

Unicode numerals
Encyclopedia
Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
and the abacus
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
standard version 3.0, these characters are called Hangzhou
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
, Korean numerals
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
, possibly from the 7th century BC
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
and acrophony
.
originating in ancient Rome
, adapted from Etruscan numerals
. The system used in classical antiquity
was slightly modified in the Middle Ages
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
or the Super Bowl
.
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 .gif", event)' onMouseout='HidePop("87346")' href="/topics/Stigma_(letter)">Stigma
: ), early 50 , 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
The characters in the range U+2160–217F are present only for compatibility
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
that contains appropriate glyphs for them.
If using blackletter
or script typefaces, Roman numerals are set in Roman type
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by


 instead of
instead of  , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.
, which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.
Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
and the abacus
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
standard version 3.0, these characters are called Hangzhou
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
, Korean numerals
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
, possibly from the 7th century BC
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
and acrophony
.
originating in ancient Rome
, adapted from Etruscan numerals
. The system used in classical antiquity
was slightly modified in the Middle Ages
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
or the Super Bowl
.
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 .gif", event)' onMouseout='HidePop("87346")' href="/topics/Stigma_(letter)">Stigma
: ), early 50 , 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
The characters in the range U+2160–217F are present only for compatibility
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
that contains appropriate glyphs for them.
If using blackletter
or script typefaces, Roman numerals are set in Roman type
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.
Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
and the abacus
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
standard version 3.0, these characters are called Hangzhou
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
, Korean numerals
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
, possibly from the 7th century BC
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
and acrophony
.
originating in ancient Rome
, adapted from Etruscan numerals
. The system used in classical antiquity
was slightly modified in the Middle Ages
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
or the Super Bowl
.
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 .gif", event)' onMouseout='HidePop("87346")' href="/topics/Stigma_(letter)">Stigma
: ), early 50 , 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
The characters in the range U+2160–217F are present only for compatibility
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
that contains appropriate glyphs for them.
If using blackletter
or script typefaces, Roman numerals are set in Roman type
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.
Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
and the abacus
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
standard version 3.0, these characters are called Hangzhou
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
, Korean numerals
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
, possibly from the 7th century BC
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
and acrophony
.
originating in ancient Rome
, adapted from Etruscan numerals
. The system used in classical antiquity
was slightly modified in the Middle Ages
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
or the Super Bowl
.
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 .gif", event)' onMouseout='HidePop("87346")' href="/topics/Stigma_(letter)">Stigma
: ), early 50 , 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
The characters in the range U+2160–217F are present only for compatibility
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
that contains appropriate glyphs for them.
If using blackletter
or script typefaces, Roman numerals are set in Roman type
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.
Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
and the abacus
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
standard version 3.0, these characters are called Hangzhou
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
, Korean numerals
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
, possibly from the 7th century BC
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
and acrophony
.
originating in ancient Rome
, adapted from Etruscan numerals
. The system used in classical antiquity
was slightly modified in the Middle Ages
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
or the Super Bowl
.
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 (, similar to Greek Stigma
: ), early 50 (, similar to down arrow ), 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
The characters in the range U+2160–217F are present only for compatibility
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
that contains appropriate glyphs for them.
If using blackletter
or script typefaces, Roman numerals are set in Roman type
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.
Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
and the abacus
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
standard version 3.0, these characters are called Hangzhou
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
, Korean numerals
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
, possibly from the 7th century BC
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
and acrophony
.
originating in ancient Rome
, adapted from Etruscan numerals
. The system used in classical antiquity
was slightly modified in the Middle Ages
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
or the Super Bowl
.
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 (, similar to Greek Stigma
: ), early 50 (, similar to down arrow ), 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
The characters in the range U+2160–217F are present only for compatibility
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
that contains appropriate glyphs for them.
If using blackletter
or script typefaces, Roman numerals are set in Roman type
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.
Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
and the abacus
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
standard version 3.0, these characters are called Hangzhou
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
, Korean numerals
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
, possibly from the 7th century BC
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
and acrophony
.
originating in ancient Rome
, adapted from Etruscan numerals
. The system used in classical antiquity
was slightly modified in the Middle Ages
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
or the Super Bowl
.
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 .gif", event)' onMouseout='HidePop("87346")' href="/topics/Stigma_(letter)">Stigma
: ), early 50 , 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
The characters in the range U+2160–217F are present only for compatibility
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
that contains appropriate glyphs for them.
If using blackletter
or script typefaces, Roman numerals are set in Roman type
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.
Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
and the abacus
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
standard version 3.0, these characters are called Hangzhou
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
, Korean numerals
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
, possibly from the 7th century BC
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
and acrophony
.
originating in ancient Rome
, adapted from Etruscan numerals
. The system used in classical antiquity
was slightly modified in the Middle Ages
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
or the Super Bowl
.
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 (, similar to Greek Stigma
: ), early 50 (, similar to down arrow ), 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
The characters in the range U+2160–217F are present only for compatibility
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
that contains appropriate glyphs for them.
If using blackletter
or script typefaces, Roman numerals are set in Roman type
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.
Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
and the abacus
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
standard version 3.0, these characters are called Hangzhou
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
, Korean numerals
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
, possibly from the 7th century BC
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
and acrophony
.
originating in ancient Rome
, adapted from Etruscan numerals
. The system used in classical antiquity
was slightly modified in the Middle Ages
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
or the Super Bowl
.
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 (, similar to Greek Stigma
: ), early 50 (, similar to down arrow ), 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
The characters in the range U+2160–217F are present only for compatibility
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
that contains appropriate glyphs for them.
If using blackletter
or script typefaces, Roman numerals are set in Roman type
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
Arabic-Indic Numerals
The Arabic-Indic numerals involve ten digits (for base ten; 0-9 ) and a decimal separator that can be combined into composite numerals representing any rational number. Unicode includes these ten digits in the Basic Latin (or ASCII derived) block. Unicode has no decimal separator for common unified use. The Arabic script includes an Arabic specific decimal separator (U+066B). Other writing systems are to use whatever punctuation produces the appropriate glyph for the locale: for example ‘Full Stop’ (U+002E period) in United States usage and Comma (U+002C) in many other locales.The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
Hexadecimal numerals
Unicode adds a ‘Hex_Digit’ property to the characters commonly used for hexadecimal digits: decimal digits 0-9, Latin capital letters A-F and Latin small letters a-f. This property is also indicated on the compatibility characters for CJK Fullwidth Forms.Fractions
The fraction slash character (U+2044) allows authors using Unicode to compose any arbitrary fraction along with the decimal digits. Unicode also includes a handful of vulgar fractions as compatibility characters, but discourages their use.Decimal fractions
Several characters in Unicode can serve as a decimal separator depending on the locale. Decimal fractions are represented in text as a sequence of decimal digit numerals with a decimal separator separating the whole-number portion from the fractional portion. For example, the decimal fraction for “¼” is expressed as zero-point-two-five (“0.25”). Unicode has no dedicated general decimal separator but unifies the decimal separator function with other punctuation characters. So the “.” used in “0.25” is the same period character used to end the sentence. However cultures vary in the glyph or grapheme used for a decimal separator. So in some locales, the comma may be used instead ”0,25”. Still other locales use a space for “0 25”. The Arabic writing system includes a dedicated character for a decimal separator that looks much like a comma ”٫” (U+066B) which when combined with the Arabic graphemes for the Arabic-Indic decimal digits to express one-quarter appears as: “٠٫٢٥”. Note that although Arabic is written from right to left, the significance of the digits is just as in English: from right to left (less significant to more significant).Characters for irrational numbers, sets and other constants
As stated above, the ten decimal digits, decimal separator and fraction slash are limited to representing rational numbers. Irrational numbers would require composition of infinite character sequences and so irrational numbers and other related constructs must be represented with other characters. In principle, Unicode does not yet encode characters to solely denote these numbers. For example, although Unicode 1.1 includes a character for “natural exponent’ ℯ (U+212F) its UCS canonical name derives from its glyph: “Script Small E”. As exceptions to this general rule, Unicode does include three characters canonically named for the number they represent: Plancks constant ℎ (U+210E), the reduced Planck constant ℏ (U+210F), and Eulers constantEuler–Mascheroni constant
The Euler–Mascheroni constant is a mathematical constant recurring in analysis and number theory, usually denoted by the lowercase Greek letter ....
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text and other compatibility numerals
The Arabic-Indic numerals also appear among the compatibility characters as rich text variant forms including bold, double-struck,, monospace, sans-serif and sans-serif bold. and fullwidth variants for legacy vertical text support.Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
CJK Suzhou (huāmǎ) numerals
The huāmǎ system is a variation of the rod numeral system. Rod numerals are closely related to the counting rodsCounting rods
Counting rods are small bars, typically 3–14 cm long, used by mathematicians for calculation in China, Japan, Korea, and Vietnam. They are placed either horizontally or vertically to represent any number and any fraction....
and the abacus
Chinese abacus
thumb|Suanpan The suanpan is an abacus of Chinese origin first described in a 190 CE book of the Eastern Han Dynasty, namely Supplementary Notes on the Art of Figures written by Xu Yue...
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
Suzhou (huāmǎ) numerals in Unicode
According to the UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
standard version 3.0, these characters are called Hangzhou
Hangzhou
Hangzhou , formerly transliterated as Hangchow, is the capital and largest city of Zhejiang Province in Eastern China. Governed as a sub-provincial city, and as of 2010, its entire administrative division or prefecture had a registered population of 8.7 million people...
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
Japanese numerals
The system of Japanese numerals is the system of number names used in the Japanese language. The Japanese numerals in writing are entirely based on the Chinese numerals and the grouping of large numbers follow the Chinese tradition of grouping by 10,000...
, Korean numerals
Korean numerals
The Korean language has two regularly used sets of numerals, a native Korean system and Sino-Korean system.-Construction:For both native and Sino- Korean numerals, the teens are represented by a combination of tens and the ones places...
Ancient Greek numerals
Unicode provides support for several variants of Greek numeralsGreek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
Ancient Greece
Ancient Greece is a civilization belonging to a period of Greek history that lasted from the Archaic period of the 8th to 6th centuries BC to the end of antiquity. Immediately following this period was the beginning of the Early Middle Ages and the Byzantine era. Included in Ancient Greece is the...
, possibly from the 7th century BC
7th century BC
The 7th century BC started the first day of 700 BC and ended the last day of 601 BC.The Assyrian Empire continued to dominate the Near East during this century, exercising formidable power over neighbors like Babylon and Egypt. In the last two decades of the century, however, the empire began to...
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
Aelius Herodianus
Aelius Herodianus or Herodian was one of the most celebrated grammarians of Greco-Roman antiquity. He is usually known as Herodian except when there is a danger of confusion with the historian also named Herodian....
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
Greek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
and acrophony
Acrophony
Acrophony is the naming of letters of an alphabetic writing system so that a letter's name begins with the letter itself. For example, Greek letter names are acrophonic: the names of the letters α, β, γ, δ, are spelled with the respective letters: ....
.
| Decimal | Symbol | Greek numeral |
|---|---|---|
| 1 | Ι | ἴος (ios) |
| 5 | Π | πέντε (pente) |
| 10 10 (number) 10 is an even natural number following 9 and preceding 11.-In mathematics:Ten is a composite number, its proper divisors being , and... |
Δ | δέκα (deka) |
| 100 100 (number) 100 is the natural number following 99 and preceding 101.-In mathematics:One hundred is the square of 10... |
Η | ἑκατόν (hekaton) |
| 1000 | Χ | χίλιοι (khilioi) |
| 10000 10000 (number) 10000 is the natural number following 9999 and preceding 10001.-Name:Many languages have a specific word for this number: In English it is myriad, in Ancient Greek , in Aramaic , in Hebrew רבבה , in Chinese , in Japanese [man], in Korean [man], and in Thai หมื่น [meun]... |
Μ | μύριοι (myrioi) |
Roman numerals
Roman numerals are a numeral systemNumeral system
A numeral system is a writing system for expressing numbers, that is a mathematical notation for representing numbers of a given set, using graphemes or symbols in a consistent manner....
originating in ancient Rome
Rome
Rome is the capital of Italy and the country's largest and most populated city and comune, with over 2.7 million residents in . The city is located in the central-western portion of the Italian Peninsula, on the Tiber River within the Lazio region of Italy.Rome's history spans two and a half...
, adapted from Etruscan numerals
Etruscan numerals
The Etruscan numerals were used by the ancient Etruscans. The system was adapted from the Greek Attic numerals and formed the inspiration for the later Roman numerals.There is very little surviving evidence of these numerals...
. The system used in classical antiquity
Classical antiquity
Classical antiquity is a broad term for a long period of cultural history centered on the Mediterranean Sea, comprising the interlocking civilizations of ancient Greece and ancient Rome, collectively known as the Greco-Roman world...
was slightly modified in the Middle Ages
Middle Ages
The Middle Ages is a periodization of European history from the 5th century to the 15th century. The Middle Ages follows the fall of the Western Roman Empire in 476 and precedes the Early Modern Era. It is the middle period of a three-period division of Western history: Classic, Medieval and Modern...
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
Olympic Games
The Olympic Games is a major international event featuring summer and winter sports, in which thousands of athletes participate in a variety of competitions. The Olympic Games have come to be regarded as the world’s foremost sports competition where more than 200 nations participate...
or the Super Bowl
Super Bowl
The Super Bowl is the championship game of the National Football League , the highest level of professional American football in the United States, culminating a season that begins in the late summer of the previous calendar year. The Super Bowl uses Roman numerals to identify each game, rather...
