

Reliability engineering
Encyclopedia
Reliability engineering is an engineering
field, that deals with the study, evaluation, and life-cycle management
of reliability: the ability of a system
or component to perform its required functions under stated conditions for a specified period of time. It is often measured as a probability
of failure or a measure of availability
. However, maintainability
is also an important part of reliability engineering.
Reliability engineering for complex systems requires a different, more elaborated systems approach than reliability for non-complex systems / items. Reliability engineering is closely related to system safety engineering
in the sense that they both use common sorts of methods for their analysis and might require input from each other. Reliability analysis have important links with function analysis, requirements specification, systems design, hardware design, software design, manufacturing
, testing, maintenance, transport, storage, spare parts, operations research
, human factors, technical documentation, training and more.
Most industries do not have specialized reliability engineers and the engineering task often becomes part of the tasks of a design engineer, logistics engineer, systems engineer or quality engineer. Reliability engineers should have broad skills and knowledge.
 Reliability may be defined in several ways:
Reliability may be defined in several ways:
Reliability engineering is a special discipline within Systems engineering
. Reliability engineers rely heavily on statistics
, probability theory
, and reliability theory
to set requirements, measure or predict reliability and advice on improvements for reliability performance. Many engineering techniques are used in reliability engineering, such as Reliability Hazard analysis
, Failure mode and effects analysis
(FMEA), Fault tree analysis
, Reliability Prediction, Weibull analysis, thermal management, reliability testing and accelerated life testing
. Because of the large number of reliability techniques, their expense, and the varying degrees of reliability required for different situations, most projects develop a reliability program plan to specify the reliability tasks that will be performed for that specific system.
The function of reliability engineering is to develop the reliability requirements for the product, establish an adequate life-cycle reliability program, show that corrective measures (risk mitigations) produce reliability improvements, and perform appropriate analyses and tasks to ensure the product will meet its requirements and the unreliability risk is controlled to an acceptable level. It needs to provide a robust set of (statistical) evidence and justification material to verify if the requirements have been met and to check preliminary reliability risk assessments. The goal is to first identify the reliability hazards, assess the risk associated with them and to control the risk to an acceptable level. What is acceptable is determined by the managing authority / customers. These tasks are normally managed by a reliability engineer or manager, who may hold an accredited engineering degree and has additional reliability-specific education and training.
Reliability engineering is closely associated with maintainability engineering and logistics engineering
, e.g. Integrated Logistics Support
(ILS). Many problems from other fields, such as security engineering
and safety engineering
can also be approached using common reliability engineering techniques. This article provides an overview of some of the most common reliability engineering tasks. Please see the references for a more comprehensive treatment.
Many types of engineering
employ reliability engineers and use the tools and methodology of reliability engineering. For example:
, failure rate
.
Reliability theory is the foundation of reliability engineering. For engineering purposes, reliability is defined as:
Mathematically, this may be expressed as,
Reliability engineering is concerned with four key elements of this definition:
with respect to the kind of hazards that are considered. Reliability engineering is in the end only concerned with cost. It relates to hazards that could transform into a particular level of loss of revenue for the company or the customer. These can be cost due to loss of production due to system unavailability, unexpected high or low demands for spares, repair costs, man hours, (multiple) re-designs, interruptions on normal production (e.g. due to high repair times or due to unexpected demands for non-stocked spares) and many other indirect costs. Safety engineering, on the other hand, is more specific and regulated. The related reliability Requirements are sometimes extremely high. It deals with unwanted dangerous events (for life and environment) in the same sense as reliability engineering, but does normally not directly look at cost and is not concerned with repair actions after failure. Another difference is the level of impact of failures on society and the control of governments. Safety engineering is often strictly controlled by governments (e.g. Nuclear, Aerospace, Defense, Rail and Oil industries). Furthermore, safety engineering and reliability engineering often have contradicting requirements. For example, in train control systems it is common practice to use many fail-safe devices and to lower trip settings as needed. This will unfortunately lower the reliability. Reliability can be increased here by using redundant systems, this does however lower the safety levels. The only way to increase both reliability and safety on a systems level is by using fault tolerant systems. In this case the "operational" / "mission" reliability as well as the safety of a system can be increased. This is common practice in aerospace systems that need continues availability and do not have a fail safe mode (e.g. flight computers and related steering systems). However, the "basic" reliability of the system will in this case still be lower. Basic reliability refers to failures that might not result in system failure, but do result in maintenance actions, logistic cost, use of spares, etc.
must operate under a wide range of conditions. The consequences of failure are grave, but there is a correspondingly higher budget. A pencil sharpener may be more reliable than an airliner, but has a much different set of operational conditions, insignificant consequences of failure, and a much lower budget.
A reliability program plan (RPP) is used to document exactly what "best practices" (tasks, methods, tools, analyses, and tests) are required for a particular (sub)system, as well as clarify customer requirements for reliability assessment. For large scale, complex systems, the Reliability Program Plan is a distinctive document
. For simple systems, it may be combined with the systems engineering
management plan or an integrated logistics support
management plan. A reliability program plan is essential for a successful reliability, availability
, and maintainability
(RAM) program and is developed early during system development, and refined over the systems life-cycle. It specifies not only what the reliability engineer does, but also the tasks performed by other stakeholders. A reliability program plan is approved by top program management, who is responsible for identifying resources for its implementation.
Technically, often, the main objective of a Reliability Program Plan is to evaluate and improve availability
of a system and not reliability. Reliability needs to be evaluated and improved related to both availability and the cost of ownership (due to spares costing, maintenance man-hours, transport etc. costs). Often a trade-off is needed between the two. There might be a maximum ratio between availability and cost of ownership. If availability or Cost of Ownership is more important depends on the use of the system (e.g. a system that is a critical link in a production system - for example a big oil platform - is normally allowed to have a very high cost of ownership if this translates to even a minor higher availability as the unavailability of the platform directly results in a massive loss of revenue). Testability of a system should also be addressed in the plan as this is the link between reliability and maintainability. The maintenance (the maintenance concept / strategy) can influence the reliability of a system (e.g. by preventive maintenance) - although it can never bring it above the inherent reliability. Maintainability influences the availability of a system - in theory this can be almost unlimited if one would be able to repair a failure in a very short time.
A proper reliability plan should normally always address RAMT analysis in its total context. RAMT stands in this case for Reliability, Availability, Maintainability (and maintenance) and Testability in context to users needs to the technical requirements (as translated from the needs).
needs. Reliability requirements address the system itself, test and assessment requirements, and associated tasks and documentation. Reliability requirements are included in the appropriate system/subsystem requirements specifications, test plans, and contract statements. Maintainability requirements address system issue of costs as well as time to repair. Evaluation of the effectiveness of corrective measures is part of a FRACAS
process that is usually part of a good RPP.
Some recognized authors on reliability - e.g. Patrick O'Conner, R. Barnard and others - have argued that too many emphasis is often given to the prediction of reliability parameters and more effort should be devoted to prevention of failure. The reason for this is that prediction of reliability based on historic data can be very misleading, because a comparison is only valid for exactly the same designs, products under exactly the same loads / context. Even a minor change in detail in any of these could have major effects on reliability. Furthermore, normally the most unreliable and important items (most interesting candidates for a reliability investigation) are most often subjected to many modifications and changes. Also, to perform a proper quantitative reliability prediction for systems is extremely difficult and expensive if done by testing. On part level results can be obtained often with higher confidence as many samples might be used for the available testing financial budget, however unfortunately these tests might lack validity on system level due to the assumptions that had to be made for part level testing. Testing for reliability should be done to create failures, learn from them and to improve the system / part. The general conclusion is drawn that an accurate and an absolute prediction - by field data comparison or testing - of reliability is in most cases not possible. A exception might be failures due to wear-out problems like fatigue failures. Mil. Std. 785 writes in its introduction that reliability prediction should be used with great caution if not only used for comparison in trade-off studies.
Furthermore, based on latest insights in Reliability centered maintenance
(RCM), most (complex) system failures do no occur due to wear-out issues (e.g. a number of 4% has been provided, refer to RCM page). The failures are often a result of combinations of more and multi-type events or failures. The results of these studies have shown that the majority of failures follow a constant failure rate model, for which prediction of the value of the parameters is often problematic and very time consuming (for a high level reliability - part level). Testing these constant failure rates at system level, by for example mil. handbook 781 type of testing, is not practical and can be extremely misleading.
Despite all the concerns, there will always be a need for the prediction of reliability. These numbers can be used as a Key performance indicator (KPI) or to estimate the need for spares, man-power, availability of systems, etc.
Reliability predictions:
The telecommunications industry has devoted much time over the years to concentrate on developing reliability models for electronic equipment. One such tool is the Automated Reliability Prediction Procedure (ARPP), which is an Excel-spreadsheet software tool that automates the reliability prediction procedures in SR-332, Reliability Prediction Procedure for Electronic Equipment. FD-ARPP-01 provides suppliers and manufacturers with a tool for making Reliability Prediction Procedure (RPP) calculations. It also provides a means for understanding RPP calculations through the capability of interactive examples provided by the user.
The RPP views electronic systems as hierarchical assemblies. Systems are constructed from units that, in turn, are constructed from devices. The methods presented predict reliability at these three hierarchical levels:
s. The most common reliability parameter is the mean time to failure
(MTTF), which can also be specified as the failure rate
(this is expressed as a frequency or Conditional Probability Density Function (PDF)) or the number of failures during a given period. These parameters are very useful for systems that are operated frequently, such as most vehicle
s, machinery, and electronic
equipment. Reliability increases as the MTTF increases. The MTTF is usually specified in hours, but can also be used with other units of measurement such as miles or cycles.
In other cases, reliability is specified as the probability of mission success. For example, reliability of a scheduled aircraft flight can be specified as a dimensionless probability or a percentage. as in system safety
engineering.
A special case of mission success is the single-shot device or system. These are devices or systems that remain relatively dormant and only operate once. Examples include automobile airbags, thermal batteries
and missiles. Single-shot reliability is specified as a probability of one-time success, or is subsumed into a related parameter. Single-shot missile reliability may be specified as a requirement
for the probability of hit.
For such systems, the probability of failure on demand (PFD)
is the reliability measure
- which actually is a unavailability number. This PFD is derived from failure rate (a frequency of occurrence) and mission time for non-repairable systems. For repairable systems, it is obtained from failure rate and mean-time-to-repair (MTTR) and test interval. This measure may not be unique for a given system as this measure depends on the kind of demand.
In addition to system level requirements, reliability requirements may be specified for critical subsystems. In most cases, reliability parameters are specified with appropriate statistical confidence interval
s.
For part level predictions, two separate fields of investigation are common:
Software reliability is a more challenging area that must be considered when it is a considerable component to system functionality.
For systems with a clearly defined failure time (which is sometimes not given for systems with a drifting parameter), the empirical distribution function
of these failure times can be determined. This is done in general in an experiment with increased (or accelerated) stress. These experiments can be divided into two main categories:
In a study of the intrinsic failure distribution, which is often a material property, higher (material) stresses are necessary to get failure in a reasonable period of time. Several degrees of stress have to be applied to determine an acceleration model. The empirical failure distribution is often parametrized with a Weibull or a log-normal model.
It is a general praxis to model the early (hardware) failure rate with an exponential distribution. This less complex model for the failure distribution has only one parameter: the constant failure rate. In such cases, the Chi-squared distribution can be used to find the goodness of fit
for the estimated failure rate. Compared to a model with a decreasing failure rate, this is quite pessimistic (important remark: this is not the case if less hours / load cycles are tested than service life in a wear-out type of test, in this case the opposite is true and assuming a more constant failure rate than it is in reality can be dangerous). Sensitivity analysis should be conducted in this case.
Reliability engineering is used to design a realistic and affordable test program that provides enough evidence that the system meets its reliability requirements. Statistical confidence levels
are used to address some of these concerns. A certain parameter is expressed along with a corresponding confidence level: for example, an MTBF of 1000 hours at 90% confidence level. From this specification, the reliability engineer can for example design a test with explicit criteria for the number of hours and number of failures until the requirement is met or failed. Other type tests are also possible.
The combination of reliability parameter value and confidence level greatly affects the development cost and the risk to both the customer and producer. Care is needed to select the best combination of requirements - e.g. cost-effectiveness. Reliability testing may be performed at various levels, such as component, subsystem, and system
. Also, many factors must be addressed during testing and operation, such as extreme temperature and humidity, shock, vibration, or other environmental factors (like loss of signal, cooling or power; or other catastrophes such as fire, floods, excessive heat, physical or security violations or other myriad forms of damage or degradation). Reliability engineering must assess the root cause of failures and devise corrective actions. Reliability engineering determines an effective test strategy
so that all parts are exercised in relevant environments in order to assure the best possible reliability under understood conditions. For systems that must last many years, reliability engineering may be used to design accelerated life tests.
