to maintain a certain user-specified bitrate, or (much less commonly) directly specified by the user.
Contrary to popular belief, a fixed frame-level quantizer (set by the user) does not deliver a constant level of quality. Instead, it is an arbitrary metric that will provide a somewhat varying level of quality, depending on the contents of each frame. Given two files of identical sizes, the one encoded at an average bitrate should look better than the one encoded with a fixed quantizer (variable bitrate). Constant quantizer encoding can be used, however, to accurately determine the minimum and maximum bitrates possible for encoding a given video.
A quantization matrix is a string of 64-numbers (0-255) which tells the encoder how relatively important or unimportant each piece of visual information is. Each number in the matrix corresponds to a certain frequency component of the video image.
An example quantization matrix:
Quantization is performed by taking each of the 64 frequency values of the DCT block, dividing them by the frame-level quantizer, then dividing them by their corresponding values in the quantization matrix. Finally, the result is rounded down. This significantly reduces, or completely eliminates, the information in some frequency components of the picture. Typically, high frequency information is less visually important, and so high frequencies are much more strongly quantized (drastically reduced). MPEG-1 actually uses two separate quantization matrices, one for intra-blocks (I-blocks) and one for inter-block (P- and B- blocks) so quantization of different block types can be done independently, and so, more effectively.
This quantization process usually reduces a significant number of the AC coefficients to zero, (known as sparse data) which can then be more efficiently compressed by entropy coding (lossless compression) in the next step.
An example quantized DCT block:
Quantization eliminates a large amount of data, and is the main lossy processing step in MPEG-1 video encoding. This is also the primary source of most MPEG-1 video compression artifacts, like blockiness, color banding, noise
, ringing
, discoloration, et al. This happens when video is encoded with an insufficient bitrate, and the encoder is therefore forced to use high frame-level quantizers (strong quantization) through much of the video.
.
The DCT block tend to have the most important frequencies towards the top left corner. The coefficients tend to zero towards the bottom-right. Maximum compression can be achieved by a zig-zag scanning of the DCT block starting from the top left and using Run-length encoding techniques.
The DC coefficients and motion vectors are DPCM-encoded.
Run-length encoding
(RLE) is a very simple method of compressing repetition. A sequential string of characters, no matter how long, can be replaced with a few bytes, noting the value that repeats, and how many times. For example, if someone were to say "five nines", you would know they mean the number: 99999.
RLE is particularly effective after quantization, as a significant number of the AC coefficients are now zero (called sparse data), and can be represented with just a couple bytes. This is stored in a special 2-dimensional Huffman table that codes the run-length and the run-ending character.
Huffman Coding
is a very popular method of entropy coding, and used in MPEG-1 video to reduce the data size. The data is analyzed to find strings that repeat often. Those strings are then put into a special table, with the most frequently repeating data assigned the shortest code. This keeps the data as small as possible with this form of compression. Once the table is constructed, those strings in the data are replaced with their (much smaller) codes, which reference the appropriate entry in the table. The decoder simply reverses this process to produce the original data.
This is the final step in the video encoding process, so the result of Huffman coding
is known as the MPEG-1 video "bitstream."
(GOP) should be selected based on these factors. I-frame only sequences gives least compression, but is useful for random access, FF/FR and editability. I and P frame sequences give moderate compression but add a certain degree of random access, FF/FR functionality. I,P & B frame sequences give very high compression but also increases the coding/decoding delay significantly. Such configurations are therefore not suited for video-telephony or video-conferencing applications.
The typical data rate of an I-frame is 1 bit per pixel while that of a P-frame is 0.1 bit per pixel and for a B-frame, 0.015 bit per pixel.
MPEG-1 Audio utilizes psychoacoustics to significantly reduce the data rate required by an audio stream. It reduces or completely discards certain parts of the audio that the human ear can't hear, either because they are in frequencies where the ear has limited sensitivity, or are masked
by other (typically louder) sounds.
Channel Encoding:
MPEG-1 Audio is divided into 3 layers. Each higher layer is more computationally complex, and generally more efficient at lower bitrates than the previous. The layers are semi backwards compatible as higher layers reuse technologies implemented by the lower layers. A "Full" Layer II decoder can also play Layer I audio, but not Layer III audio, although not all higher level players are "full".
encoding on the hardware available circa
1990.
Layer I saw limited adoption in its time, and most notably was used on Philips
' defunct Digital Compact Cassette
at a bitrate of 384 kbit/s. With the substantial performance improvements in digital processing since its introduction, Layer I quickly became unnecessary and obsolete.
Layer I audio files typically use the extension .mp1 or sometimes .m1a
, relative to MP3, AAC
, etc.
(CCETT), Philips
, and Institut für Rundfunktechnik
(IRT/CNET) as part of the EUREKA 147 pan-European inter-governmental research and development initiative for the development of digital audio broadcasting.
Most key features of MPEG-1 Audio were directly inherited from MUSICAM, including the filter bank, time-domain processing, audio frame sizes, etc. However, improvements were made, and the actual MUSICAM algorithm was not used in the final MPEG-1 Layer II audio standard. The widespread usage of the term MUSICAM to refer to Layer II is entirely incorrect and discouraged for both technical and legal reasons.
filter bank
for time-frequency mapping; having overlapping ranges (i.e. polyphased) to prevent aliasing. The psychoacoustic model is based on the principles of auditory masking
, simultaneous masking
effects, and the absolute threshold of hearing
(ATH). The size of a Layer II frame is fixed at 1152-samples (coefficients).
Time domain
refers to how analysis and quantization is performed: on short, discrete samples/chunks of the audio waveform. This offers low delay as only a small number of samples are analyzed before encoding, as opposed to frequency domain
encoding (like MP3) which must analyze many times more samples before it can decide how to transform and output encoded audio. This also offers higher performance on complex, random and transient impulses (such as percussive instruments, and applause), offering avoidance of artifacts like pre-echo.
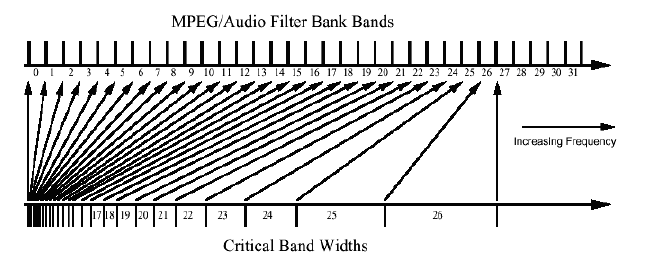 The 32 sub-band filter bank returns 32 amplitude
The 32 sub-band filter bank returns 32 amplitude
coefficients, one for each equal-sized frequency band/segment of the audio, which is about 700 Hz wide (depending on the audio's sampling frequency). The encoder then utilizes the psychoacoustic model to determine which sub-bands contain audio information that is less important, and so, where quantization will be inaudible, or at least much less noticeable.
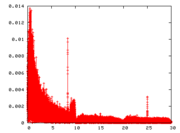 The psychoacoustic model is applied using a 1024-point Fast Fourier Transform
The psychoacoustic model is applied using a 1024-point Fast Fourier Transform
(FFT). Of the 1152 samples per frame, 64 samples at the top and bottom of the frequency range are ignored for this analysis. They are presumably not significant enough to change the result. The psychoacoustic model uses an empirically determined masking model to determine which sub-bands contribute more to the masking threshold
, and how much quantization noise each can contain without being perceived. Any sounds below the absolute threshold of hearing
(ATH) are completely discarded. The available bits are then assigned to each sub-band accordingly.
Typically, sub-bands are less important if they contain quieter sounds (smaller coefficient) than a neighboring (i.e. similar frequency) sub-band with louder sounds (larger coefficient). Also, "noise" components typically have a more significant masking effect than "tonal" components.
Less significant sub-bands are reduced in accuracy by quantization. This basically involves compressing the frequency range (amplitude of the coefficient), i.e. raising the noise floor. Then computing an amplification factor, for the decoder to use to re-expand each sub-band to the proper frequency range.
Layer II can also optionally use intensity stereo coding, a form of joint stereo. This means that the frequencies above 6 kHz of both channels are combined/down-mixed into one single (mono) channel, but the "side channel" information on the relative intensity (volume, amplitude) of each channel is preserved and encoded into the bitstream separately. On playback, the single channel is played through left and right speakers, with the intensity information applied to each channel to give the illusion of stereo sound. This perceptual trick is known as stereo irrelevancy. This can allow further reduction of the audio bitrate without much perceivable loss of fidelity, but is generally not used with higher bitrates as it does not provide very high quality (transparent) audio.
using the earliest reference implementation (more recent encoders should presumably perform even better). That (approximately) 1:6 compression ratio for CD audio is particularly impressive because it is quite close to the estimated upper limit of perceptual entropy, at just over 1:8. Achieving much higher compression is simply not possible without discarding some perceptible information.
MP2 remains a favoured lossy audio coding standard due to its particularly high audio coding performances on important audio material such as castanet, symphonic orchestra, male and female voices and particularly complex and high energy transients (impulses) like percussive sounds: triangle, glockenspiel and audience applause. More recent testing has shown that MPEG Multichannel
(based on MP2), despite being compromised by an inferior matrixed mode (for the sake of backwards compatibility) rates just slightly lower than much more recent audio codecs, such as Dolby Digital
(AC-3) and Advanced Audio Coding
(AAC) (mostly within the margin of error—and substantially superior in some cases, such as audience applause). This is one reason that MP2 audio continues to be used extensively. The MPEG-2 AAC Stereo verification tests reached a vastly different conclusion, however, showing AAC to provide superior performance to MP2 at half the bitrate. The reason for this disparity with both earlier and later tests is not clear, but strangely, a sample of applause is notably absent from this test.
Layer II audio files typically use the extension .mp2 or sometimes .m2a
) ISDN links, and 128 kbit/s for stereo sound.
ASPEC was itself based on Multiple adaptive Spectral audio Coding (MSC) by E. F. Schroeder, Optimum Coding in the Frequency domain (OCF) the doctoral thesis by Karlheinz Brandenburg
at the University of Erlangen-Nuremberg, Perceptual Transform Coding (PXFM) by J. D. Johnston at AT&T
Bell Labs
, and Transform coding of audio signals by Y. Mahieux and J. Petit at Institut für Rundfunktechnik
(IRT/CNET).