.
Roman Numerals in Unicode
UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
Number Forms
Number Forms are Unicode characters which have specific meaning as numbers, but are constructed from other characters. They consist primarily of vulgar fractions and roman numerals. They are placed in the Unicode codepoint range 0x2150 through 0x218F , except for three fractions in ISO-8859-1...
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 .gif", event)' onMouseout='HidePop("87346")' href="/topics/Stigma_(letter)">Stigma
Stigma (letter)
Stigma is a ligature of the Greek letters sigma and tau , which was used in writing Greek between the middle ages and the 19th century. It is also used as a numeral symbol for the number 6...
: ), early 50 , 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
| Code x= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 50 | 100 | 500 | 1,000 |
| U+216x | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ | Ⅺ | Ⅻ | Ⅼ | Ⅽ | Ⅾ | Ⅿ |
| U+217x | ⅰ | ⅱ | ⅲ | ⅳ | ⅴ | ⅵ | ⅶ | ⅷ | ⅸ | ⅹ | ⅺ | ⅻ | ⅼ | ⅽ | ⅾ | ⅿ |
| Value | 1000 | 5000 | 10,000 | – | – | 6 | 50 | 50,000 | 100,000 | |||||||
| U+218x | ↀ | ↁ | ↂ | Ↄ | ↄ | ↅ | ↆ | ↇ | ↈ | |||||||
The characters in the range U+2160–217F are present only for compatibility
Unicode compatibility characters
In discussing Unicode and the UCS, many often refer to compatibility characters. Compatibility characters are graphical characters that are discouraged by the Unicode Consortium...
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
Typeface
In typography, a typeface is the artistic representation or interpretation of characters; it is the way the type looks. Each type is designed and there are thousands of different typefaces in existence, with new ones being developed constantly....
that contains appropriate glyphs for them.
If using blackletter
Blackletter
Blackletter, also known as Gothic script, Gothic minuscule, or Textura, was a script used throughout Western Europe from approximately 1150 to well into the 17th century. It continued to be used for the German language until the 20th century. Fraktur is a notable script of this type, and sometimes...
or script typefaces, Roman numerals are set in Roman type
Roman type
In typography, roman is one of the three main kinds of historical type, alongside blackletter and italic. Roman type was modelled from a European scribal manuscript style of the 1400s, based on the pairing of inscriptional capitals used in ancient Rome with Carolingian minuscules developed in the...
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
Counting rod numerals
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Vertical |  |
|
|
 |
 |
 |
|
 |
 |
 |
| Horizontal | |
 |
|
 |
 |
 |
 |
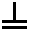 |
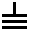 |
 |
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.Counting rod numerals in Unicode
Counting rod numerals are included in their own block in the Supplementary Multilingual Plane (SMP) from U+1D360 to U+1D37F. Eighteen characters for vertical and horizontal digits of 1-9 are included as of Unicode 5.0, though vertical and horizontal are opposite from the description above. Fourteen code points reserved for future use. Zero should be represented by U+3007Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
Arabic-Indic Numerals
The Arabic-Indic numerals involve ten digits (for base ten; 0-9 ) and a decimal separator that can be combined into composite numerals representing any rational number. Unicode includes these ten digits in the Basic Latin (or ASCII derived) block. Unicode has no decimal separator for common unified use. The Arabic script includes an Arabic specific decimal separator (U+066B). Other writing systems are to use whatever punctuation produces the appropriate glyph for the locale: for example ‘Full Stop’ (U+002E period) in United States usage and Comma (U+002C) in many other locales.The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
Hexadecimal numerals
Unicode adds a ‘Hex_Digit’ property to the characters commonly used for hexadecimal digits: decimal digits 0-9, Latin capital letters A-F and Latin small letters a-f. This property is also indicated on the compatibility characters for CJK Fullwidth Forms.Fractions
The fraction slash character (U+2044) allows authors using Unicode to compose any arbitrary fraction along with the decimal digits. Unicode also includes a handful of vulgar fractions as compatibility characters, but discourages their use.Decimal fractions
Several characters in Unicode can serve as a decimal separator depending on the locale. Decimal fractions are represented in text as a sequence of decimal digit numerals with a decimal separator separating the whole-number portion from the fractional portion. For example, the decimal fraction for “¼” is expressed as zero-point-two-five (“0.25”). Unicode has no dedicated general decimal separator but unifies the decimal separator function with other punctuation characters. So the “.” used in “0.25” is the same period character used to end the sentence. However cultures vary in the glyph or grapheme used for a decimal separator. So in some locales, the comma may be used instead ”0,25”. Still other locales use a space for “0 25”. The Arabic writing system includes a dedicated character for a decimal separator that looks much like a comma ”٫” (U+066B) which when combined with the Arabic graphemes for the Arabic-Indic decimal digits to express one-quarter appears as: “٠٫٢٥”. Note that although Arabic is written from right to left, the significance of the digits is just as in English: from right to left (less significant to more significant).Characters for irrational numbers, sets and other constants
As stated above, the ten decimal digits, decimal separator and fraction slash are limited to representing rational numbers. Irrational numbers would require composition of infinite character sequences and so irrational numbers and other related constructs must be represented with other characters. In principle, Unicode does not yet encode characters to solely denote these numbers. For example, although Unicode 1.1 includes a character for “natural exponent’ ℯ (U+212F) its UCS canonical name derives from its glyph: “Script Small E”. As exceptions to this general rule, Unicode does include three characters canonically named for the number they represent: Plancks constant ℎ (U+210E), the reduced Planck constant ℏ (U+210F), and Eulers constantEuler–Mascheroni constant
The Euler–Mascheroni constant is a mathematical constant recurring in analysis and number theory, usually denoted by the lowercase Greek letter ....
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text and other compatibility numerals
The Arabic-Indic numerals also appear among the compatibility characters as rich text variant forms including bold, double-struck,, monospace, sans-serif and sans-serif bold. and fullwidth variants for legacy vertical text support.Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
CJK Suzhou (huāmǎ) numerals
The huāmǎ system is a variation of the rod numeral system. Rod numerals are closely related to the counting rodsCounting rods
Counting rods are small bars, typically 3–14 cm long, used by mathematicians for calculation in China, Japan, Korea, and Vietnam. They are placed either horizontally or vertically to represent any number and any fraction....
and the abacus
Chinese abacus
thumb|Suanpan The suanpan is an abacus of Chinese origin first described in a 190 CE book of the Eastern Han Dynasty, namely Supplementary Notes on the Art of Figures written by Xu Yue...
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
Suzhou (huāmǎ) numerals in Unicode
According to the UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
standard version 3.0, these characters are called Hangzhou
Hangzhou
Hangzhou , formerly transliterated as Hangchow, is the capital and largest city of Zhejiang Province in Eastern China. Governed as a sub-provincial city, and as of 2010, its entire administrative division or prefecture had a registered population of 8.7 million people...
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
Japanese numerals
The system of Japanese numerals is the system of number names used in the Japanese language. The Japanese numerals in writing are entirely based on the Chinese numerals and the grouping of large numbers follow the Chinese tradition of grouping by 10,000...
, Korean numerals
Korean numerals
The Korean language has two regularly used sets of numerals, a native Korean system and Sino-Korean system.-Construction:For both native and Sino- Korean numerals, the teens are represented by a combination of tens and the ones places...
Ancient Greek numerals
Unicode provides support for several variants of Greek numeralsGreek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
Ancient Greece
Ancient Greece is a civilization belonging to a period of Greek history that lasted from the Archaic period of the 8th to 6th centuries BC to the end of antiquity. Immediately following this period was the beginning of the Early Middle Ages and the Byzantine era. Included in Ancient Greece is the...
, possibly from the 7th century BC
7th century BC
The 7th century BC started the first day of 700 BC and ended the last day of 601 BC.The Assyrian Empire continued to dominate the Near East during this century, exercising formidable power over neighbors like Babylon and Egypt. In the last two decades of the century, however, the empire began to...
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
Aelius Herodianus
Aelius Herodianus or Herodian was one of the most celebrated grammarians of Greco-Roman antiquity. He is usually known as Herodian except when there is a danger of confusion with the historian also named Herodian....
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
Greek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
and acrophony
Acrophony
Acrophony is the naming of letters of an alphabetic writing system so that a letter's name begins with the letter itself. For example, Greek letter names are acrophonic: the names of the letters α, β, γ, δ, are spelled with the respective letters: ....
.
| Decimal | Symbol | Greek numeral |
|---|---|---|
| 1 | Ι | ἴος (ios) |
| 5 | Π | πέντε (pente) |
| 10 10 (number) 10 is an even natural number following 9 and preceding 11.-In mathematics:Ten is a composite number, its proper divisors being , and... |
Δ | δέκα (deka) |
| 100 100 (number) 100 is the natural number following 99 and preceding 101.-In mathematics:One hundred is the square of 10... |
Η | ἑκατόν (hekaton) |
| 1000 | Χ | χίλιοι (khilioi) |
| 10000 10000 (number) 10000 is the natural number following 9999 and preceding 10001.-Name:Many languages have a specific word for this number: In English it is myriad, in Ancient Greek , in Aramaic , in Hebrew רבבה , in Chinese , in Japanese [man], in Korean [man], and in Thai หมื่น [meun]... |
Μ | μύριοι (myrioi) |
Roman numerals
Roman numerals are a numeral systemNumeral system
A numeral system is a writing system for expressing numbers, that is a mathematical notation for representing numbers of a given set, using graphemes or symbols in a consistent manner....
originating in ancient Rome
Rome
Rome is the capital of Italy and the country's largest and most populated city and comune, with over 2.7 million residents in . The city is located in the central-western portion of the Italian Peninsula, on the Tiber River within the Lazio region of Italy.Rome's history spans two and a half...
, adapted from Etruscan numerals
Etruscan numerals
The Etruscan numerals were used by the ancient Etruscans. The system was adapted from the Greek Attic numerals and formed the inspiration for the later Roman numerals.There is very little surviving evidence of these numerals...
. The system used in classical antiquity
Classical antiquity
Classical antiquity is a broad term for a long period of cultural history centered on the Mediterranean Sea, comprising the interlocking civilizations of ancient Greece and ancient Rome, collectively known as the Greco-Roman world...
was slightly modified in the Middle Ages
Middle Ages
The Middle Ages is a periodization of European history from the 5th century to the 15th century. The Middle Ages follows the fall of the Western Roman Empire in 476 and precedes the Early Modern Era. It is the middle period of a three-period division of Western history: Classic, Medieval and Modern...
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
Olympic Games
The Olympic Games is a major international event featuring summer and winter sports, in which thousands of athletes participate in a variety of competitions. The Olympic Games have come to be regarded as the world’s foremost sports competition where more than 200 nations participate...
or the Super Bowl
Super Bowl
The Super Bowl is the championship game of the National Football League , the highest level of professional American football in the United States, culminating a season that begins in the late summer of the previous calendar year. The Super Bowl uses Roman numerals to identify each game, rather...
.
Roman Numerals in Unicode
UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
Number Forms
Number Forms are Unicode characters which have specific meaning as numbers, but are constructed from other characters. They consist primarily of vulgar fractions and roman numerals. They are placed in the Unicode codepoint range 0x2150 through 0x218F , except for three fractions in ISO-8859-1...
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 .gif", event)' onMouseout='HidePop("87346")' href="/topics/Stigma_(letter)">Stigma
Stigma (letter)
Stigma is a ligature of the Greek letters sigma and tau , which was used in writing Greek between the middle ages and the 19th century. It is also used as a numeral symbol for the number 6...
: ), early 50 , 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
| Code x= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 50 | 100 | 500 | 1,000 |
| U+216x | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ | Ⅺ | Ⅻ | Ⅼ | Ⅽ | Ⅾ | Ⅿ |
| U+217x | ⅰ | ⅱ | ⅲ | ⅳ | ⅴ | ⅵ | ⅶ | ⅷ | ⅸ | ⅹ | ⅺ | ⅻ | ⅼ | ⅽ | ⅾ | ⅿ |
| Value | 1000 | 5000 | 10,000 | – | – | 6 | 50 | 50,000 | 100,000 | |||||||
| U+218x | ↀ | ↁ | ↂ | Ↄ | ↄ | ↅ | ↆ | ↇ | ↈ | |||||||
The characters in the range U+2160–217F are present only for compatibility
Unicode compatibility characters
In discussing Unicode and the UCS, many often refer to compatibility characters. Compatibility characters are graphical characters that are discouraged by the Unicode Consortium...
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
Typeface
In typography, a typeface is the artistic representation or interpretation of characters; it is the way the type looks. Each type is designed and there are thousands of different typefaces in existence, with new ones being developed constantly....
that contains appropriate glyphs for them.
If using blackletter
Blackletter
Blackletter, also known as Gothic script, Gothic minuscule, or Textura, was a script used throughout Western Europe from approximately 1150 to well into the 17th century. It continued to be used for the German language until the 20th century. Fraktur is a notable script of this type, and sometimes...
or script typefaces, Roman numerals are set in Roman type
Roman type
In typography, roman is one of the three main kinds of historical type, alongside blackletter and italic. Roman type was modelled from a European scribal manuscript style of the 1400s, based on the pairing of inscriptional capitals used in ancient Rome with Carolingian minuscules developed in the...