Failure reporting analysis and corrective action systems are a common approach for product/process reliability monitoring.
in products, towards a objective of improved availability
, lower sustainment costs, and maximum product utilization or lifetime. Typically, the first step in the DFR process is to establish the system’s availability requirements. Reliability must be "designed in" to the system. During system design
, the top-level reliability requirements are then allocated to subsystems by design engineers, maintainers, and reliability engineers working together.
Reliability design begins with the development of a (system) model
. Reliability models use block diagrams and fault trees to provide a graphical means of evaluating the relationships between different parts of the system. These models incorporate predictions based on parts-count failure rates taken from historical data. While the (input data) predictions are often not accurate in an absolute sense, they are valuable to assess relative differences in design alternatives.
 One of the most important design techniques is redundancy
One of the most important design techniques is redundancy
. This means that if one part of the system fails, there is an alternate success path, such as a backup system. The reason why this is the ultimate design choice is related to the fact that to provide absolute high confidence reliability evidence for new parts / items is often not possible or extremely expensive. By creating redundancy, together with a high level of failure monitoring and the avoidance of common cause failures, even a system with relative bad single channel (part) reliability, can be made highly reliable (mission reliability)on system level. No testing of reliability has to be required for this.
An automobile brake light might use two light bulbs. If one bulb fails, the brake light still operates using the other bulb. Redundancy significantly increases system reliability, and is often the only viable means of doing so. However, redundancy is difficult and expensive, and is therefore limited to critical parts of the system. Another design technique, physics of failure, relies on understanding the physical processes of stress, strength and failure at a very detailed level. Then the material or component can be re-designed to reduce the probability of failure. Another common design technique is component derating
: Selecting components whose tolerance significantly exceeds the expected stress, as using a heavier gauge wire that exceeds the normal specification for the expected electrical current.
Another effective way to deal with unreliability issues is to perform analysis to be able to predict degradation and being able to prevent unscheduled down events / failures from occurring. RCM
(Reliability Centered Maintenance) programs can be used for this.
Many tasks, techniques and analyses are specific to particular industries and applications. Commonly these include:
Results are presented during the system design reviews and logistics reviews. Reliability is just one requirement among many system requirements. Engineering trade studies are used to determine the optimum
balance between reliability and other requirements and constraints.
 The purpose of reliability testing is to discover potential problems with the design as early as possible and, ultimately, provide confidence that the system meets its reliability requirements.
The purpose of reliability testing is to discover potential problems with the design as early as possible and, ultimately, provide confidence that the system meets its reliability requirements.
Reliability testing may be performed at several levels. Complex systems may be tested at component, circuit board, unit, assembly, subsystem and system levels. (The test level nomenclature varies among applications.) For example, performing environmental stress screening tests at lower levels, such as piece parts or small assemblies, catches problems before they cause failures at higher levels. Testing proceeds during each level of integration through full-up system testing, developmental testing, and operational testing, thereby reducing program risk. System reliability is calculated at each test level. Reliability growth techniques and failure reporting, analysis and corrective active systems (FRACAS) are often employed to improve reliability as testing progresses. The drawbacks to such extensive testing are time and expense. Customers may choose to accept more risk
by eliminating some or all lower levels of testing.
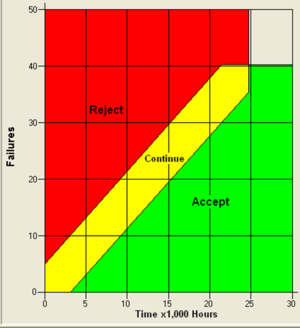
Another type of tests are called Sequential Probability Ratio type of tests. These tests use both a statistical type 1 and type 2 error, combined with a discrimination ratio as main input (together with the R requirement). This test (see for examples mil. std. 781) sets - Independently - before the start of the test both the risk of incorrectly accepting a bad design (Type 2 error) and the risk of incorrectly rejecting a good design (type 1 error) together with the discrimination ratio and the required minimum reliability parameter. The test is therefore more controllable and provides more information for a quality and business point of view. The number of test samples is not fixed, but it is said that this test is in general more efficient (requires less samples) and provides more information than for example zero failure testing.
It is not always feasible to test all system requirements. Some systems are prohibitively expensive to test; some failure mode
s may take years to observe; some complex interactions result in a huge number of possible test cases; and some tests require the use of limited test ranges or other resources. In such cases, different approaches to testing can be used, such as accelerated life testing, design of experiments
, and simulation
s.
The desired level of statistical confidence also plays an important role in reliability testing. Statistical confidence is increased by increasing either the test time or the number of items tested. Reliability test plans are designed to achieve the specified reliability at the specified confidence level
with the minimum number of test units and test time. Different test plans result in different levels of risk to the producer and consumer. The desired reliability, statistical confidence, and risk levels for each side influence the ultimate test plan. Good test requirements ensure that the customer and developer agree in advance on how reliability requirements will be tested.
A key aspect of reliability testing is to define "failure
". Although this may seem obvious, there are many situations where it is not clear whether a failure is really the fault of the system. Variations in test conditions, operator differences, weather
, and unexpected situations create differences between the customer and the system developer. One strategy to address this issue is to use a scoring conference process. A scoring conference includes representatives from the customer, the developer, the test organization, the reliability organization, and sometimes independent observers. The scoring conference process is defined in the statement of work. Each test case is considered by the group and "scored" as a success or failure. This scoring is the official result used by the reliability engineer.
As part of the requirements phase, the reliability engineer develops a test strategy with the customer. The test strategy makes trade-offs between the needs of the reliability organization, which wants as much data as possible, and constraints such as cost, schedule, and available resources. Test plans and procedures are developed for each reliability test, and results are documented in official reports.
The main objective of an accelerated test is either of the following:
An Accelerated testing program can be broken down into the following steps:
Common way to determine a life stress relationship are
, software, supporting infrastructure (including critical external interfaces), operators and procedures. Traditionally, reliability engineering focuses on critical hardware parts of the system. Since the widespread use of digital integrated circuit
technology, software has become an increasingly critical part of most electronics
and, hence, nearly all present day systems. There are significant differences, however, in how software and hardware behave. Most hardware unreliability is the result of a component or material
failure that results in the system not performing its intended function. Repairing or replacing the hardware component restores the system to its original operating state. However, software does not fail in the same sense that hardware fails. Instead, software unreliability is the result of unanticipated results of software operations. Even relatively small software programs can have astronomically large combinations of inputs and states that are infeasible to exhaustively test. Restoring software to its original state only works until the same combination of inputs and states results in the same unintended result. Software reliability engineering must take this into account.
Despite this difference in the source of failure between software and hardware — software does not wear out — some in the software reliability engineering community believe statistical models used in hardware reliability are nevertheless useful as a measure of software reliability, describing what we experience with software: the longer software is run, the higher the probability that it will eventually be used in an untested manner and exhibit a latent defect that results in a failure (Shooman 1987), (Musa 2005), (Denney 2005). (Of course, that assumes software is a constant, which it seldom is.)
As with hardware, software reliability depends on good requirements, design and implementation. Software reliability engineering relies heavily on a disciplined software engineering
process to anticipate and design against unintended consequence
s. There is more overlap between software quality engineering
and software reliability engineering than between hardware quality and reliability. A good software development plan is a key aspect of the software reliability program. The software development plan describes the design and coding standards, peer reviews
, unit test
s, configuration management
, software metrics and software models to be used during software development.
A common reliability metric is the number of software faults, usually expressed as faults per thousand lines of code. This metric, along with software execution time, is key to most software reliability models and estimates. The theory is that the software reliability increases as the number of faults (or fault density) goes down. Establishing a direct connection between fault density and mean-time-between-failure is difficult, however, because of the way software faults are distributed in the code, their severity, and the probability of the combination of inputs necessary to encounter the fault. Nevertheless, fault density serves as a useful indicator for the reliability engineer. Other software metrics, such as complexity, are also used. This metric remains controversial, since changes in software development and verification practices can have dramatic impact on overall defect rates.
Testing is even more important for software than hardware. Even the best software development process results in some software faults that are nearly undetectable until tested. As with hardware, software is tested at several levels, starting with individual units, through integration and full-up system testing. Unlike hardware, it is inadvisable to skip levels of software testing. During all phases of testing, software faults are discovered, corrected, and re-tested. Reliability estimates are updated based on the fault density and other metrics. At a system level, mean-time-between-failure data can be collected and used to estimate reliability. Unlike hardware, performing exactly the same test on exactly the same software configuration does not provide increased statistical confidence. Instead, software reliability uses different metrics, such as code coverage
.
Eventually, the software is integrated with the hardware in the top-level system, and software reliability is subsumed by system reliability. The Software Engineering Institute's Capability Maturity Model
is a common means of assessing the overall software development process for reliability and quality purposes.
, to ensure the system reliability meets requirements. Reliability data and estimates are also key inputs for system logistics
. Data collection is highly dependent on the nature of the system. Most large organizations have quality control
groups that collect failure data on vehicles, equipment, and machinery. Consumer product failures are often tracked by the number of returns. For systems in dormant storage or on standby, it is necessary to establish a formal surveillance program to inspect and test random samples. Any changes to the system, such as field upgrades or recall repairs, require additional reliability testing to ensure the reliability of the modification. Since it is not possible to anticipate all the failure modes of a given system, especially ones with a human element, failures will occur. The reliability program also includes a systematic root cause analysis
that identifies the causal relationships involved in the failure such that effective corrective actions may be implemented. When possible, system failures and corrective actions are reported to the reliability engineering organization.
One of the most common methods to apply a reliability operational assessment are Failure Reporting, Analysis and Corrective Action Systems
(FRACAS). This systematic approach develops a reliability, safety and logistics assessment based on Failure / Incident reporting, management, analysis and corrective/preventive actions. Organizations today are adopting this method and utilize commercial systems such as a Web based FRACAS application enabling and organization to create a failure/incident data repository from which statistics can be derived to view accurate and genuine reliability, safety and quality performances.
It is extremely important to have one common source FRACAS system for all end items. Also test results should be able to captured here in practical way. Failure to adopt one easy to handle (easy data entry for field engineers and repair shop engineers)and maintain integrated system is likely to result in a FRACAS program failure.
Some of the common outputs from a FRACAS system includes: Field MTBF, MTTR, Spares Consumption, Reliability Growth, Failure/Incidents distribution by type, location, part no., serial no, symptom etc.
The use of past data to predict the reliability of new comparable Systems / Items can be misleading as reliability is a function of the context of use and can be affected by small changes in the designs / manufacturing.
agency. The reliability engineering organization must be consistent with the company's organizational structure
. For small, non-critical systems, reliability engineering may be informal. As complexity grows, the need arises for a formal reliability function. Because reliability is important to the customer, the customer may even specify certain aspects of the reliability organization.
There are several common types of reliability organizations. The project manager
or chief engineer
may employ one or more reliability engineers directly. In larger organizations, there is usually a product assurance or specialty engineering
organization, which may include reliability, maintainability
, quality, safety
, human factors
, logistics
, etc. In such case, the reliability engineer reports to the product assurance manager or specialty engineering manager.
In some cases, a company may wish to establish an independent reliability organization. This is desirable to ensure that the system reliability, which is often expensive and time consuming, is not unduly slighted due to budget and schedule pressures. In such cases, the reliability engineer works for the project day-to-day, but is actually employed and paid by a separate organization within the company.
Because reliability engineering is critical to early system design, it has become common for reliability engineers, however the organization is structured, to work as part of an integrated product team
.
has a program to become a Certified Reliability Engineer, CRE. Certification is based on education, experience, and a certification test: periodic re-certification is required. The body of knowledge for the test includes: reliability management, design evaluation, product safety, statistical tools, design and development, modeling, reliability testing, collecting and using data, etc.
Another highly respected certification program is the CRP (Certified Reliability Professional). To achieve certification, candidates must complete a series of courses focused on important Reliability Engineering topics, successfully apply the learned body of knowledge in the workplace and publicly present this expertise in an industry conference or journal.
