
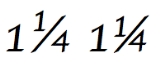
Mapping of Unicode characters
Encyclopedia
Unicode
’s Universal Character Set
has a potential capacity to support over 1 million characters. Each UCS character is mapped to a code point
which is an integer between 0 and 1,114,111 used to represent each character within the internal logic of text processing software (1,114,112 = 220 + 216 or 17 × 216, or hexadecimal
110000 code points).
As of Unicode 5.2.0, 246,943 (22.2%) of these code points are assigned, including 107,361 (9.6%) encoded characters, 137,468 (12.3%) reserved for private use, 2,048 for surrogates, and 66 designated noncharacters, leaving 867,169 (77.8%) unassigned. The number of encoded characters is made up as follows:
(See the summary table for a more detailed breakdown).
Unicode characters can be categorized in many ways. Every character is assigned a script or a symbol (though many are assigned the common or inherited scripts where they inherit the script from the adjacent character). In Unicode a script is a coherent writing system that includes letters but also may include script-specific punctuation, diacritic and other marks and numerals and symbols. A single script supports one or more languages. Symbols, including control characters, are relevant for their meaning, not their speech.
Characters are assigned in blocks of characters. A block is a single group of code points. Every character is also assigned a general category and subcategory. The general categories are: letter, mark, number, punctuation, symbol, or control (in other words a formatting or non-graphical character).
The blocks of characters are assigned according to various planes. Most characters are currently assigned to the first plane: the Basic Multilingual Plane. This is to help ease the transition for legacy software since the Basic Multilingual Plane is addressable with just two octet
bytes. The characters outside the first plane usually have very specialized or rare use.
The first 256 code points correspond with those of ISO 8859-1, the most popular 8-bit character encoding
in the Western world
. As a result, the first 128 characters are also identical to ASCII
. Though Unicode refers to these as a Latin script block, these two blocks contain many characters that are commonly useful outside of the Latin script. In general, not all characters in a given block need be of the same script, and a given script can occur in several different blocks.
Some special characters can alter the layout of text, such as the zero-width joiner and zero-width non-joiner, while others do not affect text layout at all, but instead affect the way text strings are collated, matched or otherwise processed. Other special-purpose characters, such as the mathematical invisibles, generally have no effect on text rendering, though sophisticated text layout software may choose to subtly adjust spacing around them.
Unicode does not specify the division of labor between font and text layout software (or "engine") when rendering Unicode text. Because the more complex font formats, such as OpenType
or Apple Advanced Typography
, provide for contextual substitution and positioning of glyphs, a simple text layout engine might rely entirely on the font for all decisions of glyph choice and placement. In the same situation a more complex engine may combine information from the font with its own rules to achieve its own idea of best rendering. To implement all recommendations of the Unicode specification, a text engine must be prepared to work with fonts of any level of sophistication, since contextual substitution and positioning rules do not exist in some font formats and are optional in the rest. The fraction slash is an example: complex fonts may or may not supply positioning rules in the presence of the fraction slash character to create a fraction, while fonts in simple formats cannot.
(BOM) U+FEFF hints at the encoding form and its byte order.
If the stream’s first byte is 0xFE and the second 0xFF, then the stream’s text is not likely to be encoded in UTF-8, since those bytes are meaningless in UTF-8. It is also not likely to be UTF-16 in little-endian byte order because 0xFE, 0xFF read as a 16-bit little endian word would be U+FFFE, which is meaningless. The sequence also has no meaning in any arrangement of UTF-32 encoding, so, in summary, it serves as a fairly reliable indication that the text stream is encoded as UTF-16 in big-endian byte order. Conversely, if the first two bytes are 0xFF, 0xFE, then the text stream may be assumed to be encoded as UTF-16LE because, read as a 16-bit little-endian value, the bytes yield the expected 0xFEFF byte order mark.
The UTF-8 sequence corresponding to U+FEFF is 0xEF, 0xBB, 0xBF. This sequence has no meaning in other Unicode encoding forms, so it may serve to indicate that that stream is encoded as UTF-8.
The Unicode specification does not require the use of byte order marks in text streams. It further states that they should not be used in situations where some other method of signaling the encoding form is already in use.
(U+200D) and zero-width non-joiner
(U+200C) control the joining and ligation of glyphs. The joiner does not cause characters that would not otherwise join or ligate to do so, but when paired with the non-joiner these characters can be used to control the joining and ligating properties of the surrounding two joining or ligating characters. The Combining Grapheme Joiner (U+034F) is used to distinguish two base characters as one common base or digraph, mostly for underlying text processing, collation of strings, case folding and so on.
These provide Unicode with native paragraph and line separators independent of the legacy encoded ASCII control characters such as carriage return (U+000A), linefeed (U+000D), and Next Line (U+0085). Unicode does not provide for other ASCII formatting control characters which presumably then are not part of the Unicode plain text processing model. These legacy formatting control characters include Tab (U+0009), Line Tabulation or Vertical Tab (U+000B), and Form Feed (U+000C) which is also thought of as a page break.
Aside from the original ASCII space, the other spaces are all compatibility characters. In this context this means that they effectively add no semantic content to the text, but instead provide styling control. Within Unicode, this non-semantic styling control is often referred to as rich text and is outside the thrust of Unicode’s goals. Rather than using different spaces in different contexts, this styling should instead be handled through intelligent text layout software.
Three other writing-system-specific word separators are:
Break Inhibiting
The break inhibiting characters are meant to be equivalent to a character sequence wrapped in the Word Joiner U+2060. However, the Word Joiner may be appended before or after any character that would allow a line-break to inhibit such line-breaking.
Break Enabling
Both the break inhibiting and break enabling characters participate with other punctuation and whitespace characters to enable text imaging systems to determine line breaks within the Unicode Line Breaking Algorithm.

 The fraction slash character (U+2044) has special behavior in the Unicode Standard (section 6.2, Other Punctuation):
The fraction slash character (U+2044) has special behavior in the Unicode Standard (section 6.2, Other Punctuation):
By following this Unicode recommendation, text processing systems yield sophisticated symbols from plain text alone. Here the presence of the fraction slash character instructs the layout engine to synthesize a fraction from all consecutive digits preceding and following the slash. In practice, results vary because of the complicated interplay between fonts and layout engines. Simple text layout engines tend not to synthesize fractions all, and instead draw the glyphs as a linear sequence as described in the Unicode fallback scheme.