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
Counting rod numerals
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Vertical | |
|
|
|
|
|
|
|
|
|
| Horizontal | |
|
|
|
|
|
|
|
|
|
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.Counting rod numerals in Unicode
Counting rod numerals are included in their own block in the Supplementary Multilingual Plane (SMP) from U+1D360 to U+1D37F. Eighteen characters for vertical and horizontal digits of 1-9 are included as of Unicode 5.0, though vertical and horizontal are opposite from the description above. Fourteen code points reserved for future use. Zero should be represented by U+3007Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
Arabic-Indic Numerals
The Arabic-Indic numerals involve ten digits (for base ten; 0-9 ) and a decimal separator that can be combined into composite numerals representing any rational number. Unicode includes these ten digits in the Basic Latin (or ASCII derived) block. Unicode has no decimal separator for common unified use. The Arabic script includes an Arabic specific decimal separator (U+066B). Other writing systems are to use whatever punctuation produces the appropriate glyph for the locale: for example ‘Full Stop’ (U+002E period) in United States usage and Comma (U+002C) in many other locales.The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
Hexadecimal numerals
Unicode adds a ‘Hex_Digit’ property to the characters commonly used for hexadecimal digits: decimal digits 0-9, Latin capital letters A-F and Latin small letters a-f. This property is also indicated on the compatibility characters for CJK Fullwidth Forms.Fractions
The fraction slash character (U+2044) allows authors using Unicode to compose any arbitrary fraction along with the decimal digits. Unicode also includes a handful of vulgar fractions as compatibility characters, but discourages their use.Decimal fractions
Several characters in Unicode can serve as a decimal separator depending on the locale. Decimal fractions are represented in text as a sequence of decimal digit numerals with a decimal separator separating the whole-number portion from the fractional portion. For example, the decimal fraction for “¼” is expressed as zero-point-two-five (“0.25”). Unicode has no dedicated general decimal separator but unifies the decimal separator function with other punctuation characters. So the “.” used in “0.25” is the same period character used to end the sentence. However cultures vary in the glyph or grapheme used for a decimal separator. So in some locales, the comma may be used instead ”0,25”. Still other locales use a space for “0 25”. The Arabic writing system includes a dedicated character for a decimal separator that looks much like a comma ”٫” (U+066B) which when combined with the Arabic graphemes for the Arabic-Indic decimal digits to express one-quarter appears as: “٠٫٢٥”. Note that although Arabic is written from right to left, the significance of the digits is just as in English: from right to left (less significant to more significant).Characters for irrational numbers, sets and other constants
As stated above, the ten decimal digits, decimal separator and fraction slash are limited to representing rational numbers. Irrational numbers would require composition of infinite character sequences and so irrational numbers and other related constructs must be represented with other characters. In principle, Unicode does not yet encode characters to solely denote these numbers. For example, although Unicode 1.1 includes a character for “natural exponent’ ℯ (U+212F) its UCS canonical name derives from its glyph: “Script Small E”. As exceptions to this general rule, Unicode does include three characters canonically named for the number they represent: Plancks constant ℎ (U+210E), the reduced Planck constant ℏ (U+210F), and Eulers constantEuler–Mascheroni constant
The Euler–Mascheroni constant is a mathematical constant recurring in analysis and number theory, usually denoted by the lowercase Greek letter ....
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text and other compatibility numerals
The Arabic-Indic numerals also appear among the compatibility characters as rich text variant forms including bold, double-struck,, monospace, sans-serif and sans-serif bold. and fullwidth variants for legacy vertical text support.Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
CJK Suzhou (huāmǎ) numerals
The huāmǎ system is a variation of the rod numeral system. Rod numerals are closely related to the counting rodsCounting rods
Counting rods are small bars, typically 3–14 cm long, used by mathematicians for calculation in China, Japan, Korea, and Vietnam. They are placed either horizontally or vertically to represent any number and any fraction....
and the abacus
Chinese abacus
thumb|Suanpan The suanpan is an abacus of Chinese origin first described in a 190 CE book of the Eastern Han Dynasty, namely Supplementary Notes on the Art of Figures written by Xu Yue...
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
Suzhou (huāmǎ) numerals in Unicode
According to the UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
standard version 3.0, these characters are called Hangzhou
Hangzhou
Hangzhou , formerly transliterated as Hangchow, is the capital and largest city of Zhejiang Province in Eastern China. Governed as a sub-provincial city, and as of 2010, its entire administrative division or prefecture had a registered population of 8.7 million people...
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
Japanese numerals
The system of Japanese numerals is the system of number names used in the Japanese language. The Japanese numerals in writing are entirely based on the Chinese numerals and the grouping of large numbers follow the Chinese tradition of grouping by 10,000...
, Korean numerals
Korean numerals
The Korean language has two regularly used sets of numerals, a native Korean system and Sino-Korean system.-Construction:For both native and Sino- Korean numerals, the teens are represented by a combination of tens and the ones places...
Ancient Greek numerals
Unicode provides support for several variants of Greek numeralsGreek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
Ancient Greece
Ancient Greece is a civilization belonging to a period of Greek history that lasted from the Archaic period of the 8th to 6th centuries BC to the end of antiquity. Immediately following this period was the beginning of the Early Middle Ages and the Byzantine era. Included in Ancient Greece is the...
, possibly from the 7th century BC
7th century BC
The 7th century BC started the first day of 700 BC and ended the last day of 601 BC.The Assyrian Empire continued to dominate the Near East during this century, exercising formidable power over neighbors like Babylon and Egypt. In the last two decades of the century, however, the empire began to...
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
Aelius Herodianus
Aelius Herodianus or Herodian was one of the most celebrated grammarians of Greco-Roman antiquity. He is usually known as Herodian except when there is a danger of confusion with the historian also named Herodian....
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
Greek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
and acrophony
Acrophony
Acrophony is the naming of letters of an alphabetic writing system so that a letter's name begins with the letter itself. For example, Greek letter names are acrophonic: the names of the letters α, β, γ, δ, are spelled with the respective letters: ....
.
| Decimal | Symbol | Greek numeral |
|---|---|---|
| 1 | Ι | ἴος (ios) |
| 5 | Π | πέντε (pente) |
| 10 10 (number) 10 is an even natural number following 9 and preceding 11.-In mathematics:Ten is a composite number, its proper divisors being , and... |
Δ | δέκα (deka) |
| 100 100 (number) 100 is the natural number following 99 and preceding 101.-In mathematics:One hundred is the square of 10... |
Η | ἑκατόν (hekaton) |
| 1000 | Χ | χίλιοι (khilioi) |
| 10000 10000 (number) 10000 is the natural number following 9999 and preceding 10001.-Name:Many languages have a specific word for this number: In English it is myriad, in Ancient Greek , in Aramaic , in Hebrew רבבה , in Chinese , in Japanese [man], in Korean [man], and in Thai หมื่น [meun]... |
Μ | μύριοι (myrioi) |
Roman numerals
Roman numerals are a numeral systemNumeral system
A numeral system is a writing system for expressing numbers, that is a mathematical notation for representing numbers of a given set, using graphemes or symbols in a consistent manner....
originating in ancient Rome
Rome
Rome is the capital of Italy and the country's largest and most populated city and comune, with over 2.7 million residents in . The city is located in the central-western portion of the Italian Peninsula, on the Tiber River within the Lazio region of Italy.Rome's history spans two and a half...
, adapted from Etruscan numerals
Etruscan numerals
The Etruscan numerals were used by the ancient Etruscans. The system was adapted from the Greek Attic numerals and formed the inspiration for the later Roman numerals.There is very little surviving evidence of these numerals...
. The system used in classical antiquity
Classical antiquity
Classical antiquity is a broad term for a long period of cultural history centered on the Mediterranean Sea, comprising the interlocking civilizations of ancient Greece and ancient Rome, collectively known as the Greco-Roman world...
was slightly modified in the Middle Ages
Middle Ages
The Middle Ages is a periodization of European history from the 5th century to the 15th century. The Middle Ages follows the fall of the Western Roman Empire in 476 and precedes the Early Modern Era. It is the middle period of a three-period division of Western history: Classic, Medieval and Modern...
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
Olympic Games
The Olympic Games is a major international event featuring summer and winter sports, in which thousands of athletes participate in a variety of competitions. The Olympic Games have come to be regarded as the world’s foremost sports competition where more than 200 nations participate...
or the Super Bowl
Super Bowl
The Super Bowl is the championship game of the National Football League , the highest level of professional American football in the United States, culminating a season that begins in the late summer of the previous calendar year. The Super Bowl uses Roman numerals to identify each game, rather...
.
Roman Numerals in Unicode
UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
Number Forms
Number Forms are Unicode characters which have specific meaning as numbers, but are constructed from other characters. They consist primarily of vulgar fractions and roman numerals. They are placed in the Unicode codepoint range 0x2150 through 0x218F , except for three fractions in ISO-8859-1...
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 .gif", event)' onMouseout='HidePop("87346")' href="/topics/Stigma_(letter)">Stigma
Stigma (letter)
Stigma is a ligature of the Greek letters sigma and tau , which was used in writing Greek between the middle ages and the 19th century. It is also used as a numeral symbol for the number 6...
: ), early 50 , 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
| Code x= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 50 | 100 | 500 | 1,000 |
| U+216x | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ | Ⅺ | Ⅻ | Ⅼ | Ⅽ | Ⅾ | Ⅿ |
| U+217x | ⅰ | ⅱ | ⅲ | ⅳ | ⅴ | ⅵ | ⅶ | ⅷ | ⅸ | ⅹ | ⅺ | ⅻ | ⅼ | ⅽ | ⅾ | ⅿ |
| Value | 1000 | 5000 | 10,000 | – | – | 6 | 50 | 50,000 | 100,000 | |||||||
| U+218x | ↀ | ↁ | ↂ | Ↄ | ↄ | ↅ | ↆ | ↇ | ↈ | |||||||
The characters in the range U+2160–217F are present only for compatibility
Unicode compatibility characters
In discussing Unicode and the UCS, many often refer to compatibility characters. Compatibility characters are graphical characters that are discouraged by the Unicode Consortium...
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
Typeface
In typography, a typeface is the artistic representation or interpretation of characters; it is the way the type looks. Each type is designed and there are thousands of different typefaces in existence, with new ones being developed constantly....
that contains appropriate glyphs for them.
If using blackletter
Blackletter
Blackletter, also known as Gothic script, Gothic minuscule, or Textura, was a script used throughout Western Europe from approximately 1150 to well into the 17th century. It continued to be used for the German language until the 20th century. Fraktur is a notable script of this type, and sometimes...
or script typefaces, Roman numerals are set in Roman type
Roman type
In typography, roman is one of the three main kinds of historical type, alongside blackletter and italic. Roman type was modelled from a European scribal manuscript style of the 1400s, based on the pairing of inscriptional capitals used in ancient Rome with Carolingian minuscules developed in the...
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
Counting rod numerals
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Vertical | |
|
|
|
|
|
|
|
|
|
| Horizontal | |
|
|
|
|
|
|
|
|
|
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.Counting rod numerals in Unicode
Counting rod numerals are included in their own block in the Supplementary Multilingual Plane (SMP) from U+1D360 to U+1D37F. Eighteen characters for vertical and horizontal digits of 1-9 are included as of Unicode 5.0, though vertical and horizontal are opposite from the description above. Fourteen code points reserved for future use. Zero should be represented by U+3007Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
Arabic-Indic Numerals
The Arabic-Indic numerals involve ten digits (for base ten; 0-9 ) and a decimal separator that can be combined into composite numerals representing any rational number. Unicode includes these ten digits in the Basic Latin (or ASCII derived) block. Unicode has no decimal separator for common unified use. The Arabic script includes an Arabic specific decimal separator (U+066B). Other writing systems are to use whatever punctuation produces the appropriate glyph for the locale: for example ‘Full Stop’ (U+002E period) in United States usage and Comma (U+002C) in many other locales.The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
Hexadecimal numerals
Unicode adds a ‘Hex_Digit’ property to the characters commonly used for hexadecimal digits: decimal digits 0-9, Latin capital letters A-F and Latin small letters a-f. This property is also indicated on the compatibility characters for CJK Fullwidth Forms.Fractions
The fraction slash character (U+2044) allows authors using Unicode to compose any arbitrary fraction along with the decimal digits. Unicode also includes a handful of vulgar fractions as compatibility characters, but discourages their use.Decimal fractions
Several characters in Unicode can serve as a decimal separator depending on the locale. Decimal fractions are represented in text as a sequence of decimal digit numerals with a decimal separator separating the whole-number portion from the fractional portion. For example, the decimal fraction for “¼” is expressed as zero-point-two-five (“0.25”). Unicode has no dedicated general decimal separator but unifies the decimal separator function with other punctuation characters. So the “.” used in “0.25” is the same period character used to end the sentence. However cultures vary in the glyph or grapheme used for a decimal separator. So in some locales, the comma may be used instead ”0,25”. Still other locales use a space for “0 25”. The Arabic writing system includes a dedicated character for a decimal separator that looks much like a comma ”٫” (U+066B) which when combined with the Arabic graphemes for the Arabic-Indic decimal digits to express one-quarter appears as: “٠٫٢٥”. Note that although Arabic is written from right to left, the significance of the digits is just as in English: from right to left (less significant to more significant).Characters for irrational numbers, sets and other constants
As stated above, the ten decimal digits, decimal separator and fraction slash are limited to representing rational numbers. Irrational numbers would require composition of infinite character sequences and so irrational numbers and other related constructs must be represented with other characters. In principle, Unicode does not yet encode characters to solely denote these numbers. For example, although Unicode 1.1 includes a character for “natural exponent’ ℯ (U+212F) its UCS canonical name derives from its glyph: “Script Small E”. As exceptions to this general rule, Unicode does include three characters canonically named for the number they represent: Plancks constant ℎ (U+210E), the reduced Planck constant ℏ (U+210F), and Eulers constantEuler–Mascheroni constant
The Euler–Mascheroni constant is a mathematical constant recurring in analysis and number theory, usually denoted by the lowercase Greek letter ....