, Concordia University, Montreal, Canada, Monash University
, Australia and Tampere University of Technology, Tampere, Finland). Other reliability engineers typically have an engineering degree, which can be in any field of engineering, from an accredited university
or college
program. Many engineering programs offer reliability courses, and some universities have entire reliability engineering programs. A reliability engineer may be registered as a Professional Engineer
by the state, but this is not required by most employers. There are many professional conferences and industry training programs available for reliability engineers. Several professional organizations exist for reliability engineers, including the IEEE Reliability Society
, the American Society for Quality (ASQ), and the Society of Reliability Engineers (SRE).
DEF STAN 00-40 Reliability and Maintainability (R&M)
DEF STAN 00-42 RELIABILITY AND MAINTAINABILITY ASSURANCE GUIDES
DEF STAN 00-43 RELIABILITY AND MAINTAINABILITY ASSURANCE ACTIVITY
DEF STAN 00-44 RELIABILITY AND MAINTAINABILITY DATA COLLECTION AND CLASSIFICATION
DEF STAN 00-45 Issue 1: RELIABILITY CENTERED MAINTENANCE
DEF STAN 00-49 Issue 1: RELIABILITY AND MAINTAINABILITY MOD GUIDE TO TERMINOLOGY DEFINITIONS
These can be obtained from DSTAN. There are also many commercial standards, produced by many organisations including the SAE, MSG, ARP, and IEE.
Engineering
Engineering is the discipline, art, skill and profession of acquiring and applying scientific, mathematical, economic, social, and practical knowledge, in order to design and build structures, machines, devices, systems, materials and processes that safely realize improvements to the lives of...
field, that deals with the study, evaluation, and life-cycle management
Product lifecycle management
In industry, product lifecycle management is the process of managing the entire lifecycle of a product from its conception, through design and manufacture, to service and disposal...
of reliability: the ability of a system
System
System is a set of interacting or interdependent components forming an integrated whole....
or component to perform its required functions under stated conditions for a specified period of time. It is often measured as a probability
Probability
Probability is ordinarily used to describe an attitude of mind towards some proposition of whose truth we arenot certain. The proposition of interest is usually of the form "Will a specific event occur?" The attitude of mind is of the form "How certain are we that the event will occur?" The...
of failure or a measure of availability
Availability
In telecommunications and reliability theory, the term availability has the following meanings:* The degree to which a system, subsystem, or equipment is in a specified operable and committable state at the start of a mission, when the mission is called for at an unknown, i.e., a random, time...
. However, maintainability
Maintainability
In engineering, maintainability is the ease with which a product can be maintained in order to:* isolate defects or their cause* correct defects or their cause* meet new requirements* make future maintenance easier, or* cope with a changed environment...
is also an important part of reliability engineering.
Reliability engineering for complex systems requires a different, more elaborated systems approach than reliability for non-complex systems / items. Reliability engineering is closely related to system safety engineering
Safety engineering
Safety engineering is an applied science strongly related to systems engineering / industrial engineering and the subset System Safety Engineering...
in the sense that they both use common sorts of methods for their analysis and might require input from each other. Reliability analysis have important links with function analysis, requirements specification, systems design, hardware design, software design, manufacturing
Manufacturing
Manufacturing is the use of machines, tools and labor to produce goods for use or sale. The term may refer to a range of human activity, from handicraft to high tech, but is most commonly applied to industrial production, in which raw materials are transformed into finished goods on a large scale...
, testing, maintenance, transport, storage, spare parts, operations research
Operations research
Operations research is an interdisciplinary mathematical science that focuses on the effective use of technology by organizations...
, human factors, technical documentation, training and more.
Most industries do not have specialized reliability engineers and the engineering task often becomes part of the tasks of a design engineer, logistics engineer, systems engineer or quality engineer. Reliability engineers should have broad skills and knowledge.
Overview
- The idea that something is fit for a purpose with respect to time;
- The capacity of a device or system to perform as designed;
- The resistance to failure of a device or system;
- The ability of a device or system to perform a required function under stated conditions for a specified period of timeTimeTime is a part of the measuring system used to sequence events, to compare the durations of events and the intervals between them, and to quantify rates of change such as the motions of objects....
; - The probability that a functional unit will perform its required function for a specified interval under stated conditions.
- The ability of something to "fail wellFailing badlyFailing badly and failing well are concepts in systems security and network security describing how a system reacts to failure. The terms have been popularized by Bruce Schneier, a cryptographer and security consultant....
" (fail without catastrophic consequences)
Reliability engineering is a special discipline within Systems engineering
Systems engineering
Systems engineering is an interdisciplinary field of engineering that focuses on how complex engineering projects should be designed and managed over the life cycle of the project. Issues such as logistics, the coordination of different teams, and automatic control of machinery become more...
. Reliability engineers rely heavily on statistics
Statistics
Statistics is the study of the collection, organization, analysis, and interpretation of data. It deals with all aspects of this, including the planning of data collection in terms of the design of surveys and experiments....
, probability theory
Probability theory
Probability theory is the branch of mathematics concerned with analysis of random phenomena. The central objects of probability theory are random variables, stochastic processes, and events: mathematical abstractions of non-deterministic events or measured quantities that may either be single...
, and reliability theory
Reliability theory
Reliability theory describes the probability of a system completing its expected function during an interval of time. It is the basis of reliability engineering, which is an area of study focused on optimizing the reliability, or probability of successful functioning, of systems, such as airplanes,...
to set requirements, measure or predict reliability and advice on improvements for reliability performance. Many engineering techniques are used in reliability engineering, such as Reliability Hazard analysis
Hazard analysis
A hazard analysis is used as the first step in a process used to assess risk. The result of a hazard analysis is the identification of risks. Preliminary risk levels can be provided in the hazard analysis. The validation, more precise prediction and acceptance of risk is determined in the Risk...
, Failure mode and effects analysis
Failure mode and effects analysis
A failure modes and effects analysis is a procedure in product development and operations management for analysis of potential failure modes within a system for classification by the severity and likelihood of the failures...
(FMEA), Fault tree analysis
Fault tree analysis
Fault tree analysis is a top down, deductive failure analysis in which an undesired state of a system is analyzed using boolean logic to combine a series of lower-level events...
, Reliability Prediction, Weibull analysis, thermal management, reliability testing and accelerated life testing
Accelerated life testing
Accelerated life testing is the process of testing a product by subjecting it to conditions in excess of its normal service parameters in an effort to uncover faults and potential modes of failure in a short amount of time...
. Because of the large number of reliability techniques, their expense, and the varying degrees of reliability required for different situations, most projects develop a reliability program plan to specify the reliability tasks that will be performed for that specific system.
The function of reliability engineering is to develop the reliability requirements for the product, establish an adequate life-cycle reliability program, show that corrective measures (risk mitigations) produce reliability improvements, and perform appropriate analyses and tasks to ensure the product will meet its requirements and the unreliability risk is controlled to an acceptable level. It needs to provide a robust set of (statistical) evidence and justification material to verify if the requirements have been met and to check preliminary reliability risk assessments. The goal is to first identify the reliability hazards, assess the risk associated with them and to control the risk to an acceptable level. What is acceptable is determined by the managing authority / customers. These tasks are normally managed by a reliability engineer or manager, who may hold an accredited engineering degree and has additional reliability-specific education and training.
Reliability engineering is closely associated with maintainability engineering and logistics engineering
Logistic engineering
Logistics engineering is a branch of systems engineering dedicated to the scientific organization of the purchase, transport, storage, distribution, and warehousing of materials and finished goods....
, e.g. Integrated Logistics Support
Integrated Logistics Support
Integrated logistics support is an integrated approach to the management of logistic disciplines in the military, similar to commercial product support or customer service organisations...
(ILS). Many problems from other fields, such as security engineering
Security engineering
Security engineering is a specialized field of engineering that focuses on the security aspects in the design of systems that need to be able to deal robustly with possible sources of disruption, ranging from natural disasters to malicious acts...
and safety engineering
Safety engineering
Safety engineering is an applied science strongly related to systems engineering / industrial engineering and the subset System Safety Engineering...
can also be approached using common reliability engineering techniques. This article provides an overview of some of the most common reliability engineering tasks. Please see the references for a more comprehensive treatment.
Many types of engineering
Engineering
Engineering is the discipline, art, skill and profession of acquiring and applying scientific, mathematical, economic, social, and practical knowledge, in order to design and build structures, machines, devices, systems, materials and processes that safely realize improvements to the lives of...
employ reliability engineers and use the tools and methodology of reliability engineering. For example:
- System engineers design and analyze complex systems having a specified reliability
- Mechanical engineers may have to design a machine or system with a specified reliability
- Automotive engineers have reliability requirements for the automobiles (and components) which they design
- Electronics engineers must design and test their products for reliability requirements.
- In software engineeringSoftware engineeringSoftware Engineering is the application of a systematic, disciplined, quantifiable approach to the development, operation, and maintenance of software, and the study of these approaches; that is, the application of engineering to software...
and systems engineeringSystems engineeringSystems engineering is an interdisciplinary field of engineering that focuses on how complex engineering projects should be designed and managed over the life cycle of the project. Issues such as logistics, the coordination of different teams, and automatic control of machinery become more...
the reliability engineering is the sub-discipline of ensuring that a systemSystemSystem is a set of interacting or interdependent components forming an integrated whole....
(or a device in general) will perform its intended function(s) when operated in a specified manner for a specified length of time. Reliability engineeringEngineeringEngineering is the discipline, art, skill and profession of acquiring and applying scientific, mathematical, economic, social, and practical knowledge, in order to design and build structures, machines, devices, systems, materials and processes that safely realize improvements to the lives of...
is performed throughout the entire life cycleNew product developmentIn business and engineering, new product development is the term used to describe the complete process of bringing a new product to market. A product is a set of benefits offered for exchange and can be tangible or intangible...
of a system, including development, test, production and operation.
Reliability theory
Main articles: reliability theoryReliability theory
Reliability theory describes the probability of a system completing its expected function during an interval of time. It is the basis of reliability engineering, which is an area of study focused on optimizing the reliability, or probability of successful functioning, of systems, such as airplanes,...
, failure rate
Failure rate
Failure rate is the frequency with which an engineered system or component fails, expressed for example in failures per hour. It is often denoted by the Greek letter λ and is important in reliability engineering....
.
Reliability theory is the foundation of reliability engineering. For engineering purposes, reliability is defined as:
-
-
- the probabilityProbabilityProbability is ordinarily used to describe an attitude of mind towards some proposition of whose truth we arenot certain. The proposition of interest is usually of the form "Will a specific event occur?" The attitude of mind is of the form "How certain are we that the event will occur?" The...
that a device will perform its intended function during a specified period of time under stated conditions.
- the probability
-
Mathematically, this may be expressed as,
-
 ,
,
-
- where
 is the failure probability density functionProbability density functionIn probability theory, a probability density function , or density of a continuous random variable is a function that describes the relative likelihood for this random variable to occur at a given point. The probability for the random variable to fall within a particular region is given by the...
is the failure probability density functionProbability density functionIn probability theory, a probability density function , or density of a continuous random variable is a function that describes the relative likelihood for this random variable to occur at a given point. The probability for the random variable to fall within a particular region is given by the...
and is the length of the period of time (which is assumed to start from time zero).
is the length of the period of time (which is assumed to start from time zero).
- where
Reliability engineering is concerned with four key elements of this definition:
- First, reliability is a probability. This means that failure is regarded as a random phenomenon: it is a recurring event, and we do not express any information on individual failures, the causes of failures, or relationships between failures, except that the likelihood for failures to occur varies over time according to the given probability function. Reliability engineering is concerned with meeting the specified probability of success, at a specified statistical confidence levelConfidence intervalIn statistics, a confidence interval is a particular kind of interval estimate of a population parameter and is used to indicate the reliability of an estimate. It is an observed interval , in principle different from sample to sample, that frequently includes the parameter of interest, if the...
. - Second, reliability is predicated on "intended function:" Generally, this is taken to mean operation without failureFailureFailure refers to the state or condition of not meeting a desirable or intended objective, and may be viewed as the opposite of success. Product failure ranges from failure to sell the product to fracture of the product, in the worst cases leading to personal injury, the province of forensic...
. However, even if no individual part of the system fails, but the system as a whole does not do what was intended, then it is still charged against the system reliability. The system requirements specification is the criterion against which reliability is measured. - Third, reliability applies to a specified period of time. In practical terms, this means that a system has a specified chance that it will operate without failure before time
 . Reliability engineering ensures that components and materials will meet the requirements during the specified time. Units other than time may sometimes be used. The automotive industry might specify reliability in terms of miles, the military might specify reliability of a gun for a certain number of rounds fired. A piece of mechanical equipment may have a reliability rating value in terms of cycles of use.
