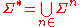A formal language is a set of words—that is, finite strings of letters, symbols, or tokens that are defined in the language. The set from which these letters are taken is the alphabet over which the language is defined. A formal language is often defined by means of a formal grammar...
Mathematical logic is a subfield of mathematics with close connections to foundations of mathematics, theoretical computer science and philosophical logic. The field includes both the mathematical study of logic and the applications of formal logic to other areas of mathematics...
Theoretical computer science is a division or subset of general computer science and mathematics which focuses on more abstract or mathematical aspects of computing....
In mathematics, a sequence is an ordered list of objects . Like a set, it contains members , and the number of terms is called the length of the sequence. Unlike a set, order matters, and exactly the same elements can appear multiple times at different positions in the sequence...
For other uses see Symbol In logic, symbols build literal utility to illustrate ideas. A symbol is an abstraction, tokens of which may be marks or a configuration of marks which form a particular pattern...
Computer programming is the process of designing, writing, testing, debugging, and maintaining the source code of computer programs. This source code is written in one or more programming languages. The purpose of programming is to create a program that performs specific operations or exhibits a...
, a string is traditionally a sequence of characters, either as a literal constant or as some kind of variable. The latter may allow its elements to be mutated and/or the length changed, or it may be fixed (after creation). A string is generally understood as a data type
Data type
In computer programming, a data type is a classification identifying one of various types of data, such as floating-point, integer, or Boolean, that determines the possible values for that type; the operations that can be done on values of that type; the meaning of the data; and the way values of...
The byte is a unit of digital information in computing and telecommunications that most commonly consists of eight bits. Historically, a byte was the number of bits used to encode a single character of text in a computer and for this reason it is the basic addressable element in many computer...
(or word) array that stores a sequence of elements, typically characters, using some character encoding
Character encoding
A character encoding system consists of a code that pairs each character from a given repertoire with something else, such as a sequence of natural numbers, octets or electrical pulses, in order to facilitate the transmission of data through telecommunication networks or storage of text in...
In computer science, an array type is a data type that is meant to describe a collection of elements , each selected by one or more indices that can be computed at run time by the program. Such a collection is usually called an array variable, array value, or simply array...
s and/or other sequential data types and structures; terms such as byte string, or more general, string ofdatatype, or datatype-string, are sometimes used to denote strings in which the stored data does not (necessarily) represent text.
Depending on programming language and/or precise datatype used, a variable
Variable (programming)
In computer programming, a variable is a symbolic name given to some known or unknown quantity or information, for the purpose of allowing the name to be used independently of the information it represents...
declared to be a string may either cause storage in memory to be statically allocated for a predetermined max length or employ dynamic allocation to allow it to hold chronologically variable number of elements.
When a string appears literally in source code
Source code
In computer science, source code is text written using the format and syntax of the programming language that it is being written in. Such a language is specially designed to facilitate the work of computer programmers, who specify the actions to be performed by a computer mostly by writing source...
A string literal is the representation of a string value within the source code of a computer program. There are numerous alternate notations for specifying string literals, and the exact notation depends on the individual programming language in question...
In mathematics, and more specifically set theory, the empty set is the unique set having no elements; its size or cardinality is zero. Some axiomatic set theories assure that the empty set exists by including an axiom of empty set; in other theories, its existence can be deduced...
finite set. Elements of Σ are called symbols or characters. A string (or word) over Σ is any finite sequence of characters from Σ. For example, if Σ = {0, 1}, then 0101 is a string over Σ.
In geometric measurements, length most commonly refers to the longest dimension of an object.In certain contexts, the term "length" is reserved for a certain dimension of an object along which the length is measured. For example it is possible to cut a length of a wire which is shorter than wire...
of a string is the number of characters in the string (the length of the sequence) and can be any non-negative integer. The empty string
Empty string
In computer science and formal language theory, the empty string is the unique string of length zero. It is denoted with λ or sometimes Λ or ε....
is the unique string over Σ of length 0, and is denoted ε or λ.