. Even though it utilizes some of the lower layer functions, MP3 is quite different from Layer II/MP2.
MP3 works on 1152 samples like Layer II, but needs to take multiple frames for analysis before frequency-domain (MDCT) processing and quantization can be effective. It outputs a variable number of samples, using a bit buffer to enable this variable bitrate (VBR) encoding while maintaining 1152 sample size output frames. This causes a significantly longer delay before output, which has caused MP3 to be considered unsuitable for studio applications where editing or other processing needs to take place.
MP3 does not benefit from the 32 sub-band polyphased filter bank, instead just using an 18-point MDCT transformation on each output to split the data into 576 frequency components, and processing it in the frequency domain. This extra granularity allows MP3 to have a much finer psychoacoustic model, and more carefully apply appropriate quantization to each band, providing much better low-bitrate performance.
Frequency-domain processing imposes some limitations as well, causing a factor of 12 or 36 × worse temporal resolution than Layer II. This causes quantization artifacts, due to transient sounds like percussive events and other high-frequency events that spread over a larger window. This results in audible smearing and pre-echo
. MP3 uses pre-echo detection routines, and VBR encoding, which allows it to temporarily increase the bitrate during difficult passages, in an attempt to reduce this effect. It is also able to switch between the normal 36 sample quantization window, and instead using 3× short 12 sample windows instead, to reduce the temporal (time) length of quantization artifacts. And yet in choosing a fairly small window size to make MP3's temporal response adequate enough to avoid the most serious artifacts, MP3 becomes much less efficient in frequency domain compression of stationary, tonal components.
Being forced to use a hybrid time domain (filter bank) /frequency domain (MDCT) model to fit in with Layer II simply wastes processing time and compromises quality by introducing aliasing artifacts. MP3 has an aliasing cancellation stage specifically to mask this problem, but which instead produces frequency domain energy which must be encoded in the audio. This is pushed to the top of the frequency range, where most people have limited hearing, in hopes the distortion it causes will be less audible.
Layer II's 1024 point FFT doesn't entirely cover all samples, and would omit several entire MP3 sub-bands, where quantization factors must be determined. MP3 instead uses two passes of FFT analysis for spectral estimation, to calculate the global and individual masking thresholds. This allows it to cover all 1152 samples. Of the two, it utilizes the global masking threshold level from the more critical pass, with the most difficult audio.
In addition to Layer II's intensity encoded joint stereo, MP3 can use middle/side (mid/side, m/s, MS, matrixed) joint stereo. With mid/side stereo, certain frequency ranges of both channels are merged into a single (middle, mid, L+R) mono channel, while the sound difference between the left and right channels is stored as a separate (side, L-R) channel. Unlike intensity stereo, this process does not discard any audio information. When combined with quantization, however, it can exaggerate artifacts.
If the difference between the left and right channels is small, the side channel will be small, which will offer as much as a 50% bitrate savings, and associated quality improvement. If the difference between left and right is large, standard (discrete, left/right) stereo encoding may be preferred, as mid/side joint stereo will not provide any benefits. An MP3 encoder can switch between m/s stereo and full stereo on a frame-by-frame basis.
Unlike Layers I/II, MP3 uses variable-length Huffman coding
(after perceptual) to further reduce the bitrate, without any further quality loss.
MP3's more fine-grained and selective quantization does prove notably superior to Layer II/MP2 at lower-bitrates, however. It is able to provide nearly equivalent audio quality to Layer II, at a 15% lower bitrate (approximately). 128 kbit/s is considered the "sweet spot
" for MP3; meaning it provides generally acceptable quality stereo sound on most music, and there are diminishing
quality improvements from increasing the bitrate further. MP3 is also regarded as exhibiting artifacts that are less annoying than Layer II, when both are used at bitrates that are too low to possibly provide faithful reproduction.
Layer III audio files use the extension .mp3.
standard includes several extensions to MPEG-1 Audio. These are known as MPEG-2 BC – backwards compatible with MPEG-1 Audio. MPEG-2 Audio is defined in ISO/IEC 13818-3
These sampling rates are exactly half that of those originally defined for MPEG-1 Audio. They were introduced to maintain higher quality sound when encoding audio at lower-bitrates. The even-lower bitrates were introduced because tests showed that MPEG-1 Audio could provide higher quality than any existing (circa
1994) very low bitrate (i.e. speech
) audio codecs.
Conformance: Procedures for testing conformance.
Provides two sets of guidelines and reference bitstreams for testing the conformance of MPEG-1 audio and video decoders, as well as the bitstreams produced by an encoder.
Simulation: Reference software.
C
reference code for encoding and decoding of audio and video, as well as multiplexing and demultiplexing.
This includes the ISO Dist10 audio encoder code, which LAME
and TooLAME
were originally based upon.
audio and video compression. MPEG-1 Part 2 video is rare nowadays, and this extension typically refers to an MPEG program stream (defined in MPEG-1 and MPEG-2) or MPEG transport stream (defined in MPEG-2). Other suffixes such as .m2ts also exists specifying the precise container, in this case MPEG-2 TS, but this has little relevance to MPEG-1 media.
.mp3 is the most common extension for files containing MPEG-1 Layer 3 audio. An MP3 file is typically an uncontained stream of raw audio; the conventional way to tag MP3 files is by writing data to "garbage" segments of each frame, which preserve the media information but are discarded by the player. This is similar in many respects to how raw .AAC files are tagged (but this is less supported nowadays, e.g. iTunes
).
Note that although it would apply, .mpg does not normally append raw AAC
or AAC in MPEG-2 Part 7 Containers. The .aac extension normally denotes these audio files.
Implementations
Video
Video is the technology of electronically capturing, recording, processing, storing, transmitting, and reconstructing a sequence of still images representing scenes in motion.- History :...
and audio
Audio frequency
An audio frequency or audible frequency is characterized as a periodic vibration whose frequency is audible to the average human...
. It is designed to compress VHS
VHS
The Video Home System is a consumer-level analog recording videocassette standard developed by Victor Company of Japan ....
-quality raw digital video and CD audio down to 1.5 Mbit/s (26:1 and 6:1 compression ratios respectively) without excessive quality loss, making video CD
Video CD
Before the advent of DVD and Blu-ray, the Video CD became the first format for distributing films on standard 120 mm optical discs. The format is a standard digital format for storing video on a Compact Disc...
s, digital cable
Cable television
Cable television is a system of providing television programs to consumers via radio frequency signals transmitted to televisions through coaxial cables or digital light pulses through fixed optical fibers located on the subscriber's property, much like the over-the-air method used in traditional...
/satellite
Satellite television
Satellite television is television programming delivered by the means of communications satellite and received by an outdoor antenna, usually a parabolic mirror generally referred to as a satellite dish, and as far as household usage is concerned, a satellite receiver either in the form of an...
TV and digital audio broadcasting
Digital audio broadcasting
Digital Audio Broadcasting is a digital radio technology for broadcasting radio stations, used in several countries, particularly in Europe. As of 2006, approximately 1,000 stations worldwide broadcast in the DAB format....
(DAB) possible.
Today, MPEG-1 has become the most widely compatible lossy audio/video format in the world, and is used in a large number of products and technologies. Perhaps the best-known part of the MPEG-1 standard is the MP3
MP3
MPEG-1 or MPEG-2 Audio Layer III, more commonly referred to as MP3, is a patented digital audio encoding format using a form of lossy data compression...
audio format it introduced.
The MPEG-1 standard is published as ISO/IEC
International Electrotechnical Commission
The International Electrotechnical Commission is a non-profit, non-governmental international standards organization that prepares and publishes International Standards for all electrical, electronic and related technologies – collectively known as "electrotechnology"...
11172 – Information technology—Coding of moving pictures and associated audio for digital storage media at up to about 1.5 Mbit/s. The standard consists of the following five Parts:
- Systems (storage and synchronization of video, audio, and other data together)
- Video (compressed video content)
- Audio (compressed audio content)
- Conformance testing (testing the correctness of implementations of the standard)
- Reference software (example software showing how to encode and decode according to the standard)
History
Modeled on the successful collaborative approach and the compression technologies developed by the Joint Photographic Experts GroupJoint Photographic Experts Group
The Joint Photographic Experts Group is the joint committee between ISO/IEC JTC1 and ITU-T that created the JPEG, JPEG 2000, and JPEG XR standards. It is one of two sub-groups of ISO/IEC Joint Technical Committee 1, Subcommittee 29, Working Group 1 - titled as Coding of still pictures...
and CCITT's Experts Group on Telephony (creators of the JPEG
JPEG
In computing, JPEG . The degree of compression can be adjusted, allowing a selectable tradeoff between storage size and image quality. JPEG typically achieves 10:1 compression with little perceptible loss in image quality....
image compression standard and the H.261
H.261
H.261 is a ITU-T video coding standard, ratified in November 1988. It is the first member of the H.26x family of video coding standards in the domain of the ITU-T Video Coding Experts Group , and was the first video codec that was useful in practical terms.H.261 was originally designed for...
standard for video conferencing respectively) the Moving Picture Experts Group
Moving Picture Experts Group
The Moving Picture Experts Group is a working group of experts that was formed by ISO and IEC to set standards for audio and video compression and transmission. It was established in 1988 by the initiative of Hiroshi Yasuda and Leonardo Chiariglione, who has been from the beginning the Chairman...
(MPEG) working group was established in January 1988. MPEG was formed to address the need for standard video and audio formats, and build on H.261 to get better quality through the use of more complex encoding methods.
Development of the MPEG-1 standard began in May 1988. 14 video and 14 audio codec proposals were submitted by individual companies and institutions for evaluation. The codecs were extensively tested for computational complexity
Computational Complexity
Computational Complexity may refer to:*Computational complexity theory*Computational Complexity...
and subjective
Subjectivity
Subjectivity refers to the subject and his or her perspective, feelings, beliefs, and desires. In philosophy, the term is usually contrasted with objectivity.-Qualia:...
(human perceived) quality, at data rates of 1.5 Mbit/s. This specific bitrate was chosen for transmission over T-1
Digital Signal 1
Digital signal 1 is a T-carrier signaling scheme devised by Bell Labs. DS1 is a widely used standard in telecommunications in North America and Japan to transmit voice and data between devices. E1 is used in place of T1 outside North America, Japan, and South Korea...