. Reliability engineering ensures that components and materials will meet the requirements during the specified time. Units other than time may sometimes be used. The automotive industry might specify reliability in terms of miles, the military might specify reliability of a gun for a certain number of rounds fired. A piece of mechanical equipment may have a reliability rating value in terms of cycles of use. - Fourth, reliability is restricted to operation under stated (or explicitly defined) conditions. This constraint is necessary because it is impossible to design a system for unlimited conditions. A Mars RoverMars RoverA Mars rover is an automated motor vehicle which propels itself across the surface of the planet Mars after landing.Rovers have several advantages over stationary landers: they examine more territory, they can be directed to interesting features, they can place themselves in sunny positions to...
will have different specified conditions than the family car. The operating environment must be addressed during design and testing. Also, that same rover, may be required to operate in varying conditions requiring additional scrutiny.
Reliability engineering vs safety engineering
Reliability engineering differs from safety engineeringSafety engineering
Safety engineering is an applied science strongly related to systems engineering / industrial engineering and the subset System Safety Engineering...
with respect to the kind of hazards that are considered. Reliability engineering is in the end only concerned with cost. It relates to hazards that could transform into a particular level of loss of revenue for the company or the customer. These can be cost due to loss of production due to system unavailability, unexpected high or low demands for spares, repair costs, man hours, (multiple) re-designs, interruptions on normal production (e.g. due to high repair times or due to unexpected demands for non-stocked spares) and many other indirect costs. Safety engineering, on the other hand, is more specific and regulated. The related reliability Requirements are sometimes extremely high. It deals with unwanted dangerous events (for life and environment) in the same sense as reliability engineering, but does normally not directly look at cost and is not concerned with repair actions after failure. Another difference is the level of impact of failures on society and the control of governments. Safety engineering is often strictly controlled by governments (e.g. Nuclear, Aerospace, Defense, Rail and Oil industries). Furthermore, safety engineering and reliability engineering often have contradicting requirements. For example, in train control systems it is common practice to use many fail-safe devices and to lower trip settings as needed. This will unfortunately lower the reliability. Reliability can be increased here by using redundant systems, this does however lower the safety levels. The only way to increase both reliability and safety on a systems level is by using fault tolerant systems. In this case the "operational" / "mission" reliability as well as the safety of a system can be increased. This is common practice in aerospace systems that need continues availability and do not have a fail safe mode (e.g. flight computers and related steering systems). However, the "basic" reliability of the system will in this case still be lower. Basic reliability refers to failures that might not result in system failure, but do result in maintenance actions, logistic cost, use of spares, etc.
Reliability program plan
Many tasks, methods, and tools can be used to achieve reliability. Every system requires a different level of reliability. A commercial airlinerAirliner
An airliner is a large fixed-wing aircraft for transporting passengers and cargo. Such aircraft are operated by airlines. Although the definition of an airliner can vary from country to country, an airliner is typically defined as an aircraft intended for carrying multiple passengers in commercial...
must operate under a wide range of conditions. The consequences of failure are grave, but there is a correspondingly higher budget. A pencil sharpener may be more reliable than an airliner, but has a much different set of operational conditions, insignificant consequences of failure, and a much lower budget.
A reliability program plan (RPP) is used to document exactly what "best practices" (tasks, methods, tools, analyses, and tests) are required for a particular (sub)system, as well as clarify customer requirements for reliability assessment. For large scale, complex systems, the Reliability Program Plan is a distinctive document
Document
The term document has multiple meanings in ordinary language and in scholarship. WordNet 3.1. lists four meanings :* document, written document, papers...
. For simple systems, it may be combined with the systems engineering
Systems engineering
Systems engineering is an interdisciplinary field of engineering that focuses on how complex engineering projects should be designed and managed over the life cycle of the project. Issues such as logistics, the coordination of different teams, and automatic control of machinery become more...
management plan or an integrated logistics support
Integrated logistics support
Integrated logistics support is an integrated approach to the management of logistic disciplines in the military, similar to commercial product support or customer service organisations...
management plan. A reliability program plan is essential for a successful reliability, availability
Availability
In telecommunications and reliability theory, the term availability has the following meanings:* The degree to which a system, subsystem, or equipment is in a specified operable and committable state at the start of a mission, when the mission is called for at an unknown, i.e., a random, time...
, and maintainability
Maintainability
In engineering, maintainability is the ease with which a product can be maintained in order to:* isolate defects or their cause* correct defects or their cause* meet new requirements* make future maintenance easier, or* cope with a changed environment...
(RAM) program and is developed early during system development, and refined over the systems life-cycle. It specifies not only what the reliability engineer does, but also the tasks performed by other stakeholders. A reliability program plan is approved by top program management, who is responsible for identifying resources for its implementation.
Technically, often, the main objective of a Reliability Program Plan is to evaluate and improve availability
Availability
In telecommunications and reliability theory, the term availability has the following meanings:* The degree to which a system, subsystem, or equipment is in a specified operable and committable state at the start of a mission, when the mission is called for at an unknown, i.e., a random, time...
of a system and not reliability. Reliability needs to be evaluated and improved related to both availability and the cost of ownership (due to spares costing, maintenance man-hours, transport etc. costs). Often a trade-off is needed between the two. There might be a maximum ratio between availability and cost of ownership. If availability or Cost of Ownership is more important depends on the use of the system (e.g. a system that is a critical link in a production system - for example a big oil platform - is normally allowed to have a very high cost of ownership if this translates to even a minor higher availability as the unavailability of the platform directly results in a massive loss of revenue). Testability of a system should also be addressed in the plan as this is the link between reliability and maintainability. The maintenance (the maintenance concept / strategy) can influence the reliability of a system (e.g. by preventive maintenance) - although it can never bring it above the inherent reliability. Maintainability influences the availability of a system - in theory this can be almost unlimited if one would be able to repair a failure in a very short time.
A proper reliability plan should normally always address RAMT analysis in its total context. RAMT stands in this case for Reliability, Availability, Maintainability (and maintenance) and Testability in context to users needs to the technical requirements (as translated from the needs).
Reliability requirements
For any system, one of the first tasks of reliability engineering is to adequately specify the reliability and maintainability requirements, as defined by the stakeholders in terms of their overall availabilityAvailability
In telecommunications and reliability theory, the term availability has the following meanings:* The degree to which a system, subsystem, or equipment is in a specified operable and committable state at the start of a mission, when the mission is called for at an unknown, i.e., a random, time...
needs. Reliability requirements address the system itself, test and assessment requirements, and associated tasks and documentation. Reliability requirements are included in the appropriate system/subsystem requirements specifications, test plans, and contract statements. Maintainability requirements address system issue of costs as well as time to repair. Evaluation of the effectiveness of corrective measures is part of a FRACAS
Fracas
Fracas may refer to:* Fracas! Improv Festival, an improvisational theater festival* Failure Reporting, Analysis and Corrective Action Systems* Fracas , a 1980 Apple II video game by Stuart Smith...
process that is usually part of a good RPP.
Reliability prediction
Reliability prediction is the combination of the creation of a proper reliability model together with estimating (and justifying) the input parameters for this model (like failure rates for a particular failure mode or event and the mean time to repair the system for a particular failure) and finally to provide a system (or part) level estimate for the output reliability parameters (system availability or a particular functional failure frequency).Some recognized authors on reliability - e.g. Patrick O'Conner, R. Barnard and others - have argued that too many emphasis is often given to the prediction of reliability parameters and more effort should be devoted to prevention of failure. The reason for this is that prediction of reliability based on historic data can be very misleading, because a comparison is only valid for exactly the same designs, products under exactly the same loads / context. Even a minor change in detail in any of these could have major effects on reliability. Furthermore, normally the most unreliable and important items (most interesting candidates for a reliability investigation) are most often subjected to many modifications and changes. Also, to perform a proper quantitative reliability prediction for systems is extremely difficult and expensive if done by testing. On part level results can be obtained often with higher confidence as many samples might be used for the available testing financial budget, however unfortunately these tests might lack validity on system level due to the assumptions that had to be made for part level testing. Testing for reliability should be done to create failures, learn from them and to improve the system / part. The general conclusion is drawn that an accurate and an absolute prediction - by field data comparison or testing - of reliability is in most cases not possible. A exception might be failures due to wear-out problems like fatigue failures. Mil. Std. 785 writes in its introduction that reliability prediction should be used with great caution if not only used for comparison in trade-off studies.
Furthermore, based on latest insights in Reliability centered maintenance
Reliability Centered Maintenance
Reliability Centered Maintenance, often known as RCM, is a process to ensure that assets continue to do what their users require in their present operating context....
(RCM), most (complex) system failures do no occur due to wear-out issues (e.g. a number of 4% has been provided, refer to RCM page). The failures are often a result of combinations of more and multi-type events or failures. The results of these studies have shown that the majority of failures follow a constant failure rate model, for which prediction of the value of the parameters is often problematic and very time consuming (for a high level reliability - part level). Testing these constant failure rates at system level, by for example mil. handbook 781 type of testing, is not practical and can be extremely misleading.
Despite all the concerns, there will always be a need for the prediction of reliability. These numbers can be used as a Key performance indicator (KPI) or to estimate the need for spares, man-power, availability of systems, etc.
Reliability predictions:
- Help assess the effect of product reliability on the maintenance activity and on the quantity of spare units required for acceptable field performance of any particular system. For example, predictions of the frequency of unit level maintenance actions can be obtained. Reliability prediction can be used to size spare populations.
- Provide necessary input to system-level reliability models. System-level reliability models can subsequently be used to predict, for example, frequency of system outages in steady-state, frequency of system outages during early life, expected downtime per year, and system availability.
- Provide necessary input to unit and system-level Life Cycle Cost Analyses. Life cycle cost studies determine the cost of a product over its entire life. Therefore, how often a unit will have to be replaced needs to be known. Inputs to this process include unit and system failure rates. This includes how often units and systems fail during the first year of operation as well as in later years.
- Assist in deciding which product to purchase from a list of competing products. As a result, it is essential that reliability predictions be based on a common procedure.
- Can be used to set factory test standards for products requiring a reliability test. Reliability predictions help determine how often the system should fail.
- Are needed as input to the analysis of complex systems such as switching systems and digital cross-connect systems. It is necessary to know how often different parts of the system are going to fail even for redundant components.
- Can be used in design trade-off studies. For example, a supplier could look at a design with many simple devices and compare it to a design with fewer devices that are newer but more complex. The unit with fewer devices is usually more reliable.
- Can be used to set achievable in-service performance standards against which to judge actual performance and stimulate action.
The telecommunications industry has devoted much time over the years to concentrate on developing reliability models for electronic equipment. One such tool is the Automated Reliability Prediction Procedure (ARPP), which is an Excel-spreadsheet software tool that automates the reliability prediction procedures in SR-332, Reliability Prediction Procedure for Electronic Equipment. FD-ARPP-01 provides suppliers and manufacturers with a tool for making Reliability Prediction Procedure (RPP) calculations. It also provides a means for understanding RPP calculations through the capability of interactive examples provided by the user.
The RPP views electronic systems as hierarchical assemblies. Systems are constructed from units that, in turn, are constructed from devices. The methods presented predict reliability at these three hierarchical levels:
- Device: A basic component (or part)
- Unit: Any assembly of devices. This may include, but is not limited to, circuit packs, modules, plug-in units, racks, power supplies, and ancillary equipment. Unless otherwise dictated by maintenance considerations, a unit will usually be the lowest level of replaceable assemblies/devices. The RPP is aimed primarily at reliability prediction of units.
- Serial System: Any assembly of units for which the failure of any single unit will cause a failure of the system or overall mission.
System reliability parameters
Requirements are specified using reliability parameterParameter
Parameter from Ancient Greek παρά also “para” meaning “beside, subsidiary” and μέτρον also “metron” meaning “measure”, can be interpreted in mathematics, logic, linguistics, environmental science and other disciplines....
s. The most common reliability parameter is the mean time to failure
Mean time to failure
No artical exists on Wiki, please create one.In short Mean Time to Failure is the time taken for a part or system to fail for the first time.A very brief formula for the Mean Time To Failure of an event which occurs with probability P is: 1 / P....
(MTTF), which can also be specified as the failure rate
Failure rate
Failure rate is the frequency with which an engineered system or component fails, expressed for example in failures per hour. It is often denoted by the Greek letter λ and is important in reliability engineering....