More sophisticated layout engines face two practical choices: they can follow Unicode’s recommendation, or they can rely on the font’s own instructions for synthesizing fractions. By ignoring the font’s instructions, the layout engine can guarantee Unicode’s recommended behavior. By following the font’s instructions, the layout engine can achieve better typography
because placement and shaping of the digits will be tuned to that particular font at that particular size.
The problem with following the font’s instructions is that the simpler font formats have no way to specify fraction synthesis behavior. Meanwhile the more complex formats do not require the font to specify fraction synthesis behavior and therefore many do not. Most fonts of complex formats can instruct the layout engine to replace a plain text sequence such as "1⁄2" with the precomposed "½" glyph. But because many of them will not issue instructions to synthesize fractions, a plain text string such as "221⁄225" may well render as 22½25 (with the ½ being the substituted precomposed fraction, rather than synthesized). In the face of problems like this, those who wish to rely on the recommended Unicode behavior should choose fonts known to synthesize fractions or text layout software known to produce Unicode’s recommended behavior regardless of font.
and Hebrew
, have right-to-left writing direction. The Unicode specification assigns a directional type to each character to inform text processors how sequences of characters should be ordered on the page.
While lexical characters (that is, letters) are normally specific to a single writing script, some symbols and punctuation marks are used across many writing scripts. Unicode could have created duplicate symbols in the repertoire that differ only by directional type, but chose instead to unify them and assign them a neutral directional type. They acquire direction at render time from adjacent characters. Some of these characters also have a bidi-mirrored property indicating the glyph should be rendered in mirror-image when used in right-to-left text.
The render-time directional type of a neutral character can remain ambiguous when the mark is placed on the boundary between directional changes. To address this, Unicode includes two characters that have strong directionality, have no glyph associated with them, and are ignorable by systems that do not process bidirectional text:
Surrounding a bidirectionally neutral character by the left-to-right mark will force the character to behave as a left-to-right character while surrounding it by the right-to-left mark will force it to behave as a right-to-left character. The behavior of these characters is detailed in Unicode’s Bidirectional Algorithm.
for the Apple logo, versus the ConScript Unicode Registry
’s use of U+F8FF as in the Klingon
script.
The Basic Multilingual Plane includes a PUA in the range from U+E000 to U+F8FF (6,400 code locations). Plane Fifteen and Plane Sixteen have a PUAs that consist of all but their final two code locations, which are designated non-characters. The PUA in Plane Fifteen is the range from U+F0000 to U+FFFFD (65,534 code locations). The PUA in Plane Sixteen is the range from U+100000 to U+10FFFD (65,534 code locations).
PUAs are a concept inherited from certain Asian encoding systems. These systems had private use areas to encode what the Japanese call gaiji (rare characters not normally found in fonts) in application-specific ways.
Schemes and initiatives that use the PUA include:
in the UCS represents a code point and a particular semantic function: For graphical characters, the semantic function is often implied by its name, and the script or block it is included within. A graphical character may also have a recommended glyph that helps define the meaning of the character. Han characters, used in China, Japan, Korea, Vietnam and their respective diaspora, include many other rich properties that participate in defining the semantic role for a character.
However, the UCS and Unicode designate other code points for other purposes. Those code points may have no or few character properties associated with them.
A surrogate pair denotes the code point
where H and L are the numeric values of the high and low surrogates respectively.
Since high surrogate values in the range DB80–DBFF always produce values in the Private Use planes, the high surrogate range can be further divided into (normal) high surrogates (D800–DB7F) and "high private use surrogates" (DB80–DBFF).
each plane are included. So, noncharacters are: U+FFFE and U+FFFF on the BMP, U+1FFFE and U+1FFFF
on Plane 1, and so on, up to U+10FFFE and U+10FFFF on Plane 16, for a total of 34 code
points. In addition, there is a contiguous range of another 32 noncharacter code points in
the BMP: U+FDD0..U+FDEF. Software implementations are therefore free to use these code points for internal use. However, these noncharacters should never be included in text interchange between implementations. One particularly useful example of a noncharacter is the code point U+FFFE. This code point has the reverse binary sequence of the byte order mark (U+FEFF). If a stream of text contains this noncharacter, this is a good indication the text has been interpreted with the incorrect endianness
.
Characters include many other properties. Some properties are strings, some are booleans, some are relations to other characters. For example cased letters include properties that map those characters to their upper case, lower case and title case equivalents (title case is only used for ligatures). Some characters (canonical and compatibility decomposable characters) include mappings to canonical and compatibility equivalents. Characters have many boolean properties to indicate whether they are included as white space, or used as pattern syntax within programming languages and more. Many of these properties are exposed through regular expressions to perform complex queries on text. These properties are also used in the many Unicode text processing algorithms and also might be used by text imaging and font technologies to display text (like the bidirectional algorithm).
Unicode provides an online database to interactively query the entire Unicode character repertoire by the various properties.
Unicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
’s Universal Character Set
Universal Character Set
The Universal Character Set , defined by the International Standard ISO/IEC 10646, Information technology — Universal multiple-octet coded character set , is a standard set of characters upon which many character encodings are based...
has a potential capacity to support over 1 million characters. Each UCS character is mapped to a code point
Code point
In character encoding terminology, a code point or code position is any of the numerical values that make up the code space . For example, ASCII comprises 128 code points in the range 0hex to 7Fhex, Extended ASCII comprises 256 code points in the range 0hex to FFhex, and Unicode comprises 1,114,112...
which is an integer between 0 and 1,114,111 used to represent each character within the internal logic of text processing software (1,114,112 = 220 + 216 or 17 × 216, or hexadecimal
Hexadecimal
In mathematics and computer science, hexadecimal is a positional numeral system with a radix, or base, of 16. It uses sixteen distinct symbols, most often the symbols 0–9 to represent values zero to nine, and A, B, C, D, E, F to represent values ten to fifteen...
110000 code points).
As of Unicode 5.2.0, 246,943 (22.2%) of these code points are assigned, including 107,361 (9.6%) encoded characters, 137,468 (12.3%) reserved for private use, 2,048 for surrogates, and 66 designated noncharacters, leaving 867,169 (77.8%) unassigned. The number of encoded characters is made up as follows:
- 107,154 graphical characters (some of which are invisible, but are still counted as graphical)
- 207 special purpose characters for control and formatting.
(See the summary table for a more detailed breakdown).
Unicode characters can be categorized in many ways. Every character is assigned a script or a symbol (though many are assigned the common or inherited scripts where they inherit the script from the adjacent character). In Unicode a script is a coherent writing system that includes letters but also may include script-specific punctuation, diacritic and other marks and numerals and symbols. A single script supports one or more languages. Symbols, including control characters, are relevant for their meaning, not their speech.
