
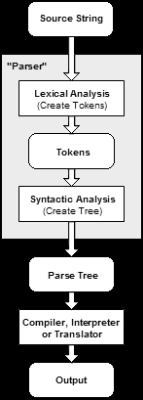
Parsing
Encyclopedia
In computer science
and linguistics
, parsing, or, more formally, syntactic analysis, is the process of analyzing a text, made of a sequence of tokens (for example, words), to determine its grammatical structure with respect to a given (more or less) formal grammar
. Parsing can also be used as a linguistic term, for instance when discussing how phrases are divided up in garden path sentence
s.
Parsing is also an earlier term for the diagramming of sentences of natural languages, and is still used for the diagramming of inflected
languages, such as the Romance languages
or Latin
. The term parsing comes from Latin pars (ōrātiōnis), meaning part (of speech).
Parsing is a common term used in psycholinguistics when describing language comprehension. In this context, parsing refers to the way that human beings, rather than computers, analyze a sentence or phrase (in spoken language or text) "in terms of grammatical constituents, identifying the parts of speech, syntactic relations, etc." This term is especially common when discussing what linguistic cues help speakers to parse garden-path sentences.
or compiler
that checks for correct syntax and builds a data structure
(often some kind of parse tree
, abstract syntax tree
or other hierarchical structure) implicit in the input tokens. The parser often uses a separate lexical analyser
to create tokens from the sequence of input characters. Parsers may be programmed by hand or may be (semi-)automatically generated (in some programming languages) by a tool.
and natural language processing
systems, human languages are parsed by computer programs. Human sentences are not easily parsed by programs, as there is substantial ambiguity
in the structure of human language, whose usage is to convey meaning (or semantics
) amongst a potentially unlimited range of possibilities but only some of which are germane to the particular case. So an utterance "Man bites dog" versus "Dog bites man" is definite on one detail but in another language might appear as "Man dog is biting" with a reliance on the larger context to distinguish between those two possibilities, if indeed that difference was of concern. It is difficult to prepare formal rules to describe informal behaviour even though it is clear that some rules are being followed.
In order to parse natural language data, researchers must first agree on the grammar
to be used. The choice of syntax is affected by both linguistic
and computational concerns; for instance some parsing systems use lexical functional grammar
, but in general, parsing for grammars of this type is known to be NP-complete
. Head-driven phrase structure grammar
is another linguistic formalism which has been popular in the parsing community, but other research efforts have focused on less complex formalisms such as the one used in the Penn Treebank
. Shallow parsing
aims to find only the boundaries of major constituents such as noun phrases. Another popular strategy for avoiding linguistic controversy is dependency grammar
parsing.
Most modern parsers are at least partly statistical
; that is, they rely on a corpus of training data which has already been annotated (parsed by hand). This approach allows the system to gather information about the frequency with which various constructions occur in specific contexts. (See machine learning
.) Approaches which have been used include straightforward PCFGs (probabilistic context free grammars), maximum entropy, and neural nets. Most of the more successful systems use lexical statistics (that is, they consider the identities of the words involved, as well as their part of speech). However such systems are vulnerable to overfitting
and require some kind of smoothing
to be effective.
Parsing algorithms for natural language cannot rely on the grammar having 'nice' properties as with manually-designed grammars for programming languages. As mentioned earlier some grammar formalisms are very difficult to parse computationally; in general, even if the desired structure is not context-free, some kind of context-free approximation to the grammar is used to perform a first pass. Algorithms which use context-free grammars often rely on some variant of the CKY algorithm, usually with some heuristic to prune away unlikely analyses to save time. (See chart parsing.) However some systems trade speed for accuracy using, e.g., linear-time versions of the shift-reduce algorithm. A somewhat recent development has been parse reranking in which the parser proposes some large number of analyses, and a more complex system selects the best option.
or interpreter
. This parses the source code
of a computer programming language to create some form of internal representation. Programming languages tend to be specified in terms of a context-free grammar
because fast and efficient parsers can be written for them. Parsers are written by hand or generated by parser generators.