/E-1
E-carrier
In digital telecommunications, where a single physical wire pair can be used to carry many simultaneous voice conversations by time-division multiplexing, worldwide standards have been created and deployed...
lines and as the approximate data rate of audio CDs
Red Book (audio CD standard)
Red Book is the standard for audio CDs . It is named after one of the Rainbow Books, a series of books that contain the technical specifications for all CD and CD-ROM formats.The first edition of the Red Book was released in 1980 by Philips and Sony; it was adopted by the Digital Audio Disc...
. The codecs that excelled in this testing were utilized as the basis for the standard and refined further, with additional features and other improvements being incorporated in the process.
After 20 meetings of the full group in various cities around the world, and 4½ years of development and testing, the final standard (for parts 1–3) was approved in early November 1992 and published a few months later. The reported completion date of the MPEG-1 standard, varies greatly: a largely complete draft standard was produced in September 1990, and from that point on, only minor changes were introduced. The draft standard was publicly available for purchase. The standard was finished with the 6 November 1992 meeting. The Berkeley Plateau Multimedia Research Group developed a MPEG-1 decoder in November 1992. In July 1990, before the first draft of the MPEG-1 standard had even been written, work began on a second standard, MPEG-2
MPEG-2
MPEG-2 is a standard for "the generic coding of moving pictures and associated audio information". It describes a combination of lossy video compression and lossy audio data compression methods which permit storage and transmission of movies using currently available storage media and transmission...
, intended to extend MPEG-1 technology to provide full broadcast-quality video (as per CCIR 601
CCIR 601
ITU-R Recommendation BT.601, more commonly known by the abbreviations Rec. 601 or BT.601 is a standard published in 1982 by International Telecommunication Union - Radiocommunications sector for encoding interlaced analog video signals in digital video form...
) at high bitrates (3–15 Mbit/s), and support for interlaced video. Due in part to the similarity between the two codecs, the MPEG-2 standard includes full backwards compatibility with MPEG-1 video, so any MPEG-2 decoder can play MPEG-1 videos.
Notably, the MPEG-1 standard very strictly defines the bitstream
Bitstream
A bitstream or bit stream is a time series of bits.A bytestream is a series of bytes, typically of 8 bits each, and can be regarded as a special case of a bitstream....
, and decoder function, but does not define how MPEG-1 encoding is to be performed, although a reference implementation is provided in ISO/IEC-11172-5. This means that MPEG-1 coding efficiency can drastically vary depending on the encoder used, and generally means that newer encoders perform significantly better than their predecessors. The first three parts (Systems, Video and Audio) of ISO/IEC 11172 were published in August 1993.
| Part | Number | First public release date (First edition) | Latest correction | Title | Description |
|---|---|---|---|---|---|
| Part 1 | ISO/IEC 11172-1 | 1993 | 1999 | Systems | |
| Part 2 | ISO/IEC 11172-2 | 1993 | 2006 | Video | |
| Part 3 | ISO/IEC 11172-3 | 1993 | 1996 | Audio | |
| Part 4 | ISO/IEC 11172-4 | 1995 | 2007 | Compliance testing | |
| Part 5 | ISO/IEC TR 11172-5 | 1998 | 2007 | Software simulation |
Patents
MPEG-1 video and Layer I/II audio may be able to be implemented without payment of license fees. The ISO patent database lists one patent for ISO 11172, US 4,472,747, which expired in 2003. The near-complete draft of the MPEG-1 standard was publicly available as ISO CD 11172 by December 6, 1991. Due to its age, many of the patents on the technology have expired. Neither the Kuro5hin article "Patent Status of MPEG-1, H.261 and MPEG-2" nor a thread on the gstreamer-devel mailing list were able to list a single unexpired MPEG-1 video and Layer I/II audio patent. A discussion on whatwg mentioned the now expired US 5,214,678 patent as a possible patent on audio layer II. A full MPEG-1 decoder and encoder can not be implemented royalty free since there are companies that require patent fees for implementations of MPEG-1 Layer 3 AudioMP3
MPEG-1 or MPEG-2 Audio Layer III, more commonly referred to as MP3, is a patented digital audio encoding format using a form of lossy data compression...
as discussed in the MP3 article.
Applications
- Most popular computer softwareComputer softwareComputer software, or just software, is a collection of computer programs and related data that provide the instructions for telling a computer what to do and how to do it....
for video playback includes MPEG-1 decoding, in addition to any other supported formats. - The popularity of MP3MP3MPEG-1 or MPEG-2 Audio Layer III, more commonly referred to as MP3, is a patented digital audio encoding format using a form of lossy data compression...
audio has established a massive installed baseInstalled baseInstalled base or installed user base is a measure of the number of units of a particular type of system—usually a computing platform—actually in use, as opposed to market share, which only reflects sales over a particular period. Because installed base includes machines that may have been in use...
of hardware that can play back MPEG-1 Audio (all three layers). - "Virtually all digital audio devices" can play back MPEG-1 Audio. Many millions have been sold to-date.
- Before MPEG-2MPEG-2MPEG-2 is a standard for "the generic coding of moving pictures and associated audio information". It describes a combination of lossy video compression and lossy audio data compression methods which permit storage and transmission of movies using currently available storage media and transmission...
became widespread, many digital satellite/cable TV services used MPEG-1 exclusively. - The widespread popularity of MPEG-2 with broadcasters means MPEG-1 is playable by most digital cable and satellite set-top boxSet-top boxA set-top box or set-top unit is an information appliance device that generally contains a tuner and connects to a television set and an external source of signal, turning the signal into content which is then displayed on the television screen or other display device.-History:Before the...
es, and digital disc and tape players, due to backwards compatibility. - MPEG-1 is the exclusive video and audio format used on Video CDVideo CDBefore the advent of DVD and Blu-ray, the Video CD became the first format for distributing films on standard 120 mm optical discs. The format is a standard digital format for storing video on a Compact Disc...
(VCD), the first consumerConsumerConsumer is a broad label for any individuals or households that use goods generated within the economy. The concept of a consumer occurs in different contexts, so that the usage and significance of the term may vary.-Economics and marketing:...
digital video format, and still a very popular format around the world. - The Super Video CDSuper Video CDSuper Video CD is a digital format for storing video on standard compact discs. SVCD was intended as a successor to Video CD and an alternative to DVD-Video, and falls somewhere between both in terms of technical capability and picture quality...
standard, based on VCD, uses MPEG-1 audio exclusively, as well as MPEG-2 video. - The DVD-VideoDVD-VideoDVD-Video is a consumer video format used to store digital video on DVD discs, and is currently the dominant consumer video format in Asia, North America, Europe, and Australia. Discs using the DVD-Video specification require a DVD drive and a MPEG-2 decoder...
format uses MPEG-2 video primarily, but MPEG-1 support is explicitly defined in the standard. - The DVD-Video standard originally required MPEG-1 Layer II audio for PAL countries, but was changed to allow AC-3/Dolby DigitalDolby DigitalDolby Digital is the name for audio compression technologies developed by Dolby Laboratories. It was originally called Dolby Stereo Digital until 1994. Except for Dolby TrueHD, the audio compression is lossy. The first use of Dolby Digital was to provide digital sound in cinemas from 35mm film prints...
-only discs. MPEG-1 Layer II audio is still allowed on DVDs, although newer extensions to the format, like MPEG MultichannelMPEG MultichannelMPEG Multichannel is an extension to the MPEG-1 Layer II audio compression specification, as defined in the MPEG-2 Audio standard , which allows it provide up to 5.1-channels of audio...
, are rarely supported. - Most DVD players also support Video CD and MP3 CDMP3 CDAn MP3 CD is a Compact Disc that contains digital audio in the MP3 file format. Discs are written in the Yellow Book standard data format , as opposed to the Red Book standard audio format ....
playback, which use MPEG-1. - The international Digital Video Broadcasting (DVB) standard primarily uses MPEG-1 Layer II audio, and MPEG-2 video.
- The international Digital Audio BroadcastingDigital audio broadcastingDigital Audio Broadcasting is a digital radio technology for broadcasting radio stations, used in several countries, particularly in Europe. As of 2006, approximately 1,000 stations worldwide broadcast in the DAB format....
(DAB) standard uses MPEG-1 Layer II audio exclusively, due to MP2's especially high quality, modest decoder performance requirements, and tolerance of errors.
Part 1: Systems
Part 1 of the MPEG-1 standard covers systems, and is defined in ISO/IEC-11172-1.MPEG-1 Systems specifies the logical layout and methods used to store the encoded audio, video, and other data into a standard bitstream, and to maintain synchronization between the different contents. This file format
File format
A file format is a particular way that information is encoded for storage in a computer file.Since a disk drive, or indeed any computer storage, can store only bits, the computer must have some way of converting information to 0s and 1s and vice-versa. There are different kinds of formats for...
is specifically designed for storage on media, and transmission over data channels
Channel (communications)
In telecommunications and computer networking, a communication channel, or channel, refers either to a physical transmission medium such as a wire, or to a logical connection over a multiplexed medium such as a radio channel...
, that are considered relatively reliable. Only limited error protection is defined by the standard, and small errors in the bitstream may cause noticeable defects.
This structure was later named an MPEG program stream: "The MPEG-1 Systems design is essentially identical to the MPEG-2 Program Stream structure." This terminology is more popular, precise (differentiates it from an MPEG transport stream) and will be used here.
Elementary streams
Elementary Streams (ES) are the raw bitstreams of MPEG-1 audio and video encoded data (output from an encoder). These files can be distributed on their own, such as is the case with MP3 files.Packetized Elementary Streams (PES) are elementary streams packetized into packets of variable lengths, i.e., divided ES into independent chunks where cyclic redundancy check
Cyclic redundancy check
A cyclic redundancy check is an error-detecting code commonly used in digital networks and storage devices to detect accidental changes to raw data...
(CRC) checksum
Checksum
A checksum or hash sum is a fixed-size datum computed from an arbitrary block of digital data for the purpose of detecting accidental errors that may have been introduced during its transmission or storage. The integrity of the data can be checked at any later time by recomputing the checksum and...
was added to each packet for error detection.