(this is expressed as a frequency or Conditional Probability Density Function (PDF)) or the number of failures during a given period. These parameters are very useful for systems that are operated frequently, such as most vehicle
Vehicle
A vehicle is a device that is designed or used to transport people or cargo. Most often vehicles are manufactured, such as bicycles, cars, motorcycles, trains, ships, boats, and aircraft....
s, machinery, and electronic
Electronics
Electronics is the branch of science, engineering and technology that deals with electrical circuits involving active electrical components such as vacuum tubes, transistors, diodes and integrated circuits, and associated passive interconnection technologies...
equipment. Reliability increases as the MTTF increases. The MTTF is usually specified in hours, but can also be used with other units of measurement such as miles or cycles.
In other cases, reliability is specified as the probability of mission success. For example, reliability of a scheduled aircraft flight can be specified as a dimensionless probability or a percentage. as in system safety
System safety
The system safety concept calls for a risk management strategy based on identification, analysis of hazards and application of remedial controls using a systems-based approach...
engineering.
A special case of mission success is the single-shot device or system. These are devices or systems that remain relatively dormant and only operate once. Examples include automobile airbags, thermal batteries
Battery (electricity)
An electrical battery is one or more electrochemical cells that convert stored chemical energy into electrical energy. Since the invention of the first battery in 1800 by Alessandro Volta and especially since the technically improved Daniell cell in 1836, batteries have become a common power...
and missiles. Single-shot reliability is specified as a probability of one-time success, or is subsumed into a related parameter. Single-shot missile reliability may be specified as a requirement
Requirement
In engineering, a requirement is a singular documented physical and functional need that a particular product or service must be or perform. It is most commonly used in a formal sense in systems engineering, software engineering, or enterprise engineering...
for the probability of hit.
For such systems, the probability of failure on demand (PFD)
Safety Integrity Level
Safety Integrity Level is defined as a relative level of risk-reduction provided by a safety function, or to specify a target level of risk reduction. In simple terms, SIL is a measurement of performance required for a Safety Instrumented Function ....
is the reliability measure
Measurement
Measurement is the process or the result of determining the ratio of a physical quantity, such as a length, time, temperature etc., to a unit of measurement, such as the metre, second or degree Celsius...
- which actually is a unavailability number. This PFD is derived from failure rate (a frequency of occurrence) and mission time for non-repairable systems. For repairable systems, it is obtained from failure rate and mean-time-to-repair (MTTR) and test interval. This measure may not be unique for a given system as this measure depends on the kind of demand.
In addition to system level requirements, reliability requirements may be specified for critical subsystems. In most cases, reliability parameters are specified with appropriate statistical confidence interval
Confidence interval
In statistics, a confidence interval is a particular kind of interval estimate of a population parameter and is used to indicate the reliability of an estimate. It is an observed interval , in principle different from sample to sample, that frequently includes the parameter of interest, if the...
s.
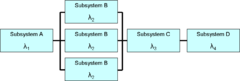
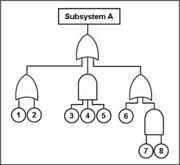
Reliability modelling
Reliability modelling is the process of predicting or understanding the reliability of a component or system prior to its implementation. Two types of analysis that are often used to model a system reliability behavior are Fault Tree Analysis and Reliability Block diagrams. On component level the same analysis can be used together with others. The input for the models can come from many sources, e.g.: Testing, Earlier operational experience field data or Data Handbooks from the same or mixed industries can be used. In all cases, the data must be used with great caution as predictions are only valid in case the same product in the same context is used. Often predictions are only made to compare alternatives.For part level predictions, two separate fields of investigation are common:
- The physics of failurePhysics of failurePhysics of Failure is a technique under the practice of Design for Reliability that leverages the knowledge and understanding of the processes and mechanisms that induce failure to predict reliability and improve product performance....
approach uses an understanding of physical failure mechanisms involved, such as mechanical crack propagation or chemical corrosionCorrosionCorrosion is the disintegration of an engineered material into its constituent atoms due to chemical reactions with its surroundings. In the most common use of the word, this means electrochemical oxidation of metals in reaction with an oxidant such as oxygen...
degradation or failure; - The parts stress modellingParts stress modellingParts stress modelling is a method in engineering and especially electronics to find an expected value for the rate of failure of the mechanical and electronic components of a system...
approach is an empirical method for prediction based on counting the number and type of components of the system, and the stress they undergo during operation.
Software reliability is a more challenging area that must be considered when it is a considerable component to system functionality.
For systems with a clearly defined failure time (which is sometimes not given for systems with a drifting parameter), the empirical distribution function
Empirical distribution function
In statistics, the empirical distribution function, or empirical cdf, is the cumulative distribution function associated with the empirical measure of the sample. This cdf is a step function that jumps up by 1/n at each of the n data points. The empirical distribution function estimates the true...
of these failure times can be determined. This is done in general in an experiment with increased (or accelerated) stress. These experiments can be divided into two main categories:
- Early failure rate studies determine the distribution with a decreasing failure rate over the first part of the bathtub curveBathtub curveThe bathtub curve is widely used in reliability engineering. It describes a particular form of the hazard function which comprises three parts:*The first part is a decreasing failure rate, known as early failures....
. (The bathtub curve only holds for hardware failures, not software.) Here in general only moderate stress is necessary. The stress is applied for a limited period of time in what is called a censored test. Therefore, only the part of the distribution with early failures can be determined.
- In so-called zero defect experiments, only limited information about the failure distribution is acquired. Here the stress, stress time, or the sample size is so low that not a single failure occurs. Due to the insufficient sample size, only an upper limit of the early failure rate can be determined. At any rate, it looks good for the customer if there are no failures.
In a study of the intrinsic failure distribution, which is often a material property, higher (material) stresses are necessary to get failure in a reasonable period of time. Several degrees of stress have to be applied to determine an acceleration model. The empirical failure distribution is often parametrized with a Weibull or a log-normal model.
It is a general praxis to model the early (hardware) failure rate with an exponential distribution. This less complex model for the failure distribution has only one parameter: the constant failure rate. In such cases, the Chi-squared distribution can be used to find the goodness of fit
Goodness of fit
The goodness of fit of a statistical model describes how well it fits a set of observations. Measures of goodness of fit typically summarize the discrepancy between observed values and the values expected under the model in question. Such measures can be used in statistical hypothesis testing, e.g...
for the estimated failure rate. Compared to a model with a decreasing failure rate, this is quite pessimistic (important remark: this is not the case if less hours / load cycles are tested than service life in a wear-out type of test, in this case the opposite is true and assuming a more constant failure rate than it is in reality can be dangerous). Sensitivity analysis should be conducted in this case.
Reliability test requirements
Reliability test requirements can follow from any analysis for which the first estimate of failure probability, failure mode or effect needs to be justified. Evidence can be generated with some level of confidence by testing. With software-based systems, the probability is a mix of software and hardware-based failures. Testing reliability requirements is problematic for several reasons. A single test is in most cases insufficient to generate enough statistical data. Multiple tests or long-duration tests are usually very expensive. Some tests are simply impractical, and environmental conditions can be hard to predict over a systems life-cycle.Reliability engineering is used to design a realistic and affordable test program that provides enough evidence that the system meets its reliability requirements. Statistical confidence levels
Confidence interval
In statistics, a confidence interval is a particular kind of interval estimate of a population parameter and is used to indicate the reliability of an estimate. It is an observed interval , in principle different from sample to sample, that frequently includes the parameter of interest, if the...
are used to address some of these concerns. A certain parameter is expressed along with a corresponding confidence level: for example, an MTBF of 1000 hours at 90% confidence level. From this specification, the reliability engineer can for example design a test with explicit criteria for the number of hours and number of failures until the requirement is met or failed. Other type tests are also possible.
The combination of reliability parameter value and confidence level greatly affects the development cost and the risk to both the customer and producer. Care is needed to select the best combination of requirements - e.g. cost-effectiveness. Reliability testing may be performed at various levels, such as component, subsystem, and system
System
System is a set of interacting or interdependent components forming an integrated whole....
. Also, many factors must be addressed during testing and operation, such as extreme temperature and humidity, shock, vibration, or other environmental factors (like loss of signal, cooling or power; or other catastrophes such as fire, floods, excessive heat, physical or security violations or other myriad forms of damage or degradation). Reliability engineering must assess the root cause of failures and devise corrective actions. Reliability engineering determines an effective test strategy
Test strategy
A test strategy is an outline that describes the testing portion of the software development cycle. It is created to inform project managers, testers, and developers about some key issues of the testing process...
so that all parts are exercised in relevant environments in order to assure the best possible reliability under understood conditions. For systems that must last many years, reliability engineering may be used to design accelerated life tests.
Requirements for reliability tasks
Reliability engineering must also address requirements for various reliability tasks and documentation during system development, test, production, and operation. These requirements are generally specified in the contract statement of work and depend on how much leeway the customer wishes to provide to the contractor. Reliability tasks include various analyses, planning, and failure reporting. Task selection depends on the criticality of the system as well as cost. A critical system may require a formal failure reporting and review process throughout development, whereas a non-critical system may rely on final test reports. The most common reliability program tasks are documented in reliability program standards, such as MIL-STD-785 and IEEE 1332.Failure reporting analysis and corrective action systems are a common approach for product/process reliability monitoring.
Design for reliability
Design For Reliability (DFR), is an emerging discipline that refers to the process of designing reliability into designs. This process encompasses several tools and practices and describes the order of their deployment that an organization needs to have in place to drive reliability and improve maintainabilityMaintainability
In engineering, maintainability is the ease with which a product can be maintained in order to:* isolate defects or their cause* correct defects or their cause* meet new requirements* make future maintenance easier, or* cope with a changed environment...
in products, towards a objective of improved availability
Availability
In telecommunications and reliability theory, the term availability has the following meanings:* The degree to which a system, subsystem, or equipment is in a specified operable and committable state at the start of a mission, when the mission is called for at an unknown, i.e., a random, time...
, lower sustainment costs, and maximum product utilization or lifetime. Typically, the first step in the DFR process is to establish the system’s availability requirements. Reliability must be "designed in" to the system. During system design
Design
Design as a noun informally refers to a plan or convention for the construction of an object or a system while “to design” refers to making this plan...
, the top-level reliability requirements are then allocated to subsystems by design engineers, maintainers, and reliability engineers working together.
Reliability design begins with the development of a (system) model
Mathematical model
A mathematical model is a description of a system using mathematical concepts and language. The process of developing a mathematical model is termed mathematical modeling. Mathematical models are used not only in the natural sciences and engineering disciplines A mathematical model is a...
. Reliability models use block diagrams and fault trees to provide a graphical means of evaluating the relationships between different parts of the system. These models incorporate predictions based on parts-count failure rates taken from historical data. While the (input data) predictions are often not accurate in an absolute sense, they are valuable to assess relative differences in design alternatives.
Redundancy (engineering)
In engineering, redundancy is the duplication of critical components or functions of a system with the intention of increasing reliability of the system, usually in the case of a backup or fail-safe....
. This means that if one part of the system fails, there is an alternate success path, such as a backup system. The reason why this is the ultimate design choice is related to the fact that to provide absolute high confidence reliability evidence for new parts / items is often not possible or extremely expensive. By creating redundancy, together with a high level of failure monitoring and the avoidance of common cause failures, even a system with relative bad single channel (part) reliability, can be made highly reliable (mission reliability)on system level. No testing of reliability has to be required for this.
An automobile brake light might use two light bulbs. If one bulb fails, the brake light still operates using the other bulb. Redundancy significantly increases system reliability, and is often the only viable means of doing so. However, redundancy is difficult and expensive, and is therefore limited to critical parts of the system. Another design technique, physics of failure, relies on understanding the physical processes of stress, strength and failure at a very detailed level. Then the material or component can be re-designed to reduce the probability of failure. Another common design technique is component derating
Derating
Derating is the operation of a machine at less than its rated maximum power in order to prolong its life. The term is commonly applied to electrical and electronic devices and to internal combustion engines.-In electronics:...
: Selecting components whose tolerance significantly exceeds the expected stress, as using a heavier gauge wire that exceeds the normal specification for the expected electrical current.
Another effective way to deal with unreliability issues is to perform analysis to be able to predict degradation and being able to prevent unscheduled down events / failures from occurring. RCM
Reliability Centered Maintenance
Reliability Centered Maintenance, often known as RCM, is a process to ensure that assets continue to do what their users require in their present operating context....
(Reliability Centered Maintenance) programs can be used for this.