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text and other compatibility numerals
The Arabic-Indic numerals also appear among the compatibility characters as rich text variant forms including bold, double-struck,, monospace, sans-serif and sans-serif bold. and fullwidth variants for legacy vertical text support.Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
CJK Suzhou (huāmǎ) numerals
The huāmǎ system is a variation of the rod numeral system. Rod numerals are closely related to the counting rodsCounting rods
Counting rods are small bars, typically 3–14 cm long, used by mathematicians for calculation in China, Japan, Korea, and Vietnam. They are placed either horizontally or vertically to represent any number and any fraction....
and the abacus
Chinese abacus
thumb|Suanpan The suanpan is an abacus of Chinese origin first described in a 190 CE book of the Eastern Han Dynasty, namely Supplementary Notes on the Art of Figures written by Xu Yue...
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
Suzhou (huāmǎ) numerals in Unicode
According to the UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
standard version 3.0, these characters are called Hangzhou
Hangzhou
Hangzhou , formerly transliterated as Hangchow, is the capital and largest city of Zhejiang Province in Eastern China. Governed as a sub-provincial city, and as of 2010, its entire administrative division or prefecture had a registered population of 8.7 million people...
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
Japanese numerals
The system of Japanese numerals is the system of number names used in the Japanese language. The Japanese numerals in writing are entirely based on the Chinese numerals and the grouping of large numbers follow the Chinese tradition of grouping by 10,000...
, Korean numerals
Korean numerals
The Korean language has two regularly used sets of numerals, a native Korean system and Sino-Korean system.-Construction:For both native and Sino- Korean numerals, the teens are represented by a combination of tens and the ones places...
Ancient Greek numerals
Unicode provides support for several variants of Greek numeralsGreek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
Ancient Greece
Ancient Greece is a civilization belonging to a period of Greek history that lasted from the Archaic period of the 8th to 6th centuries BC to the end of antiquity. Immediately following this period was the beginning of the Early Middle Ages and the Byzantine era. Included in Ancient Greece is the...
, possibly from the 7th century BC
7th century BC
The 7th century BC started the first day of 700 BC and ended the last day of 601 BC.The Assyrian Empire continued to dominate the Near East during this century, exercising formidable power over neighbors like Babylon and Egypt. In the last two decades of the century, however, the empire began to...
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
Aelius Herodianus
Aelius Herodianus or Herodian was one of the most celebrated grammarians of Greco-Roman antiquity. He is usually known as Herodian except when there is a danger of confusion with the historian also named Herodian....
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
Greek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
and acrophony
Acrophony
Acrophony is the naming of letters of an alphabetic writing system so that a letter's name begins with the letter itself. For example, Greek letter names are acrophonic: the names of the letters α, β, γ, δ, are spelled with the respective letters: ....
.
| Decimal | Symbol | Greek numeral |
|---|---|---|
| 1 | Ι | ἴος (ios) |
| 5 | Π | πέντε (pente) |
| 10 10 (number) 10 is an even natural number following 9 and preceding 11.-In mathematics:Ten is a composite number, its proper divisors being , and... |
Δ | δέκα (deka) |
| 100 100 (number) 100 is the natural number following 99 and preceding 101.-In mathematics:One hundred is the square of 10... |
Η | ἑκατόν (hekaton) |
| 1000 | Χ | χίλιοι (khilioi) |
| 10000 10000 (number) 10000 is the natural number following 9999 and preceding 10001.-Name:Many languages have a specific word for this number: In English it is myriad, in Ancient Greek , in Aramaic , in Hebrew רבבה , in Chinese , in Japanese [man], in Korean [man], and in Thai หมื่น [meun]... |
Μ | μύριοι (myrioi) |
Roman numerals
Roman numerals are a numeral systemNumeral system
A numeral system is a writing system for expressing numbers, that is a mathematical notation for representing numbers of a given set, using graphemes or symbols in a consistent manner....
originating in ancient Rome
Rome
Rome is the capital of Italy and the country's largest and most populated city and comune, with over 2.7 million residents in . The city is located in the central-western portion of the Italian Peninsula, on the Tiber River within the Lazio region of Italy.Rome's history spans two and a half...
, adapted from Etruscan numerals
Etruscan numerals
The Etruscan numerals were used by the ancient Etruscans. The system was adapted from the Greek Attic numerals and formed the inspiration for the later Roman numerals.There is very little surviving evidence of these numerals...
. The system used in classical antiquity
Classical antiquity
Classical antiquity is a broad term for a long period of cultural history centered on the Mediterranean Sea, comprising the interlocking civilizations of ancient Greece and ancient Rome, collectively known as the Greco-Roman world...
was slightly modified in the Middle Ages
Middle Ages
The Middle Ages is a periodization of European history from the 5th century to the 15th century. The Middle Ages follows the fall of the Western Roman Empire in 476 and precedes the Early Modern Era. It is the middle period of a three-period division of Western history: Classic, Medieval and Modern...
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
Olympic Games
The Olympic Games is a major international event featuring summer and winter sports, in which thousands of athletes participate in a variety of competitions. The Olympic Games have come to be regarded as the world’s foremost sports competition where more than 200 nations participate...
or the Super Bowl
Super Bowl
The Super Bowl is the championship game of the National Football League , the highest level of professional American football in the United States, culminating a season that begins in the late summer of the previous calendar year. The Super Bowl uses Roman numerals to identify each game, rather...
.
Roman Numerals in Unicode
UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
Number Forms
Number Forms are Unicode characters which have specific meaning as numbers, but are constructed from other characters. They consist primarily of vulgar fractions and roman numerals. They are placed in the Unicode codepoint range 0x2150 through 0x218F , except for three fractions in ISO-8859-1...
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 .gif", event)' onMouseout='HidePop("87346")' href="/topics/Stigma_(letter)">Stigma
Stigma (letter)
Stigma is a ligature of the Greek letters sigma and tau , which was used in writing Greek between the middle ages and the 19th century. It is also used as a numeral symbol for the number 6...
: ), early 50 , 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
| Code x= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 50 | 100 | 500 | 1,000 |
| U+216x | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ | Ⅺ | Ⅻ | Ⅼ | Ⅽ | Ⅾ | Ⅿ |
| U+217x | ⅰ | ⅱ | ⅲ | ⅳ | ⅴ | ⅵ | ⅶ | ⅷ | ⅸ | ⅹ | ⅺ | ⅻ | ⅼ | ⅽ | ⅾ | ⅿ |
| Value | 1000 | 5000 | 10,000 | – | – | 6 | 50 | 50,000 | 100,000 | |||||||
| U+218x | ↀ | ↁ | ↂ | Ↄ | ↄ | ↅ | ↆ | ↇ | ↈ | |||||||
The characters in the range U+2160–217F are present only for compatibility
Unicode compatibility characters
In discussing Unicode and the UCS, many often refer to compatibility characters. Compatibility characters are graphical characters that are discouraged by the Unicode Consortium...
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
Typeface
In typography, a typeface is the artistic representation or interpretation of characters; it is the way the type looks. Each type is designed and there are thousands of different typefaces in existence, with new ones being developed constantly....
that contains appropriate glyphs for them.
If using blackletter
Blackletter
Blackletter, also known as Gothic script, Gothic minuscule, or Textura, was a script used throughout Western Europe from approximately 1150 to well into the 17th century. It continued to be used for the German language until the 20th century. Fraktur is a notable script of this type, and sometimes...
or script typefaces, Roman numerals are set in Roman type
Roman type
In typography, roman is one of the three main kinds of historical type, alongside blackletter and italic. Roman type was modelled from a European scribal manuscript style of the 1400s, based on the pairing of inscriptional capitals used in ancient Rome with Carolingian minuscules developed in the...
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
Counting rod numerals
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Vertical | |
|
|
|
|
|
|
|
|
|
| Horizontal | |
|
|
|
|
|
|
|
|
|
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.Counting rod numerals in Unicode
Counting rod numerals are included in their own block in the Supplementary Multilingual Plane (SMP) from U+1D360 to U+1D37F. Eighteen characters for vertical and horizontal digits of 1-9 are included as of Unicode 5.0, though vertical and horizontal are opposite from the description above. Fourteen code points reserved for future use. Zero should be represented by U+3007Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
Arabic-Indic Numerals
The Arabic-Indic numerals involve ten digits (for base ten; 0-9 ) and a decimal separator that can be combined into composite numerals representing any rational number. Unicode includes these ten digits in the Basic Latin (or ASCII derived) block. Unicode has no decimal separator for common unified use. The Arabic script includes an Arabic specific decimal separator (U+066B). Other writing systems are to use whatever punctuation produces the appropriate glyph for the locale: for example ‘Full Stop’ (U+002E period) in United States usage and Comma (U+002C) in many other locales.The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
Hexadecimal numerals
Unicode adds a ‘Hex_Digit’ property to the characters commonly used for hexadecimal digits: decimal digits 0-9, Latin capital letters A-F and Latin small letters a-f. This property is also indicated on the compatibility characters for CJK Fullwidth Forms.Fractions
The fraction slash character (U+2044) allows authors using Unicode to compose any arbitrary fraction along with the decimal digits. Unicode also includes a handful of vulgar fractions as compatibility characters, but discourages their use.Decimal fractions
Several characters in Unicode can serve as a decimal separator depending on the locale. Decimal fractions are represented in text as a sequence of decimal digit numerals with a decimal separator separating the whole-number portion from the fractional portion. For example, the decimal fraction for “¼” is expressed as zero-point-two-five (“0.25”). Unicode has no dedicated general decimal separator but unifies the decimal separator function with other punctuation characters. So the “.” used in “0.25” is the same period character used to end the sentence. However cultures vary in the glyph or grapheme used for a decimal separator. So in some locales, the comma may be used instead ”0,25”. Still other locales use a space for “0 25”. The Arabic writing system includes a dedicated character for a decimal separator that looks much like a comma ”٫” (U+066B) which when combined with the Arabic graphemes for the Arabic-Indic decimal digits to express one-quarter appears as: “٠٫٢٥”. Note that although Arabic is written from right to left, the significance of the digits is just as in English: from right to left (less significant to more significant).Characters for irrational numbers, sets and other constants
As stated above, the ten decimal digits, decimal separator and fraction slash are limited to representing rational numbers. Irrational numbers would require composition of infinite character sequences and so irrational numbers and other related constructs must be represented with other characters. In principle, Unicode does not yet encode characters to solely denote these numbers. For example, although Unicode 1.1 includes a character for “natural exponent’ ℯ (U+212F) its UCS canonical name derives from its glyph: “Script Small E”. As exceptions to this general rule, Unicode does include three characters canonically named for the number they represent: Plancks constant ℎ (U+210E), the reduced Planck constant ℏ (U+210F), and Eulers constantEuler–Mascheroni constant
The Euler–Mascheroni constant is a mathematical constant recurring in analysis and number theory, usually denoted by the lowercase Greek letter ....
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text and other compatibility numerals
The Arabic-Indic numerals also appear among the compatibility characters as rich text variant forms including bold, double-struck,, monospace, sans-serif and sans-serif bold. and fullwidth variants for legacy vertical text support.Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
CJK Suzhou (huāmǎ) numerals
The huāmǎ system is a variation of the rod numeral system. Rod numerals are closely related to the counting rodsCounting rods
Counting rods are small bars, typically 3–14 cm long, used by mathematicians for calculation in China, Japan, Korea, and Vietnam. They are placed either horizontally or vertically to represent any number and any fraction....
and the abacus
Chinese abacus
thumb|Suanpan The suanpan is an abacus of Chinese origin first described in a 190 CE book of the Eastern Han Dynasty, namely Supplementary Notes on the Art of Figures written by Xu Yue...
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
Suzhou (huāmǎ) numerals in Unicode
According to the UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
standard version 3.0, these characters are called Hangzhou
Hangzhou
Hangzhou , formerly transliterated as Hangchow, is the capital and largest city of Zhejiang Province in Eastern China. Governed as a sub-provincial city, and as of 2010, its entire administrative division or prefecture had a registered population of 8.7 million people...
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
Japanese numerals
The system of Japanese numerals is the system of number names used in the Japanese language. The Japanese numerals in writing are entirely based on the Chinese numerals and the grouping of large numbers follow the Chinese tradition of grouping by 10,000...
, Korean numerals
Korean numerals
The Korean language has two regularly used sets of numerals, a native Korean system and Sino-Korean system.-Construction:For both native and Sino- Korean numerals, the teens are represented by a combination of tens and the ones places...
Ancient Greek numerals
Unicode provides support for several variants of Greek numeralsGreek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
Ancient Greece
Ancient Greece is a civilization belonging to a period of Greek history that lasted from the Archaic period of the 8th to 6th centuries BC to the end of antiquity. Immediately following this period was the beginning of the Early Middle Ages and the Byzantine era. Included in Ancient Greece is the...