System Clock Reference (SCR) is a timing value stored in a 33-bit header of each PES, at a frequency/precision of 90 kHz, with an extra 9-bit extension that stores additional timing data with a precision of 27 MHz. These are inserted by the encoder, derived from the system time clock (STC). Simultaneously encoded audio and video streams will not have identical SCR values, however, due to buffering, encoding, jitter, and other delay.
Program streams
Program Streams (PS) are concerned with combining multiple packetized elementary streams (usually just one audio and video PES) into a single stream, ensuring simultaneous delivery, and maintaining synchronization. The PS structure is known as a multiplexMultiplexing
The multiplexed signal is transmitted over a communication channel, which may be a physical transmission medium. The multiplexing divides the capacity of the low-level communication channel into several higher-level logical channels, one for each message signal or data stream to be transferred...
, or a container format.
Presentation time stamps (PTS) exist in PS to correct the inevitable disparity between audio and video SCR values (time-base correction). 90 kHz PTS values in the PS header tell the decoder which video SCR values match which audio SCR values. PTS determines when to display a portion of an MPEG program, and is also used by the decoder to determine when data can be discarded from the buffer. Either video or audio will be delayed by the decoder until the corresponding segment of the other arrives and can be decoded.
PTS handling can be problematic. Decoders must accept multiple program streams that have been concatenated (joined sequentially). This causes PTS values in the middle of the video to reset to zero, which then begin incrementing again. Such PTS wraparound disparities can cause timing issues that must be specially handled by the decoder.
Decoding Time Stamps (DTS), additionally, are required because of B-frames. With B-frames in the video stream, adjacent frames have to be encoded and decoded out-of-order (re-ordered frames). DTS is quite similar to PTS, but instead of just handling sequential frames, it contains the proper time-stamps to tell the decoder when to decode and display the next B-frame (types of frames explained below), ahead of its anchor (P- or I-) frame. Without B-frames in the video, PTS and DTS values are identical.
Multiplexing
To generate the PS, the multiplexer will interleave the (two or more) packetized elementary streams. This is done so the packets of the simultaneous streams can be transferred over the same channelChannel (communications)
In telecommunications and computer networking, a communication channel, or channel, refers either to a physical transmission medium such as a wire, or to a logical connection over a multiplexed medium such as a radio channel...
and are guaranteed to both arrive at the decoder at precisely the same time. This is a case of time-division multiplexing
Time-division multiplexing
Time-division multiplexing is a type of digital multiplexing in which two or more bit streams or signals are transferred apparently simultaneously as sub-channels in one communication channel, but are physically taking turns on the channel. The time domain is divided into several recurrent...
.
Determining how much data from each stream should be in each interleaved segment (the size of the interleave) is complicated, yet an important requirement. Improper interleaving will result in buffer underflows or overflows, as the receiver gets more of one stream than it can store (eg. audio), before it gets enough data to decode the other simultaneous stream (eg. video). The MPEG Video Buffering Verifier
Video buffering verifier
The video buffering verifier is a theoretical MPEG video buffer model used to ensure that an encoded video stream can be correctly buffered and played back at the decoder device....
(VBV) assists in determining if a multiplexed PS can be decoded by a device with a specified data throughput rate and buffer size. This offers feedback to the muxer and the encoder, so that they can change the mux size or adjust bitrates as needed for compliance.
Part 2: Video
Part 2 of the MPEG-1 standard covers video and is defined in ISO/IEC-11172-2. The design was heavily influenced by H.261H.261
H.261 is a ITU-T video coding standard, ratified in November 1988. It is the first member of the H.26x family of video coding standards in the domain of the ITU-T Video Coding Experts Group , and was the first video codec that was useful in practical terms.H.261 was originally designed for...
.
MPEG-1 Video exploits perceptual compression methods to significantly reduce the data rate required by a video stream. It reduces or completely discards information in certain frequencies and areas of the picture that the human eye has limited ability to fully perceive. It also exploits temporal (over time) and spatial (across a picture) redundancy common in video to achieve better data compression than would be possible otherwise. (See: Video compression)
Color space
Luma (video)
In video, luma, sometimes called luminance, represents the brightness in an image . Luma is typically paired with chrominance. Luma represents the achromatic image without any color, while the chroma components represent the color information...
(brightness, resolution) is stored separately from chroma
Chrominance
Chrominance is the signal used in video systems to convey the color information of the picture, separately from the accompanying luma signal . Chrominance is usually represented as two color-difference components: U = B' − Y' and V = R' − Y'...
(color, hue, phase) and even further separated into red and blue components. The chroma is also subsampled to 4:2:0, meaning it is reduced by one half vertically and one half horizontally, to just one quarter the resolution of the video.
This software algorithm also has analogies in hardware, such as the output from a Bayer pattern filter
Bayer filter
A Bayer filter mosaic is a color filter array for arranging RGB color filters on a square grid of photosensors. Its particular arrangement of color filters is used in most single-chip digital image sensors used in digital cameras, camcorders, and scanners to create a color image...
, common in digital colour cameras.
Because the human eye is much less sensitive to small changes in color than in brightness, chroma subsampling
Chroma subsampling
Chroma subsampling is the practice of encoding images by implementing less resolution for chroma information than for luma information, taking advantage of the human visual system's lower acuity for color differences than for luminance....
is a very effective way to reduce the amount of video data that needs to be compressed. On videos with fine detail (high spatial complexity) this can manifest as chroma aliasing
Aliasing
In signal processing and related disciplines, aliasing refers to an effect that causes different signals to become indistinguishable when sampled...
artifacts. Compared to other digital compression artifact
Compression artifact
A compression artifact is a noticeable distortion of media caused by the application of lossy data compression....
s, this issue seems to be very rarely a source of annoyance.
Because of subsampling, Y'CbCr video must always be stored using even dimensions (divisible by 2), otherwise chroma mismatch ("ghosts") will occur, and it will appear as if the color is ahead of, or behind the rest of the video, much like a shadow.
Y'CbCr is often inaccurately called YUV
YUV
YUV is a color space typically used as part of a color image pipeline. It encodes a color image or video taking human perception into account, allowing reduced bandwidth for chrominance components, thereby typically enabling transmission errors or compression artifacts to be more efficiently...
which is only used in the domain of analog
Analog transmission
Analog transmission is a transmission method of conveying voice, data, image, signal or video information using a continuous signal which varies in amplitude, phase, or some other property in proportion to that of a variable...
video signals. Similarly, the terms luminance
Luminance
Luminance is a photometric measure of the luminous intensity per unit area of light travelling in a given direction. It describes the amount of light that passes through or is emitted from a particular area, and falls within a given solid angle. The SI unit for luminance is candela per square...
and chrominance
Chrominance
Chrominance is the signal used in video systems to convey the color information of the picture, separately from the accompanying luma signal . Chrominance is usually represented as two color-difference components: U = B' − Y' and V = R' − Y'...
are often used instead of the (more accurate) terms luma and chroma.
Resolution/Bitrate
MPEG-1 supports resolutions up to 4095×4095 (12-bits), and bitrates up to 100 Mbit/s.MPEG-1 videos are most commonly seen using Source Input Format
Source Input Format
Source Input Format defined in MPEG-1, is a video format that was developed to allow the storage and transmission of digital video....
(SIF) resolution: 352x240, 352x288, or 320x240. These low resolutions, combined with a bitrate less than 1.5 Mbit/s, make up what is known as a constrained parameters bitstream (CPB), later renamed the "Low Level" (LL) profile in MPEG-2. This is the minimum video specifications any decoder
Decoder
A decoder is a device which does the reverse operation of an encoder, undoing the encoding so that the original information can be retrieved. The same method used to encode is usually just reversed in order to decode...
should be able to handle, to be considered MPEG-1 compliant. This was selected to provide a good balance between quality and performance, allowing the use of reasonably inexpensive hardware of the time.
Frame/picture/block types
MPEG-1 has several frame/picture types that serve different purposes. The most important, yet simplest, is I-frame.I-frames
I-frame is an abbreviation for Intra-frame, so-called because they can be decoded independently of any other frames. They may also be known as I-pictures, or keyframes due to their somewhat similar function to the key frameKey frame
A key frame in animation and filmmaking is a drawing that defines the starting and ending points of any smooth transition. They are called "frames" because their position in time is measured in frames on a strip of film...
s used in animation. I-frames can be considered effectively identical to baseline JPEG
JPEG
In computing, JPEG . The degree of compression can be adjusted, allowing a selectable tradeoff between storage size and image quality. JPEG typically achieves 10:1 compression with little perceptible loss in image quality....
images.
High-speed seeking through an MPEG-1 video is only possible to the nearest I-frame. When cutting a video it is not possible to start playback of a segment of video before the first I-frame in the segment (at least not without computationally intensive re-encoding). For this reason, I-frame-only MPEG videos are used in editing applications.
I-frame only compression is very fast, but produces very large file sizes: a factor of 3× (or more) larger than normally encoded MPEG-1 video, depending on how temporally complex a specific video is. I-frame only MPEG-1 video is very similar to MJPEG
MJPEG
In multimedia, Motion JPEG is an informal name for a class of video formats where each video frame or interlaced field of a digital video sequence is separately compressed as a JPEG image...
video. So much so that very high-speed and theoretically lossless (in reality, there are rounding errors) conversion can be made from one format to the other, provided a couple of restrictions (color space and quantization matrix) are followed in the creation of the bitstream.
The length between I-frames is known as the group of pictures
Group of pictures
In Video coding, a group of pictures, or GOP structure, specifies the order in which intra- and inter-frames are arranged. The GOP is a group of successive pictures within a coded video stream. Each coded video stream consists of successive GOPs...
(GOP) size. MPEG-1 most commonly uses a GOP size of 15-18. i.e. 1 I-frame for every 14-17 non-I-frames (some combination of P- and B- frames). With more intelligent encoders, GOP size is dynamically chosen, up to some pre-selected maximum limit.
Limits are placed on the maximum number of frames between I-frames due to decoding complexing, decoder buffer size, recovery time after data errors, seeking ability, and accumulation of IDCT errors in low-precision implementations most common in hardware decoders (See: IEEE-1180).
P-frames
P-frame is an abbreviation for Predicted-frame. They may also be called forward-predicted frames, or inter-frames (B-frames are also inter-frames).P-frames exist to improve compression by exploiting the temporal (over time) redundancy in a video. P-frames store only the difference in image from the frame (either an I-frame or P-frame) immediately preceding it (this reference frame is also called the anchor frame).