The set of all strings over Σ of length n is denoted Σn. For example, if Σ = {0, 1}, then Σ2 = {00, 01, 10, 11}. Note that Σ0 = {ε} for any alphabet Σ.
The set of all strings over Σ of any length is the Kleene closure
Kleene star
In mathematical logic and computer science, the Kleene star is a unary operation, either on sets of strings or on sets of symbols or characters. The application of the Kleene star to a set V is written as V*...
of Σ and is denoted Σ*. In terms of Σn,
For example, if Σ = {0, 1}, Σ* = {ε, 0, 1, 00, 01, 10, 11, 000, 001, 010, 011, …}. Although Σ* itself is countably infinite, all elements of Σ* have finite length.
In mathematics, especially in set theory, a set A is a subset of a set B if A is "contained" inside B. A and B may coincide. The relationship of one set being a subset of another is called inclusion or sometimes containment...
of Σ*) is called a formal language over Σ. For example, if Σ = {0, 1}, the set of strings with an even number of zeros ({ε, 1, 00, 11, 001, 010, 100, 111, 0000, 0011, 0101, 0110, 1001, 1010, 1100, 1111, …}) is a formal language over Σ.
In computer programming, string concatenation is the operation of joining two character strings end-to-end. For example, the strings "snow" and "ball" may be concatenated to give "snowball"...
In mathematics, a binary operation is a calculation involving two operands, in other words, an operation whose arity is two. Examples include the familiar arithmetic operations of addition, subtraction, multiplication and division....
on Σ*. For any two strings s and t in Σ*, their concatenation is defined as the sequence of characters in s followed by the sequence of characters in t, and is denoted st. For example, if Σ = {a, b, …, z}, s = bear, and t = hug, then st = bearhug and ts = hugbear.
String concatenation is an associative, but non-commutative operation. The empty string serves as the identity element
Identity element
In mathematics, an identity element is a special type of element of a set with respect to a binary operation on that set. It leaves other elements unchanged when combined with them...
; for any string s, εs = sε = s. Therefore, the set Σ* and the concatenation operation form a monoid
Monoid
In abstract algebra, a branch of mathematics, a monoid is an algebraic structure with a single associative binary operation and an identity element. Monoids are studied in semigroup theory as they are naturally semigroups with identity. Monoids occur in several branches of mathematics; for...
, the free monoid generated by Σ. In addition, the length function defines a monoid homomorphism from Σ* to the non-negative integers.
A subsequence, substring, prefix or suffix of a string is a subset of the symbols in a string, where the order of the elements is preserved...
or factor of t if there exist (possibly empty) strings u and v such that t = usv. The relation
Binary relation
In mathematics, a binary relation on a set A is a collection of ordered pairs of elements of A. In other words, it is a subset of the Cartesian product A2 = . More generally, a binary relation between two sets A and B is a subset of...
"is a substring of" defines a partial order on Σ*, the least element of which is the empty string.
Order theory is a branch of mathematics which investigates our intuitive notion of order using binary relations. It provides a formal framework for describing statements such as "this is less than that" or "this precedes that". This article introduces the field and gives some basic definitions...
on a set of strings. If the alphabet Σ has a total order
Total order
In set theory, a total order, linear order, simple order, or ordering is a binary relation on some set X. The relation is transitive, antisymmetric, and total...
(cf. alphabetical order) one can define a total order on Σ* called lexicographical order
Lexicographical order
In mathematics, the lexicographic or lexicographical order, , is a generalization of the way the alphabetical order of words is based on the alphabetical order of letters.-Definition:Given two partially ordered sets A and B, the lexicographical order on...
. For example, if Σ = {0, 1} and 0 < 1, then the lexicographical order on Σ* includes the relationships ε < 0 < 00 < 000 < … < 0001 < 001 < 01 < 010 < 011 < 0110 < 01111 < 1 < 10 < 100 < 101 < 111 < 1111 < 11111 …
String operations
A number of additional operations on strings commonly occur in the formal theory. These are given in the article on string operations
String operations
In computer science, in the area of formal language theory, frequent use is made of a variety of string functions; however, the notation used is different from that used on computer programming, and some commonly used functions in the theoretical realm are rarely used when programming...