, possibly from the 7th century BC
7th century BC
The 7th century BC started the first day of 700 BC and ended the last day of 601 BC.The Assyrian Empire continued to dominate the Near East during this century, exercising formidable power over neighbors like Babylon and Egypt. In the last two decades of the century, however, the empire began to...
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
Aelius Herodianus
Aelius Herodianus or Herodian was one of the most celebrated grammarians of Greco-Roman antiquity. He is usually known as Herodian except when there is a danger of confusion with the historian also named Herodian....
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
Greek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
and acrophony
Acrophony
Acrophony is the naming of letters of an alphabetic writing system so that a letter's name begins with the letter itself. For example, Greek letter names are acrophonic: the names of the letters α, β, γ, δ, are spelled with the respective letters: ....
.
| Decimal | Symbol | Greek numeral |
|---|---|---|
| 1 | Ι | ἴος (ios) |
| 5 | Π | πέντε (pente) |
| 10 10 (number) 10 is an even natural number following 9 and preceding 11.-In mathematics:Ten is a composite number, its proper divisors being , and... |
Δ | δέκα (deka) |
| 100 100 (number) 100 is the natural number following 99 and preceding 101.-In mathematics:One hundred is the square of 10... |
Η | ἑκατόν (hekaton) |
| 1000 | Χ | χίλιοι (khilioi) |
| 10000 10000 (number) 10000 is the natural number following 9999 and preceding 10001.-Name:Many languages have a specific word for this number: In English it is myriad, in Ancient Greek , in Aramaic , in Hebrew רבבה , in Chinese , in Japanese [man], in Korean [man], and in Thai หมื่น [meun]... |
Μ | μύριοι (myrioi) |
Roman numerals
Roman numerals are a numeral systemNumeral system
A numeral system is a writing system for expressing numbers, that is a mathematical notation for representing numbers of a given set, using graphemes or symbols in a consistent manner....
originating in ancient Rome
Rome
Rome is the capital of Italy and the country's largest and most populated city and comune, with over 2.7 million residents in . The city is located in the central-western portion of the Italian Peninsula, on the Tiber River within the Lazio region of Italy.Rome's history spans two and a half...
, adapted from Etruscan numerals
Etruscan numerals
The Etruscan numerals were used by the ancient Etruscans. The system was adapted from the Greek Attic numerals and formed the inspiration for the later Roman numerals.There is very little surviving evidence of these numerals...
. The system used in classical antiquity
Classical antiquity
Classical antiquity is a broad term for a long period of cultural history centered on the Mediterranean Sea, comprising the interlocking civilizations of ancient Greece and ancient Rome, collectively known as the Greco-Roman world...
was slightly modified in the Middle Ages
Middle Ages
The Middle Ages is a periodization of European history from the 5th century to the 15th century. The Middle Ages follows the fall of the Western Roman Empire in 476 and precedes the Early Modern Era. It is the middle period of a three-period division of Western history: Classic, Medieval and Modern...
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
Olympic Games
The Olympic Games is a major international event featuring summer and winter sports, in which thousands of athletes participate in a variety of competitions. The Olympic Games have come to be regarded as the world’s foremost sports competition where more than 200 nations participate...
or the Super Bowl
Super Bowl
The Super Bowl is the championship game of the National Football League , the highest level of professional American football in the United States, culminating a season that begins in the late summer of the previous calendar year. The Super Bowl uses Roman numerals to identify each game, rather...
.
Roman Numerals in Unicode
UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
Number Forms
Number Forms are Unicode characters which have specific meaning as numbers, but are constructed from other characters. They consist primarily of vulgar fractions and roman numerals. They are placed in the Unicode codepoint range 0x2150 through 0x218F , except for three fractions in ISO-8859-1...
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 (, similar to Greek Stigma
Stigma (letter)
Stigma is a ligature of the Greek letters sigma and tau , which was used in writing Greek between the middle ages and the 19th century. It is also used as a numeral symbol for the number 6...
: ), early 50 (, similar to down arrow ), 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
| Code x= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 50 | 100 | 500 | 1,000 |
| U+216x | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ | Ⅺ | Ⅻ | Ⅼ | Ⅽ | Ⅾ | Ⅿ |
| U+217x | ⅰ | ⅱ | ⅲ | ⅳ | ⅴ | ⅵ | ⅶ | ⅷ | ⅸ | ⅹ | ⅺ | ⅻ | ⅼ | ⅽ | ⅾ | ⅿ |
| Value | 1000 | 5000 | 10,000 | – | – | 6 | 50 | 50,000 | 100,000 | |||||||
| U+218x | ↀ | ↁ | ↂ | Ↄ | ↄ | ↅ | ↆ | ↇ | ↈ | |||||||
The characters in the range U+2160–217F are present only for compatibility
Unicode compatibility characters
In discussing Unicode and the UCS, many often refer to compatibility characters. Compatibility characters are graphical characters that are discouraged by the Unicode Consortium...
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
Typeface
In typography, a typeface is the artistic representation or interpretation of characters; it is the way the type looks. Each type is designed and there are thousands of different typefaces in existence, with new ones being developed constantly....
that contains appropriate glyphs for them.
If using blackletter
Blackletter
Blackletter, also known as Gothic script, Gothic minuscule, or Textura, was a script used throughout Western Europe from approximately 1150 to well into the 17th century. It continued to be used for the German language until the 20th century. Fraktur is a notable script of this type, and sometimes...
or script typefaces, Roman numerals are set in Roman type
Roman type
In typography, roman is one of the three main kinds of historical type, alongside blackletter and italic. Roman type was modelled from a European scribal manuscript style of the 1400s, based on the pairing of inscriptional capitals used in ancient Rome with Carolingian minuscules developed in the...
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
Counting rod numerals
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Vertical | |
|
|
|
|
|
|
|
|
|
| Horizontal | |
|
|
|
|
|
|
|
|
|
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.Counting rod numerals in Unicode
Counting rod numerals are included in their own block in the Supplementary Multilingual Plane (SMP) from U+1D360 to U+1D37F. Eighteen characters for vertical and horizontal digits of 1-9 are included as of Unicode 5.0, though vertical and horizontal are opposite from the description above. Fourteen code points reserved for future use. Zero should be represented by U+3007Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
Arabic-Indic Numerals
The Arabic-Indic numerals involve ten digits (for base ten; 0-9 ) and a decimal separator that can be combined into composite numerals representing any rational number. Unicode includes these ten digits in the Basic Latin (or ASCII derived) block. Unicode has no decimal separator for common unified use. The Arabic script includes an Arabic specific decimal separator (U+066B). Other writing systems are to use whatever punctuation produces the appropriate glyph for the locale: for example ‘Full Stop’ (U+002E period) in United States usage and Comma (U+002C) in many other locales.The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
Hexadecimal numerals
Unicode adds a ‘Hex_Digit’ property to the characters commonly used for hexadecimal digits: decimal digits 0-9, Latin capital letters A-F and Latin small letters a-f. This property is also indicated on the compatibility characters for CJK Fullwidth Forms.Fractions
The fraction slash character (U+2044) allows authors using Unicode to compose any arbitrary fraction along with the decimal digits. Unicode also includes a handful of vulgar fractions as compatibility characters, but discourages their use.Decimal fractions
Several characters in Unicode can serve as a decimal separator depending on the locale. Decimal fractions are represented in text as a sequence of decimal digit numerals with a decimal separator separating the whole-number portion from the fractional portion. For example, the decimal fraction for “¼” is expressed as zero-point-two-five (“0.25”). Unicode has no dedicated general decimal separator but unifies the decimal separator function with other punctuation characters. So the “.” used in “0.25” is the same period character used to end the sentence. However cultures vary in the glyph or grapheme used for a decimal separator. So in some locales, the comma may be used instead ”0,25”. Still other locales use a space for “0 25”. The Arabic writing system includes a dedicated character for a decimal separator that looks much like a comma ”٫” (U+066B) which when combined with the Arabic graphemes for the Arabic-Indic decimal digits to express one-quarter appears as: “٠٫٢٥”. Note that although Arabic is written from right to left, the significance of the digits is just as in English: from right to left (less significant to more significant).Characters for irrational numbers, sets and other constants
As stated above, the ten decimal digits, decimal separator and fraction slash are limited to representing rational numbers. Irrational numbers would require composition of infinite character sequences and so irrational numbers and other related constructs must be represented with other characters. In principle, Unicode does not yet encode characters to solely denote these numbers. For example, although Unicode 1.1 includes a character for “natural exponent’ ℯ (U+212F) its UCS canonical name derives from its glyph: “Script Small E”. As exceptions to this general rule, Unicode does include three characters canonically named for the number they represent: Plancks constant ℎ (U+210E), the reduced Planck constant ℏ (U+210F), and Eulers constantEuler–Mascheroni constant
The Euler–Mascheroni constant is a mathematical constant recurring in analysis and number theory, usually denoted by the lowercase Greek letter ....
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text and other compatibility numerals
The Arabic-Indic numerals also appear among the compatibility characters as rich text variant forms including bold, double-struck,, monospace, sans-serif and sans-serif bold. and fullwidth variants for legacy vertical text support.Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
CJK Suzhou (huāmǎ) numerals
The huāmǎ system is a variation of the rod numeral system. Rod numerals are closely related to the counting rodsCounting rods
Counting rods are small bars, typically 3–14 cm long, used by mathematicians for calculation in China, Japan, Korea, and Vietnam. They are placed either horizontally or vertically to represent any number and any fraction....
and the abacus
Chinese abacus
thumb|Suanpan The suanpan is an abacus of Chinese origin first described in a 190 CE book of the Eastern Han Dynasty, namely Supplementary Notes on the Art of Figures written by Xu Yue...
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
Suzhou (huāmǎ) numerals in Unicode
According to the UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
standard version 3.0, these characters are called Hangzhou
Hangzhou
Hangzhou , formerly transliterated as Hangchow, is the capital and largest city of Zhejiang Province in Eastern China. Governed as a sub-provincial city, and as of 2010, its entire administrative division or prefecture had a registered population of 8.7 million people...
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
Japanese numerals
The system of Japanese numerals is the system of number names used in the Japanese language. The Japanese numerals in writing are entirely based on the Chinese numerals and the grouping of large numbers follow the Chinese tradition of grouping by 10,000...
, Korean numerals
Korean numerals
The Korean language has two regularly used sets of numerals, a native Korean system and Sino-Korean system.-Construction:For both native and Sino- Korean numerals, the teens are represented by a combination of tens and the ones places...
Ancient Greek numerals
Unicode provides support for several variants of Greek numeralsGreek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
Ancient Greece
Ancient Greece is a civilization belonging to a period of Greek history that lasted from the Archaic period of the 8th to 6th centuries BC to the end of antiquity. Immediately following this period was the beginning of the Early Middle Ages and the Byzantine era. Included in Ancient Greece is the...
, possibly from the 7th century BC
7th century BC
The 7th century BC started the first day of 700 BC and ended the last day of 601 BC.The Assyrian Empire continued to dominate the Near East during this century, exercising formidable power over neighbors like Babylon and Egypt. In the last two decades of the century, however, the empire began to...
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
Aelius Herodianus
Aelius Herodianus or Herodian was one of the most celebrated grammarians of Greco-Roman antiquity. He is usually known as Herodian except when there is a danger of confusion with the historian also named Herodian....
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
Greek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
and acrophony
Acrophony
Acrophony is the naming of letters of an alphabetic writing system so that a letter's name begins with the letter itself. For example, Greek letter names are acrophonic: the names of the letters α, β, γ, δ, are spelled with the respective letters: ....
.
| Decimal | Symbol | Greek numeral |
|---|---|---|
| 1 | Ι | ἴος (ios) |
| 5 | Π | πέντε (pente) |
| 10 10 (number) 10 is an even natural number following 9 and preceding 11.-In mathematics:Ten is a composite number, its proper divisors being , and... |
Δ | δέκα (deka) |
| 100 100 (number) 100 is the natural number following 99 and preceding 101.-In mathematics:One hundred is the square of 10... |
Η | ἑκατόν (hekaton) |
| 1000 | Χ | χίλιοι (khilioi) |
| 10000 10000 (number) 10000 is the natural number following 9999 and preceding 10001.-Name:Many languages have a specific word for this number: In English it is myriad, in Ancient Greek , in Aramaic , in Hebrew רבבה , in Chinese , in Japanese [man], in Korean [man], and in Thai หมื่น [meun]... |
Μ | μύριοι (myrioi) |
Roman numerals
Roman numerals are a numeral systemNumeral system
A numeral system is a writing system for expressing numbers, that is a mathematical notation for representing numbers of a given set, using graphemes or symbols in a consistent manner....
originating in ancient Rome
Rome
Rome is the capital of Italy and the country's largest and most populated city and comune, with over 2.7 million residents in . The city is located in the central-western portion of the Italian Peninsula, on the Tiber River within the Lazio region of Italy.Rome's history spans two and a half...
, adapted from Etruscan numerals
Etruscan numerals
The Etruscan numerals were used by the ancient Etruscans. The system was adapted from the Greek Attic numerals and formed the inspiration for the later Roman numerals.There is very little surviving evidence of these numerals...
. The system used in classical antiquity
Classical antiquity
Classical antiquity is a broad term for a long period of cultural history centered on the Mediterranean Sea, comprising the interlocking civilizations of ancient Greece and ancient Rome, collectively known as the Greco-Roman world...
was slightly modified in the Middle Ages
Middle Ages
The Middle Ages is a periodization of European history from the 5th century to the 15th century. The Middle Ages follows the fall of the Western Roman Empire in 476 and precedes the Early Modern Era. It is the middle period of a three-period division of Western history: Classic, Medieval and Modern...