Context-free grammars are limited in the extent to which they can express all of the requirements of a language. Informally, the reason is that the memory of such a language is limited. The grammar cannot remember the presence of a construct over an arbitrarily long input; this is necessary for a language in which, for example, a name must be declared before it may be referenced. More powerful grammars that can express this constraint, however, cannot be parsed efficiently. Thus, it is a common strategy to create a relaxed parser for a context-free grammar which accepts a superset of the desired language constructs (that is, it accepts some invalid constructs); later, the unwanted constructs can be filtered out.
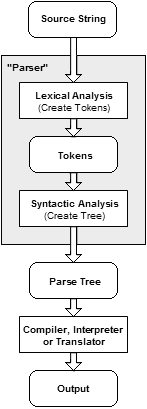 The following example demonstrates the common case of parsing a computer language with two levels of grammar: lexical and syntactic.
The following example demonstrates the common case of parsing a computer language with two levels of grammar: lexical and syntactic.
The first stage is the token generation, or lexical analysis
, by which the input character stream is split into meaningful symbols defined by a grammar of regular expression
s. For example, a calculator program would look at an input such as "
The next stage is parsing or syntactic analysis, which is checking that the tokens form an allowable expression. This is usually done with reference to a context-free grammar
which recursively defines components that can make up an expression and the order in which they must appear. However, not all rules defining programming languages can be expressed by context-free grammars alone, for example type validity and proper declaration of identifiers. These rules can be formally expressed with attribute grammar
s.
The final phase is semantic parsing or analysis, which is working out the implications of the expression just validated and taking the appropriate action. In the case of a calculator or interpreter, the action is to evaluate the expression or program, a compiler, on the other hand, would generate some kind of code. Attribute grammars can also be used to define these actions.
LL parser
s and recursive-descent parser are examples of top-down parsers which cannot accommodate left recursive
productions. Although it has been believed that simple implementations of top-down parsing cannot accommodate direct and indirect left-recursion and may require exponential time and space complexity while parsing ambiguous context-free grammar
s, more sophisticated algorithms for top-down parsing have been created by Frost, Hafiz, and Callaghan which accommodate ambiguity
and left recursion
in polynomial time and which generate polynomial-size representations of the potentially-exponential number of parse trees. Their algorithm is able to produce both left-most and right-most derivations of an input with regard to a given CFG
.
An important distinction with regard to parsers is whether a parser generates a leftmost derivation or a rightmost derivation (see context-free grammar
). LL parsers will generate a leftmost derivation
and LR parsers will generate a rightmost derivation (although usually in reverse).
include:
include:
.
Computer science
Computer science or computing science is the study of the theoretical foundations of information and computation and of practical techniques for their implementation and application in computer systems...
and linguistics
Linguistics
Linguistics is the scientific study of human language. Linguistics can be broadly broken into three categories or subfields of study: language form, language meaning, and language in context....
, parsing, or, more formally, syntactic analysis, is the process of analyzing a text, made of a sequence of tokens (for example, words), to determine its grammatical structure with respect to a given (more or less) formal grammar
Formal grammar
A formal grammar is a set of formation rules for strings in a formal language. The rules describe how to form strings from the language's alphabet that are valid according to the language's syntax...
. Parsing can also be used as a linguistic term, for instance when discussing how phrases are divided up in garden path sentence
Garden path sentence
A garden path sentence is a grammatically correct sentence that starts in such a way that the readers' most likely interpretation will be incorrect; they are lured into an improper parse that turns out to be a dead end. Garden path sentences are used in psycholinguistics to illustrate the fact that...
s.
Parsing is also an earlier term for the diagramming of sentences of natural languages, and is still used for the diagramming of inflected
Inflection
In grammar, inflection or inflexion is the modification of a word to express different grammatical categories such as tense, grammatical mood, grammatical voice, aspect, person, number, gender and case...
languages, such as the Romance languages
Romance languages
The Romance languages are a branch of the Indo-European language family, more precisely of the Italic languages subfamily, comprising all the languages that descend from Vulgar Latin, the language of ancient Rome...
or Latin
Latin
Latin is an Italic language originally spoken in Latium and Ancient Rome. It, along with most European languages, is a descendant of the ancient Proto-Indo-European language. Although it is considered a dead language, a number of scholars and members of the Christian clergy speak it fluently, and...