.
Topology
Strings admit the following interpretation as nodes on a graph:
Fixed-length strings can be viewed as nodes on a hypercube
Hypercube
In geometry, a hypercube is an n-dimensional analogue of a square and a cube . It is a closed, compact, convex figure whose 1-skeleton consists of groups of opposite parallel line segments aligned in each of the space's dimensions, perpendicular to each other and of the same length.An...
Variable-length strings (of finite length) can be viewed as nodes on the k-ary tree
K-ary tree
In graph theory, a k-ary tree is a rooted tree in which each node has no more than k children. It is also sometimes known as a k-way tree, an N-ary tree, or an M-ary tree.A binary tree is the special case where k=2....
, where k is the number of symbols in Σ
Infinite strings can be viewed as infinite paths on the k-ary tree.
The natural topology on the set of fixed-length strings or variable length strings is the discrete topology, but the natural topology on the set of infinite strings is the limit topology, viewing the set of infinite strings as the inverse limit
Inverse limit
In mathematics, the inverse limit is a construction which allows one to "glue together" several related objects, the precise manner of the gluing process being specified by morphisms between the objects...
of the sets of finite strings. This is the construction used for the p-adic numbers and some constructions of the Cantor set
Cantor set
In mathematics, the Cantor set is a set of points lying on a single line segment that has a number of remarkable and deep properties. It was discovered in 1875 by Henry John Stephen Smith and introduced by German mathematician Georg Cantor in 1883....
, and yields the same topology.
String datatypes
A string datatype is a datatype modeled on the idea of a formal string. Strings are such an important and useful datatype that they are implemented in nearly every programming language
Programming language
A programming language is an artificial language designed to communicate instructions to a machine, particularly a computer. Programming languages can be used to create programs that control the behavior of a machine and/or to express algorithms precisely....
. In some languages they are available as primitive type
Primitive type
In computer science, primitive data type is either of the following:* a basic type is a data type provided by a programming language as a basic building block...
In computer science, a composite data type is any data type which can be constructed in a program using its programming language's primitive data types and other composite types...
In linguistics, syntax is the study of the principles and rules for constructing phrases and sentences in natural languages....
of most high-level programming languages allows for a string, usually quoted in some way, to represent an instance of a string datatype; such a meta-string is called a literal or string literal.
String length
Although formal strings can have an arbitrary (but finite) length, the length of strings in real languages is often constrained to an artificial maximum. In general, there are two types of string datatypes: fixed-length strings, which have a fixed maximum length and which use the same amount of memory whether this maximum is reached or not, and variable-length strings, whose length is not arbitrarily fixed and which use varying amounts of memory depending on their actual size. Most strings in modern programming languages are variable-length strings. Despite the name, even variable-length strings are limited in length, although, in general, the limit depends only on the amount of memory
Computer memory
In computing, memory refers to the physical devices used to store programs or data on a temporary or permanent basis for use in a computer or other digital electronic device. The term primary memory is used for the information in physical systems which are fast In computing, memory refers to the...
available. The string length can be stored as a separate integer (which puts a theoretical limit on the length) or implicitly through a termination character, usually a character value with all bits zero. See also "Null-terminated" below.
Character encoding
String datatypes have historically allocated one byte per character, and, although the exact character set varied by region, character encodings were similar enough that programmers could often get away with ignoring this — since characters a program treated specially (such as period and space and comma) were in the same place in all the encodings a program would encounter. These character sets were typically based on ASCII
ASCII
The American Standard Code for Information Interchange is a character-encoding scheme based on the ordering of the English alphabet. ASCII codes represent text in computers, communications equipment, and other devices that use text...
Extended Binary Coded Decimal Interchange Code is an 8-bit character encoding used mainly on IBM mainframe and IBM midrange computer operating systems....