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
Olympic Games
The Olympic Games is a major international event featuring summer and winter sports, in which thousands of athletes participate in a variety of competitions. The Olympic Games have come to be regarded as the world’s foremost sports competition where more than 200 nations participate...
or the Super Bowl
Super Bowl
The Super Bowl is the championship game of the National Football League , the highest level of professional American football in the United States, culminating a season that begins in the late summer of the previous calendar year. The Super Bowl uses Roman numerals to identify each game, rather...
.
Roman Numerals in Unicode
UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
Number Forms
Number Forms are Unicode characters which have specific meaning as numbers, but are constructed from other characters. They consist primarily of vulgar fractions and roman numerals. They are placed in the Unicode codepoint range 0x2150 through 0x218F , except for three fractions in ISO-8859-1...
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 (, similar to Greek Stigma
Stigma (letter)
Stigma is a ligature of the Greek letters sigma and tau , which was used in writing Greek between the middle ages and the 19th century. It is also used as a numeral symbol for the number 6...
: ), early 50 (, similar to down arrow ), 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
| Code x= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 50 | 100 | 500 | 1,000 |
| U+216x | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ | Ⅺ | Ⅻ | Ⅼ | Ⅽ | Ⅾ | Ⅿ |
| U+217x | ⅰ | ⅱ | ⅲ | ⅳ | ⅴ | ⅵ | ⅶ | ⅷ | ⅸ | ⅹ | ⅺ | ⅻ | ⅼ | ⅽ | ⅾ | ⅿ |
| Value | 1000 | 5000 | 10,000 | – | – | 6 | 50 | 50,000 | 100,000 | |||||||
| U+218x | ↀ | ↁ | ↂ | Ↄ | ↄ | ↅ | ↆ | ↇ | ↈ | |||||||
The characters in the range U+2160–217F are present only for compatibility
Unicode compatibility characters
In discussing Unicode and the UCS, many often refer to compatibility characters. Compatibility characters are graphical characters that are discouraged by the Unicode Consortium...
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
Typeface
In typography, a typeface is the artistic representation or interpretation of characters; it is the way the type looks. Each type is designed and there are thousands of different typefaces in existence, with new ones being developed constantly....
that contains appropriate glyphs for them.
If using blackletter
Blackletter
Blackletter, also known as Gothic script, Gothic minuscule, or Textura, was a script used throughout Western Europe from approximately 1150 to well into the 17th century. It continued to be used for the German language until the 20th century. Fraktur is a notable script of this type, and sometimes...
or script typefaces, Roman numerals are set in Roman type
Roman type
In typography, roman is one of the three main kinds of historical type, alongside blackletter and italic. Roman type was modelled from a European scribal manuscript style of the 1400s, based on the pairing of inscriptional capitals used in ancient Rome with Carolingian minuscules developed in the...
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
Counting rod numerals
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Vertical | |
|
|
|
|
|
|
|
|
|
| Horizontal | |
|
|
|
|
|
|
|
|
|
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.Counting rod numerals in Unicode
Counting rod numerals are included in their own block in the Supplementary Multilingual Plane (SMP) from U+1D360 to U+1D37F. Eighteen characters for vertical and horizontal digits of 1-9 are included as of Unicode 5.0, though vertical and horizontal are opposite from the description above. Fourteen code points reserved for future use. Zero should be represented by U+3007Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
Arabic-Indic Numerals
The Arabic-Indic numerals involve ten digits (for base ten; 0-9 ) and a decimal separator that can be combined into composite numerals representing any rational number. Unicode includes these ten digits in the Basic Latin (or ASCII derived) block. Unicode has no decimal separator for common unified use. The Arabic script includes an Arabic specific decimal separator (U+066B). Other writing systems are to use whatever punctuation produces the appropriate glyph for the locale: for example ‘Full Stop’ (U+002E period) in United States usage and Comma (U+002C) in many other locales.The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
Hexadecimal numerals
Unicode adds a ‘Hex_Digit’ property to the characters commonly used for hexadecimal digits: decimal digits 0-9, Latin capital letters A-F and Latin small letters a-f. This property is also indicated on the compatibility characters for CJK Fullwidth Forms.Fractions
The fraction slash character (U+2044) allows authors using Unicode to compose any arbitrary fraction along with the decimal digits. Unicode also includes a handful of vulgar fractions as compatibility characters, but discourages their use.Decimal fractions
Several characters in Unicode can serve as a decimal separator depending on the locale. Decimal fractions are represented in text as a sequence of decimal digit numerals with a decimal separator separating the whole-number portion from the fractional portion. For example, the decimal fraction for “¼” is expressed as zero-point-two-five (“0.25”). Unicode has no dedicated general decimal separator but unifies the decimal separator function with other punctuation characters. So the “.” used in “0.25” is the same period character used to end the sentence. However cultures vary in the glyph or grapheme used for a decimal separator. So in some locales, the comma may be used instead ”0,25”. Still other locales use a space for “0 25”. The Arabic writing system includes a dedicated character for a decimal separator that looks much like a comma ”٫” (U+066B) which when combined with the Arabic graphemes for the Arabic-Indic decimal digits to express one-quarter appears as: “٠٫٢٥”. Note that although Arabic is written from right to left, the significance of the digits is just as in English: from right to left (less significant to more significant).Characters for irrational numbers, sets and other constants
As stated above, the ten decimal digits, decimal separator and fraction slash are limited to representing rational numbers. Irrational numbers would require composition of infinite character sequences and so irrational numbers and other related constructs must be represented with other characters. In principle, Unicode does not yet encode characters to solely denote these numbers. For example, although Unicode 1.1 includes a character for “natural exponent’ ℯ (U+212F) its UCS canonical name derives from its glyph: “Script Small E”. As exceptions to this general rule, Unicode does include three characters canonically named for the number they represent: Plancks constant ℎ (U+210E), the reduced Planck constant ℏ (U+210F), and Eulers constantEuler–Mascheroni constant
The Euler–Mascheroni constant is a mathematical constant recurring in analysis and number theory, usually denoted by the lowercase Greek letter ....
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text and other compatibility numerals
The Arabic-Indic numerals also appear among the compatibility characters as rich text variant forms including bold, double-struck,, monospace, sans-serif and sans-serif bold. and fullwidth variants for legacy vertical text support.Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
CJK Suzhou (huāmǎ) numerals
The huāmǎ system is a variation of the rod numeral system. Rod numerals are closely related to the counting rodsCounting rods
Counting rods are small bars, typically 3–14 cm long, used by mathematicians for calculation in China, Japan, Korea, and Vietnam. They are placed either horizontally or vertically to represent any number and any fraction....
and the abacus
Chinese abacus
thumb|Suanpan The suanpan is an abacus of Chinese origin first described in a 190 CE book of the Eastern Han Dynasty, namely Supplementary Notes on the Art of Figures written by Xu Yue...
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
Suzhou (huāmǎ) numerals in Unicode
According to the UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
standard version 3.0, these characters are called Hangzhou
Hangzhou
Hangzhou , formerly transliterated as Hangchow, is the capital and largest city of Zhejiang Province in Eastern China. Governed as a sub-provincial city, and as of 2010, its entire administrative division or prefecture had a registered population of 8.7 million people...
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
Japanese numerals
The system of Japanese numerals is the system of number names used in the Japanese language. The Japanese numerals in writing are entirely based on the Chinese numerals and the grouping of large numbers follow the Chinese tradition of grouping by 10,000...
, Korean numerals
Korean numerals
The Korean language has two regularly used sets of numerals, a native Korean system and Sino-Korean system.-Construction:For both native and Sino- Korean numerals, the teens are represented by a combination of tens and the ones places...
Ancient Greek numerals
Unicode provides support for several variants of Greek numeralsGreek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
Ancient Greece
Ancient Greece is a civilization belonging to a period of Greek history that lasted from the Archaic period of the 8th to 6th centuries BC to the end of antiquity. Immediately following this period was the beginning of the Early Middle Ages and the Byzantine era. Included in Ancient Greece is the...
, possibly from the 7th century BC
7th century BC
The 7th century BC started the first day of 700 BC and ended the last day of 601 BC.The Assyrian Empire continued to dominate the Near East during this century, exercising formidable power over neighbors like Babylon and Egypt. In the last two decades of the century, however, the empire began to...
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
Aelius Herodianus
Aelius Herodianus or Herodian was one of the most celebrated grammarians of Greco-Roman antiquity. He is usually known as Herodian except when there is a danger of confusion with the historian also named Herodian....
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
Greek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
and acrophony
Acrophony
Acrophony is the naming of letters of an alphabetic writing system so that a letter's name begins with the letter itself. For example, Greek letter names are acrophonic: the names of the letters α, β, γ, δ, are spelled with the respective letters: ....
.
| Decimal | Symbol | Greek numeral |
|---|---|---|
| 1 | Ι | ἴος (ios) |
| 5 | Π | πέντε (pente) |
| 10 10 (number) 10 is an even natural number following 9 and preceding 11.-In mathematics:Ten is a composite number, its proper divisors being , and... |
Δ | δέκα (deka) |
| 100 100 (number) 100 is the natural number following 99 and preceding 101.-In mathematics:One hundred is the square of 10... |
Η | ἑκατόν (hekaton) |
| 1000 | Χ | χίλιοι (khilioi) |
| 10000 10000 (number) 10000 is the natural number following 9999 and preceding 10001.-Name:Many languages have a specific word for this number: In English it is myriad, in Ancient Greek , in Aramaic , in Hebrew רבבה , in Chinese , in Japanese [man], in Korean [man], and in Thai หมื่น [meun]... |
Μ | μύριοι (myrioi) |
Roman numerals
Roman numerals are a numeral systemNumeral system
A numeral system is a writing system for expressing numbers, that is a mathematical notation for representing numbers of a given set, using graphemes or symbols in a consistent manner....
originating in ancient Rome
Rome
Rome is the capital of Italy and the country's largest and most populated city and comune, with over 2.7 million residents in . The city is located in the central-western portion of the Italian Peninsula, on the Tiber River within the Lazio region of Italy.Rome's history spans two and a half...
, adapted from Etruscan numerals
Etruscan numerals
The Etruscan numerals were used by the ancient Etruscans. The system was adapted from the Greek Attic numerals and formed the inspiration for the later Roman numerals.There is very little surviving evidence of these numerals...
. The system used in classical antiquity
Classical antiquity
Classical antiquity is a broad term for a long period of cultural history centered on the Mediterranean Sea, comprising the interlocking civilizations of ancient Greece and ancient Rome, collectively known as the Greco-Roman world...
was slightly modified in the Middle Ages
Middle Ages
The Middle Ages is a periodization of European history from the 5th century to the 15th century. The Middle Ages follows the fall of the Western Roman Empire in 476 and precedes the Early Modern Era. It is the middle period of a three-period division of Western history: Classic, Medieval and Modern...
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
Olympic Games
The Olympic Games is a major international event featuring summer and winter sports, in which thousands of athletes participate in a variety of competitions. The Olympic Games have come to be regarded as the world’s foremost sports competition where more than 200 nations participate...
or the Super Bowl
Super Bowl
The Super Bowl is the championship game of the National Football League , the highest level of professional American football in the United States, culminating a season that begins in the late summer of the previous calendar year. The Super Bowl uses Roman numerals to identify each game, rather...
.
Roman Numerals in Unicode
UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
Number Forms
Number Forms are Unicode characters which have specific meaning as numbers, but are constructed from other characters. They consist primarily of vulgar fractions and roman numerals. They are placed in the Unicode codepoint range 0x2150 through 0x218F , except for three fractions in ISO-8859-1...
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 .gif", event)' onMouseout='HidePop("87346")' href="/topics/Stigma_(letter)">Stigma
Stigma (letter)
Stigma is a ligature of the Greek letters sigma and tau , which was used in writing Greek between the middle ages and the 19th century. It is also used as a numeral symbol for the number 6...
: ), early 50 , 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
| Code x= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 50 | 100 | 500 | 1,000 |
| U+216x | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ | Ⅺ | Ⅻ | Ⅼ | Ⅽ | Ⅾ | Ⅿ |
| U+217x | ⅰ | ⅱ | ⅲ | ⅳ | ⅴ | ⅵ | ⅶ | ⅷ | ⅸ | ⅹ | ⅺ | ⅻ | ⅼ | ⅽ | ⅾ | ⅿ |
| Value | 1000 | 5000 | 10,000 | – | – | 6 | 50 | 50,000 | 100,000 | |||||||
| U+218x | ↀ | ↁ | ↂ | Ↄ | ↄ | ↅ | ↆ | ↇ | ↈ | |||||||
The characters in the range U+2160–217F are present only for compatibility
Unicode compatibility characters
In discussing Unicode and the UCS, many often refer to compatibility characters. Compatibility characters are graphical characters that are discouraged by the Unicode Consortium...
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
Typeface
In typography, a typeface is the artistic representation or interpretation of characters; it is the way the type looks. Each type is designed and there are thousands of different typefaces in existence, with new ones being developed constantly....
that contains appropriate glyphs for them.
If using blackletter
Blackletter
Blackletter, also known as Gothic script, Gothic minuscule, or Textura, was a script used throughout Western Europe from approximately 1150 to well into the 17th century. It continued to be used for the German language until the 20th century. Fraktur is a notable script of this type, and sometimes...
or script typefaces, Roman numerals are set in Roman type
Roman type
In typography, roman is one of the three main kinds of historical type, alongside blackletter and italic. Roman type was modelled from a European scribal manuscript style of the 1400s, based on the pairing of inscriptional capitals used in ancient Rome with Carolingian minuscules developed in the...