The difference between a P-frame and its anchor frame is calculated using motion vectors on each macroblock of the frame (see below). Such motion vector data will be embedded in the P-frame for use by the decoder.
A P-frame can contain any number of intra-coded blocks, in addition to any forward-predicted blocks.
If a video drastically changes from one frame to the next (such as a cut
Cut (filmmaking)
In the post-production process of film editing and video editing, a cut is an abrupt, but usually trivial film transition from one sequence to another. It is synonymous with the term edit, though "edit" can imply any number of transitions or effects. The cut, dissolve and wipe serve as the three...
), it is more efficient to encode it as an I-frame.
B-frames
B-frame stands for bidirectional-frame. They may also be known as backwards-predicted frames or B-pictures. B-frames are quite similar to P-frames, except they can make predictions using both the previous and future frames (i.e. two anchor frames).It is therefore necessary for the player to first decode the next I- or P- anchor frame sequentially after the B-frame, before the B-frame can be decoded and displayed. This means decoding B-frames requires larger data buffers and causes an increased delay on both decoding and during encoding. This also necessitates the decoding time stamps (DTS) feature in the container/system stream (see above). As such, B-frames have long been subject of much controversy, they are often avoided in videos, and are sometimes not fully supported by hardware decoders.
No other frames are predicted from a B-frame. Because of this, a very low bitrate B-frame can be inserted, where needed, to help control the bitrate. If this was done with a P-frame, future P-frames would be predicted from it and would lower the quality of the entire sequence. However, similarly, the future P-frame must still encode all the changes between it and the previous I- or P- anchor frame. B-frames can also be beneficial in videos where the background behind an object is being revealed over several frames, or in fading transitions, such as scene changes.
A B-frame can contain any number of intra-coded blocks and forward-predicted blocks, in addition to backwards-predicted, or bidirectionally predicted blocks.
D-frames
MPEG-1 has a unique frame type not found in later video standards. D-frames or DC-pictures are independent images (intra-frames) that have been encoded DC-only (AC coefficients are removed—see DCT below) and hence are very low quality. D-frames are never referenced by I-, P- or B- frames. D-frames are only used for fast previews of video, for instance when seeking through a video at high speed.Given moderately higher-performance decoding equipment, this feature can be approximated by decoding I-frames instead. This provides higher quality previews, and without the need for D-frames taking up space in the stream, yet not improving video quality.
Macroblocks
MPEG-1 operates on video in a series of 8x8 blocks for quantization. However, because chroma (color) is subsampled by a factor of 4, each pair of (red and blue) chroma blocks corresponds to 4 different luma blocks. This set of 6 blocks, with a resolution of 16x16, is called a macroblock.A macroblock is the smallest independent unit of (color) video. Motion vectors (see below) operate solely at the macroblock level.
If the height and/or width of the video is not exact multiples of 16, a full row of macroblocks must still be encoded (though not displayed) to store the remainder of the picture (macroblock padding). This wastes a significant amount of data in the bitstream, and is to be strictly avoided.
Some decoders will also improperly handle videos with partial macroblocks, resulting in visible artifacts.
Motion vectors
To decrease the amount of spatial redundancy in a video, only blocks that change are updated, (up to the maximum GOP size). This is known as conditional replenishment. However, this is not very effective by itself. Movement of the objects, and/or the camera may result in large portions of the frame needing to be updated, even though only the position of the previously encoded objects has changed. Through motion estimation the encoder can compensate for this movement and remove a large amount of redundant information.The encoder compares the current frame with adjacent parts of the video from the anchor frame (previous I- or P- frame) in a diamond pattern, up to a (encoder-specific) predefined radius
Radius
In classical geometry, a radius of a circle or sphere is any line segment from its center to its perimeter. By extension, the radius of a circle or sphere is the length of any such segment, which is half the diameter. If the object does not have an obvious center, the term may refer to its...
limit from the area of the current macroblock. If a match is found, only the direction and distance (i.e. the vector of the motion) from the previous video area to the current macroblock need to be encoded into the inter-frame (P- or B- frame). The reverse of this process, performed by the decoder to reconstruct the picture, is called motion compensation.
A predicted macroblock rarely matches the current picture perfectly, however. The differences between the estimated matching area, and the real frame/macroblock is called the prediction error. The larger the error, the more data must be additionally encoded in the frame. For efficient video compression, it is very important that the encoder is capable of effectively and precisely performing motion estimation.
Motion vectors record the distance between two areas on screen based on the number of pixels (called pels). MPEG-1 video uses a motion vector (MV) precision of one half of one pixel, or half-pel. The finer the precision of the MVs, the more accurate the match is likely to be, and the more efficient the compression. There are trade-offs to higher precision, however. Finer MVs result in larger data size, as larger numbers must be stored in the frame for every single MV, increased coding complexity as increasing levels of interpolation on the macroblock are required for both the encoder and decoder, and diminishing returns (minimal gains) with higher precision MVs. Half-pel was chosen as the ideal trade-off. (See: qpel
Qpel
Quarter pixel refers to a quarter of a standard pixel. It is used in many modern video encoding standards such as MPEG-4 ASP and H.264/AVC to refer to quarter pixel precision in motion estimation and motion compensation...
)
Because neighboring macroblocks are likely to have very similar motion vectors, this redundant information can be compressed quite effectively by being stored DPCM-encoded. Only the (smaller) amount of difference between the MVs for each macroblock needs to be stored in the final bitstream.
P-frames have 1 motion vector per macroblock, relative to the previous anchor frame. B-frames, however, can use 2 motion vectors; one from the previous anchor frame, and one from the future anchor frame.
Partial macroblocks, and black borders/bars encoded into the video that do not fall exactly on a macroblock boundary, cause havoc with motion prediction. The block padding/border information prevents the macroblock from closely matching with any other area of the video, and so, significantly larger prediction error information must be encoded for every one of the several dozen partial macroblocks along the screen border. DCT encoding and quantization (see below) also isn't nearly as effective when there is large/sharp picture contrast in a block.
An even more serious problem exists with macroblocks that contain significant, random, edge noise, where the picture transitions to (typically) black. All the above problems also apply to edge noise. In addition, the added randomness is simply impossible to compress significantly. All of these effects will lower the quality (or increase the bitrate) of the video substantially.
DCT
Each 8x8 block is encoded by first applying a Forward Discrete Cosine TransformDiscrete cosine transform
A discrete cosine transform expresses a sequence of finitely many data points in terms of a sum of cosine functions oscillating at different frequencies. DCTs are important to numerous applications in science and engineering, from lossy compression of audio and images A discrete cosine transform...
(FDCT) and then a quantization process. The FDCT process (by itself) is theoretically lossless, and can be reversed by applying an Inverse DCT (IDCT) to reproduce the original values (in the absence of any quantization and rounding errors). In reality, there are some (sometimes large) rounding errors introduced both by quantization in the encoder (as described in the next section) and by IDCT approximation error in the decoder. The minimum allowed accuracy of a decoder IDCT approximation is defined by ISO/IEC 23002-1. (Prior to 2006, it was specified by IEEE 1180-1990.)
The FDCT process converts the 8x8 block of uncompressed pixel values (brightness or color difference values) into an 8x8 indexed array of frequency coefficient values. One of these is the (statistically high in variance) DC coefficient, which represents the average value of the entire 8x8 block. The other 63 coefficients are the statistically smaller AC coefficients, which are positive or negative values each representing sinusoidal deviations from the flat block value represented by the DC coefficient.
An example of an encoded 8x8 FDCT block:
Since the DC coefficient value is statistically correlated from one block to the next, it is compressed using DPCM encoding. Only the (smaller) amount of difference between each DC value and the value of the DC coefficient in the block to its left needs to be represented in the final bitstream.
Additionally, the frequency conversion performed by applying the DCT provides a statistical decorrelation function to efficiently concentrate the signal into fewer high-amplitude values prior to applying quantization (see below).
Quantization
QuantizationQuantization (image processing)
Quantization, involved in image processing, is a lossy compression technique achieved by compressing a range of values to a single quantum value. When the number of discrete symbols in a given stream is reduced, the stream becomes more compressible. For example, reducing the number of colors...
(of digital data) is, essentially, the process of reducing the accuracy of a signal, by dividing it into some larger step size (i.e. finding the nearest multiple, and discarding the remainder/modulus).
The frame-level quantizer is a number from 0 to 31 (although encoders will usually omit/disable some of the extreme values) which determines how much information will be removed from a given frame. The frame-level quantizer is either dynamically selected by the encoder to maintain a certain user-specified bitrate, or (much less commonly) directly specified by the user.
Contrary to popular belief, a fixed frame-level quantizer (set by the user) does not deliver a constant level of quality. Instead, it is an arbitrary metric that will provide a somewhat varying level of quality, depending on the contents of each frame. Given two files of identical sizes, the one encoded at an average bitrate should look better than the one encoded with a fixed quantizer (variable bitrate). Constant quantizer encoding can be used, however, to accurately determine the minimum and maximum bitrates possible for encoding a given video.
A quantization matrix is a string of 64-numbers (0-255) which tells the encoder how relatively important or unimportant each piece of visual information is. Each number in the matrix corresponds to a certain frequency component of the video image.
An example quantization matrix:
Quantization is performed by taking each of the 64 frequency values of the DCT block, dividing them by the frame-level quantizer, then dividing them by their corresponding values in the quantization matrix. Finally, the result is rounded down. This significantly reduces, or completely eliminates, the information in some frequency components of the picture. Typically, high frequency information is less visually important, and so high frequencies are much more strongly quantized (drastically reduced). MPEG-1 actually uses two separate quantization matrices, one for intra-blocks (I-blocks) and one for inter-block (P- and B- blocks) so quantization of different block types can be done independently, and so, more effectively.
This quantization process usually reduces a significant number of the AC coefficients to zero, (known as sparse data) which can then be more efficiently compressed by entropy coding (lossless compression) in the next step.
An example quantized DCT block:
Quantization eliminates a large amount of data, and is the main lossy processing step in MPEG-1 video encoding. This is also the primary source of most MPEG-1 video compression artifacts, like blockiness, color banding, noise
Noise
In common use, the word noise means any unwanted sound. In both analog and digital electronics, noise is random unwanted perturbation to a wanted signal; it is called noise as a generalisation of the acoustic noise heard when listening to a weak radio transmission with significant electrical noise...