. The term parsing comes from Latin pars (ōrātiōnis), meaning part (of speech).
Parsing is a common term used in psycholinguistics when describing language comprehension. In this context, parsing refers to the way that human beings, rather than computers, analyze a sentence or phrase (in spoken language or text) "in terms of grammatical constituents, identifying the parts of speech, syntactic relations, etc." This term is especially common when discussing what linguistic cues help speakers to parse garden-path sentences.
Parser
In computing, a parser is one of the components in an interpreterInterpreter (computing)
In computer science, an interpreter normally means a computer program that executes, i.e. performs, instructions written in a programming language...
or compiler
Compiler
A compiler is a computer program that transforms source code written in a programming language into another computer language...
that checks for correct syntax and builds a data structure
Data structure
In computer science, a data structure is a particular way of storing and organizing data in a computer so that it can be used efficiently.Different kinds of data structures are suited to different kinds of applications, and some are highly specialized to specific tasks...
(often some kind of parse tree
Parse tree
A concrete syntax tree or parse tree or parsing treeis an ordered, rooted tree that represents the syntactic structure of a string according to some formal grammar. In a parse tree, the interior nodes are labeled by non-terminals of the grammar, while the leaf nodes are labeled by terminals of the...
, abstract syntax tree
Abstract syntax tree
In computer science, an abstract syntax tree , or just syntax tree, is a tree representation of the abstract syntactic structure of source code written in a programming language. Each node of the tree denotes a construct occurring in the source code. The syntax is 'abstract' in the sense that it...
or other hierarchical structure) implicit in the input tokens. The parser often uses a separate lexical analyser
Lexical analysis
In computer science, lexical analysis is the process of converting a sequence of characters into a sequence of tokens. A program or function which performs lexical analysis is called a lexical analyzer, lexer or scanner...
to create tokens from the sequence of input characters. Parsers may be programmed by hand or may be (semi-)automatically generated (in some programming languages) by a tool.
Human languages
In some machine translationMachine translation
Machine translation, sometimes referred to by the abbreviation MT is a sub-field of computational linguistics that investigates the use of computer software to translate text or speech from one natural language to another.On a basic...
and natural language processing
Natural language processing
Natural language processing is a field of computer science and linguistics concerned with the interactions between computers and human languages; it began as a branch of artificial intelligence....
systems, human languages are parsed by computer programs. Human sentences are not easily parsed by programs, as there is substantial ambiguity
Syntactic ambiguity
Syntactic ambiguity is a property of sentences which may be reasonably interpreted in more than one way, or reasonably interpreted to mean more than one thing...
in the structure of human language, whose usage is to convey meaning (or semantics
Semantics
Semantics is the study of meaning. It focuses on the relation between signifiers, such as words, phrases, signs and symbols, and what they stand for, their denotata....
) amongst a potentially unlimited range of possibilities but only some of which are germane to the particular case. So an utterance "Man bites dog" versus "Dog bites man" is definite on one detail but in another language might appear as "Man dog is biting" with a reliance on the larger context to distinguish between those two possibilities, if indeed that difference was of concern. It is difficult to prepare formal rules to describe informal behaviour even though it is clear that some rules are being followed.
In order to parse natural language data, researchers must first agree on the grammar
Grammar
In linguistics, grammar is the set of structural rules that govern the composition of clauses, phrases, and words in any given natural language. The term refers also to the study of such rules, and this field includes morphology, syntax, and phonology, often complemented by phonetics, semantics,...
to be used. The choice of syntax is affected by both linguistic
Language
Language may refer either to the specifically human capacity for acquiring and using complex systems of communication, or to a specific instance of such a system of complex communication...
and computational concerns; for instance some parsing systems use lexical functional grammar
Lexical functional grammar
Lexical functional grammar is a grammar framework in theoretical linguistics, a variety of generative grammar. It is a type of phrase structure grammar, as opposed to a dependency grammar. The development of the theory was initiated by Joan Bresnan and Ronald Kaplan in the 1970s, in reaction to...