Characters are assigned in blocks of characters. A block is a single group of code points. Every character is also assigned a general category and subcategory. The general categories are: letter, mark, number, punctuation, symbol, or control (in other words a formatting or non-graphical character).
The blocks of characters are assigned according to various planes. Most characters are currently assigned to the first plane: the Basic Multilingual Plane. This is to help ease the transition for legacy software since the Basic Multilingual Plane is addressable with just two octet
Octet (computing)
An octet is a unit of digital information in computing and telecommunications that consists of eight bits. The term is often used when the term byte might be ambiguous, as there is no standard for the size of the byte.-Overview:...
bytes. The characters outside the first plane usually have very specialized or rare use.
The first 256 code points correspond with those of ISO 8859-1, the most popular 8-bit character encoding
Character encoding
A character encoding system consists of a code that pairs each character from a given repertoire with something else, such as a sequence of natural numbers, octets or electrical pulses, in order to facilitate the transmission of data through telecommunication networks or storage of text in...
in the Western world
Western world
The Western world, also known as the West and the Occident , is a term referring to the countries of Western Europe , the countries of the Americas, as well all countries of Northern and Central Europe, Australia and New Zealand...
. As a result, the first 128 characters are also identical to ASCII
ASCII
The American Standard Code for Information Interchange is a character-encoding scheme based on the ordering of the English alphabet. ASCII codes represent text in computers, communications equipment, and other devices that use text...
. Though Unicode refers to these as a Latin script block, these two blocks contain many characters that are commonly useful outside of the Latin script. In general, not all characters in a given block need be of the same script, and a given script can occur in several different blocks.
Planes
All available codepoints are located on 17 Planes, each plane corresponding with the value of the hexadecimal digits (0–9, A–F) preceding the four final ones: hence U+24321 is in Plane 2, U+4321 is in Plane 0 (implicitly read U+04321), and U+10A200 would be in Plane 16 (for Hex 10=decimal 16). Within one plane, the maximum range of possible codepoints is Hex 0000–FFFF, about 65,000. Some planes only allow a limited number of this range.Special-purpose characters
The latest Unicode repertoire codifies over a hundred thousand characters. Most of those represent graphemes for processing as linear text. Some, however, either do not represent graphemes, or, as graphemes, require exceptional treatment. Unlike the ASCII control characters and other characters included for legacy round-trip capabilities, these other special-purpose characters endow plain text with important semantics.Some special characters can alter the layout of text, such as the zero-width joiner and zero-width non-joiner, while others do not affect text layout at all, but instead affect the way text strings are collated, matched or otherwise processed. Other special-purpose characters, such as the mathematical invisibles, generally have no effect on text rendering, though sophisticated text layout software may choose to subtly adjust spacing around them.
Unicode does not specify the division of labor between font and text layout software (or "engine") when rendering Unicode text. Because the more complex font formats, such as OpenType
OpenType
OpenType is a format for scalable computer fonts. It was built on its predecessor TrueType, retaining TrueType's basic structure and adding many intricate data structures for prescribing typographic behavior...
or Apple Advanced Typography
Apple Advanced Typography
Apple Advanced Typography is Apple Inc's computer software for advanced font rendering, supporting internationalization and complex features for typographers, a successor to Apple's little-used QuickDraw GX font technology of the mid-1990s...
, provide for contextual substitution and positioning of glyphs, a simple text layout engine might rely entirely on the font for all decisions of glyph choice and placement. In the same situation a more complex engine may combine information from the font with its own rules to achieve its own idea of best rendering. To implement all recommendations of the Unicode specification, a text engine must be prepared to work with fonts of any level of sophistication, since contextual substitution and positioning rules do not exist in some font formats and are optional in the rest. The fraction slash is an example: complex fonts may or may not supply positioning rules in the presence of the fraction slash character to create a fraction, while fonts in simple formats cannot.
Byte order mark
When appearing at the head of a text file or stream, the byte order markByte Order Mark
The byte order mark is a Unicode character used to signal the endianness of a text file or stream. Its code point is U+FEFF. BOM use is optional, and, if used, should appear at the start of the text stream...
(BOM) U+FEFF hints at the encoding form and its byte order.
If the stream’s first byte is 0xFE and the second 0xFF, then the stream’s text is not likely to be encoded in UTF-8, since those bytes are meaningless in UTF-8. It is also not likely to be UTF-16 in little-endian byte order because 0xFE, 0xFF read as a 16-bit little endian word would be U+FFFE, which is meaningless. The sequence also has no meaning in any arrangement of UTF-32 encoding, so, in summary, it serves as a fairly reliable indication that the text stream is encoded as UTF-16 in big-endian byte order. Conversely, if the first two bytes are 0xFF, 0xFE, then the text stream may be assumed to be encoded as UTF-16LE because, read as a 16-bit little-endian value, the bytes yield the expected 0xFEFF byte order mark.
The UTF-8 sequence corresponding to U+FEFF is 0xEF, 0xBB, 0xBF. This sequence has no meaning in other Unicode encoding forms, so it may serve to indicate that that stream is encoded as UTF-8.
The Unicode specification does not require the use of byte order marks in text streams. It further states that they should not be used in situations where some other method of signaling the encoding form is already in use.
Grapheme joiners and non-joiners
The zero-width joinerZero-width joiner
The zero-width joiner is a non-printing character used in the computerized typesetting of some complex scripts, such as the Arabic script or any of the Indic scripts. When placed between two characters that would otherwise not be connected, a ZWJ causes them to be printed in their connected...
(U+200D) and zero-width non-joiner
Zero-width non-joiner
The zero-width non-joiner is a non-printing character used in the computerization of writing systems that make use of ligatures. When placed between two characters that would otherwise be connected into a ligature, a ZWNJ causes them to be printed in their final and initial forms, respectively...
(U+200C) control the joining and ligation of glyphs. The joiner does not cause characters that would not otherwise join or ligate to do so, but when paired with the non-joiner these characters can be used to control the joining and ligating properties of the surrounding two joining or ligating characters. The Combining Grapheme Joiner (U+034F) is used to distinguish two base characters as one common base or digraph, mostly for underlying text processing, collation of strings, case folding and so on.