, ringing
Ringing (signal)
In electronics, signal processing, and video, ringing is unwanted oscillation of a signal, particularly in the step response...
, discoloration, et al. This happens when video is encoded with an insufficient bitrate, and the encoder is therefore forced to use high frame-level quantizers (strong quantization) through much of the video.
Entropy coding
Several steps in the encoding of MPEG-1 video are lossless, meaning they will be reversed upon decoding, to produce exactly the same (original) values. Since these lossless data compression steps don't add noise into, or otherwise change the contents (unlike quantization), it is sometimes referred to as noiseless coding. Since lossless compression aims to remove as much redundancy as possible, it is known as entropy coding in the field of information theoryInformation theory
Information theory is a branch of applied mathematics and electrical engineering involving the quantification of information. Information theory was developed by Claude E. Shannon to find fundamental limits on signal processing operations such as compressing data and on reliably storing and...
.
The DCT block tend to have the most important frequencies towards the top left corner. The coefficients tend to zero towards the bottom-right. Maximum compression can be achieved by a zig-zag scanning of the DCT block starting from the top left and using Run-length encoding techniques.
The DC coefficients and motion vectors are DPCM-encoded.
Run-length encoding
Run-length encoding
Run-length encoding is a very simple form of data compression in which runs of data are stored as a single data value and count, rather than as the original run...
(RLE) is a very simple method of compressing repetition. A sequential string of characters, no matter how long, can be replaced with a few bytes, noting the value that repeats, and how many times. For example, if someone were to say "five nines", you would know they mean the number: 99999.
RLE is particularly effective after quantization, as a significant number of the AC coefficients are now zero (called sparse data), and can be represented with just a couple bytes. This is stored in a special 2-dimensional Huffman table that codes the run-length and the run-ending character.
Huffman Coding
Huffman coding
In computer science and information theory, Huffman coding is an entropy encoding algorithm used for lossless data compression. The term refers to the use of a variable-length code table for encoding a source symbol where the variable-length code table has been derived in a particular way based on...
is a very popular method of entropy coding, and used in MPEG-1 video to reduce the data size. The data is analyzed to find strings that repeat often. Those strings are then put into a special table, with the most frequently repeating data assigned the shortest code. This keeps the data as small as possible with this form of compression. Once the table is constructed, those strings in the data are replaced with their (much smaller) codes, which reference the appropriate entry in the table. The decoder simply reverses this process to produce the original data.
This is the final step in the video encoding process, so the result of Huffman coding
Huffman coding
In computer science and information theory, Huffman coding is an entropy encoding algorithm used for lossless data compression. The term refers to the use of a variable-length code table for encoding a source symbol where the variable-length code table has been derived in a particular way based on...
is known as the MPEG-1 video "bitstream."
GOP configurations for specific applications
I-frames store complete frame info within the frame and is therefore suited for random access. P-frames provide compression using motion vectors relative to the previous frame ( I or P ). B-frames provide maximum compression but requires the previous as well as next frame for computation. Therefore, processing of B-frames require more buffer on the decoded side. A configuration of the Group of PicturesGroup of pictures
In Video coding, a group of pictures, or GOP structure, specifies the order in which intra- and inter-frames are arranged. The GOP is a group of successive pictures within a coded video stream. Each coded video stream consists of successive GOPs...
(GOP) should be selected based on these factors. I-frame only sequences gives least compression, but is useful for random access, FF/FR and editability. I and P frame sequences give moderate compression but add a certain degree of random access, FF/FR functionality. I,P & B frame sequences give very high compression but also increases the coding/decoding delay significantly. Such configurations are therefore not suited for video-telephony or video-conferencing applications.
The typical data rate of an I-frame is 1 bit per pixel while that of a P-frame is 0.1 bit per pixel and for a B-frame, 0.015 bit per pixel.
Part 3: Audio
Part 3 of the MPEG-1 standard covers audio and is defined in ISO/IEC-11172-3.MPEG-1 Audio utilizes psychoacoustics to significantly reduce the data rate required by an audio stream. It reduces or completely discards certain parts of the audio that the human ear can't hear, either because they are in frequencies where the ear has limited sensitivity, or are masked
Auditory masking
Auditory masking occurs when the perception of one sound is affected by the presence of another sound.- Simultaneous masking :Simultaneous masking is when a sound is made inaudible by a "masker", a noise or unwanted sound of the same duration as the original sound.-Critical bandwidth:If two sounds...
by other (typically louder) sounds.
Channel Encoding:
- Mono
- Joint Stereo – intensity encoded
- Joint Stereo – M/S encoded for Layer 3 only
- Stereo
- Dual (two uncorrelated mono channels)
- Sampling rateSampling rateThe sampling rate, sample rate, or sampling frequency defines the number of samples per unit of time taken from a continuous signal to make a discrete signal. For time-domain signals, the unit for sampling rate is hertz , sometimes noted as Sa/s...
s: 32000, 44100, and 48000 Hz - BitrateBitrateIn telecommunications and computing, bit rate is the number of bits that are conveyed or processed per unit of time....
s: 32, 48, 56, 64, 80, 96, 112, 128, 160, 192, 224, 256, 320 and 384 kbit/s
MPEG-1 Audio is divided into 3 layers. Each higher layer is more computationally complex, and generally more efficient at lower bitrates than the previous. The layers are semi backwards compatible as higher layers reuse technologies implemented by the lower layers. A "Full" Layer II decoder can also play Layer I audio, but not Layer III audio, although not all higher level players are "full".
Layer I
MPEG-1 Layer I is nothing more than a simplified version of Layer II. Layer I uses a smaller 384-sample frame size for very low delay, and finer resolution. This is advantageous for applications like teleconferencing, studio editing, etc. It has lower complexity than Layer II to facilitate real-timeReal-time computing
In computer science, real-time computing , or reactive computing, is the study of hardware and software systems that are subject to a "real-time constraint"— e.g. operational deadlines from event to system response. Real-time programs must guarantee response within strict time constraints...
encoding on the hardware available circa
Circa
Circa , usually abbreviated c. or ca. , means "approximately" in the English language, usually referring to a date...
1990.
Layer I saw limited adoption in its time, and most notably was used on Philips
Philips
Koninklijke Philips Electronics N.V. , more commonly known as Philips, is a multinational Dutch electronics company....
' defunct Digital Compact Cassette
Digital Compact Cassette
Digital Compact Cassette was a magnetic tape sound recording format introduced by Philips and Matsushita in late 1992 and pitched as a successor to the standard analog cassette. It was also a direct competitor to Sony's MiniDisc but neither format toppled the then ubiquitous analog cassette...
at a bitrate of 384 kbit/s. With the substantial performance improvements in digital processing since its introduction, Layer I quickly became unnecessary and obsolete.
Layer I audio files typically use the extension .mp1 or sometimes .m1a
Layer II
MPEG-1 Layer II (MP2—often incorrectly called MUSICAM) is a lossy audio format designed to provide high quality at about 192 kbit/s for stereo sound. Decoding MP2 audio is computationally simpleComputational complexity theory
Computational complexity theory is a branch of the theory of computation in theoretical computer science and mathematics that focuses on classifying computational problems according to their inherent difficulty, and relating those classes to each other...
, relative to MP3, AAC
Advanced Audio Coding
Advanced Audio Coding is a standardized, lossy compression and encoding scheme for digital audio. Designed to be the successor of the MP3 format, AAC generally achieves better sound quality than MP3 at similar bit rates....
, etc.
History/MUSICAM
MPEG-1 Layer II was derived from the MUSICAM (Masking pattern adapted Universal Subband Integrated Coding And Multiplexing) audio codec, developed by Centre commun d'études de télévision et télécommunicationsCentre commun d'études de télévision et télécommunications
CCETT or Centre commun d'études de télévision et télécommunications was a research centre created in Rennes in 1972 jointly by the Office de Radiodiffusion Télévision Française and Centre National...
(CCETT), Philips
Philips
Koninklijke Philips Electronics N.V. , more commonly known as Philips, is a multinational Dutch electronics company....
, and Institut für Rundfunktechnik
Institut für Rundfunktechnik
The Institut für Rundfunktechnik GmbH is the research centre of the German broadcasters , Austria's broadcaster and the Swiss public broadcaster . It is located in Munich and is responsible for the research and standardisation of broadcasting technology...
(IRT/CNET) as part of the EUREKA 147 pan-European inter-governmental research and development initiative for the development of digital audio broadcasting.
Most key features of MPEG-1 Audio were directly inherited from MUSICAM, including the filter bank, time-domain processing, audio frame sizes, etc. However, improvements were made, and the actual MUSICAM algorithm was not used in the final MPEG-1 Layer II audio standard. The widespread usage of the term MUSICAM to refer to Layer II is entirely incorrect and discouraged for both technical and legal reasons.
Technical details
Layer II/MP2 is a time-domain encoder. It uses a low-delay 32 sub-band polyphasedPolyphase quadrature filter
A polyphase quadrature filter, or PQF, is a filter bank which splits an input signal into a given number N of equidistant sub-bands. These sub-bands are subsampled by a factor of N, so they are critically sampled....
filter bank
Filter bank
In signal processing, a filter bank is an array of band-pass filters that separates the input signal into multiple components, each one carrying a single frequency subband of the original signal. One application of a filter bank is a graphic equalizer, which can attenuate the components...
for time-frequency mapping; having overlapping ranges (i.e. polyphased) to prevent aliasing. The psychoacoustic model is based on the principles of auditory masking
Auditory masking
Auditory masking occurs when the perception of one sound is affected by the presence of another sound.- Simultaneous masking :Simultaneous masking is when a sound is made inaudible by a "masker", a noise or unwanted sound of the same duration as the original sound.-Critical bandwidth:If two sounds...
, simultaneous masking
Simultaneous masking
In acoustics, simultaneous masking is masking between two concurrent sounds. Sometimes called frequency masking or spectral masking since it is often observed when the sounds share a frequency band e.g. two sine tones at 440 and 450 Hz can be perceived clearly when separated...
effects, and the absolute threshold of hearing
Absolute threshold of hearing
The absolute threshold of hearing is the minimum sound level of a pure tone that an average ear with normal hearing can hear with no other sound present. The absolute threshold relates to the sound that can just be heard by the organism...