Many tasks, techniques and analyses are specific to particular industries and applications. Commonly these include:
- Built-in test (BIT) (Testability analysis)
- Failure mode and effects analysisFailure mode and effects analysisA failure modes and effects analysis is a procedure in product development and operations management for analysis of potential failure modes within a system for classification by the severity and likelihood of the failures...
(FMEA) - Reliability simulation modeling
- Reliability Hazard analysisHazard analysisA hazard analysis is used as the first step in a process used to assess risk. The result of a hazard analysis is the identification of risks. Preliminary risk levels can be provided in the hazard analysis. The validation, more precise prediction and acceptance of risk is determined in the Risk...
- Thermal analysisThermal analysisThermal analysis is a branch of materials science where the properties of materials are studied as they change with temperature. Several methods are commonly used - these are distinguished from one another by the property which is measured:...
- Reliability Block Diagram analysis
- Fault tree analysisFault tree analysisFault tree analysis is a top down, deductive failure analysis in which an undesired state of a system is analyzed using boolean logic to combine a series of lower-level events...
- Root cause analysisRoot cause analysisRoot cause analysis is a class of problem solving methods aimed at identifying the root causes of problems or events.Root Cause Analysis is any structured approach to identifying the factors that resulted in the nature, the magnitude, the location, and the timing of the harmful outcomes of one...
- Sneak circuit analysis
- Accelerated Testing
- Reliability Growth analysis
- Weibull analysis
- Electromagnetic analysis
- Statistical interferenceStatistical interferenceWhen two probability distributions overlap, statistical interference exists. Knowledge of the distributions can be used to determine the likelihood that one parameter exceeds another, and by how much....
- Avoid Single Point of FailureSingle point of failureA single point of failure is a part of a system that, if it fails, will stop the entire system from working. They are undesirable in any system with a goal of high availability or reliability, be it a business practice, software application, or other industrial system.-Overview:Systems can be made...
- Functional Analysis (Functional FMEA)
- Predictive and Preventive maintenance: Reliability Centered Maintenance (RCM) analysis
- Testability analysis
- Failure diagnostics analysis
- Human error analysis
- Operational Hazard analysis /
- Manual screening
- Integrated Logistics SupportIntegrated Logistics SupportIntegrated logistics support is an integrated approach to the management of logistic disciplines in the military, similar to commercial product support or customer service organisations...
Results are presented during the system design reviews and logistics reviews. Reliability is just one requirement among many system requirements. Engineering trade studies are used to determine the optimum
Optimization (mathematics)
In mathematics, computational science, or management science, mathematical optimization refers to the selection of a best element from some set of available alternatives....
balance between reliability and other requirements and constraints.
Reliability testing
Reliability testing may be performed at several levels. Complex systems may be tested at component, circuit board, unit, assembly, subsystem and system levels. (The test level nomenclature varies among applications.) For example, performing environmental stress screening tests at lower levels, such as piece parts or small assemblies, catches problems before they cause failures at higher levels. Testing proceeds during each level of integration through full-up system testing, developmental testing, and operational testing, thereby reducing program risk. System reliability is calculated at each test level. Reliability growth techniques and failure reporting, analysis and corrective active systems (FRACAS) are often employed to improve reliability as testing progresses. The drawbacks to such extensive testing are time and expense. Customers may choose to accept more risk
Risk
Risk is the potential that a chosen action or activity will lead to a loss . The notion implies that a choice having an influence on the outcome exists . Potential losses themselves may also be called "risks"...
by eliminating some or all lower levels of testing.
Another type of tests are called Sequential Probability Ratio type of tests. These tests use both a statistical type 1 and type 2 error, combined with a discrimination ratio as main input (together with the R requirement). This test (see for examples mil. std. 781) sets - Independently - before the start of the test both the risk of incorrectly accepting a bad design (Type 2 error) and the risk of incorrectly rejecting a good design (type 1 error) together with the discrimination ratio and the required minimum reliability parameter. The test is therefore more controllable and provides more information for a quality and business point of view. The number of test samples is not fixed, but it is said that this test is in general more efficient (requires less samples) and provides more information than for example zero failure testing.
It is not always feasible to test all system requirements. Some systems are prohibitively expensive to test; some failure mode
Failure mode
Failure causes are defects in design, process, quality, or part application, which are the underlying cause of a failure or which initiate a process which leads to failure. Where failure depends on the user of the product or process, then human error must be considered.-Component failure:A part...
s may take years to observe; some complex interactions result in a huge number of possible test cases; and some tests require the use of limited test ranges or other resources. In such cases, different approaches to testing can be used, such as accelerated life testing, design of experiments
Design of experiments
In general usage, design of experiments or experimental design is the design of any information-gathering exercises where variation is present, whether under the full control of the experimenter or not. However, in statistics, these terms are usually used for controlled experiments...
, and simulation
Simulation
Simulation is the imitation of some real thing available, state of affairs, or process. The act of simulating something generally entails representing certain key characteristics or behaviours of a selected physical or abstract system....
s.
The desired level of statistical confidence also plays an important role in reliability testing. Statistical confidence is increased by increasing either the test time or the number of items tested. Reliability test plans are designed to achieve the specified reliability at the specified confidence level
Confidence interval
In statistics, a confidence interval is a particular kind of interval estimate of a population parameter and is used to indicate the reliability of an estimate. It is an observed interval , in principle different from sample to sample, that frequently includes the parameter of interest, if the...
with the minimum number of test units and test time. Different test plans result in different levels of risk to the producer and consumer. The desired reliability, statistical confidence, and risk levels for each side influence the ultimate test plan. Good test requirements ensure that the customer and developer agree in advance on how reliability requirements will be tested.
A key aspect of reliability testing is to define "failure
Failure
Failure refers to the state or condition of not meeting a desirable or intended objective, and may be viewed as the opposite of success. Product failure ranges from failure to sell the product to fracture of the product, in the worst cases leading to personal injury, the province of forensic...
". Although this may seem obvious, there are many situations where it is not clear whether a failure is really the fault of the system. Variations in test conditions, operator differences, weather
Weather
Weather is the state of the atmosphere, to the degree that it is hot or cold, wet or dry, calm or stormy, clear or cloudy. Most weather phenomena occur in the troposphere, just below the stratosphere. Weather refers, generally, to day-to-day temperature and precipitation activity, whereas climate...
, and unexpected situations create differences between the customer and the system developer. One strategy to address this issue is to use a scoring conference process. A scoring conference includes representatives from the customer, the developer, the test organization, the reliability organization, and sometimes independent observers. The scoring conference process is defined in the statement of work. Each test case is considered by the group and "scored" as a success or failure. This scoring is the official result used by the reliability engineer.
As part of the requirements phase, the reliability engineer develops a test strategy with the customer. The test strategy makes trade-offs between the needs of the reliability organization, which wants as much data as possible, and constraints such as cost, schedule, and available resources. Test plans and procedures are developed for each reliability test, and results are documented in official reports.
Accelerated testing
The purpose of accelerated life testing is to induce field failure in the laboratory at a much faster rate by providing a harsher, but nonetheless representative, environment. In such a test the product is expected to fail in the lab just as it would have failed in the field—but in much less time.The main objective of an accelerated test is either of the following:
- To discover failure modes
- To predict the normal field life from the high stressStress testingStress testing is a form of testing that is used to determine the stability of a given system or entity. It involves testing beyond normal operational capacity, often to a breaking point, in order to observe the results...
lab life
An Accelerated testing program can be broken down into the following steps:
- Define objective and scope of the test
- Collect required information about the product
- Identify the stress(es)
- Determine level of stress(es)
- Conduct the Accelerated test and analyze the accelerated data.
Common way to determine a life stress relationship are
- Arrhenius Model
- Eyring Model
- Inverse Power Law Model
- Temperature-Humidity Model
- Temperature Non-thermal Model
Software reliability
Software reliability is a special aspect of reliability engineering. System reliability, by definition, includes all parts of the system, including hardwareHardware
Hardware is a general term for equipment such as keys, locks, hinges, latches, handles, wire, chains, plumbing supplies, tools, utensils, cutlery and machine parts. Household hardware is typically sold in hardware stores....
, software, supporting infrastructure (including critical external interfaces), operators and procedures. Traditionally, reliability engineering focuses on critical hardware parts of the system. Since the widespread use of digital integrated circuit
Integrated circuit
An integrated circuit or monolithic integrated circuit is an electronic circuit manufactured by the patterned diffusion of trace elements into the surface of a thin substrate of semiconductor material...
technology, software has become an increasingly critical part of most electronics
Electronics
Electronics is the branch of science, engineering and technology that deals with electrical circuits involving active electrical components such as vacuum tubes, transistors, diodes and integrated circuits, and associated passive interconnection technologies...
and, hence, nearly all present day systems. There are significant differences, however, in how software and hardware behave. Most hardware unreliability is the result of a component or material
Material
Material is anything made of matter, constituted of one or more substances. Wood, cement, hydrogen, air and water are all examples of materials. Sometimes the term "material" is used more narrowly to refer to substances or components with certain physical properties that are used as inputs to...
failure that results in the system not performing its intended function. Repairing or replacing the hardware component restores the system to its original operating state. However, software does not fail in the same sense that hardware fails. Instead, software unreliability is the result of unanticipated results of software operations. Even relatively small software programs can have astronomically large combinations of inputs and states that are infeasible to exhaustively test. Restoring software to its original state only works until the same combination of inputs and states results in the same unintended result. Software reliability engineering must take this into account.
Despite this difference in the source of failure between software and hardware — software does not wear out — some in the software reliability engineering community believe statistical models used in hardware reliability are nevertheless useful as a measure of software reliability, describing what we experience with software: the longer software is run, the higher the probability that it will eventually be used in an untested manner and exhibit a latent defect that results in a failure (Shooman 1987), (Musa 2005), (Denney 2005). (Of course, that assumes software is a constant, which it seldom is.)
As with hardware, software reliability depends on good requirements, design and implementation. Software reliability engineering relies heavily on a disciplined software engineering
Software engineering
Software Engineering is the application of a systematic, disciplined, quantifiable approach to the development, operation, and maintenance of software, and the study of these approaches; that is, the application of engineering to software...
process to anticipate and design against unintended consequence
Unintended consequence
In the social sciences, unintended consequences are outcomes that are not the outcomes intended by a purposeful action. The concept has long existed but was named and popularised in the 20th century by American sociologist Robert K. Merton...
s. There is more overlap between software quality engineering
Quality Assurance
Quality assurance, or QA for short, is the systematic monitoring and evaluation of the various aspects of a project, service or facility to maximize the probability that minimum standards of quality are being attained by the production process...
and software reliability engineering than between hardware quality and reliability. A good software development plan is a key aspect of the software reliability program. The software development plan describes the design and coding standards, peer reviews
Software peer review
In software development, peer review is a type of software review in which a work product is examined by its author and one or more colleagues, in order to evaluate its technical content and quality.-Purpose:...
, unit test
Unit test
In computer programming, unit testing is a method by which individual units of source code are tested to determine if they are fit for use.A unit is the smallest testable part of an application. In procedural programming a unit could be an entire module but is more commonly an individual function...
s, configuration management
Configuration management
Configuration management is a field of management that focuses on establishing and maintaining consistency of a system or product's performance and its functional and physical attributes with its requirements, design, and operational information throughout its life.For information assurance, CM...
, software metrics and software models to be used during software development.
A common reliability metric is the number of software faults, usually expressed as faults per thousand lines of code. This metric, along with software execution time, is key to most software reliability models and estimates. The theory is that the software reliability increases as the number of faults (or fault density) goes down. Establishing a direct connection between fault density and mean-time-between-failure is difficult, however, because of the way software faults are distributed in the code, their severity, and the probability of the combination of inputs necessary to encounter the fault. Nevertheless, fault density serves as a useful indicator for the reliability engineer. Other software metrics, such as complexity, are also used. This metric remains controversial, since changes in software development and verification practices can have dramatic impact on overall defect rates.
Testing is even more important for software than hardware. Even the best software development process results in some software faults that are nearly undetectable until tested. As with hardware, software is tested at several levels, starting with individual units, through integration and full-up system testing. Unlike hardware, it is inadvisable to skip levels of software testing. During all phases of testing, software faults are discovered, corrected, and re-tested. Reliability estimates are updated based on the fault density and other metrics. At a system level, mean-time-between-failure data can be collected and used to estimate reliability. Unlike hardware, performing exactly the same test on exactly the same software configuration does not provide increased statistical confidence. Instead, software reliability uses different metrics, such as code coverage
Code coverage
Code coverage is a measure used in software testing. It describes the degree to which the source code of a program has been tested. It is a form of testing that inspects the code directly and is therefore a form of white box testing....