The Chinese language is a language or language family consisting of varieties which are mutually intelligible to varying degrees. Originally the indigenous languages spoken by the Han Chinese in China, it forms one of the branches of Sino-Tibetan family of languages...
is a language spoken by over 130 million people in Japan and in Japanese emigrant communities. It is a member of the Japonic language family, which has a number of proposed relationships with other languages, none of which has gained wide acceptance among historical linguists .Japanese is an...
Korean is the official language of the country Korea, in both South and North. It is also one of the two official languages in the Yanbian Korean Autonomous Prefecture in People's Republic of China. There are about 78 million Korean speakers worldwide. In the 15th century, a national writing...
CJK is a collective term for Chinese, Japanese, and Korean, which is used in the field of software and communications internationalization.The term CJKV means CJK plus Vietnamese, which constitute the main East Asian languages.- Characteristics :...
) need far more than 256 characters (the limit of a one 8-bit byte per-character encoding) for reasonable representation. The normal solutions involved keeping single-byte representations for ASCII and using two-byte representations for CJK ideographs. Use of these with existing code led to problems with matching and cutting of strings, the severity of which depended on how the character encoding was designed. Some encodings such as the EUC
Extended Unix Code
Extended Unix Code is a multibyte character encoding system used primarily for Japanese, Korean, and simplified Chinese.The structure of EUC is based on the ISO-2022 standard, which specifies a way to represent character sets containing a maximum of 94 characters, or 8836 characters, or 830584 ...
family guarantee that a byte value in the ASCII range will represent only that ASCII character, making the encoding safe for systems that use those characters as field separators. Other encodings such as ISO-2022 and Shift-JIS
Shift-JIS
Shift JIS is a character encoding for the Japanese language originally developed by a Japanese company called ASCII Corporation in conjunction with Microsoft and standardized as JIS X 0208 Appendix 1...
do not make such guarantees, making matching on byte codes unsafe. These encodings also were not "self-synchronizing", so that locating character boundaries required backing up to the start of a string, and pasting two strings together could result in corruption of the second string (these problems were much less with EUC as any ASCII character did synchronize the encoding).
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
has simplified the picture somewhat. Most programming languages have a datatype for Unicode strings (usually UTF-16 as it was usually added before Unicode supplemental planes were introduced). Unicode's preferred byte stream format UTF-8
UTF-8
UTF-8 is a multibyte character encoding for Unicode. Like UTF-16 and UTF-32, UTF-8 can represent every character in the Unicode character set. Unlike them, it is backward-compatible with ASCII and avoids the complications of endianness and byte order marks...
is designed not to have the problems described above for older multibyte encodings. All UTF-8, UTF-16 and UTF-32 require the programmer to know that the fixed-size code units are different than the "characters", the main difficulty currently is incorrectly designed API's that attempt to hide this difference.
C++ is a statically typed, free-form, multi-paradigm, compiled, general-purpose programming language. It is regarded as an intermediate-level language, as it comprises a combination of both high-level and low-level language features. It was developed by Bjarne Stroustrup starting in 1979 at Bell...
In a broad definition, generic programming is a style of computer programming in which algorithms are written in terms of to-be-specified-later types that are then instantiated when needed for specific types provided as parameters...
that can be used with any datatype, but this is the exception, not the rule.
Ruby is a dynamic, reflective, general-purpose object-oriented programming language that combines syntax inspired by Perl with Smalltalk-like features. Ruby originated in Japan during the mid-1990s and was first developed and designed by Yukihiro "Matz" Matsumoto...
, normally allow the contents of a string to be changed after it has been created; these are termed mutable strings. In other languages, such as Java
Java (programming language)
Java is a programming language originally developed by James Gosling at Sun Microsystems and released in 1995 as a core component of Sun Microsystems' Java platform. The language derives much of its syntax from C and C++ but has a simpler object model and fewer low-level facilities...
Python is a general-purpose, high-level programming language whose design philosophy emphasizes code readability. Python claims to "[combine] remarkable power with very clear syntax", and its standard library is large and comprehensive...