, but in general, parsing for grammars of this type is known to be NP-complete
NP-complete
In computational complexity theory, the complexity class NP-complete is a class of decision problems. A decision problem L is NP-complete if it is in the set of NP problems so that any given solution to the decision problem can be verified in polynomial time, and also in the set of NP-hard...
. Head-driven phrase structure grammar
Head-driven phrase structure grammar
Head-driven phrase structure grammar is a highly lexicalized, non-derivational generative grammar theory developed by Carl Pollard and Ivan Sag. It is the immediate successor to generalized phrase structure grammar. HPSG draws from other fields such as computer science and uses Ferdinand de...
is another linguistic formalism which has been popular in the parsing community, but other research efforts have focused on less complex formalisms such as the one used in the Penn Treebank
Treebank
A treebank or parsed corpus is a text corpus in which each sentence has been parsed, i.e. annotated with syntactic structure. Syntactic structure is commonly represented as a tree structure, hence the name Treebank...
. Shallow parsing
Shallow parsing
Shallow parsing is an analysis of a sentence which identifies the constituents , but does not specify their internal structure, nor their role in the main sentence....
aims to find only the boundaries of major constituents such as noun phrases. Another popular strategy for avoiding linguistic controversy is dependency grammar
Dependency grammar
Dependency grammar is a class of modern syntactic theories that are all based on the dependency relation and that can be traced back primarily to the work of Lucien Tesnière. Dependency grammars are distinct from phrase structure grammars , since they lack phrasal nodes. Structure is determined by...
parsing.
Most modern parsers are at least partly statistical
Statistics
Statistics is the study of the collection, organization, analysis, and interpretation of data. It deals with all aspects of this, including the planning of data collection in terms of the design of surveys and experiments....
; that is, they rely on a corpus of training data which has already been annotated (parsed by hand). This approach allows the system to gather information about the frequency with which various constructions occur in specific contexts. (See machine learning
Machine learning
Machine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
.) Approaches which have been used include straightforward PCFGs (probabilistic context free grammars), maximum entropy, and neural nets. Most of the more successful systems use lexical statistics (that is, they consider the identities of the words involved, as well as their part of speech). However such systems are vulnerable to overfitting
Overfitting
In statistics, overfitting occurs when a statistical model describes random error or noise instead of the underlying relationship. Overfitting generally occurs when a model is excessively complex, such as having too many parameters relative to the number of observations...
and require some kind of smoothing
Smoothing
In statistics and image processing, to smooth a data set is to create an approximating function that attempts to capture important patterns in the data, while leaving out noise or other fine-scale structures/rapid phenomena. Many different algorithms are used in smoothing...
to be effective.
Parsing algorithms for natural language cannot rely on the grammar having 'nice' properties as with manually-designed grammars for programming languages. As mentioned earlier some grammar formalisms are very difficult to parse computationally; in general, even if the desired structure is not context-free, some kind of context-free approximation to the grammar is used to perform a first pass. Algorithms which use context-free grammars often rely on some variant of the CKY algorithm, usually with some heuristic to prune away unlikely analyses to save time. (See chart parsing.) However some systems trade speed for accuracy using, e.g., linear-time versions of the shift-reduce algorithm. A somewhat recent development has been parse reranking in which the parser proposes some large number of analyses, and a more complex system selects the best option.
Programming languages
The most common use of a parser is as a component of a compilerCompiler
A compiler is a computer program that transforms source code written in a programming language into another computer language...
or interpreter
Interpreter (computing)
In computer science, an interpreter normally means a computer program that executes, i.e. performs, instructions written in a programming language...
. This parses the source code
Source code
In computer science, source code is text written using the format and syntax of the programming language that it is being written in. Such a language is specially designed to facilitate the work of computer programmers, who specify the actions to be performed by a computer mostly by writing source...
of a computer programming language to create some form of internal representation. Programming languages tend to be specified in terms of a context-free grammar
Context-free grammar
In formal language theory, a context-free grammar is a formal grammar in which every production rule is of the formwhere V is a single nonterminal symbol, and w is a string of terminals and/or nonterminals ....
because fast and efficient parsers can be written for them. Parsers are written by hand or generated by parser generators.