(ATH). The size of a Layer II frame is fixed at 1152-samples (coefficients).
Time domain
Time domain
Time domain is a term used to describe the analysis of mathematical functions, physical signals or time series of economic or environmental data, with respect to time. In the time domain, the signal or function's value is known for all real numbers, for the case of continuous time, or at various...
refers to how analysis and quantization is performed: on short, discrete samples/chunks of the audio waveform. This offers low delay as only a small number of samples are analyzed before encoding, as opposed to frequency domain
Frequency domain
In electronics, control systems engineering, and statistics, frequency domain is a term used to describe the domain for analysis of mathematical functions or signals with respect to frequency, rather than time....
encoding (like MP3) which must analyze many times more samples before it can decide how to transform and output encoded audio. This also offers higher performance on complex, random and transient impulses (such as percussive instruments, and applause), offering avoidance of artifacts like pre-echo.
Amplitude
Amplitude is the magnitude of change in the oscillating variable with each oscillation within an oscillating system. For example, sound waves in air are oscillations in atmospheric pressure and their amplitudes are proportional to the change in pressure during one oscillation...
coefficients, one for each equal-sized frequency band/segment of the audio, which is about 700 Hz wide (depending on the audio's sampling frequency). The encoder then utilizes the psychoacoustic model to determine which sub-bands contain audio information that is less important, and so, where quantization will be inaudible, or at least much less noticeable.
Fast Fourier transform
A fast Fourier transform is an efficient algorithm to compute the discrete Fourier transform and its inverse. "The FFT has been called the most important numerical algorithm of our lifetime ." There are many distinct FFT algorithms involving a wide range of mathematics, from simple...
(FFT). Of the 1152 samples per frame, 64 samples at the top and bottom of the frequency range are ignored for this analysis. They are presumably not significant enough to change the result. The psychoacoustic model uses an empirically determined masking model to determine which sub-bands contribute more to the masking threshold
Masking threshold
The masking threshold is the sound pressure level of a sound needed to make the sound perceptible in the presence of another noice, called a "masker". This threshold depends upon the frequency, the kind of masker, and the kind of sound being masked...
, and how much quantization noise each can contain without being perceived. Any sounds below the absolute threshold of hearing
Absolute threshold of hearing
The absolute threshold of hearing is the minimum sound level of a pure tone that an average ear with normal hearing can hear with no other sound present. The absolute threshold relates to the sound that can just be heard by the organism...
(ATH) are completely discarded. The available bits are then assigned to each sub-band accordingly.
Typically, sub-bands are less important if they contain quieter sounds (smaller coefficient) than a neighboring (i.e. similar frequency) sub-band with louder sounds (larger coefficient). Also, "noise" components typically have a more significant masking effect than "tonal" components.
Less significant sub-bands are reduced in accuracy by quantization. This basically involves compressing the frequency range (amplitude of the coefficient), i.e. raising the noise floor. Then computing an amplification factor, for the decoder to use to re-expand each sub-band to the proper frequency range.
Layer II can also optionally use intensity stereo coding, a form of joint stereo. This means that the frequencies above 6 kHz of both channels are combined/down-mixed into one single (mono) channel, but the "side channel" information on the relative intensity (volume, amplitude) of each channel is preserved and encoded into the bitstream separately. On playback, the single channel is played through left and right speakers, with the intensity information applied to each channel to give the illusion of stereo sound. This perceptual trick is known as stereo irrelevancy. This can allow further reduction of the audio bitrate without much perceivable loss of fidelity, but is generally not used with higher bitrates as it does not provide very high quality (transparent) audio.
Quality
Subjective audio testing by experts, in the most critical conditions ever implemented, has shown MP2 to offer transparent audio compression at 256 kbit/s for 16-bit 44.1 kHz CD audioRed Book (audio CD standard)
Red Book is the standard for audio CDs . It is named after one of the Rainbow Books, a series of books that contain the technical specifications for all CD and CD-ROM formats.The first edition of the Red Book was released in 1980 by Philips and Sony; it was adopted by the Digital Audio Disc...
using the earliest reference implementation (more recent encoders should presumably perform even better). That (approximately) 1:6 compression ratio for CD audio is particularly impressive because it is quite close to the estimated upper limit of perceptual entropy, at just over 1:8. Achieving much higher compression is simply not possible without discarding some perceptible information.
MP2 remains a favoured lossy audio coding standard due to its particularly high audio coding performances on important audio material such as castanet, symphonic orchestra, male and female voices and particularly complex and high energy transients (impulses) like percussive sounds: triangle, glockenspiel and audience applause. More recent testing has shown that MPEG Multichannel
MPEG Multichannel
MPEG Multichannel is an extension to the MPEG-1 Layer II audio compression specification, as defined in the MPEG-2 Audio standard , which allows it provide up to 5.1-channels of audio...
(based on MP2), despite being compromised by an inferior matrixed mode (for the sake of backwards compatibility) rates just slightly lower than much more recent audio codecs, such as Dolby Digital
Dolby Digital
Dolby Digital is the name for audio compression technologies developed by Dolby Laboratories. It was originally called Dolby Stereo Digital until 1994. Except for Dolby TrueHD, the audio compression is lossy. The first use of Dolby Digital was to provide digital sound in cinemas from 35mm film prints...
(AC-3) and Advanced Audio Coding
Advanced Audio Coding
Advanced Audio Coding is a standardized, lossy compression and encoding scheme for digital audio. Designed to be the successor of the MP3 format, AAC generally achieves better sound quality than MP3 at similar bit rates....
(AAC) (mostly within the margin of error—and substantially superior in some cases, such as audience applause). This is one reason that MP2 audio continues to be used extensively. The MPEG-2 AAC Stereo verification tests reached a vastly different conclusion, however, showing AAC to provide superior performance to MP2 at half the bitrate. The reason for this disparity with both earlier and later tests is not clear, but strangely, a sample of applause is notably absent from this test.
Layer II audio files typically use the extension .mp2 or sometimes .m2a
Layer III/MP3
MPEG-1 Layer III (MP3) is a lossy audio format designed to provide acceptable quality at about 64 kbit/s for monaural audio over single-channel (BRIBasic rate interface
Basic Rate Interface is an Integrated Services Digital Network configuration intended primarily for use in subscriber lines similar to those that have long been used for plain old telephone service...
) ISDN links, and 128 kbit/s for stereo sound.
History/ASPEC
Layer III/MP3 was derived from the Adaptive Spectral Perceptual Entropy Coding (ASPEC) codec developed by Fraunhofer as part of the EUREKA 147 pan-European inter-governmental research and development initiative for the development of digital audio broadcasting. ASPEC was adapted to fit in with the Layer II/MUSICAM model (frame size, filter bank, FFT, etc.), to become Layer III.ASPEC was itself based on Multiple adaptive Spectral audio Coding (MSC) by E. F. Schroeder, Optimum Coding in the Frequency domain (OCF) the doctoral thesis by Karlheinz Brandenburg
Karlheinz Brandenburg
Karlheinz Brandenburg is an audio engineer who has contributed to the audio compression format MPEG Audio Layer 3, more commonly known as MP3.- Biography :...
at the University of Erlangen-Nuremberg, Perceptual Transform Coding (PXFM) by J. D. Johnston at AT&T
AT&T
AT&T Inc. is an American multinational telecommunications corporation headquartered in Whitacre Tower, Dallas, Texas, United States. It is the largest provider of mobile telephony and fixed telephony in the United States, and is also a provider of broadband and subscription television services...
Bell Labs
Bell Labs
Bell Laboratories is the research and development subsidiary of the French-owned Alcatel-Lucent and previously of the American Telephone & Telegraph Company , half-owned through its Western Electric manufacturing subsidiary.Bell Laboratories operates its...
, and Transform coding of audio signals by Y. Mahieux and J. Petit at Institut für Rundfunktechnik
Institut für Rundfunktechnik
The Institut für Rundfunktechnik GmbH is the research centre of the German broadcasters , Austria's broadcaster and the Swiss public broadcaster . It is located in Munich and is responsible for the research and standardisation of broadcasting technology...
(IRT/CNET).
Technical details
MP3 is a frequency-domain audio transform encoderTransform coding
Transform coding is a type of data compression for "natural" data like audio signals or photographic images. The transformation is typically lossy, resulting in a lower quality copy of the original input....
. Even though it utilizes some of the lower layer functions, MP3 is quite different from Layer II/MP2.
MP3 works on 1152 samples like Layer II, but needs to take multiple frames for analysis before frequency-domain (MDCT) processing and quantization can be effective. It outputs a variable number of samples, using a bit buffer to enable this variable bitrate (VBR) encoding while maintaining 1152 sample size output frames. This causes a significantly longer delay before output, which has caused MP3 to be considered unsuitable for studio applications where editing or other processing needs to take place.
MP3 does not benefit from the 32 sub-band polyphased filter bank, instead just using an 18-point MDCT transformation on each output to split the data into 576 frequency components, and processing it in the frequency domain. This extra granularity allows MP3 to have a much finer psychoacoustic model, and more carefully apply appropriate quantization to each band, providing much better low-bitrate performance.
Frequency-domain processing imposes some limitations as well, causing a factor of 12 or 36 × worse temporal resolution than Layer II. This causes quantization artifacts, due to transient sounds like percussive events and other high-frequency events that spread over a larger window. This results in audible smearing and pre-echo
Pre-echo
Pre-echo is a digital audio compression artifact where a sound is heard before it occurs . It is most noticeable in impulsive sounds from percussion instruments such as castanets or cymbals....
. MP3 uses pre-echo detection routines, and VBR encoding, which allows it to temporarily increase the bitrate during difficult passages, in an attempt to reduce this effect. It is also able to switch between the normal 36 sample quantization window, and instead using 3× short 12 sample windows instead, to reduce the temporal (time) length of quantization artifacts. And yet in choosing a fairly small window size to make MP3's temporal response adequate enough to avoid the most serious artifacts, MP3 becomes much less efficient in frequency domain compression of stationary, tonal components.
Being forced to use a hybrid time domain (filter bank) /frequency domain (MDCT) model to fit in with Layer II simply wastes processing time and compromises quality by introducing aliasing artifacts. MP3 has an aliasing cancellation stage specifically to mask this problem, but which instead produces frequency domain energy which must be encoded in the audio. This is pushed to the top of the frequency range, where most people have limited hearing, in hopes the distortion it causes will be less audible.