, the value is fixed and a new string must be created if any alteration is to be made; these are termed immutable strings.
In computer science, an array type is a data type that is meant to describe a collection of elements , each selected by one or more indices that can be computed at run time by the program. Such a collection is usually called an array variable, array value, or simply array...
of characters, in order to allow fast access to individual characters. A few languages such as Haskell
Haskell (programming language)
Haskell is a standardized, general-purpose purely functional programming language, with non-strict semantics and strong static typing. It is named after logician Haskell Curry. In Haskell, "a function is a first-class citizen" of the programming language. As a functional programming language, the...
In computer science, a linked list is a data structure consisting of a group of nodes which together represent a sequence. Under the simplest form, each node is composed of a datum and a reference to the next node in the sequence; more complex variants add additional links...
Prolog is a general purpose logic programming language associated with artificial intelligence and computational linguistics.Prolog has its roots in first-order logic, a formal logic, and unlike many other programming languages, Prolog is declarative: the program logic is expressed in terms of...
and Erlang, avoid implementing a dedicated string datatype at all, instead adopting the convention of representing strings as lists of character codes.
Representations
Representations of strings depend heavily on the choice of character repertoire and the method of character encoding. Older string implementations were designed to work with repertoire and encoding defined by ASCII, or more recent extensions like the ISO 8859 series. Modern implementations often use the extensive repertoire defined by Unicode along with a variety of complex encodings such as UTF-8 and UTF-16.
Most string implementations are very similar to variable-length array
Array data type
In computer science, an array type is a data type that is meant to describe a collection of elements , each selected by one or more indices that can be computed at run time by the program. Such a collection is usually called an array variable, array value, or simply array...
s with the entries storing the character codes of corresponding characters. The principal difference is that, with certain encodings, a single logical character may take up more than one entry in the array. This happens for example with UTF-8, where single characters can take anywhere from one to four bytes. In these cases, the logical length of the string (number of characters) differs from the logical length of the array (number of bytes in use). UTF-32 is the only Unicode encoding that avoids this problem.
Null-terminated
The length of a string can be stored implicitly by using a special terminating character; often this is the null character
Null character
The null character , abbreviated NUL, is a control character with the value zero.It is present in many character sets, including ISO/IEC 646 , the C0 control code, the Universal Character Set , and EBCDIC...
(NUL), which has all bits zero, a convention used and perpetuated by the popular C programming language
C (programming language)
C is a general-purpose computer programming language developed between 1969 and 1973 by Dennis Ritchie at the Bell Telephone Laboratories for use with the Unix operating system....
. Hence, this representation is commonly referred to as C string. The length of a string can also be stored explicitly, for example by prefixing the string with the length as a byte value — a convention used in many Pascal
Pascal (programming language)
Pascal is an influential imperative and procedural programming language, designed in 1968/9 and published in 1970 by Niklaus Wirth as a small and efficient language intended to encourage good programming practices using structured programming and data structuring.A derivative known as Object Pascal...
dialects; as a consequence, some people call it a P-string. Storing the string length as byte limits the maximum string length to 255. To avoid such limitations, improved implementations of P-strings use 16-
16-bit
-16-bit architecture:The HP BPC, introduced in 1975, was the world's first 16-bit microprocessor. Prominent 16-bit processors include the PDP-11, Intel 8086, Intel 80286 and the WDC 65C816. The Intel 8088 was program-compatible with the Intel 8086, and was 16-bit in that its registers were 16...
The range of integer values that can be stored in 32 bits is 0 through 4,294,967,295. Hence, a processor with 32-bit memory addresses can directly access 4 GB of byte-addressable memory....
64-bit is a word size that defines certain classes of computer architecture, buses, memory and CPUs, and by extension the software that runs on them. 64-bit CPUs have existed in supercomputers since the 1970s and in RISC-based workstations and servers since the early 1990s...
words to store the string length. When the length field covers the address space
Address space
In computing, an address space defines a range of discrete addresses, each of which may correspond to a network host, peripheral device, disk sector, a memory cell or other logical or physical entity.- Overview :...
strings are limited only by the available memory.