Word joiners and separators
The most common word separator is a space (U+0020). However, there are other word joiners and separators that also indicate a break between words and participate in line-breaking algorithms. The No-Break Space (U+00A0) also produces a baseline advance without a glyph but inhibits rather than enabling a line-break. The Zero Width Space (U+200B) allows a line-break but provides no space: in a sense joining, rather than separating, two words. Finally, the Word Joiner (U+2060) inhibits line breaks and also involves none of the white space produced by a baseline advance.| Baseline Advance | No Baseline Advance | |
| Allow Line-break (Separators) |
Space U+0020 | Zero Width Space U+200B |
| Inhibit Line-break (Joiners) |
No-Break Space U+00A0 | Word Joiner U+2060 |
Other Separators
- Line Separator (U+2028)
- Paragraph Separator (U+2029)
These provide Unicode with native paragraph and line separators independent of the legacy encoded ASCII control characters such as carriage return (U+000A), linefeed (U+000D), and Next Line (U+0085). Unicode does not provide for other ASCII formatting control characters which presumably then are not part of the Unicode plain text processing model. These legacy formatting control characters include Tab (U+0009), Line Tabulation or Vertical Tab (U+000B), and Form Feed (U+000C) which is also thought of as a page break.
Spaces
The space character (U+0020) typically input by the space bar on a keyboard serves semantically as a word separator in many languages. For legacy reasons, the UCS also includes spaces of varying sizes that are compatibility equivalents for the space character. While these spaces of varying width are important in typography, the Unicode processing model calls for such visual effects to be handled by rich text, markup and other such protocols. They are included in the Unicode repertoire primarily to handle lossless roundtrip transcoding from other character set encodings. These spaces include:- En Quad (U+2000)
- Em Quad (U+2001)
- En Space (U+2002)
- Em Space (U+2003)
- Three-Per-Em Space (U+2004)
- Four-Per-Em Space (U+2005)
- Six-Per-Em Space (U+2006)
- Figure Space (U+2007)
- Punctuation Space (U+2008)
- Thin Space (U+2009)
- Hair Space (U+200A)
- Mathematical Space (U+205F)
Aside from the original ASCII space, the other spaces are all compatibility characters. In this context this means that they effectively add no semantic content to the text, but instead provide styling control. Within Unicode, this non-semantic styling control is often referred to as rich text and is outside the thrust of Unicode’s goals. Rather than using different spaces in different contexts, this styling should instead be handled through intelligent text layout software.
Three other writing-system-specific word separators are:
- Mongolian Vowel Separator U+180E
- Ideographic Space (U+3000): behaves as an ideographic separator and generally rendered as white space of the same width as an ideograph.
- Ogham Space Mark ( U+1680): this character is sometimes displayed with a glyph and other times as only white space.
Line-break control characters
Several characters are designed to help control line-breaks either by discouraging them (no-break characters) or suggesting line breaks such as the soft hyphen (U+00AD) (sometimes called the "shy hyphen"). Such characters, though designed for styling, are probably indispensable for the intricate types of line-breaking they make possible.Break Inhibiting
- Non-breaking hyphen (U+2011)
- No-break space (U+00A0)
- Tibetan Mark Delimiter Tsheg Bstar (U+0F0C)
- Narrow no-break space (U+202F)
The break inhibiting characters are meant to be equivalent to a character sequence wrapped in the Word Joiner U+2060. However, the Word Joiner may be appended before or after any character that would allow a line-break to inhibit such line-breaking.
Break Enabling
- Soft hyphen (U+00AD)
- Tibetan Mark Intersyllabic Tsheg (U+0F0B)
- Zero-width space (U+200B)
Both the break inhibiting and break enabling characters participate with other punctuation and whitespace characters to enable text imaging systems to determine line breaks within the Unicode Line Breaking Algorithm.
Mathematical invisibles
Primarily for mathematics, the Invisible Separator (U+2063) provides a separator between characters where punctuation or space may be omitted such as in a two-dimensional index like ij. Invisible Times (U+2062) and Function Application (U+2061) are useful in mathematics text where the multiplication of terms or the application of a function is implied without any glyph indicating the operation. Unicode 5.1 introduces the Mathematical Invisible Plus character as well (U+2064).Fraction slash
The standard form of a fraction built using the fraction slash is defined as follows: any sequence of one or more decimal digits (General Category = Nd), followed by the fraction slash, followed by any sequence of one or more decimal digits. Such a fraction should be displayed as a unit, such as ¾. If the displaying software is incapable of mapping the fraction to a unit, then it can also be displayed as a simple linear sequence as a fallback (for example, 3/4).
By following this Unicode recommendation, text processing systems yield sophisticated symbols from plain text alone. Here the presence of the fraction slash character instructs the layout engine to synthesize a fraction from all consecutive digits preceding and following the slash. In practice, results vary because of the complicated interplay between fonts and layout engines. Simple text layout engines tend not to synthesize fractions all, and instead draw the glyphs as a linear sequence as described in the Unicode fallback scheme.
More sophisticated layout engines face two practical choices: they can follow Unicode’s recommendation, or they can rely on the font’s own instructions for synthesizing fractions. By ignoring the font’s instructions, the layout engine can guarantee Unicode’s recommended behavior. By following the font’s instructions, the layout engine can achieve better typography
Typography
Typography is the art and technique of arranging type in order to make language visible. The arrangement of type involves the selection of typefaces, point size, line length, leading , adjusting the spaces between groups of letters and adjusting the space between pairs of letters...
because placement and shaping of the digits will be tuned to that particular font at that particular size.
The problem with following the font’s instructions is that the simpler font formats have no way to specify fraction synthesis behavior. Meanwhile the more complex formats do not require the font to specify fraction synthesis behavior and therefore many do not. Most fonts of complex formats can instruct the layout engine to replace a plain text sequence such as "1⁄2" with the precomposed "½" glyph. But because many of them will not issue instructions to synthesize fractions, a plain text string such as "221⁄225" may well render as 22½25 (with the ½ being the substituted precomposed fraction, rather than synthesized). In the face of problems like this, those who wish to rely on the recommended Unicode behavior should choose fonts known to synthesize fractions or text layout software known to produce Unicode’s recommended behavior regardless of font.
Bidirectional Neutral Formatting
Writing direction is the direction glyphs are placed on the page in relation to forward progression of characters in the Unicode string. English and other languages of Latin script have left-to-right writing direction. Several major writing scripts, such as ArabicArabic alphabet
The Arabic alphabet or Arabic abjad is the Arabic script as it is codified for writing the Arabic language. It is written from right to left, in a cursive style, and includes 28 letters. Because letters usually stand for consonants, it is classified as an abjad.-Consonants:The Arabic alphabet has...
and Hebrew
Hebrew alphabet
The Hebrew alphabet , known variously by scholars as the Jewish script, square script, block script, or more historically, the Assyrian script, is used in the writing of the Hebrew language, as well as other Jewish languages, most notably Yiddish, Ladino, and Judeo-Arabic. There have been two...