Layer II's 1024 point FFT doesn't entirely cover all samples, and would omit several entire MP3 sub-bands, where quantization factors must be determined. MP3 instead uses two passes of FFT analysis for spectral estimation, to calculate the global and individual masking thresholds. This allows it to cover all 1152 samples. Of the two, it utilizes the global masking threshold level from the more critical pass, with the most difficult audio.
In addition to Layer II's intensity encoded joint stereo, MP3 can use middle/side (mid/side, m/s, MS, matrixed) joint stereo. With mid/side stereo, certain frequency ranges of both channels are merged into a single (middle, mid, L+R) mono channel, while the sound difference between the left and right channels is stored as a separate (side, L-R) channel. Unlike intensity stereo, this process does not discard any audio information. When combined with quantization, however, it can exaggerate artifacts.
If the difference between the left and right channels is small, the side channel will be small, which will offer as much as a 50% bitrate savings, and associated quality improvement. If the difference between left and right is large, standard (discrete, left/right) stereo encoding may be preferred, as mid/side joint stereo will not provide any benefits. An MP3 encoder can switch between m/s stereo and full stereo on a frame-by-frame basis.
Unlike Layers I/II, MP3 uses variable-length Huffman coding
Huffman coding
In computer science and information theory, Huffman coding is an entropy encoding algorithm used for lossless data compression. The term refers to the use of a variable-length code table for encoding a source symbol where the variable-length code table has been derived in a particular way based on...
(after perceptual) to further reduce the bitrate, without any further quality loss.
Quality
These technical limitations inherently prevent MP3 from providing critically transparent quality at any bitrate. This makes Layer II sound quality actually superior to MP3 audio, when it is used at a high enough bitrate to avoid noticeable artifacts. The term "transparent" often gets misused, however. The quality of MP3 (and other codecs) is sometimes called "transparent," even at impossibly low bitrates, when what is really meant is "good quality on average/non-critical material," or perhaps "exhibiting only non-annoying artifacts."MP3's more fine-grained and selective quantization does prove notably superior to Layer II/MP2 at lower-bitrates, however. It is able to provide nearly equivalent audio quality to Layer II, at a 15% lower bitrate (approximately). 128 kbit/s is considered the "sweet spot
Sweet spot
Sweet spot may refer to:*Sweet spot *Sweet spot *Sweet spot...
" for MP3; meaning it provides generally acceptable quality stereo sound on most music, and there are diminishing
Diminishing returns
In economics, diminishing returns is the decrease in the marginal output of a production process as the amount of a single factor of production is increased, while the amounts of all other factors of production stay constant.The law of diminishing returns In economics, diminishing returns (also...
quality improvements from increasing the bitrate further. MP3 is also regarded as exhibiting artifacts that are less annoying than Layer II, when both are used at bitrates that are too low to possibly provide faithful reproduction.
Layer III audio files use the extension .mp3.
MPEG-2 audio extensions
The MPEG-2MPEG-2
MPEG-2 is a standard for "the generic coding of moving pictures and associated audio information". It describes a combination of lossy video compression and lossy audio data compression methods which permit storage and transmission of movies using currently available storage media and transmission...
standard includes several extensions to MPEG-1 Audio. These are known as MPEG-2 BC – backwards compatible with MPEG-1 Audio. MPEG-2 Audio is defined in ISO/IEC 13818-3
- MPEG MultichannelMPEG MultichannelMPEG Multichannel is an extension to the MPEG-1 Layer II audio compression specification, as defined in the MPEG-2 Audio standard , which allows it provide up to 5.1-channels of audio...
– Backward compatible 5.1-channel surround soundSurround soundSurround sound encompasses a range of techniques such as for enriching the sound reproduction quality of an audio source with audio channels reproduced via additional, discrete speakers. Surround sound is characterized by a listener location or sweet spot where the audio effects work best, and...
.
- Sampling rateSampling rateThe sampling rate, sample rate, or sampling frequency defines the number of samples per unit of time taken from a continuous signal to make a discrete signal. For time-domain signals, the unit for sampling rate is hertz , sometimes noted as Sa/s...
s: 16000, 22050, and 24000 Hz - BitrateBitrateIn telecommunications and computing, bit rate is the number of bits that are conveyed or processed per unit of time....
s: 8, 16, 24, 40, 48, and 144 kbit/s
These sampling rates are exactly half that of those originally defined for MPEG-1 Audio. They were introduced to maintain higher quality sound when encoding audio at lower-bitrates. The even-lower bitrates were introduced because tests showed that MPEG-1 Audio could provide higher quality than any existing (circa
Circa
Circa , usually abbreviated c. or ca. , means "approximately" in the English language, usually referring to a date...
1994) very low bitrate (i.e. speech
Speech coding
Speech coding is the application of data compression of digital audio signals containing speech. Speech coding uses speech-specific parameter estimation using audio signal processing techniques to model the speech signal, combined with generic data compression algorithms to represent the resulting...
) audio codecs.
Part 4: Conformance testing
Part 4 of the MPEG-1 standard covers conformance testing, and is defined in ISO/IEC-11172-4.Conformance: Procedures for testing conformance.
Provides two sets of guidelines and reference bitstreams for testing the conformance of MPEG-1 audio and video decoders, as well as the bitstreams produced by an encoder.
Part 5: Reference software
Part 5 of the MPEG-1 standard includes reference software, and is defined in ISO/IEC TR 11172-5.Simulation: Reference software.
C
C (programming language)
C is a general-purpose computer programming language developed between 1969 and 1973 by Dennis Ritchie at the Bell Telephone Laboratories for use with the Unix operating system....
reference code for encoding and decoding of audio and video, as well as multiplexing and demultiplexing.
This includes the ISO Dist10 audio encoder code, which LAME
LAME
LAME is a free software codec used to encode/compress audio into the lossy MP3 file format.-History:The name LAME is a recursive acronym for "LAME Ain't an MP3 Encoder". Around mid-1998, Mike Cheng created LAME 1.0 as a set of modifications against the "8Hz-MP3" encoder source code...
and TooLAME
TooLAME
TooLAME is a free software MPEG-1 Layer II audio encoder written primarily by Mike Cheng. While there are innumerable MP2 encoders, TooLAME is well-known and widely used for its particularly high audio quality. It has been unmaintained since 2003, but is directly succeeded by the TwoLAME code fork...
were originally based upon.
File extension
.mpg is one of a number of file extensions for MPEG-1 or MPEG-2MPEG-2
MPEG-2 is a standard for "the generic coding of moving pictures and associated audio information". It describes a combination of lossy video compression and lossy audio data compression methods which permit storage and transmission of movies using currently available storage media and transmission...
audio and video compression. MPEG-1 Part 2 video is rare nowadays, and this extension typically refers to an MPEG program stream (defined in MPEG-1 and MPEG-2) or MPEG transport stream (defined in MPEG-2). Other suffixes such as .m2ts also exists specifying the precise container, in this case MPEG-2 TS, but this has little relevance to MPEG-1 media.
.mp3 is the most common extension for files containing MPEG-1 Layer 3 audio. An MP3 file is typically an uncontained stream of raw audio; the conventional way to tag MP3 files is by writing data to "garbage" segments of each frame, which preserve the media information but are discarded by the player. This is similar in many respects to how raw .AAC files are tagged (but this is less supported nowadays, e.g. iTunes
ITunes
iTunes is a media player computer program, used for playing, downloading, and organizing digital music and video files on desktop computers. It can also manage contents on iPod, iPhone, iPod Touch and iPad....
).
Note that although it would apply, .mpg does not normally append raw AAC
Advanced Audio Coding
Advanced Audio Coding is a standardized, lossy compression and encoding scheme for digital audio. Designed to be the successor of the MP3 format, AAC generally achieves better sound quality than MP3 at similar bit rates....
or AAC in MPEG-2 Part 7 Containers. The .aac extension normally denotes these audio files.
See also
- MPEG The Moving Picture Experts Group, developers of the MPEG-1 standard
- MP3MP3MPEG-1 or MPEG-2 Audio Layer III, more commonly referred to as MP3, is a patented digital audio encoding format using a form of lossy data compression...
More (less technical) detail about MPEG-1 Layer III audio - MPEG MultichannelMPEG MultichannelMPEG Multichannel is an extension to the MPEG-1 Layer II audio compression specification, as defined in the MPEG-2 Audio standard , which allows it provide up to 5.1-channels of audio...
Backwards compatible 5.1 channel surround soundSurround soundSurround sound encompasses a range of techniques such as for enriching the sound reproduction quality of an audio source with audio channels reproduced via additional, discrete speakers. Surround sound is characterized by a listener location or sweet spot where the audio effects work best, and...
extension to Layer II audio - MPEG-2MPEG-2MPEG-2 is a standard for "the generic coding of moving pictures and associated audio information". It describes a combination of lossy video compression and lossy audio data compression methods which permit storage and transmission of movies using currently available storage media and transmission...
The direct successor to the MPEG-1 standard.
Implementations
- LibavcodecLibavcodeclibavcodec is a free software/open source LGPL-licensed library of codecs for encoding and decoding video and audio data. Same name but incompatible libraries are provided from both FFmpeg project and Libav project....
includes MPEG-1/2 video/audio encoders and decoders - Mjpegtools MPEG-1/2 video/audio encoders
- TooLAMETooLAMETooLAME is a free software MPEG-1 Layer II audio encoder written primarily by Mike Cheng. While there are innumerable MP2 encoders, TooLAME is well-known and widely used for its particularly high audio quality. It has been unmaintained since 2003, but is directly succeeded by the TwoLAME code fork...
A high quality MPEG-1 Layer II audio encoder. - LAMELAMELAME is a free software codec used to encode/compress audio into the lossy MP3 file format.-History:The name LAME is a recursive acronym for "LAME Ain't an MP3 Encoder". Around mid-1998, Mike Cheng created LAME 1.0 as a set of modifications against the "8Hz-MP3" encoder source code...
A high quality MP3 (Layer III) audio encoder. - MusepackMusepackMusepack or MPC is an open source lossy audio codec, specifically optimized for transparent compression of stereo audio at bitrates of 160–180 kbit/s...
A format originally based on MPEG-1 Layer II audio, but now incompatible.