In terminated strings, the terminating code is not an allowable character in any string. Strings with length field do not have this limitation and can also store arbitrary binary data. In C two things are needed to handle binary data, a character pointer and the length of the data.
The term bytestring usually indicates a general-purpose string of bytes — rather than strings of only (readable) characters, strings of bits, or such. Byte strings often imply that bytes can take any value and any data can be stored as-is, meaning that there should be no value interpreted as a termination value.
Here is an example of a null-terminated string stored in a 10-byte buffer
Buffer (computer science)
In computer science, a buffer is a region of a physical memory storage used to temporarily hold data while it is being moved from one place to another. Typically, the data is stored in a buffer as it is retrieved from an input device or just before it is sent to an output device...
UTF-8 is a multibyte character encoding for Unicode. Like UTF-16 and UTF-32, UTF-8 can represent every character in the Unicode character set. Unlike them, it is backward-compatible with ASCII and avoids the complications of endianness and byte order marks...
) representation as 8-bit hexadecimal numbers:
|-
| F >
R
A
N
NUL
| style="background: #DDD" | k
| style="background: #DDD" | e
| style="background: #DDD" | f
| style="background: #DDD" | w
|-
| 46h
52h
41h
4Eh
The length of the string in the above example, "FRANK", is 5 characters, but it occupies 6 bytes. Characters after the terminator do not form part of the representation; they may be either part of another string or just garbage. (Strings of this form are sometimes called ASCIZ strings, after the original assembly language
Assembly language
An assembly language is a low-level programming language for computers, microprocessors, microcontrollers, and other programmable devices. It implements a symbolic representation of the machine codes and other constants needed to program a given CPU architecture...
directive used to declare them.)
Length-prefixed
Here is the equivalent (old style) Pascal string stored in a 10-byte buffer, along with its ASCII / UTF-8 representation:
|-
| length
| F >
R
A
N
k
| style="background: #DDD" | e
| style="background: #DDD" | f
| style="background: #DDD" | w
|-
| 5dec
| 46h
52h
41h
4Eh
Object oriented
An object oriented language will typically implement a string like this: class string {
int length;
char *text;
};
although this implemention is hidden, and accessed through member functions. The "text" will be a dynamically allocated memory area, that might be expanded if needed. See also string (C++)
String (C++)
In the C++ programming language, the std::string class is a standard representation for a string of text. This class alleviates many of the problems introduced by C-style strings by putting the onus of memory ownership on the string class rather than on the programmer...
.
Linked-list
Both character termination and length codes limit strings: For example, C character arrays that contain null (NUL) characters cannot be handled directly by C string library functions: Strings using a length code are limited to the maximum value of the length code.
Both of these limitations can be overcome by clever programming, of course, but such workarounds are by definition not standard.
Rough equivalents of the C termination method have historically appeared in both hardware and software. For example, "data processing" machines like the IBM 1401
IBM 1401
The IBM 1401 was a variable wordlength decimal computer that was announced by IBM on October 5, 1959. The first member of the highly successful IBM 1400 series, it was aimed at replacing electromechanical unit record equipment for processing data stored on punched cards...
used a special word mark bit to delimit strings at the left, where the operation would start at the right. This meant that, while the IBM 1401 had a seven-bit word in "reality", almost no-one ever thought to use this as a feature, and override the assignment of the seventh bit to (for example) handle ASCII codes.
It is possible to create data structures and functions that manipulate them that do not have the problems associated with character termination and can in principle overcome length code bounds. It is also possible to optimize the string represented using techniques from run length encoding
Run-length encoding
Run-length encoding is a very simple form of data compression in which runs of data are stored as a single data value and count, rather than as the original run...
(replacing repeated characters by the character value and a length) and Hamming encoding.