, have right-to-left writing direction. The Unicode specification assigns a directional type to each character to inform text processors how sequences of characters should be ordered on the page.
While lexical characters (that is, letters) are normally specific to a single writing script, some symbols and punctuation marks are used across many writing scripts. Unicode could have created duplicate symbols in the repertoire that differ only by directional type, but chose instead to unify them and assign them a neutral directional type. They acquire direction at render time from adjacent characters. Some of these characters also have a bidi-mirrored property indicating the glyph should be rendered in mirror-image when used in right-to-left text.
The render-time directional type of a neutral character can remain ambiguous when the mark is placed on the boundary between directional changes. To address this, Unicode includes two characters that have strong directionality, have no glyph associated with them, and are ignorable by systems that do not process bidirectional text:
- Left-to-right mark (U+200E)
- Right-to-left mark (U+200F)
Surrounding a bidirectionally neutral character by the left-to-right mark will force the character to behave as a left-to-right character while surrounding it by the right-to-left mark will force it to behave as a right-to-left character. The behavior of these characters is detailed in Unicode’s Bidirectional Algorithm.
Bidirectional General Formatting
While Unicode is designed to handle multiple languages, multiple writing systems and even text that flows either left-to-right or right-to-left with minimal author intervention, there are special circumstances where the mix of bidirectional text can become intricate—requiring more author control. For these circumstances, Unicode includes five other characters to control the complex embedding of left-to-right text within right-to-left text and vice versa:- Left-to-right embedding (U+202A)
- Right-to-left embedding (U+202B)
- Pop directional formatting (U+202C)
- Left-to-right override (U+202D)
- Right-to-left override (U+202E)
Interlinear annotation characters
- Interlinear Annotation Anchor (U+FFF9)
- Interlinear Annotation Separator (U+FFFA)
- Interlinear Annotation Terminator (U+FFFB)
Script-specific
- Prefixed format control
- Arabic Number Sign (U+0600)
- Arabic Sign Sanah (U+0601)
- Arabic Footnote Marker (U+0602)
- Arabic Sign Safha (U+0603)
- Arabic End of Ayah (U+06DD)
- Syriac Abbreviation MarkSyriac Abbreviation MarkThe Syriac Abbreviation Mark is a Unicode Control character that forms part of the Syriac script block. In Syriac, words are sometimes written in an abbreviated form, omitting some of the last letters. In such cases, a special overline is drawn over some of the final letters of the abbreviated word...
(U+070F)
- Brahmi-derived script dead-character formation
- Devanagari Sign Virama (U+094D)
- Bengali Sign Virama (U+09CD)
- Gurmukhi Sign Virama (U+0A4D)
- Gujarati Sign Virama (U+0ACD)
- Oriya Sign Virama (U+0B4D)
- Tamil Sign Virama (U+0BCD)
- Telugu Sign Virama (U+0C4D)
- Kannada Sign Virama (U+0CCD)
- Malayalam Sign Virama (U+0D4D)
- Sinhala Sign Al-Lakuna (U+0DCA)
- Thai Character Phinthu (U+0E3A)
- Myanmar Sign Virama (U+1039)
- Tagalog Sign Virama (U+1714)
- Hanunoo Sign Pamudpod (U+1734)
- Khmer Sign Coeng (U+17D2)
- Balinese Adeg Adeg (U+1B44)
- Syloti Nagri Sign Hasanta (U+A806)
- Kharoshthi Virama (U+10A3F)
- Historical Viramas with other functions
- Tibetan Mark Halanta (U+0F84)
- Limbu Sign SA-1 (U+193B)
- Mongolian Variation Selectors
- Mongolian Free Variation Selector One (U+180B)
- Mongolian Free Variation Selector Two (U+180C)
- Mongolian Free Variation Selector Three (U+180D)
- Mongolian Vowel Separator (U+180E)
- Ogham
- Ogham Space Mark ( U+1680)
- Ideographic
- Ideographic variation indicator (U+303E)
- Ideographic Description (U+2FF0..U+2FFB)
- Musical Format Control
- Musical Symbol Begin Beam (U+1D173)
- Musical Symbol End Beam (U+1D174)
- Musical Symbol Begin Tie (U+1D175)
- Musical Symbol End Tie (U+1D176)
- Musical Symbol Begin Slur (U+1D177)
- Musical Symbol End Slur (U+1D178)
- Musical Symbol Begin Phrase (U+1D179)
- Musical Symbol End Phrase (U+1D17A)
Whitespace characters
Unicode provides a list of characters it deems whitespace characters for interoperability support. Software Implementations and other standards may use the term to denote a slightly different set of characters. For example, Java does not consider U+00A0 NO-BREAK SPACE or U+0085 NEXT LINE to be whitespace, even though Unicode does. Whitespace characters are characters typically designated for programming environments. Often they have no syntactic meaning in such programming environments and are ignored by the machine interpreters. Unicode designates the legacy control characters U+0009 through U+000D and U+0085 as whitespace characters, as well as all characters whose General Category property value is Separator. There are 26 total whitespace characters as of Unicode 6.0.0.Private use characters
The UCS includes 137,468 code points for private use in three different ranges, each called a Private Use Area (PUA). The Unicode standard recognizes code points within PUAs as legitimate Unicode character codes, but does not assign them any (abstract) character. Instead, individuals, organizations and software vendors are free to use them as they see fit. Within closed systems, characters in the PUA can operate unambiguously, allowing such systems to represent characters or glyphs not defined in Unicode. In public systems their use is more problematic, since there is no registry and no way to prevent several organizations from adopting the same code points for different purposes. One example of such a conflict is Apple’s use of U+F8FFU+F8FF
Unicode code point U+F8FF or is the last code point in the Private Use Area in BMP. Its meaning and appearance vary depending on the font in use, but its usage in several fonts makes it the most notable code point in the private use area....
for the Apple logo, versus the ConScript Unicode Registry
ConScript Unicode Registry
The ConScript Unicode Registry is a volunteer project to coordinate the assignment of code points in the Unicode Private Use Area for the encoding of artificial scripts. It was founded by and is maintained by John Cowan and Michael Everson...
