

Pre- and post-test probability
Encyclopedia
Pre-test probability and post-test probability (alternatively spelled pretest and posttest probability) are the subjective
probabilities of the presence of a condition (such as a disease
) before and after a diagnostic test, respectively. Post-test probability, in turn, can be positive or negative, depending on whether the test falls out as a positive test or a negative test
, respectively. In some cases, it is used for the probability of developing the condition of interest in the future.
The subjectivity of the probabilities are based one that, in reality, an individual either has the condition or not (with the probability always being either 0% or 100%), so pre- and post-test probabilities for individuals can rather be regarded as psychological phenomenons in the minds of those involved in the diagnostics at hand.
Test, in this sense, can refer to any medical test
(but usually in the sense of diagnostic tests), and in a broad sense also including questions and even assumptions (such as assuming that the target individual is a female or male). The ability to make a difference between pre- and posttest probabilities of various conditions is a major factor in the indication of medical tests.
sign or symptom, in which case it is almost certain that the target condition is present; or in the absence of finding a sine qua non
sign or symptom, in which case it is almost certain that the target condition is absent.
In reality, however, the subjective probability of the presence of a condition is never exactly 0 or 100%. Yet, there are several systematic methods to estimate that probability. Such methods are usually based on previously having performed the test on a reference group
in which the presence or absence on the condition is known (or at least estimated by another test that is considered highly accurate, such as by "Gold standard
), in order to establish data of test performance. These data are subsequently used to to interpret the test result of any individual tested by the method. An alternative or complement to reference group-based methods is comparing a test result to a previous test on the same individual, which is more common in tests for monitoring
.
The most important systematic reference group-based methods to estimate post-test probability includes the ones summarized and compared in the following table, and further described in individual sections below.
on which both test results and knowledge on the presence or absence of the condition (for example a disease, such as may determined by "Gold standard
) are available.
If the test result is of a binary classification
into either positive or negative tests, then the following table can be made:
Pre-test probability can be calculated from the diagram as follows:
Pretest probability = (True positive + False negative) / Total sample
Also, in this case, the positive post-test probability (the probability of having the target condition if the test falls out positive), is numerically equal to the positive predictive value
, and the negative post-test probability (the probability of having the target condition if the test falls out negative) is numerically complementary to the negative predictive value
([ negative post-test probability] = 1 - [ negative predictive value] ), again assuming that the individual being tested does not have any other risk factors that result in that individual having a different pre-test probability than the reference group used to establish the positive and negative predictive values of the test.
In the diagram above, this positive post-test probability, that is, the posttest probability of a target condition given a positive test result, is calculated as:
Positive posttest probability = True positives / (True positives + False positives)
Similarly:
The post-test probability of disease given a negative result is calculated as:
Negative posttest probability = False negatives / (False negatives + True negatives)
The validity of the equations above also depend on that the sample from the population does not have substantial sampling bias that could cause the groups of those who have the condition and those who do not to be substantially disproportionate from corresponding prevalence and "non-prevalence" in the population. In effect, the equations above are not valid with merely a case-control study that separately collects one group with the condition and one group without it.
, signs in a physical examination
, either by calculating on each finding as a test in itself with its own sensitivity and specificity, or at least making a rough estimation of the individual pre-test probability.
In these cases, the prevalence in the reference group is not completely accurate in representing the pre-test probability of the individual, and, consequently, the predictive value (whether positive or negative) is not completely accurate in representing the post-test probability of the individual of having the target condition.
In these cases, a posttest probability can be estimated more accurately by using a likelihood ratio for the test. Likelihood ratio is calculated from sensitivity and specificity
of the test, and thereby it does not depend on prevalence in the reference group, and, likewise, it does not change with changed pre-test probability, in contrast to positive or negative predictive values (which would change). Also, in effect, the validity of post-test probability determined from likelihood ratio is not vulnerable to sampling bias in regard to those with and without the condition in the population sample, and can be done as a case-control study that separately gathers those with and without the condition.