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
Counting rod numerals
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Vertical | |
|
|
|
|
|
|
|
|
|
| Horizontal | |
|
|
|
|
|
|
|
|
|
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.Counting rod numerals in Unicode
Counting rod numerals are included in their own block in the Supplementary Multilingual Plane (SMP) from U+1D360 to U+1D37F. Eighteen characters for vertical and horizontal digits of 1-9 are included as of Unicode 5.0, though vertical and horizontal are opposite from the description above. Fourteen code points reserved for future use. Zero should be represented by U+3007Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
Arabic-Indic Numerals
The Arabic-Indic numerals involve ten digits (for base ten; 0-9 ) and a decimal separator that can be combined into composite numerals representing any rational number. Unicode includes these ten digits in the Basic Latin (or ASCII derived) block. Unicode has no decimal separator for common unified use. The Arabic script includes an Arabic specific decimal separator (U+066B). Other writing systems are to use whatever punctuation produces the appropriate glyph for the locale: for example ‘Full Stop’ (U+002E period) in United States usage and Comma (U+002C) in many other locales.The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
Hexadecimal numerals
Unicode adds a ‘Hex_Digit’ property to the characters commonly used for hexadecimal digits: decimal digits 0-9, Latin capital letters A-F and Latin small letters a-f. This property is also indicated on the compatibility characters for CJK Fullwidth Forms.Fractions
The fraction slash character (U+2044) allows authors using Unicode to compose any arbitrary fraction along with the decimal digits. Unicode also includes a handful of vulgar fractions as compatibility characters, but discourages their use.Decimal fractions
Several characters in Unicode can serve as a decimal separator depending on the locale. Decimal fractions are represented in text as a sequence of decimal digit numerals with a decimal separator separating the whole-number portion from the fractional portion. For example, the decimal fraction for “¼” is expressed as zero-point-two-five (“0.25”). Unicode has no dedicated general decimal separator but unifies the decimal separator function with other punctuation characters. So the “.” used in “0.25” is the same period character used to end the sentence. However cultures vary in the glyph or grapheme used for a decimal separator. So in some locales, the comma may be used instead ”0,25”. Still other locales use a space for “0 25”. The Arabic writing system includes a dedicated character for a decimal separator that looks much like a comma ”٫” (U+066B) which when combined with the Arabic graphemes for the Arabic-Indic decimal digits to express one-quarter appears as: “٠٫٢٥”. Note that although Arabic is written from right to left, the significance of the digits is just as in English: from right to left (less significant to more significant).Characters for irrational numbers, sets and other constants
As stated above, the ten decimal digits, decimal separator and fraction slash are limited to representing rational numbers. Irrational numbers would require composition of infinite character sequences and so irrational numbers and other related constructs must be represented with other characters. In principle, Unicode does not yet encode characters to solely denote these numbers. For example, although Unicode 1.1 includes a character for “natural exponent’ ℯ (U+212F) its UCS canonical name derives from its glyph: “Script Small E”. As exceptions to this general rule, Unicode does include three characters canonically named for the number they represent: Plancks constant ℎ (U+210E), the reduced Planck constant ℏ (U+210F), and Eulers constantEuler–Mascheroni constant
The Euler–Mascheroni constant is a mathematical constant recurring in analysis and number theory, usually denoted by the lowercase Greek letter ....
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text and other compatibility numerals
The Arabic-Indic numerals also appear among the compatibility characters as rich text variant forms including bold, double-struck,, monospace, sans-serif and sans-serif bold. and fullwidth variants for legacy vertical text support.Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
CJK Suzhou (huāmǎ) numerals
The huāmǎ system is a variation of the rod numeral system. Rod numerals are closely related to the counting rodsCounting rods
Counting rods are small bars, typically 3–14 cm long, used by mathematicians for calculation in China, Japan, Korea, and Vietnam. They are placed either horizontally or vertically to represent any number and any fraction....
and the abacus
Chinese abacus
thumb|Suanpan The suanpan is an abacus of Chinese origin first described in a 190 CE book of the Eastern Han Dynasty, namely Supplementary Notes on the Art of Figures written by Xu Yue...
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
Suzhou (huāmǎ) numerals in Unicode
According to the UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
standard version 3.0, these characters are called Hangzhou
Hangzhou
Hangzhou , formerly transliterated as Hangchow, is the capital and largest city of Zhejiang Province in Eastern China. Governed as a sub-provincial city, and as of 2010, its entire administrative division or prefecture had a registered population of 8.7 million people...
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
Japanese numerals
The system of Japanese numerals is the system of number names used in the Japanese language. The Japanese numerals in writing are entirely based on the Chinese numerals and the grouping of large numbers follow the Chinese tradition of grouping by 10,000...
, Korean numerals
Korean numerals
The Korean language has two regularly used sets of numerals, a native Korean system and Sino-Korean system.-Construction:For both native and Sino- Korean numerals, the teens are represented by a combination of tens and the ones places...
Ancient Greek numerals
Unicode provides support for several variants of Greek numeralsGreek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
Ancient Greece
Ancient Greece is a civilization belonging to a period of Greek history that lasted from the Archaic period of the 8th to 6th centuries BC to the end of antiquity. Immediately following this period was the beginning of the Early Middle Ages and the Byzantine era. Included in Ancient Greece is the...
, possibly from the 7th century BC
7th century BC
The 7th century BC started the first day of 700 BC and ended the last day of 601 BC.The Assyrian Empire continued to dominate the Near East during this century, exercising formidable power over neighbors like Babylon and Egypt. In the last two decades of the century, however, the empire began to...
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
Aelius Herodianus
Aelius Herodianus or Herodian was one of the most celebrated grammarians of Greco-Roman antiquity. He is usually known as Herodian except when there is a danger of confusion with the historian also named Herodian....
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
Greek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
and acrophony
Acrophony
Acrophony is the naming of letters of an alphabetic writing system so that a letter's name begins with the letter itself. For example, Greek letter names are acrophonic: the names of the letters α, β, γ, δ, are spelled with the respective letters: ....
.
| Decimal | Symbol | Greek numeral |
|---|---|---|
| 1 | Ι | ἴος (ios) |
| 5 | Π | πέντε (pente) |
| 10 10 (number) 10 is an even natural number following 9 and preceding 11.-In mathematics:Ten is a composite number, its proper divisors being , and... |
Δ | δέκα (deka) |
| 100 100 (number) 100 is the natural number following 99 and preceding 101.-In mathematics:One hundred is the square of 10... |
Η | ἑκατόν (hekaton) |
| 1000 | Χ | χίλιοι (khilioi) |
| 10000 10000 (number) 10000 is the natural number following 9999 and preceding 10001.-Name:Many languages have a specific word for this number: In English it is myriad, in Ancient Greek , in Aramaic , in Hebrew רבבה , in Chinese , in Japanese [man], in Korean [man], and in Thai หมื่น [meun]... |
Μ | μύριοι (myrioi) |
Roman numerals
Roman numerals are a numeral systemNumeral system
A numeral system is a writing system for expressing numbers, that is a mathematical notation for representing numbers of a given set, using graphemes or symbols in a consistent manner....
originating in ancient Rome
Rome
Rome is the capital of Italy and the country's largest and most populated city and comune, with over 2.7 million residents in . The city is located in the central-western portion of the Italian Peninsula, on the Tiber River within the Lazio region of Italy.Rome's history spans two and a half...
, adapted from Etruscan numerals
Etruscan numerals
The Etruscan numerals were used by the ancient Etruscans. The system was adapted from the Greek Attic numerals and formed the inspiration for the later Roman numerals.There is very little surviving evidence of these numerals...
. The system used in classical antiquity
Classical antiquity
Classical antiquity is a broad term for a long period of cultural history centered on the Mediterranean Sea, comprising the interlocking civilizations of ancient Greece and ancient Rome, collectively known as the Greco-Roman world...
was slightly modified in the Middle Ages
Middle Ages
The Middle Ages is a periodization of European history from the 5th century to the 15th century. The Middle Ages follows the fall of the Western Roman Empire in 476 and precedes the Early Modern Era. It is the middle period of a three-period division of Western history: Classic, Medieval and Modern...
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
Olympic Games
The Olympic Games is a major international event featuring summer and winter sports, in which thousands of athletes participate in a variety of competitions. The Olympic Games have come to be regarded as the world’s foremost sports competition where more than 200 nations participate...
or the Super Bowl
Super Bowl
The Super Bowl is the championship game of the National Football League , the highest level of professional American football in the United States, culminating a season that begins in the late summer of the previous calendar year. The Super Bowl uses Roman numerals to identify each game, rather...
.
Roman Numerals in Unicode
UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
Number Forms
Number Forms are Unicode characters which have specific meaning as numbers, but are constructed from other characters. They consist primarily of vulgar fractions and roman numerals. They are placed in the Unicode codepoint range 0x2150 through 0x218F , except for three fractions in ISO-8859-1...
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 (, similar to Greek Stigma
Stigma (letter)
Stigma is a ligature of the Greek letters sigma and tau , which was used in writing Greek between the middle ages and the 19th century. It is also used as a numeral symbol for the number 6...
: ), early 50 (, similar to down arrow ), 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
| Code x= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 50 | 100 | 500 | 1,000 |
| U+216x | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ | Ⅺ | Ⅻ | Ⅼ | Ⅽ | Ⅾ | Ⅿ |
| U+217x | ⅰ | ⅱ | ⅲ | ⅳ | ⅴ | ⅵ | ⅶ | ⅷ | ⅸ | ⅹ | ⅺ | ⅻ | ⅼ | ⅽ | ⅾ | ⅿ |
| Value | 1000 | 5000 | 10,000 | – | – | 6 | 50 | 50,000 | 100,000 | |||||||
| U+218x | ↀ | ↁ | ↂ | Ↄ | ↄ | ↅ | ↆ | ↇ | ↈ | |||||||
The characters in the range U+2160–217F are present only for compatibility
Unicode compatibility characters
In discussing Unicode and the UCS, many often refer to compatibility characters. Compatibility characters are graphical characters that are discouraged by the Unicode Consortium...
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
Typeface
In typography, a typeface is the artistic representation or interpretation of characters; it is the way the type looks. Each type is designed and there are thousands of different typefaces in existence, with new ones being developed constantly....
that contains appropriate glyphs for them.
If using blackletter
Blackletter
Blackletter, also known as Gothic script, Gothic minuscule, or Textura, was a script used throughout Western Europe from approximately 1150 to well into the 17th century. It continued to be used for the German language until the 20th century. Fraktur is a notable script of this type, and sometimes...
or script typefaces, Roman numerals are set in Roman type
Roman type
In typography, roman is one of the three main kinds of historical type, alongside blackletter and italic. Roman type was modelled from a European scribal manuscript style of the 1400s, based on the pairing of inscriptional capitals used in ancient Rome with Carolingian minuscules developed in the...
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
Counting rod numerals
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Vertical | |
|
|
|
|
|
|
|
|
|
| Horizontal | |
|
|
|
|
|
|
|
|
|
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.Counting rod numerals in Unicode
Counting rod numerals are included in their own block in the Supplementary Multilingual Plane (SMP) from U+1D360 to U+1D37F. Eighteen characters for vertical and horizontal digits of 1-9 are included as of Unicode 5.0, though vertical and horizontal are opposite from the description above. Fourteen code points reserved for future use. Zero should be represented by U+3007Numerals are characters that denote a number. The same Arabic-Indic numerals are used widely in various writing systems throughout the world and all share the same semantics for denoting numbers, However, the graphemes representing these numerals differ widely from one writing system to another. To support these grapheme differences, Unicode includes encodings of these numerals within many of the script blocks. The decimal digits are repeated in 23 separate blocks: 2 times in Arabic مرات باللغة العربية .Six additional blocks contain the digits again as rich text primarily to serve as a palette of graphemes for specialized mathematical use. In addition to many forms of the Arabic-Indic numerals, Unicode also includes several less common numerals such as: Aegean numerals, Roman numerals, counting rod numerals, Cuneiform numerals and ancient Greek numerals.
Numerals invariably involve composition of glyphs as a limited number of characters are composed to make other numerals. For example the sequence 9–9–0 in Arabic-Indic numerals composes the numeral for nine hundred and ninety (990). In Roman numerals, the same number is expressed by the composed numeral Ⅹↀ or ⅩⅯ. Each of these is a distinct numeral for representing the same abstract number. The semantics of the numerals differ in particular in their composition. The Arabic-Indic decimal digits are positional-value compositions, while the Roman numerals are sign-value and they are additive and subtractive depending on their composition.
Arabic-Indic Numerals
The Arabic-Indic numerals involve ten digits (for base ten; 0-9 ) and a decimal separator that can be combined into composite numerals representing any rational number. Unicode includes these ten digits in the Basic Latin (or ASCII derived) block. Unicode has no decimal separator for common unified use. The Arabic script includes an Arabic specific decimal separator (U+066B). Other writing systems are to use whatever punctuation produces the appropriate glyph for the locale: for example ‘Full Stop’ (U+002E period) in United States usage and Comma (U+002C) in many other locales.The Arabic-Indic digits are repeated in several other scripts: Arabic, Balinese, Bengali, Devanagari, Ethiopic, Gujarati, Gurmukhi, Telugu, Khmer, Lao, Limbu, Malayalam, Mongolian, Myanmar, New Tai Lue, Nko, Oriya, Telugu, Thai, Tibetan, Osmanya. Unicode includes a numeric value property for each digit to assist in collation and other text processing operations. However, there is no mapping between the various related Arabic-Indic digits.