Context-free grammars are limited in the extent to which they can express all of the requirements of a language. Informally, the reason is that the memory of such a language is limited. The grammar cannot remember the presence of a construct over an arbitrarily long input; this is necessary for a language in which, for example, a name must be declared before it may be referenced. More powerful grammars that can express this constraint, however, cannot be parsed efficiently. Thus, it is a common strategy to create a relaxed parser for a context-free grammar which accepts a superset of the desired language constructs (that is, it accepts some invalid constructs); later, the unwanted constructs can be filtered out.
Overview of process
The first stage is the token generation, or lexical analysis
Lexical analysis
In computer science, lexical analysis is the process of converting a sequence of characters into a sequence of tokens. A program or function which performs lexical analysis is called a lexical analyzer, lexer or scanner...
, by which the input character stream is split into meaningful symbols defined by a grammar of regular expression
Regular expression
In computing, a regular expression provides a concise and flexible means for "matching" strings of text, such as particular characters, words, or patterns of characters. Abbreviations for "regular expression" include "regex" and "regexp"...
s. For example, a calculator program would look at an input such as "
12*(3+4)^2" and split it into the tokens 12, *, (, 3, +, 4, ), ^, 2, each of which is a meaningful symbol in the context of an arithmetic expression. The lexer would contain rules to tell it that the characters *, +, ^, ( and ) mark the start of a new token, so meaningless tokens like "12*" or "(3" will not be generated.The next stage is parsing or syntactic analysis, which is checking that the tokens form an allowable expression. This is usually done with reference to a context-free grammar
Context-free grammar
In formal language theory, a context-free grammar is a formal grammar in which every production rule is of the formwhere V is a single nonterminal symbol, and w is a string of terminals and/or nonterminals ....
which recursively defines components that can make up an expression and the order in which they must appear. However, not all rules defining programming languages can be expressed by context-free grammars alone, for example type validity and proper declaration of identifiers. These rules can be formally expressed with attribute grammar
Attribute grammar
An attribute grammar is a formal way to define attributes for the productions of a formal grammar, associating these attributes to values. The evaluation occurs in the nodes of the abstract syntax tree, when the language is processed by some parser or compiler....
s.
The final phase is semantic parsing or analysis, which is working out the implications of the expression just validated and taking the appropriate action. In the case of a calculator or interpreter, the action is to evaluate the expression or program, a compiler, on the other hand, would generate some kind of code. Attribute grammars can also be used to define these actions.
Types of parser
The task of the parser is essentially to determine if and how the input can be derived from the start symbol of the grammar. This can be done in essentially two ways:- Top-down parsingTop-down parsingTop-down parsing is a type of parsing strategy where in one first looks at the highest level of the parse tree and works down the parse tree by using the rewriting rules of a formal grammar...
- Top-down parsing can be viewed as an attempt to find left-most derivations of an input-stream by searching for parse treeParse treeA concrete syntax tree or parse tree or parsing treeis an ordered, rooted tree that represents the syntactic structure of a string according to some formal grammar. In a parse tree, the interior nodes are labeled by non-terminals of the grammar, while the leaf nodes are labeled by terminals of the...
s using a top-down expansion of the given formal grammarFormal grammarA formal grammar is a set of formation rules for strings in a formal language. The rules describe how to form strings from the language's alphabet that are valid according to the language's syntax...
rules. Tokens are consumed from left to right. Inclusive choice is used to accommodate ambiguityAmbiguityAmbiguity of words or phrases is the ability to express more than one interpretation. It is distinct from vagueness, which is a statement about the lack of precision contained or available in the information.Context may play a role in resolving ambiguity...
by expanding all alternative right-hand-sides of grammar rules. - Bottom-up parsingBottom-up parsingBottom-up parsing is a strategy for analyzing unknown information that attempts to identify the most fundamental units first, and then to infer higher-order structures from them...