Estimation of post-test probability from pre-test probability and likelihood ratio goes as follows:
In equation above, positive post-test probability is calculated using the likelihood ratio positive, and the negative post-test probability is calculated using the likelihood ratio negative.
The relation can also be estimated by a so called Fagan nomogram (shown at right) by making a straight line from the point of the given pre-test probability to the given likelihood ratio in their scales, which, in turn, estimates the post-test probability at the point where that straight line crosses its scale.
The post-test probability can, in turn, be used as pre-test probability for additional tests if it continues to be calculated in the same manner.
(FOB) to estimate the probability for that person having the target condition of bowel cancer, and it fell out positive (blood were detected in stool). Before the test, that individual had a pre-test probability of having bowel cancer of, for example, 3% (0.03), as could have been estimated by evaluation of, for example, the medical history, examination and previous tests of that individual.
The sensitivity, specificity etc. of the FOB test were established with a population sample of 203 people (without such heredity), and fell out as follows:
From this, the likelihood ratios of the test can be established:
Thus, that individual has a post-test probability (or "post-test "risk") of 18.6% of having bowel cancer.
The prevalence
in the population sample is calculated to be:
The individual's pre-test probability was more than twice the one of the population sample, although the individual's post-test probability was less than twice the one of the population sample (which is estimated by the positive predictive value of the test of 10%), opposite to what would result by a less accurate method of simply multiplying relative risks.
Post-test probability, as estimated from the pre-test probability with likelihood ratio, should be handled with caution in individuals with other determinants (such as risk factors) than the general population, as well as in individuals that have undergone previous tests, because such determinants or tests may also influence the test itself in unpredictive ways, still causing inaccurate results. An example with the risk factor of obesity
is that additional abdominal fat can make it difficult to palpate abdominal organs and decrease the resolution of abdominal ultrasonography
, and similarly, remnant barium contrast from a previous radiography can interfere with subsequent abdominal examinations, in effect decreasing the sensitivities and specificities of such subsequent tests. On the other hand, the effect of interference can potentially improve the efficacy of subsequent tests as compared to usage in the reference group, such as some abdominal examinations being easier when performed on underweight people.
Furthermore, the validity of calculations upon any pre-test probability that itself is derived from a previous test depend on that the two tests do not significantly overlap in regard to the target parameter being tested, such as blood tests of substances belonging to one and the same deranged metabolic pathway
. An example of the extreme of such an overlap is where the sensitivity and specificity has been established for a blood test detecting "substance X", and likewise for one detecting "substance Y". If, in fact, "substance X" and "substance Y" are one and the same substance, then, making a two consecutive tests of one and the same substance may not have any diagnostic value at all, although the calculation appears to show a difference. In contrast to interference as described above, increasing overlap of tests only decreases their efficacy. In the medical setting, diagnostic validity is increased by combining tests of different modalities to avoid substantial overlap, for example in making a combination of a blood test, a biopsy
and radiograph
.
To avoid such sources of inaccuracy by using likelihood ratios, the optimal method would be to gather a large reference group of equivalent individuals, in order to establish separate predictive values for use of the test in such individuals. However, with more knowledge of an individual's medical history, physical examination and previous test etc. that individual becomes more unique, with increasing difficulty to find a reference group to establish tailored predictive values, making an estimation of post-test probability by predictive values invalid.
Another method to overcome such inaccuracies is by evaluating the test result in the context of diagnostic critera, as described in the next section.
given by the test. In clinical practice, this is usually applied in evaluation of a medical history
of an individual, where the "test" usually is a question (or even assumption) regarding various risk factors, for example, sex, tobacco smoking
or weight, but it can potentially be a substantial test such as putting the individual on a weighing scale
. When using relative risks, the resultant probability is usually rather related to the individual developing the condition over a period of time (similarly to the incidence
in a population), instead of being the probability of an individual of having the condition in the present, but can indirectly be an estimation of the latter.