.
Eventually, the software is integrated with the hardware in the top-level system, and software reliability is subsumed by system reliability. The Software Engineering Institute's Capability Maturity Model
Capability Maturity Model
The Capability Maturity Model is a development model that was created after study of data collected from organizations that contracted with the U.S. Department of Defense, who funded the research. This model became the foundation from which CMU created the Software Engineering Institute...
is a common means of assessing the overall software development process for reliability and quality purposes.
Reliability operational assessment
After a system is produced, reliability engineering monitors, assesses, and corrects deficiencies. Monitoring includes electronic and visual surveillance of critical parameters identified during the fault tree analysis design stage. The data are constantly analyzed using statistical techniques, such as Weibull analysis and linear regressionLinear regression
In statistics, linear regression is an approach to modeling the relationship between a scalar variable y and one or more explanatory variables denoted X. The case of one explanatory variable is called simple regression...
, to ensure the system reliability meets requirements. Reliability data and estimates are also key inputs for system logistics
Logistics
Logistics is the management of the flow of goods between the point of origin and the point of destination in order to meet the requirements of customers or corporations. Logistics involves the integration of information, transportation, inventory, warehousing, material handling, and packaging, and...
. Data collection is highly dependent on the nature of the system. Most large organizations have quality control
Quality control
Quality control, or QC for short, is a process by which entities review the quality of all factors involved in production. This approach places an emphasis on three aspects:...
groups that collect failure data on vehicles, equipment, and machinery. Consumer product failures are often tracked by the number of returns. For systems in dormant storage or on standby, it is necessary to establish a formal surveillance program to inspect and test random samples. Any changes to the system, such as field upgrades or recall repairs, require additional reliability testing to ensure the reliability of the modification. Since it is not possible to anticipate all the failure modes of a given system, especially ones with a human element, failures will occur. The reliability program also includes a systematic root cause analysis
Root cause analysis
Root cause analysis is a class of problem solving methods aimed at identifying the root causes of problems or events.Root Cause Analysis is any structured approach to identifying the factors that resulted in the nature, the magnitude, the location, and the timing of the harmful outcomes of one...
that identifies the causal relationships involved in the failure such that effective corrective actions may be implemented. When possible, system failures and corrective actions are reported to the reliability engineering organization.
One of the most common methods to apply a reliability operational assessment are Failure Reporting, Analysis and Corrective Action Systems
Failure Reporting, Analysis and Corrective Action Systems
A failure reporting, analysis and corrective action system is a system, sometimes carried out using software, that provides a process for reporting, classifying, analyzing failures, and planning corrective actions in response to those failures. It is typically used in an industrial environment to...
(FRACAS). This systematic approach develops a reliability, safety and logistics assessment based on Failure / Incident reporting, management, analysis and corrective/preventive actions. Organizations today are adopting this method and utilize commercial systems such as a Web based FRACAS application enabling and organization to create a failure/incident data repository from which statistics can be derived to view accurate and genuine reliability, safety and quality performances.
It is extremely important to have one common source FRACAS system for all end items. Also test results should be able to captured here in practical way. Failure to adopt one easy to handle (easy data entry for field engineers and repair shop engineers)and maintain integrated system is likely to result in a FRACAS program failure.
Some of the common outputs from a FRACAS system includes: Field MTBF, MTTR, Spares Consumption, Reliability Growth, Failure/Incidents distribution by type, location, part no., serial no, symptom etc.
The use of past data to predict the reliability of new comparable Systems / Items can be misleading as reliability is a function of the context of use and can be affected by small changes in the designs / manufacturing.
Reliability organizations
Systems of any significant complexity are developed by organizations of people, such as a commercial company or a governmentGovernment
Government refers to the legislators, administrators, and arbitrators in the administrative bureaucracy who control a state at a given time, and to the system of government by which they are organized...
agency. The reliability engineering organization must be consistent with the company's organizational structure
Organizational structure
An organizational structure consists of activities such as task allocation, coordination and supervision, which are directed towards the achievement of organizational aims. It can also be considered as the viewing glass or perspective through which individuals see their organization and its...
. For small, non-critical systems, reliability engineering may be informal. As complexity grows, the need arises for a formal reliability function. Because reliability is important to the customer, the customer may even specify certain aspects of the reliability organization.
There are several common types of reliability organizations. The project manager
Project manager
A project manager is a professional in the field of project management. Project managers can have the responsibility of the planning, execution, and closing of any project, typically relating to construction industry, architecture, computer networking, telecommunications or software...
or chief engineer
Engineer
An engineer is a professional practitioner of engineering, concerned with applying scientific knowledge, mathematics and ingenuity to develop solutions for technical problems. Engineers design materials, structures, machines and systems while considering the limitations imposed by practicality,...
may employ one or more reliability engineers directly. In larger organizations, there is usually a product assurance or specialty engineering
Specialty engineering
In systems engineering, Specialty Engineering includes the engineering domains that are not typical of the main engineering effort. Hardware engineering, software engineering, and human factors engineering may be used as major elements in a majority of systems engineering efforts and therefore are...
organization, which may include reliability, maintainability
Maintainability
In engineering, maintainability is the ease with which a product can be maintained in order to:* isolate defects or their cause* correct defects or their cause* meet new requirements* make future maintenance easier, or* cope with a changed environment...
, quality, safety
Safety
Safety is the state of being "safe" , the condition of being protected against physical, social, spiritual, financial, political, emotional, occupational, psychological, educational or other types or consequences of failure, damage, error, accidents, harm or any other event which could be...
, human factors
Human factors
Human factors science or human factors technologies is a multidisciplinary field incorporating contributions from psychology, engineering, industrial design, statistics, operations research and anthropometry...
, logistics
Logistics
Logistics is the management of the flow of goods between the point of origin and the point of destination in order to meet the requirements of customers or corporations. Logistics involves the integration of information, transportation, inventory, warehousing, material handling, and packaging, and...
, etc. In such case, the reliability engineer reports to the product assurance manager or specialty engineering manager.
In some cases, a company may wish to establish an independent reliability organization. This is desirable to ensure that the system reliability, which is often expensive and time consuming, is not unduly slighted due to budget and schedule pressures. In such cases, the reliability engineer works for the project day-to-day, but is actually employed and paid by a separate organization within the company.
Because reliability engineering is critical to early system design, it has become common for reliability engineers, however the organization is structured, to work as part of an integrated product team
Integrated Product Team
An integrated product team is a multidisciplinary group of people who are collectively responsible for delivering a defined product or process.IPTs are used in complex development programs/projects for review and decision making...
.
Certification
The American Society for QualityAmerican Society for Quality
American Society for Quality , formerly known as American Society for Quality Control , is a knowledge-based global community of quality control experts, with nearly 85,000 members dedicated to the promotion and advancement of quality tools, principles, and practices in their workplaces and in...
has a program to become a Certified Reliability Engineer, CRE. Certification is based on education, experience, and a certification test: periodic re-certification is required. The body of knowledge for the test includes: reliability management, design evaluation, product safety, statistical tools, design and development, modeling, reliability testing, collecting and using data, etc.
Another highly respected certification program is the CRP (Certified Reliability Professional). To achieve certification, candidates must complete a series of courses focused on important Reliability Engineering topics, successfully apply the learned body of knowledge in the workplace and publicly present this expertise in an industry conference or journal.
Reliability engineering education
Some Universities offer graduate degrees in Reliability Engineering (e.g., see University of Tennessee, Knoxville, University of Maryland, College ParkUniversity of Maryland, College Park
The University of Maryland, College Park is a top-ranked public research university located in the city of College Park in Prince George's County, Maryland, just outside Washington, D.C...
, Concordia University, Montreal, Canada, Monash University
Monash University
Monash University is a public university based in Melbourne, Victoria. It was founded in 1958 and is the second oldest university in the state. Monash is a member of Australia's Group of Eight and the ASAIHL....
, Australia and Tampere University of Technology, Tampere, Finland). Other reliability engineers typically have an engineering degree, which can be in any field of engineering, from an accredited university
University
A university is an institution of higher education and research, which grants academic degrees in a variety of subjects. A university is an organisation that provides both undergraduate education and postgraduate education...
or college
College
A college is an educational institution or a constituent part of an educational institution. Usage varies in English-speaking nations...
program. Many engineering programs offer reliability courses, and some universities have entire reliability engineering programs. A reliability engineer may be registered as a Professional Engineer
Professional Engineer
Regulation of the engineering profession is established by various jurisdictions of the world to protect the safety, well-being and other interests of the general public, and to define the licensure process through which an engineer becomes authorized to provide professional services to the...
by the state, but this is not required by most employers. There are many professional conferences and industry training programs available for reliability engineers. Several professional organizations exist for reliability engineers, including the IEEE Reliability Society
IEEE Reliability Society
The IEEE Reliability Society is a society of the Institute of Electrical and Electronics Engineers with a focus on Reliability Engineering.- History :...
, the American Society for Quality (ASQ), and the Society of Reliability Engineers (SRE).
See also
- Brittle Systems
- Burn-in
- Failing badlyFailing badlyFailing badly and failing well are concepts in systems security and network security describing how a system reacts to failure. The terms have been popularized by Bruce Schneier, a cryptographer and security consultant....
- Human reliabilityHuman reliabilityHuman reliability is related to the field of human factors engineering and ergonomics, and refers to the reliability of humans in fields such as manufacturing, transportation, the military, or medicine...
- Integrated Logistics SupportIntegrated Logistics SupportIntegrated logistics support is an integrated approach to the management of logistic disciplines in the military, similar to commercial product support or customer service organisations...
- Highly accelerated stress testHighly accelerated stress testThe highly accelerated stress test method was invented by Nihal Sinnadurai while working as a Research Engineer at British Telecommunications Research Laboratories in 1968 in order to perform highly accelerated reliability testing of electronics components that are likely to encounter humid...
- Highly Accelerated Life TestHighly Accelerated Life TestA highly accelerated life test , is a stress testing methodology for accelerating product reliability during the engineering development process. It is commonly applied to electronic equipment and is performed to identify and thus help resolve design weaknesses in newly-developed equipment...
- Logistic engineeringLogistic engineeringLogistics engineering is a branch of systems engineering dedicated to the scientific organization of the purchase, transport, storage, distribution, and warehousing of materials and finished goods....
- Performance engineeringPerformance EngineeringPerformance engineering within systems engineering, encompasses the set of roles, skills, activities, practices, tools, and deliverables applied at every phase of the Systems Development Life Cycle which ensures that a solution will be designed, implemented, and operationally supported to meet the...
- Professional engineerProfessional EngineerRegulation of the engineering profession is established by various jurisdictions of the world to protect the safety, well-being and other interests of the general public, and to define the licensure process through which an engineer becomes authorized to provide professional services to the...
- Product qualification
- Quality assuranceQuality AssuranceQuality assurance, or QA for short, is the systematic monitoring and evaluation of the various aspects of a project, service or facility to maximize the probability that minimum standards of quality are being attained by the production process...
- Reliability (disambiguation)
- Reliable system design
- Reliability theoryReliability theoryReliability theory describes the probability of a system completing its expected function during an interval of time. It is the basis of reliability engineering, which is an area of study focused on optimizing the reliability, or probability of successful functioning, of systems, such as airplanes,...
- Reliability theory of aging and longevityReliability theory of aging and longevityReliability theory of aging and longevity is a scientific approach aimed to gain theoretical insights into mechanisms of biological aging and species survival patterns by applying a general theory of systems failure, known as reliability theory.-Overview:...
- Risk assessmentRisk assessmentRisk assessment is a step in a risk management procedure. Risk assessment is the determination of quantitative or qualitative value of risk related to a concrete situation and a recognized threat...
- Redundancy (total quality management)Redundancy (total quality management)In total quality management, TQM, redundancy in quality or redundant quality means quality which exceeds the required quality level. Tolerances may be too accurate, for example, creating unnecessarily high costs of production....
- Security engineeringSecurity engineeringSecurity engineering is a specialized field of engineering that focuses on the security aspects in the design of systems that need to be able to deal robustly with possible sources of disruption, ranging from natural disasters to malicious acts...
- Single point of failureSingle point of failureA single point of failure is a part of a system that, if it fails, will stop the entire system from working. They are undesirable in any system with a goal of high availability or reliability, be it a business practice, software application, or other industrial system.-Overview:Systems can be made...