’s use of U+F8FF as in the Klingon
Klingon writing systems
Klingon alphabets is fictional alphabet used in the Star Trek movies and television shows. The alien Klingons use their own alphabets to write the Klingon language....
script.
The Basic Multilingual Plane includes a PUA in the range from U+E000 to U+F8FF (6,400 code locations). Plane Fifteen and Plane Sixteen have a PUAs that consist of all but their final two code locations, which are designated non-characters. The PUA in Plane Fifteen is the range from U+F0000 to U+FFFFD (65,534 code locations). The PUA in Plane Sixteen is the range from U+100000 to U+10FFFD (65,534 code locations).
PUAs are a concept inherited from certain Asian encoding systems. These systems had private use areas to encode what the Japanese call gaiji (rare characters not normally found in fonts) in application-specific ways.
Schemes and initiatives that use the PUA include:
Standardization initiative uses
- The ConScript Unicode RegistryConScript Unicode RegistryThe ConScript Unicode Registry is a volunteer project to coordinate the assignment of code points in the Unicode Private Use Area for the encoding of artificial scripts. It was founded by and is maintained by John Cowan and Michael Everson...
(unofficial and not related to the Unicode ConsortiumUnicode ConsortiumThe Unicode Consortium is a non-profit organization that coordinates the development of the Unicode standard. Its stated goal is to eventually replace existing character encoding schemes with Unicode and its standard Unicode Transformation Format schemes, claiming that many of the existing...
) aims to coordinate the mapping of scripts not yet encoded in or rejected by Unicode in the PUAs. - EmojiEmojiis the Japanese term for the picture characters or emoticons used in Japanese electronic messages and webpages. Originally meaning pictograph, the word literally means e "picture" + moji "letter". The characters are used much like emoticons elsewhere, but a wider range is provided, and the icons...
is an encoding for picture characters or emoticons used in Japanese wireless messages and webpages. - GB/T 20524-2006 ("Tibetan Coded Character Set Extension A") is a Chinese national standardGuobiaoGuóbiāo is usually the phonetic transcription of the word "National Standards" in Chinese.It could mean any of the standards issued by the Standardization Administration of China , the Chinese National Committee of the ISO and IEC....
that uses the PUA to encode precomposed Tibetan ligatures. - The Institute of the Estonian LanguageInstitute of the Estonian LanguageThe Institute of the Estonian Language is the language regulator of the Estonian language. It was founded in 1993 as the Institute of Language and Literature was reorganized. It is based in Tallinn. Its director is currently Urmas Sutrop....
uses the PUA to encode Latin and Cyrillic precomposed characters that have no Unicode encoding. - The MARC 21 standard uses the PUA to encode East Asian characters present in MARC-8 that have no Unicode encoding.
- The Medieval Unicode Font InitiativeMedieval Unicode Font InitiativeIn digital typography, the Medieval Unicode Font Initiative is a project which aims to coordinate the encoding and display of special characters in medieval texts written in the Latin alphabet, which are not encoded as part of Unicode....
uses the PUA to encode various ligatures, precomposed characterPrecomposed characterA precomposed character is a Unicode entity that can be defined as a combination of two or more other characters. A precomposed character may typically represent a letter with a diacritical mark, such as é...
s, and symbols found in medieval texts. - The SILSIL InternationalSIL International is a U.S.-based, worldwide, Christian non-profit organization, whose main purpose is to study, develop and document languages, especially those that are lesser-known, in order to expand linguistic knowledge, promote literacy, translate the Christian Bible into local languages,...
Corporate PUA uses the PUA to encode characters used in minority languages that have not yet been accepted into Unicode. - The STIX Fonts project uses the PUA to provide a comprehensive font set of mathematical symbols and alphabets.
- The Tamil Unicode New Encoding (TUNE) is a proposed scheme for encoding TamilTamil scriptThe Tamil script is a script that is used to write the Tamil language as well as other minority languages such as Badaga, Irulas, and Paniya...
that overcomes perceived deficiencies in the current Unicode encoding.
Vendor use
- The Adobe Glyph ListAdobe Glyph ListThe Adobe Glyph List is a mapping of 4,281 glyph names to one or more Unicode characters. Its purpose is to provide an implementation guideline for consumers of fonts ; it lists a variety of standard names that are given to glyphs that correspond to certain Unicode character sequences...
uses the PUA for some of its glyphs. - Apple lists a range of 1,280 characters in its developer documentation of U+F400–U+F8FF within the PUA for Apple’s use. Of those, only 311 are used in the range U+F700–U+F8FF.
- WGL4 uses the PUA (U+F001 and U+F002) to encode two characters which are duplicates of the ligatures fi (U+FB01) fl (U+FB02).
- In old versions of its RichEdit component, Microsoft mapped U+F020–U+F0FF within the PUA to symbol fonts. For any character in this range, RichEdit would show a character from a symbol font instead of the end-user-defined character (EUDC).
- AutoCADAutoCADAutoCAD is a software application for computer-aided design and drafting in both 2D and 3D. It is developed and sold by Autodesk, Inc. First released in December 1982, AutoCAD was one of the first CAD programs to run on personal computers, notably the IBM PC...
uses U+F8FC–U+F8FE for ⌀ (diameter sign), ± (plus-minus signPlus-minus signThe plus-minus sign is a mathematical symbol commonly used either*to indicate the precision of an approximation, or*to indicate a value that can be of either sign....
) and ° (degree sign) respectively.
Special code points
At the simplest level, each characterUniversal Character Set Characters
The Unicode Consortium and the International Organisation for Standardisation collaborate on the Universal Character Set. . The UCS is an international standard to map characters used in natural language characters into numeric — machine readable — values...
in the UCS represents a code point and a particular semantic function: For graphical characters, the semantic function is often implied by its name, and the script or block it is included within. A graphical character may also have a recommended glyph that helps define the meaning of the character. Han characters, used in China, Japan, Korea, Vietnam and their respective diaspora, include many other rich properties that participate in defining the semantic role for a character.
However, the UCS and Unicode designate other code points for other purposes. Those code points may have no or few character properties associated with them.
Surrogates
The 2,048 surrogates are not characters, but are reserved for use in UTF-16 to specify code points outside the Basic Multilingual Plane. They are divided into leading or "high surrogates" (D800–DBFF) and trailing or "low surrogates" (DC00–DFFF). In UTF-16, they must always appear in pairs, as a high surrogate followed by a low surrogate, thus using 32 bits to denote one code point.A surrogate pair denotes the code point
- 1000016 + (H − D80016) × 40016 + (L − DC0016)
where H and L are the numeric values of the high and low surrogates respectively.