Usage of hazard ratio
can be used somewhat similarly to relative risk.
If only one risk factor of an individual is taken into account, the post-test probability can be estimated by multiplying the relative risk with the risk in the control group. The control group usually represents the unexposed population, but if a very low fraction of the population is exposed, then the prevalence in the general population can often be assumed to be equal to the prevalence in the control group. In such cases, the post-test probability can be estimated by multiplying the relative risk with the risk in the general population.
For example, the incidence
of breast cancer
in a woman in the United Kingdom at age 55 to 59 is estimated to be approximately 280 cases per 100.000 per year, and the risk factor of having been exposed to high-dose ionizing radiation
to the chest (for example, as treatments for other cancers) confers a relative risk of breast cancer between 2.1 to 4.0, compared to unexposed. Because a low fraction of the population is exposed, the prevalence in the unexposed population can be assumed to be equal to the prevalence in the general population. Subsequently, it can be estimated that a woman in the United Kingdom that is aged between 55 and 59 and that has been exposed to high-dose ionizing radiation should have a risk of developing breast cancer over a period of one year of between 588 and 1.120 in 100.000 (that is, between 0,6% and 1.1%).
The (latter mentioned) effect of overestimation can be compensated for by converting risks to odds, and relative risks to odds ratio
s. However, this does not compensate for (former mentioned) effect of any difference between pre-test probability of an individual and the prevalence in the reference group.
A method to compensate for both sources of inaccuracy above is to establish the relative risks by multivariate regression analysis. However, to retain its validity, relative risks established as such need to be multiplied with all the other risk factors in the same regression analysis, and without any addition of other factors beyond the regression analysis.
In addition, multiplying multiple relative risks has the same risk of missing important overlaps of the included risk factors, similarly to when using likelihood ratios. Also, different risk factors can act in synergy
, with the result that, for example, two factors that both individually have a relative risk of 2 have a total relative risk of 6 when both are present, or can inhibit each other, somewhat similarly to the interference described for using likelihood ratios.
s. The establishment of diagnostic criteria or clinical prediction rules consists of a comprehensive evaluation of many tests that are regarded to be important in estimating the probability of a condition of interest, sometimes also including how to divide it into subgroups, and when and how to treat the condition. Such establishment can include usage of predictive values, likelihood ratios as well as relative risks.
For example, the ACR criteria for systemic lupus erythematosis defines the diagnosis as presence of at least 4 out of 11 findings, each of which can be regarded as a target value of a test with its own sensitivity and specificity. In this case, there has been evaluation of the tests for these target parameters when used in combination in regard to, for example, interference between them and overlap of target parameters, thereby striving to avoid inaccuracies that could otherwise arise if attempting to calculate the probability of the disease using likelihood ratios of the individual tests. Therefore, if diagnostic criteria have been established for a condition, it is generally most appropriate to interpret any post-test probability for that condition in the context of these criteria.
Also, there are risk assessment tools for estimating the combined risk of several risk factors, such as the online tool http://hp2010.nhlbihin.net/atpiii/calculator.asp?usertype=prof from the Framingham Heart Study
for estimating the risk for coronary heart disease outcomes using multiple risk factors, including age, gender, blood lipids, blood pressure and smoking, being much more accurate than multiplying the individual relative risks of each risk factor.
Still, an experienced physician may estimate the post-test probability (and the actions it motivates) by a broad consideration including criteria and rules in addition to other methods described previously, including both individual risk factors and the performances of tests that have been carried out.
Absolute
difference =
(pre-test probability) - (post-test probability)|
A major factor for such an absolute difference is the power of the test itself, such as can be described in terms of, for example, sensitivity and specificity or likelihood ratio. Another factor is the pre-test probability, with a lower pre-test probability resulting in a lower absolute difference, with the consequence that even very powerful tests achieve a low absolute difference for very unlikely conditions in an individual (such as rare disease
s in the absence of any other indicating sign), but on the other hand, that even tests with low power can make a great difference for highly suspected conditions.