Hexadecimal numerals
Unicode adds a ‘Hex_Digit’ property to the characters commonly used for hexadecimal digits: decimal digits 0-9, Latin capital letters A-F and Latin small letters a-f. This property is also indicated on the compatibility characters for CJK Fullwidth Forms.Fractions
The fraction slash character (U+2044) allows authors using Unicode to compose any arbitrary fraction along with the decimal digits. Unicode also includes a handful of vulgar fractions as compatibility characters, but discourages their use.Decimal fractions
Several characters in Unicode can serve as a decimal separator depending on the locale. Decimal fractions are represented in text as a sequence of decimal digit numerals with a decimal separator separating the whole-number portion from the fractional portion. For example, the decimal fraction for “¼” is expressed as zero-point-two-five (“0.25”). Unicode has no dedicated general decimal separator but unifies the decimal separator function with other punctuation characters. So the “.” used in “0.25” is the same period character used to end the sentence. However cultures vary in the glyph or grapheme used for a decimal separator. So in some locales, the comma may be used instead ”0,25”. Still other locales use a space for “0 25”. The Arabic writing system includes a dedicated character for a decimal separator that looks much like a comma ”٫” (U+066B) which when combined with the Arabic graphemes for the Arabic-Indic decimal digits to express one-quarter appears as: “٠٫٢٥”. Note that although Arabic is written from right to left, the significance of the digits is just as in English: from right to left (less significant to more significant).Characters for irrational numbers, sets and other constants
As stated above, the ten decimal digits, decimal separator and fraction slash are limited to representing rational numbers. Irrational numbers would require composition of infinite character sequences and so irrational numbers and other related constructs must be represented with other characters. In principle, Unicode does not yet encode characters to solely denote these numbers. For example, although Unicode 1.1 includes a character for “natural exponent’ ℯ (U+212F) its UCS canonical name derives from its glyph: “Script Small E”. As exceptions to this general rule, Unicode does include three characters canonically named for the number they represent: Plancks constant ℎ (U+210E), the reduced Planck constant ℏ (U+210F), and Eulers constantEuler–Mascheroni constant
The Euler–Mascheroni constant is a mathematical constant recurring in analysis and number theory, usually denoted by the lowercase Greek letter ....
ℇ (U+2107). These characters are all given canonical names by the UCS for the number they semantically represent. They are not necessarily irrational number though, in practical terms, they would be exceedingly difficult to represent through composition of decimal digits. Representation of other irrational number and math constants is achieved through borrowing characters from other writing systems: for example using π from the Greek script (U+03C0) to signify the irrational number that is the ratio of the circumference to the diameter of a perfect circle.
Rich text and other compatibility numerals
The Arabic-Indic numerals also appear among the compatibility characters as rich text variant forms including bold, double-struck,, monospace, sans-serif and sans-serif bold. and fullwidth variants for legacy vertical text support.Rich text parenthesized, circled and other variants are also included in the blocks: Enclosed CJK Letters and Months; Enclosed Alphanumerics, Superscripts and Subscripts; Number Forms; and Dingbats.
CJK Suzhou (huāmǎ) numerals
The huāmǎ system is a variation of the rod numeral system. Rod numerals are closely related to the counting rodsCounting rods
Counting rods are small bars, typically 3–14 cm long, used by mathematicians for calculation in China, Japan, Korea, and Vietnam. They are placed either horizontally or vertically to represent any number and any fraction....
and the abacus
Chinese abacus
thumb|Suanpan The suanpan is an abacus of Chinese origin first described in a 190 CE book of the Eastern Han Dynasty, namely Supplementary Notes on the Art of Figures written by Xu Yue...
, which is why the numeric symbols for 1, 2, 3, 6, 7 and 8 in the huāmǎ system are represented in a similar way as on the abacus. Nowadays, the huāmǎ system is only used for displaying prices in Chinese markets or on traditional handwritten invoices.
Suzhou (huāmǎ) numerals in Unicode
According to the UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
standard version 3.0, these characters are called Hangzhou
Hangzhou
Hangzhou , formerly transliterated as Hangchow, is the capital and largest city of Zhejiang Province in Eastern China. Governed as a sub-provincial city, and as of 2010, its entire administrative division or prefecture had a registered population of 8.7 million people...
style numerals. This indicates that it is not used only by Cantonese in Hong Kong. In the Unicode standard 4.0, an erratum was added which stated:
The digits of the Suzhou numerals are designated in the CJK Symbols and Punctuation block between U+3021 and U+3029, U+3007, U+5341, U+5344, and. U+5345.
See also: Japanese numerals
Japanese numerals
The system of Japanese numerals is the system of number names used in the Japanese language. The Japanese numerals in writing are entirely based on the Chinese numerals and the grouping of large numbers follow the Chinese tradition of grouping by 10,000...
, Korean numerals
Korean numerals
The Korean language has two regularly used sets of numerals, a native Korean system and Sino-Korean system.-Construction:For both native and Sino- Korean numerals, the teens are represented by a combination of tens and the ones places...
Ancient Greek numerals
Unicode provides support for several variants of Greek numeralsGreek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
, assigned to the Supplementary Multilingual Plane from U+10140 through U+1018F.
Attic numerals were used by ancient Greeks
Ancient Greece
Ancient Greece is a civilization belonging to a period of Greek history that lasted from the Archaic period of the 8th to 6th centuries BC to the end of antiquity. Immediately following this period was the beginning of the Early Middle Ages and the Byzantine era. Included in Ancient Greece is the...
, possibly from the 7th century BC
7th century BC
The 7th century BC started the first day of 700 BC and ended the last day of 601 BC.The Assyrian Empire continued to dominate the Near East during this century, exercising formidable power over neighbors like Babylon and Egypt. In the last two decades of the century, however, the empire began to...
. They were also known as Herodianic numerals because they were first described in a 2nd century manuscript by Herodian
Aelius Herodianus
Aelius Herodianus or Herodian was one of the most celebrated grammarians of Greco-Roman antiquity. He is usually known as Herodian except when there is a danger of confusion with the historian also named Herodian....
. They are also known as acrophonic numerals because all of the symbols used derive from the first letters of the words that the symbols represent: 'one', 'five', 'ten', 'hundred', 'thousand' and 'ten thousand'. See Greek numerals
Greek numerals
Greek numerals are a system of representing numbers using letters of the Greek alphabet. They are also known by the names Ionian numerals, Milesian numerals , Alexandrian numerals, or alphabetic numerals...
and acrophony
Acrophony
Acrophony is the naming of letters of an alphabetic writing system so that a letter's name begins with the letter itself. For example, Greek letter names are acrophonic: the names of the letters α, β, γ, δ, are spelled with the respective letters: ....
.
| Decimal | Symbol | Greek numeral |
|---|---|---|
| 1 | Ι | ἴος (ios) |
| 5 | Π | πέντε (pente) |
| 10 10 (number) 10 is an even natural number following 9 and preceding 11.-In mathematics:Ten is a composite number, its proper divisors being , and... |
Δ | δέκα (deka) |
| 100 100 (number) 100 is the natural number following 99 and preceding 101.-In mathematics:One hundred is the square of 10... |
Η | ἑκατόν (hekaton) |
| 1000 | Χ | χίλιοι (khilioi) |
| 10000 10000 (number) 10000 is the natural number following 9999 and preceding 10001.-Name:Many languages have a specific word for this number: In English it is myriad, in Ancient Greek , in Aramaic , in Hebrew רבבה , in Chinese , in Japanese [man], in Korean [man], and in Thai หมื่น [meun]... |
Μ | μύριοι (myrioi) |
Roman numerals
Roman numerals are a numeral systemNumeral system
A numeral system is a writing system for expressing numbers, that is a mathematical notation for representing numbers of a given set, using graphemes or symbols in a consistent manner....
originating in ancient Rome
Rome
Rome is the capital of Italy and the country's largest and most populated city and comune, with over 2.7 million residents in . The city is located in the central-western portion of the Italian Peninsula, on the Tiber River within the Lazio region of Italy.Rome's history spans two and a half...
, adapted from Etruscan numerals
Etruscan numerals
The Etruscan numerals were used by the ancient Etruscans. The system was adapted from the Greek Attic numerals and formed the inspiration for the later Roman numerals.There is very little surviving evidence of these numerals...
. The system used in classical antiquity
Classical antiquity
Classical antiquity is a broad term for a long period of cultural history centered on the Mediterranean Sea, comprising the interlocking civilizations of ancient Greece and ancient Rome, collectively known as the Greco-Roman world...
was slightly modified in the Middle Ages
Middle Ages
The Middle Ages is a periodization of European history from the 5th century to the 15th century. The Middle Ages follows the fall of the Western Roman Empire in 476 and precedes the Early Modern Era. It is the middle period of a three-period division of Western history: Classic, Medieval and Modern...
to produce the system we use today. It is based on certain letters which are given values as numerals.
Roman numerals are commonly used today in numbered lists (in outline format), clockfaces, pages preceding the main body of a book, chord triads in music analysis, the numbering of movie and video game sequels, book publication dates, successive political leaders or children with identical names, and the numbering of some sport events, such as the Olympic Games
Olympic Games
The Olympic Games is a major international event featuring summer and winter sports, in which thousands of athletes participate in a variety of competitions. The Olympic Games have come to be regarded as the world’s foremost sports competition where more than 200 nations participate...
or the Super Bowl
Super Bowl
The Super Bowl is the championship game of the National Football League , the highest level of professional American football in the United States, culminating a season that begins in the late summer of the previous calendar year. The Super Bowl uses Roman numerals to identify each game, rather...
.
Roman Numerals in Unicode
UnicodeUnicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
has a number of characters specifically designated as Roman numerals, as part of the Number Forms
Number Forms
Number Forms are Unicode characters which have specific meaning as numbers, but are constructed from other characters. They consist primarily of vulgar fractions and roman numerals. They are placed in the Unicode codepoint range 0x2150 through 0x218F , except for three fractions in ISO-8859-1...
range from U+2160 to U+2188. This range includes both upper- and lowercase numerals, as well as pre-combined characters for numbers up to 12 ( or ). One reason for the existence of pre-combined numbers is to facilitate the setting of multiple-letter numbers (such as VIII) in a single "square" in Asian vertical text. Another reason is for 12-hour clock-face use.
Additionally, characters exist for archaic forms of 1000, 5000, 10,000, large reversed C , late 6 (, similar to Greek Stigma
Stigma (letter)
Stigma is a ligature of the Greek letters sigma and tau , which was used in writing Greek between the middle ages and the 19th century. It is also used as a numeral symbol for the number 6...
: ), early 50 (, similar to down arrow ), 50,000, and 100,000. Note that the small reversed c, is not intended to be used in Roman numerals, but as lower case Claudian letter ,
| Code x= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 50 | 100 | 500 | 1,000 |
| U+216x | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ | Ⅺ | Ⅻ | Ⅼ | Ⅽ | Ⅾ | Ⅿ |
| U+217x | ⅰ | ⅱ | ⅲ | ⅳ | ⅴ | ⅵ | ⅶ | ⅷ | ⅸ | ⅹ | ⅺ | ⅻ | ⅼ | ⅽ | ⅾ | ⅿ |
| Value | 1000 | 5000 | 10,000 | – | – | 6 | 50 | 50,000 | 100,000 | |||||||
| U+218x | ↀ | ↁ | ↂ | Ↄ | ↄ | ↅ | ↆ | ↇ | ↈ | |||||||
The characters in the range U+2160–217F are present only for compatibility
Unicode compatibility characters
In discussing Unicode and the UCS, many often refer to compatibility characters. Compatibility characters are graphical characters that are discouraged by the Unicode Consortium...
with other character set standards which provide these characters. For ordinary uses, the standard Latin letters are preferred. Displaying these characters requires a program that can handle Unicode and a font
Typeface
In typography, a typeface is the artistic representation or interpretation of characters; it is the way the type looks. Each type is designed and there are thousands of different typefaces in existence, with new ones being developed constantly....
that contains appropriate glyphs for them.
If using blackletter
Blackletter
Blackletter, also known as Gothic script, Gothic minuscule, or Textura, was a script used throughout Western Europe from approximately 1150 to well into the 17th century. It continued to be used for the German language until the 20th century. Fraktur is a notable script of this type, and sometimes...
or script typefaces, Roman numerals are set in Roman type
Roman type
In typography, roman is one of the three main kinds of historical type, alongside blackletter and italic. Roman type was modelled from a European scribal manuscript style of the 1400s, based on the pairing of inscriptional capitals used in ancient Rome with Carolingian minuscules developed in the...
. Such typefaces may contain Roman numerals matching the style of the typeface in the Unicode range U+2160–217F; if they don't exist, a matching Antiqua typeface is used for Roman numerals.
Counting rod numerals
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Vertical | |
|
|
|
|
|
|
|
|
|
| Horizontal | |
|
|
|
|
|
|
|
|
|
The vertical rods are usually for even powers of ten (1, 100, 10000...) and the horizontal for odd powers (10, 1000...). For example 126 is represented by
instead of , which could be confused with 36. Historically, red rods were used for positive numbers and black rods for negative numbers.