(SPOF) - Software engineeringSoftware engineeringSoftware Engineering is the application of a systematic, disciplined, quantifiable approach to the development, operation, and maintenance of software, and the study of these approaches; that is, the application of engineering to software...
- Systems engineeringSystems engineeringSystems engineering is an interdisciplinary field of engineering that focuses on how complex engineering projects should be designed and managed over the life cycle of the project. Issues such as logistics, the coordination of different teams, and automatic control of machinery become more...
- Temperature cyclingTemperature cyclingTemperature cycling is the process of cycling through two temperature extremes, typically at relatively high rates of change. It is an environmental stress test used in evaluating product reliability as well as in manufacturing to catch early-term, latent defects by inducing failure through...
- Spurious trip levelSpurious trip levelSpurious Trip Level is defined as a discrete level for specifying the spurious trip requirements of safety functions to be allocated to safety systems. An STL of 1 means that this safety function has the highest level of spurious trips. The higher the STL level the lower the number of spurious...
- Safety integrity levelSafety Integrity LevelSafety Integrity Level is defined as a relative level of risk-reduction provided by a safety function, or to specify a target level of risk reduction. In simple terms, SIL is a measurement of performance required for a Safety Instrumented Function ....
Further reading
- Blanchard, Benjamin S. (1992), Logistics Engineering and Management (Fourth Ed.), Prentice-Hall, Inc., Englewood Cliffs, New Jersey.
- Breitler, Alan L. and Sloan, C. (2005), Proceedings of the American Institute of Aeronautics and Astronautics (AIAA) Air Force T&E Days Conference, Nashville, TN, December, 2005: System Reliability Prediction: towards a General Approach Using a Neural Network.
- Ebeling, Charles E., (1997), An Introduction to Reliability and Maintainability Engineering, McGraw-Hill Companies, Inc., Boston.
- Denney, Richard (2005) Succeeding with Use Cases: Working Smart to Deliver Quality. Addison-Wesley Professional Publishing. ISBN . Discusses the use of software reliability engineering in use caseUse caseIn software engineering and systems engineering, a use case is a description of steps or actions between a user and a software system which leads the user towards something useful...
driven software development. - Gano, Dean L. (2007), "Apollo Root Cause Analysis" (Third Edition), Apollonian Publications, LLC., Richland, Washington
- Holmes, Oliver WendellOliver Wendell Holmes, Sr.Oliver Wendell Holmes, Sr. was an American physician, professor, lecturer, and author. Regarded by his peers as one of the best writers of the 19th century, he is considered a member of the Fireside Poets. His most famous prose works are the "Breakfast-Table" series, which began with The Autocrat...
, Sr. The Deacon's Masterpiece - Kapur, K.C., and Lamberson, L.R., (1977), Reliability in Engineering Design, John Wiley & Sons, New York.
- Kececioglu, Dimitri, (1991) "Reliability Engineering Handbook", Prentice-Hall, Englewood Cliffs, New Jersey
- Trevor KletzTrevor KletzTrevor Kletz OBE is a prolific British author on the topic of chemical engineering safety. He is credited with introducing the concept of inherent safety, and was a major promoter of Hazop.-Early life and education:...
(1998) Process Plants: A Handbook for Inherently Safer Design CRC ISBN 1-56032-619-0 - Leemis, Lawrence, (1995) Reliability: Probabilistic Models and Statistical Methods, 1995, Prentice-Hall. ISBN 0-13-720517-1
- MacDiarmid, Preston; Morris, Seymour; et al., (1995), Reliability Toolkit: Commercial Practices Edition, Reliability Analysis Center and Rome Laboratory, Rome, New York.
- Modarres, Mohammad; Kaminskiy, Mark; Krivtsov, Vasiliy (1999), "Reliability Engineering and Risk Analysis: A Practical Guide, CRC Press, ISBN 0-8247-2000-8.
- Musa, John (2005) Software Reliability Engineering: More Reliable Software Faster and Cheaper, 2nd. Edition, AuthorHouse. ISBN
- Neubeck, Ken (2004) "Practical Reliability Analysis", Prentice Hall, New Jersey
- Neufelder, Ann Marie, (1993), Ensuring Software Reliability, Marcel Dekker, Inc., New York.
- O'Connor, Patrick D. T. (2002), Practical Reliability Engineering (Fourth Ed.), John Wiley & Sons, New York.
- Shooman, Martin, (1987), Software Engineering: Design, Reliability, and Management, McGraw-Hill, New York.
- Tobias, Trindade, (1995), Applied Reliability, Chapman & Hall/CRC, ISBN 0-442-00469-9
- Springer Series in Reliability Engineering
- Nelson, Wayne B., (2004), Accelerated Testing - Statistical Models, Test Plans, and Data Analysis, John Wiley & Sons, New York, ISBN 0-471-69736-2
- Bagdonavicius, V., Nikulin, M., (2002), "Accelerated Life Models. Modeling and Statistical analysis", CHAPMAN&HALL/CRC, Boca Raton, ISBN 1-58488-186-0
US standards, specifications, and handbooks
- Aerospace Report Number: TOR-2007(8583)-6889 Reliability Program Requirements for Space Systems, The Aerospace CorporationThe Aerospace CorporationThe Aerospace Corporation is a private, non-profit corporation headquartered in El Segundo, California that has operated a Federally Funded Research and Development Center for the United States Air Force since 1960...
(10 Jul 2007) - DoD 3235.1-H (3rd Ed) Test and Evaluation of System Reliability, Availability, and Maintainability (A Primer), U.S. Department of Defense (March 1982) .
- NASA GSFC 431-REF-000370 Flight Assurance Procedure: Performing a Failure Mode and Effects Analysis, National Aeronautics and Space Administration Goddard Space Flight CenterGoddard Space Flight CenterThe Goddard Space Flight Center is a major NASA space research laboratory established on May 1, 1959 as NASA's first space flight center. GSFC employs approximately 10,000 civil servants and contractors, and is located approximately northeast of Washington, D.C. in Greenbelt, Maryland, USA. GSFC,...
(10 Aug 1996). - IEEE 1332-1998 IEEE Standard Reliability Program for the Development and Production of Electronic Systems and Equipment, Institute of Electrical and Electronics EngineersInstitute of Electrical and Electronics EngineersThe Institute of Electrical and Electronics Engineers is a non-profit professional association headquartered in New York City that is dedicated to advancing technological innovation and excellence...
(1998). - JPL D-5703 Reliability Analysis Handbook, National Aeronautics and Space Administration Jet Propulsion LaboratoryJet Propulsion LaboratoryJet Propulsion Laboratory is a federally funded research and development center and NASA field center located in the San Gabriel Valley area of Los Angeles County, California, United States. The facility is headquartered in the city of Pasadena on the border of La Cañada Flintridge and Pasadena...
(July 1990). - MIL-STD-785B Reliability Program for Systems and Equipment Development and Production, U.S. Department of Defense (15 Sep 1980). (*Obsolete, superseded by ANSI/GEIA-STD-0009-2008 titled Reliability Program Standard for Systems Design, Development, and Manufacturing, 13 Nov 2008)
- MIL-HDBK-217F Reliability Prediction of Electronic Equipment, U.S. Department of Defense (2 Dec 1991).
- MIL-HDBK-217F (Notice 1) Reliability Prediction of Electronic Equipment, U.S. Department of Defense (10 Jul 1992).
- MIL-HDBK-217F (Notice 2) Reliability Prediction of Electronic Equipment, U.S. Department of Defense (28 Feb 1995).
- MIL-STD-690D Failure Rate Sampling Plans and Procedures, U.S. Department of Defense (10 Jun 2005).
- MIL-HDBK-338B Electronic Reliability Design Handbook, U.S. Department of Defense (1 Oct 1998).
- MIL-HDBK-2173 Reliability-Centered Maintenance (RCM) Requirements for Naval Aircraft, Weapon Systems, and Support Equipment, U.S. Department of Defense (30 JAN 1998); (superseded by NAVAIR 00-25-403).
- MIL-STD-1543B Reliability Program Requirements for Space and Launch Vehicles, U.S. Department of Defense (25 Oct 1988).
- MIL-STD-1629A Procedures for Performing a Failure Mode Effects and Criticality Analysis, U.S. Department of Defense (24 Nov 1980).
- MIL-HDBK-781A Reliability Test Methods, Plans, and Environments for Engineering Development, Qualification, and Production, U.S. Department of Defense (1 Apr 1996).
- NSWC-06 (Part A) Handbook of Reliability Prediction Procedures for Mechanical Equipment, Naval Surface Warfare CenterNaval Surface Warfare CenterThe Naval Sea Systems Command Warfare Centers are composed of the Naval Surface Warfare Centers and the Naval Undersea Warfare Center . They operate in a seamless, integrated manner, and they collaborate with customers using a common work assignment process to get the right work to the right...
(10 Jan 2006). - NSWC-06 (Part B) Handbook of Reliability Prediction Procedures for Mechanical Equipment, Naval Surface Warfare CenterNaval Surface Warfare CenterThe Naval Sea Systems Command Warfare Centers are composed of the Naval Surface Warfare Centers and the Naval Undersea Warfare Center . They operate in a seamless, integrated manner, and they collaborate with customers using a common work assignment process to get the right work to the right...
(10 Jan 2006).
UK standards
In the UK, there are more up to date standards maintained under the sponsorship of UK MOD as Defence Standards. The relevant Standards include:DEF STAN 00-40 Reliability and Maintainability (R&M)
- PART 1: Issue 5: Management Responsibilities and Requirements for Programmes and Plans
- PART 4: (ARMP-4)Issue 2: Guidance for Writing NATO R&M Requirements Documents
- PART 6: Issue 1: IN-SERVICE R & M
- PART 7 (ARMP-7) Issue 1: NATO R&M Terminology Applicable to ARMP’s
DEF STAN 00-42 RELIABILITY AND MAINTAINABILITY ASSURANCE GUIDES
- PART 1: Issue 1: ONE-SHOT DEVICES/SYSTEMS
- PART 2: Issue 1: SOFTWARE
- PART 3: Issue 2: R&M CASE
- PART 4: Issue 1: Testability
- PART 5: Issue 1: IN-SERVICE RELIABILITY DEMONSTRATIONS
DEF STAN 00-43 RELIABILITY AND MAINTAINABILITY ASSURANCE ACTIVITY
- PART 2: Issue 1: IN-SERVICE MAINTAINABILITY DEMONSTRATIONS
DEF STAN 00-44 RELIABILITY AND MAINTAINABILITY DATA COLLECTION AND CLASSIFICATION
- PART 1: Issue 2: MAINTENANCE DATA & DEFECT REPORTING IN THE ROYAL NAVY, THE ARMY AND THE ROYAL AIR FORCE
- PART 2: Issue 1: DATA CLASSIFICATION AND INCIDENT SENTENCING - GENERAL
- PART 3: Issue 1: INCIDENT SENTENCING - SEA
- PART 4: Issue 1: INCIDENT SENTENCING - LAND
DEF STAN 00-45 Issue 1: RELIABILITY CENTERED MAINTENANCE
DEF STAN 00-49 Issue 1: RELIABILITY AND MAINTAINABILITY MOD GUIDE TO TERMINOLOGY DEFINITIONS
These can be obtained from DSTAN. There are also many commercial standards, produced by many organisations including the SAE, MSG, ARP, and IEE.
French standards
- FIDES http://fides-reliability.org. The FIDES methodology (UTE-C 80-811) is based on the physics of failures and supported by the analysis of test data, field returns and existing modelling.
- UTE-C 80-810 or RDF2000 http://www.ute-fr.com/FR/. The RDF2000 methodology is based on the French telecom experience.
International standards
External links
- American Society for Quality
- Carnegie Mellon Software Engineering Institute
- IEEE Reliability Society
- NASA Hardware and Software Reliability report
- NIST/SEMATECH, "Engineering Statistics Handbook", http://www.itl.nist.gov/div898/handbook/index.htm
- Society of Reliability Engineers
- University of Maryland Reliability Engineering Program
- Reliability Information Analysis Center
- Models and methods regarding reliability analysis
- UK Defence Standardization Organisation's Home on the Web
- Center for Risk and Reliability at University of Maryland, College Park
- Reliability Engineering services and software
- On-line Reliability Engineering Resources for the Reliability Professional
- EURELNET European Reliability Network - Failure Mechanisms and Materials Database
- Institut pour la Maitrise des Risques : Method Sheets, english version