Since high surrogate values in the range DB80–DBFF always produce values in the Private Use planes, the high surrogate range can be further divided into (normal) high surrogates (D800–DB7F) and "high private use surrogates" (DB80–DBFF).
Noncharacters
Unicode defines sixty-six code points as non-characters (labeledeach plane are included. So, noncharacters are: U+FFFE and U+FFFF on the BMP, U+1FFFE and U+1FFFF
on Plane 1, and so on, up to U+10FFFE and U+10FFFF on Plane 16, for a total of 34 code
points. In addition, there is a contiguous range of another 32 noncharacter code points in
the BMP: U+FDD0..U+FDEF. Software implementations are therefore free to use these code points for internal use. However, these noncharacters should never be included in text interchange between implementations. One particularly useful example of a noncharacter is the code point U+FFFE. This code point has the reverse binary sequence of the byte order mark (U+FEFF). If a stream of text contains this noncharacter, this is a good indication the text has been interpreted with the incorrect endianness
Endianness
In computing, the term endian or endianness refers to the ordering of individually addressable sub-components within the representation of a larger data item as stored in external memory . Each sub-component in the representation has a unique degree of significance, like the place value of digits...
.
Character properties
Every character in Unicode is defined by a large and growing set of properties. The properties facilitate text processing including collation or sorting of text, identifying words, sentences and graphemes, rendering or imaging text and so on. Below is a list of some of the core properties. There are many others documented in the Unicode Character Database.Categories
- Letter (L)
- Uppercase (Lu)
- Lowercase (Ll)
- Titlecase (Lt) — Ligatures containing uppercase followed by lowercase letters (e.g., Dž, Lj, Nj, and Dz)
- Modifier (Lm)
- Other (Lo)
- Mark (M)
- Spacing combining (Mc)
- Enclosing (Me)
- Nonspacing (Mn)
- Other (Mo)
- Number (N)
- Decimal digit (Nd)Numerical digitA digit is a symbol used in combinations to represent numbers in positional numeral systems. The name "digit" comes from the fact that the 10 digits of the hands correspond to the 10 symbols of the common base 10 number system, i.e...
- Letter (Nl) — Numerals composed of letters or letterlike symbols (e.g., Roman numeralsRoman numeralsThe numeral system of ancient Rome, or Roman numerals, uses combinations of letters from the Latin alphabet to signify values. The numbers 1 to 10 can be expressed in Roman numerals as:...
) - Other (No) — Includes vulgar fractionsFractionIn common usage a fraction is any part of a unit.Fraction may also mean:*Fraction , one of more equal parts of something, eg...
and superscript and subscript digits.
- Decimal digit (Nd)
- Punctuation (P)
- Connector (Pc) — Includes the underscoreUnderscoreThe underscore [ _ ] is a character that originally appeared on the typewriter and was primarily used to underline words...
. - Dash (Pd)DashA dash is one of several kinds of punctuation mark. Dashes appear similar to hyphens, but differ from them primarily in length, and serve different functions. The most common versions of the dash are the en dash and the em dash .-Common dashes:...
— Also includes several hyphenHyphenThe hyphen is a punctuation mark used to join words and to separate syllables of a single word. The use of hyphens is called hyphenation. The hyphen should not be confused with dashes , which are longer and have different uses, or with the minus sign which is also longer...
characters. - Open (Ps) — Opening bracketBracketBrackets are tall punctuation marks used in matched pairs within text, to set apart or interject other text. In the United States, "bracket" usually refers specifically to the "square" or "box" type.-List of types:...
characters. - Close (Pe) — Closing bracket characters.
- Initial quote (Pi) — Opening quotation markQuotation markQuotation marks or inverted commas are punctuation marks at the beginning and end of a quotation, direct speech, literal title or name. Quotation marks can also be used to indicate a different meaning of a word or phrase than the one typically associated with it and are often used to express irony...
. Does not include the ASCII "neutral" quotation mark. - Final quote (Pf) — Closing quotation mark.
- Other (Po)
- Connector (Pc) — Includes the underscore
- Symbol (S)
- Currency (Sc)Currency signA currency sign is a graphic symbol used as a shorthand for a currency's name, especially in reference to amounts of money. They typically employ the first letter or character of the currency, sometimes with minor changes such as ligatures or overlaid vertical or horizontal bars...
- Modifier (Sk)
- Math (Sm)Operation (mathematics)The general operation as explained on this page should not be confused with the more specific operators on vector spaces. For a notion in elementary mathematics, see arithmetic operation....
- Currency (Sc)
- Separator (Z)
- Space (Zs) — Includes the ASCII space, but not TABTab keyTab key on a keyboard is used to advance the cursor to the next tab stop.- Origin :The word tab derives from the word tabulate, which means "to arrange data in a tabular, or table, form"...
, CRCarriage returnCarriage return, often shortened to return, refers to a control character or mechanism used to start a new line of text.Originally, the term "carriage return" referred to a mechanism or lever on a typewriter...
, or LFNewlineIn computing, a newline, also known as a line break or end-of-line marker, is a special character or sequence of characters signifying the end of a line of text. The name comes from the fact that the next character after the newline will appear on a new line—that is, on the next line below the...
, which are under Cc. - Line (Zl) — The single character U+2028 LINE SEPARATOR.
- Paragraph (Zp) — The single character U+2029 PARAGRAPH SEPARATOR.
- Space (Zs) — Includes the ASCII space, but not TAB
- Other (C)
- Control (Cc)Control characterIn computing and telecommunication, a control character or non-printing character is a code point in a character set, that does not in itself represent a written symbol.It is in-band signaling in the context of character encoding....
- Format (Cf) — Includes the soft hyphenSoft hyphenIn computing and typesetting, a soft hyphen is a type of hyphen used to specify a place in text where a hyphenated break is allowed without forcing a line break in an inconvenient place if the text is re-flowed....
, control characters to support bi-directional textBi-directional textBi-directional text is text containing text in both text directionalities, both right-to-left and left-to-right . It generally involves text containing different types of alphabets, but may also refer to boustrophedon, which is changing text directionality in each row.Some writing systems of the...