- A parser can start with the input and attempt to rewrite it to the start symbol. Intuitively, the parser attempts to locate the most basic elements, then the elements containing these, and so on. LR parserLR parserIn computer science, an LR parser is a parser that reads input from Left to right and produces a Rightmost derivation. The term LR parser is also used; where the k refers to the number of unconsumed "look ahead" input symbols that are used in making parsing decisions...
s are examples of bottom-up parsers. Another term used for this type of parser is Shift-Reduce parsing.
LL parser
LL parser
An LL parser is a top-down parser for a subset of the context-free grammars. It parses the input from Left to right, and constructs a Leftmost derivation of the sentence...
s and recursive-descent parser are examples of top-down parsers which cannot accommodate left recursive
Left recursion
In computer science, left recursion is a special case of recursion.In terms of context-free grammar, a non-terminal r is left-recursive if the left-most symbol in any of r’s ‘alternatives’ either immediately or through some other non-terminal definitions rewrites to r again.- Definition :"A...
productions. Although it has been believed that simple implementations of top-down parsing cannot accommodate direct and indirect left-recursion and may require exponential time and space complexity while parsing ambiguous context-free grammar
Context-free grammar
In formal language theory, a context-free grammar is a formal grammar in which every production rule is of the formwhere V is a single nonterminal symbol, and w is a string of terminals and/or nonterminals ....
s, more sophisticated algorithms for top-down parsing have been created by Frost, Hafiz, and Callaghan which accommodate ambiguity
Ambiguity
Ambiguity of words or phrases is the ability to express more than one interpretation. It is distinct from vagueness, which is a statement about the lack of precision contained or available in the information.Context may play a role in resolving ambiguity...
and left recursion
Left recursion
In computer science, left recursion is a special case of recursion.In terms of context-free grammar, a non-terminal r is left-recursive if the left-most symbol in any of r’s ‘alternatives’ either immediately or through some other non-terminal definitions rewrites to r again.- Definition :"A...
in polynomial time and which generate polynomial-size representations of the potentially-exponential number of parse trees. Their algorithm is able to produce both left-most and right-most derivations of an input with regard to a given CFG
Context-free grammar
In formal language theory, a context-free grammar is a formal grammar in which every production rule is of the formwhere V is a single nonterminal symbol, and w is a string of terminals and/or nonterminals ....
.
An important distinction with regard to parsers is whether a parser generates a leftmost derivation or a rightmost derivation (see context-free grammar
Context-free grammar
In formal language theory, a context-free grammar is a formal grammar in which every production rule is of the formwhere V is a single nonterminal symbol, and w is a string of terminals and/or nonterminals ....
). LL parsers will generate a leftmost derivation
Derivation
Derivation may refer to:* Derivation , a function on an algebra which generalizes certain features of the derivative operator* Derivation * Derivation in differential algebra, a unary function satisfying the Leibniz product law...
and LR parsers will generate a rightmost derivation (although usually in reverse).
Top-down parsers
Some of the parsers that use top-down parsingTop-down parsing
Top-down parsing is a type of parsing strategy where in one first looks at the highest level of the parse tree and works down the parse tree by using the rewriting rules of a formal grammar...
include:
- Recursive descent parserRecursive descent parserA recursive descent parser is a top-down parser built from a set of mutually-recursive procedures where each such procedure usually implements one of the production rules of the grammar...
- LL parserLL parserAn LL parser is a top-down parser for a subset of the context-free grammars. It parses the input from Left to right, and constructs a Leftmost derivation of the sentence...
(Left-to-right, Leftmost derivation) - Earley parserEarley parserIn computer science, the Earley parser is an algorithm for parsing strings that belong to a given context-free language, named after its inventor, Jay Earley...
- X-SAIGA - eXecutable SpecificAtIons of GrAmmars. Contains publications related to top-down parsing algorithm that supports left-recursion and ambiguity in polynomial time and space.