While these representations are common, others are possible. Using rope
Rope (computer science)
In computer programming a rope, or cord, is a data structure for efficiently storing and manipulating a very long string. For example, a text editing program may use a rope to represent the text being edited, so that operations such as insertion, deletion, and random access can be done...
s makes certain string operations, such as insertions, deletions, and concatenations more efficient.
Text file strings
In computer readable text files, for example programming language source files or configuration files, strings can be represented. The NUL byte is normally not used as terminator since that does not correspond to the ASCII text standard, and the length is usually not stored, since the file should be human editable without bugs.
Quotation marks or inverted commas are punctuation marks at the beginning and end of a quotation, direct speech, literal title or name. Quotation marks can also be used to indicate a different meaning of a word or phrase than the one typically associated with it and are often used to express irony...
s (ASCII 22h), used by most programming languages. To be able to include quotation marks, newline characters etc, escape sequence
Escape character
In computing and telecommunication, an escape character is a character which invokes an alternative interpretation on subsequent characters in a character sequence. An escape character is a particular case of metacharacters...
s are often available, usually using the backslash
Backslash
The backslash is a typographical mark used mainly in computing. It was first introduced to computers in 1960 by Bob Bemer. Sometimes called a reverse solidus or a slosh, it is the mirror image of the common slash....
In computing, a newline, also known as a line break or end-of-line marker, is a special character or sequence of characters signifying the end of a line of text. The name comes from the fact that the next character after the newline will appear on a new line—that is, on the next line below the...
A string literal is the representation of a string value within the source code of a computer program. There are numerous alternate notations for specifying string literals, and the exact notation depends on the individual programming language in question...
.
Non-text strings
While character strings are very common uses of strings, a string in computer science may refer generically to any sequence of homogeneously typed data. A string of bit
Bit
A bit is the basic unit of information in computing and telecommunications; it is the amount of information stored by a digital device or other physical system that exists in one of two possible distinct states...
s or bytes, for example, may be used to represent non-textual binary data retrieved from a communications medium. This data may or may not be represented by a string-specific datatype, depending on the needs of the application, the desire of the programmer, and the capabilities of the programming language being used.
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
s for processing strings, each with various trade-offs. Some categories of algorithms include:
String searching algorithms, sometimes called string matching algorithms, are an important class of string algorithms that try to find a place where one or several strings are found within a larger string or text....
In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order...
In computing, a regular expression provides a concise and flexible means for "matching" strings of text, such as particular characters, words, or patterns of characters. Abbreviations for "regular expression" include "regex" and "regexp"...
algorithms
Parsing a string
Advanced string algorithms often employ complex mechanisms and data structures, among them suffix tree
Suffix tree
In computer science, a suffix tree is a data structure that presents the suffixes of a given string in a way that allows for a particularly fast implementation of many important string operations.The suffix tree for a string S is a tree whose edges are labeled with strings, such that each suffix...
A finite-state machine or finite-state automaton , or simply a state machine, is a mathematical model used to design computer programs and digital logic circuits. It is conceived as an abstract machine that can be in one of a finite number of states...
s.
Character string oriented languages and utilities
Character strings are such a useful datatype that several languages have been designed in order to make string processing applications easy to write. Examples include the following languages:
The AWK utility is a data extraction and reporting tool that uses a data-driven scripting language consisting of a set of actions to be taken against textual data for the purpose of producing formatted reports...
MUMPS , or alternatively M, is a programming language created in the late 1960s, originally for use in the healthcare industry. It was designed for the production of multi-user database-driven applications...
Perl is a high-level, general-purpose, interpreted, dynamic programming language. Perl was originally developed by Larry Wall in 1987 as a general-purpose Unix scripting language to make report processing easier. Since then, it has undergone many changes and revisions and become widely popular...
REXX is an interpreted programming language that was developed at IBM. It is a structured high-level programming language that was designed to be both easy to learn and easy to read...
Ruby is a dynamic, reflective, general-purpose object-oriented programming language that combines syntax inspired by Perl with Smalltalk-like features. Ruby originated in Japan during the mid-1990s and was first developed and designed by Yukihiro "Matz" Matsumoto...
sed is a Unix utility that parses text and implements a programming language which can apply transformations to such text. It reads input line by line , applying the operation which has been specified via the command line , and then outputs the line. It was developed from 1973 to 1974 as a Unix...