, and language tag characters. - Private Use (Co)
- Surrogate (Cs)
- Not assigned (Cn)
- Control (Cc)
| Property | Example | Details |
| Name | LATIN CAPITAL LETTER A | This is a permanent name assigned by the joint cooperation of Unicode and the ISO UCS |
| Code Point | U+0041 | The Unicode code point is a number also permanently assigned along with the "Name" property and included in the companion UCS. The usual custom is to represent the code point as hexadecimal number with the prefix "U+" in front. |
| Representative Glyph | The representative glyphs are provided in code charts. | |
| General Category | Uppercase_Letter | The general category is expressed as a two-letter sequence such as "Lu" for uppercase letter or "Nd", for decimal digit number. |
| Combining Class | Not_Reordered (0) | Since diacritics and other combining marks can be expressed with multiple characters in Unicode the "Combining Class" property allows characters to be differentiated by the type of combining character it represents. The combining class can be expressed as an integer between 0 and 255 or as a named value. The integer values allow the combining marks to be reordered into a canonical order to make string comparison of identical strings possible. |
| Bidirectional Category | Left_To_Right | Indicates the type of character for applying the Unicode bidirectional algorithm. |
| Bidirectional Mirrored | no | Indicates the character’s glyph must be reversed or mirrored within the bidirectional algorithm. Mirrored glyphs can be provided by font makers, extracted from other characters related through the “Bidirectional Mirroring Glyph” property or synthesized by the text rendering system. |
| Bidirectional Mirroring Glyph | N/A | This property indicates the code point of another character whose glyph can serve as the mirrored glyph for the present character when mirroring within the bidirectional algorithm. |
| Decimal Digit Value | NaN | For numerals, this property indicates the numeric value of the character. Decimal digits have all three values set to the same value, presentational rich text compatibility characters and other Arabic-Indic non-decimal digits typically have only the latter two properties set to the numeric value of the character while numerals unrelated to Arabic Indic digits such as Roman Numerals or Hanzhou/Suzhou numerals typically have only the "Numeric Value" indicated. |
| Digit Value | NaN | |
| Numeric Value | NaN | |
| Ideographic | False | Indicates the character is an ideograph Ideograph Ideograph is a term coined by rhetorical scholar and critic Michael Calvin McGee describing the use of particular words and phrases as political language in a way that captures particular ideological positions... . |
| Default Ignorable | False | Indicates the character is ignorable for implementations and that no glyph, last resort glyph, or replacement character need be displayed. |
| Deprecated | False | Unicode never removes characters from the repertoire, but on occasion Unicode has deprecated a small number of characters. |
Additional examples
| Bidirectional | Numeric Value | |||||||||
| Name | Code Point |
Repre- sentative Glyph |
General Category |
Combining Class |
Category | Mirrored | Mirroring Glyph | Decimal | Digit | Numeric |
| DIGIT FOUR | U+0034 | 4 | Decimal_Number_Digit (Nd) | Not_Reordered (0) | European_Number | no | n/a | 4 | 4 | 4 |
| DEVANAGARI DIGIT FOUR | U+096A | ४ | Decimal_Number_Digit (Nd) | Not_Reordered (0) | Left_To_Right | no | n/a | 4 | 4 | 4 |
| CIRCLED DIGIT FOUR | U+2463 | ④ | Other_Number (Nd) | Not_Reordered (0) | Other_Neutral | no | n/a | n/a | 4 | 4 |
| ROMAN NUMERAL FOUR | U+2163 | Ⅳ | Letter_Number (Nd) | Not_Reordered (0) | Left_To_Right | no | n/a | n/a | n/a | 4 |
| LEFT CURLY BRACKET | U+007B | { | Open_Punctuation (Ps) | Not_Reordered (0) | Other_Neutral (On) | yes | “}” U+007D | NaN | NaN | NaN |
| COMBINING CIRCUMFLEX ACCENT | U+0302 | ̂ | Nonspacing_Mark (Mn) | Above (230) | Nonspacing_Mark (NSM) | no | n/a | NaN | NaN | NaN |
| COMBINING GRAVE ACCENT BELOW | U+0316 | ̖ | Nonspacing_Mark (Mn) | Below (220) | Nonspacing_Mark (NSM) | no | n/a | NaN | NaN | NaN |
| ARABIC LETTER BEH | U+0628 | ب | Other_Letter (Lo) | Not_Reordered (0) | Arabic_Letter (AL) | no | n/a | n/a | n/a | n/a |
| HEBREW LETTER BET | U+05D1 | ב | Other_Letter (Lo) | Not_Reordered (0) | Right_To_Left (R) | no | n/a | n/a | n/a | n/a |
| CJK UNIFIED IDEOGRAPH-4E0F (kDefinition = parapet; invisible) | U+4E0F | 丏 | Other_Letter (Lo) | Not_Reordered (0) | Left_To_Right (L) | no | n/a | n/a | n/a | n/a |
Characters include many other properties. Some properties are strings, some are booleans, some are relations to other characters. For example cased letters include properties that map those characters to their upper case, lower case and title case equivalents (title case is only used for ligatures). Some characters (canonical and compatibility decomposable characters) include mappings to canonical and compatibility equivalents. Characters have many boolean properties to indicate whether they are included as white space, or used as pattern syntax within programming languages and more. Many of these properties are exposed through regular expressions to perform complex queries on text. These properties are also used in the many Unicode text processing algorithms and also might be used by text imaging and font technologies to display text (like the bidirectional algorithm).
Unicode provides an online database to interactively query the entire Unicode character repertoire by the various properties.
See also
- ConScript Unicode RegistryConScript Unicode RegistryThe ConScript Unicode Registry is a volunteer project to coordinate the assignment of code points in the Unicode Private Use Area for the encoding of artificial scripts. It was founded by and is maintained by John Cowan and Michael Everson...
- Universal Character SetUniversal Character SetThe Universal Character Set , defined by the International Standard ISO/IEC 10646, Information technology — Universal multiple-octet coded character set , is a standard set of characters upon which many character encodings are based...
- Mapping of Unicode graphic charactersMapping of Unicode graphic charactersBy far the most common Unicode characters are graphical characters. Graphical characters all have some visual representation or glyphs associated with them. While Unicode does not specify the concrete glyphs for these characters, it does specify recommended or prototypical glyphs...
- Unicode compatibility charactersUnicode compatibility charactersIn discussing Unicode and the UCS, many often refer to compatibility characters. Compatibility characters are graphical characters that are discouraged by the Unicode Consortium...
External links
- Unicode Consortium
- decodeunicode.org Unicode Wiki with all 98,884 graphic characters of Unicode 5.0 as gifs, full text search
- Unicode Characters by Property