Bottom-up parsers
Some of the parsers that use bottom-up parsingBottom-up parsing
Bottom-up parsing is a strategy for analyzing unknown information that attempts to identify the most fundamental units first, and then to infer higher-order structures from them...
include:
- Precedence parser
- Operator-precedence parserOperator-precedence parserAn operator precedence parser is a bottom-up parser that interprets an operator-precedence grammar. For example, most calculators use operator precedence parsers to convert from the human-readable infix notation with order of operations format into an internally optimized computer-readable format...
- Simple precedence parserSimple precedence parserIn computer science, a Simple precedence parser is a type of bottom-up parser for context-free grammars that can be used only by Simple precedence grammars....
- Operator-precedence parser
- BC (bounded context) parsing
- LR parserLR parserIn computer science, an LR parser is a parser that reads input from Left to right and produces a Rightmost derivation. The term LR parser is also used; where the k refers to the number of unconsumed "look ahead" input symbols that are used in making parsing decisions...
(Left-to-right, Rightmost derivation)- Simple LR (SLR) parser
- LALR parserLALR parserIn computer science, an LALR parser is a type of LR parser based on a finite-state-automata concept. The data structure used by an LALR parser is a pushdown automaton...
- Canonical LR (LR(1)) parserCanonical LR parserA canonical LR parser or LR parser is an LR parser whose parsing tables are constructed in a similar way as with LR parsers except that the items in the item sets also contain a lookahead, i.e., a terminal that is expected by the parser after the right-hand side of the rule...
- GLR parserGLR parserA GLR parser is an extension of an LR parser algorithm to handle nondeterministic and ambiguous grammars. First described in a 1984 paper by Masaru Tomita, it has also been referred to as a "parallel parser"...
- CYK parserCYK algorithmThe Cocke–Younger–Kasami algorithm is a parsing algorithm for context-free grammars. It employs bottom-up parsing and dynamic programming....
Parser development software
Some of the well known parser development tools include the following. Also see comparison of parser generatorsComparison of parser generators
This is a list of notable lexer generators and parser generators for various language classes.- Regular languages :- Deterministic context-free languages :-Parsing expression grammars, deterministic boolean grammars:...
.
See also
- LALR parserLALR parserIn computer science, an LALR parser is a type of LR parser based on a finite-state-automata concept. The data structure used by an LALR parser is a pushdown automaton...
- BacktrackingBacktrackingBacktracking is a general algorithm for finding all solutions to some computational problem, that incrementally builds candidates to the solutions, and abandons each partial candidate c as soon as it determines that c cannot possibly be completed to a valid solution.The classic textbook example...
- Lexing
- Chart parserChart parserA chart parser is a type of parser suitable for ambiguous grammars . It uses the dynamic programming approach—partial hypothesized results are stored in a structure called a chart and can be re-used...
- Compiler-compilerCompiler-compilerA compiler-compiler or compiler generator is a tool that creates a parser, interpreter, or compiler from some form of formal description of a language and machine...
- Deterministic parsingDeterministic parsingIn natural language processing, deterministic parsing refers to parsing algorithms that do not back up. LR-parsers are an example....
- Generating stringsGenerating stringsIn computer science generating strings is one of the names given to the process of creating a set of strings from some collection of rules. This is the opposite process to that used when parsing, which recognises a string based on some collection of rules....
- Grammar checkerGrammar checkerA grammar checker in computing terms, is a program, or part of a program, that attempts to verify written text for grammatical correctness. Grammar checkers are most often implemented as a feature of a larger program, such as a word processor, but are also available as stand-alone application that...
- Shallow parsingShallow parsingShallow parsing is an analysis of a sentence which identifies the constituents , but does not specify their internal structure, nor their role in the main sentence....
Further reading
- Chapman, Nigel P., LR Parsing: Theory and Practice, Cambridge University PressCambridge University PressCambridge University Press is the publishing business of the University of Cambridge. Granted letters patent by Henry VIII in 1534, it is the world's oldest publishing house, and the second largest university press in the world...
, 1987. ISBN 0-521-30413-X - Grune, Dick; Jacobs, Ceriel J.H., Parsing Techniques - A Practical Guide, Vrije Universiteit Amsterdam, Amsterdam, The Netherlands. Originally published by Ellis Horwood, Chichester, England, 1990; ISBN 0-13-651431-6