SNOBOL is a generic name for the computer programming languages developed between 1962 and 1967 at AT&T Bell Laboratories by David J. Farber, Ralph E. Griswold and Ivan P. Polonsky, culminating in SNOBOL4...
Tcl is a scripting language created by John Ousterhout. Originally "born out of frustration", according to the author, with programmers devising their own languages intended to be embedded into applications, Tcl gained acceptance on its own...
Unix is a multitasking, multi-user computer operating system originally developed in 1969 by a group of AT&T employees at Bell Labs, including Ken Thompson, Dennis Ritchie, Brian Kernighan, Douglas McIlroy, and Joe Ossanna...
utilities perform simple string manipulations and can be used to easily program some powerful string processing algorithms. Files and finite streams may be viewed as strings.
An application programming interface is a source code based specification intended to be used as an interface by software components to communicate with each other...
Embedded SQL is a method of combining the computing power of a programming language and the database manipulation capabilities of SQL. Embedded SQL statements are SQL statements written inline with the program source code of the host language. The embedded SQL statements are parsed by an embedded...
Printf format string refers to a control parameter used by a class of functions typically associated with some types of programming languages. The format string specifies a method for rendering an arbitrary number of varied data type parameter into a string...
use strings to hold commands that will be interpreted.
Recent scripting programming languages, including Perl, Python
Python (programming language)
Python is a general-purpose, high-level programming language whose design philosophy emphasizes code readability. Python claims to "[combine] remarkable power with very clear syntax", and its standard library is large and comprehensive...
In computing, a regular expression provides a concise and flexible means for "matching" strings of text, such as particular characters, words, or patterns of characters. Abbreviations for "regular expression" include "regex" and "regexp"...
String interpolation is a common feature in many programming languages such as Ruby, PHP, Perl, etc. It means to insert a string or replace a variable with its value. It makes string formatting and specifying contents more intuitive.- PHP :...
, which permits arbitrary expressions to be evaluated and included in string literals.
Character string functions
String functions are used to manipulate a string or change or edit the contents of a string. They also are used to query information about a string. They are usually used within the context of a computer programming language
Programming language
A programming language is an artificial language designed to communicate instructions to a machine, particularly a computer. Programming languages can be used to create programs that control the behavior of a machine and/or to express algorithms precisely....
.
The most basic example of a string function is the length(string) function, which returns the length of a string (not counting any terminator characters or any of the string's internal structural information) and does not modify the string. For example, length("helloworld") returns 11.
There are many string functions that exist in other languages with similar or exactly the same syntax or parameters. For example, in many languages, the length function is usually represented as len(string). Even though string functions are very useful to a computer programmer, a computer programmer using these functions should be mindful that a string function in one language could in another language behave differently or have a similar or completely different function name, parameters, syntax, and results.
In computing, a connection string is a string that specifies information about a data source and the means of connecting to it. It is passed in code to an underlying driver or provider in order to initiate the connection...
In computer programming a rope, or cord, is a data structure for efficiently storing and manipulating a very long string. For example, a text editing program may use a rope to represent the text being edited, so that operations such as insertion, deletion, and random access can be done...
An incompressible string is one that cannot be compressed because it lacks sufficient repeating sequences. Whether a string is compressible will often depend on the algorithm being used...
In mathematics, string metrics are a class of metric that measure similarity or dissimilarity between two text strings for approximate string matching or comparison and in fuzzy string searching. For example the strings "Sam" and "Samuel" can be considered to be similar...
In the C++ programming language, the std::string class is a standard representation for a string of text. This class alleviates many of the problems introduced by C-style strings by putting the onus of memory ownership on the string class rather than on the programmer...
string.h
:Category:Algorithms on strings
The source of this article is wikipedia, the free encyclopedia. The text of this article is licensed under the GFDL.