The probabilities in this sense may also need to be considered in context of conditions that are not primary targets of the test, such as profile-relative probabilities in a differential diagnostic procedure.
The absolute difference can be put in relation to the benefit for an individual that a medical test
achieves, such as can roughly be estimated as:
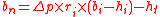 , where:
, where:
Additional factors that influence a decision whether a medical test should be performed or not include: cost of the test, availability of additional tests, potential interference with subsequent test (such as an abdominal palpation potentially inducing intestinal activity whose sounds interfere with a subsequent abdominal auscultation), time taken for the test or other practical or administrative aspects. Also, even if not beneficial for the individual being tested, the results may be useful for the establishment of statistics in order to improve health care for other individuals.
Subjectivity
Subjectivity refers to the subject and his or her perspective, feelings, beliefs, and desires. In philosophy, the term is usually contrasted with objectivity.-Qualia:...
probabilities of the presence of a condition (such as a disease
Disease
A disease is an abnormal condition affecting the body of an organism. It is often construed to be a medical condition associated with specific symptoms and signs. It may be caused by external factors, such as infectious disease, or it may be caused by internal dysfunctions, such as autoimmune...
) before and after a diagnostic test, respectively. Post-test probability, in turn, can be positive or negative, depending on whether the test falls out as a positive test or a negative test
Negative test
The subject Negative Test can relate to:*A negative medical test, in which the target parameter that was evaluated was not present.*In software testing, a test designed to determine the response of the system outside of what is defined. It is designed to determine if the system doesn't crash with...
, respectively. In some cases, it is used for the probability of developing the condition of interest in the future.
The subjectivity of the probabilities are based one that, in reality, an individual either has the condition or not (with the probability always being either 0% or 100%), so pre- and post-test probabilities for individuals can rather be regarded as psychological phenomenons in the minds of those involved in the diagnostics at hand.
Test, in this sense, can refer to any medical test
Medical test
A diagnostic test is any kind of medical test performed to aid in the diagnosis or detection of disease. For example:* to diagnose diseases, and preferably sub-classify it regarding, for example, severity and treatability...
(but usually in the sense of diagnostic tests), and in a broad sense also including questions and even assumptions (such as assuming that the target individual is a female or male). The ability to make a difference between pre- and posttest probabilities of various conditions is a major factor in the indication of medical tests.
Pre-test probability
The pre-test probability of an individual can be chosen to be one of the following:- The prevalencePrevalenceIn epidemiology, the prevalence of a health-related state in a statistical population is defined as the total number of cases of the risk factor in the population at a given time, or the total number of cases in the population, divided by the number of individuals in the population...
of the disease, which may have to be chosen if no other characteristic is known for the individual, or it can be chosen for ease of calculation even if other characteristics are known although such omission may cause inaccurate results - The post-test probability of the condition resulting from one or more preceding tests
- A rough estimation, which may have to be chosen if more systematic approaches are not possible or efficient
Estimation of post-test probability
In clinical practice, post-test probabilities are often just roughly estimated or even guessed. This is usually acceptable in the finding of a pathognomonicPathognomonic
Pathognomonic is a term, often used in medicine, that means characteristic for a particular disease. A pathognomonic sign is a particular sign whose presence means that a particular disease is present beyond any doubt...
sign or symptom, in which case it is almost certain that the target condition is present; or in the absence of finding a sine qua non
Sine qua non
Sine qua non or condicio sine qua non refers to an indispensable and essential action, condition, or ingredient...
sign or symptom, in which case it is almost certain that the target condition is absent.
In reality, however, the subjective probability of the presence of a condition is never exactly 0 or 100%. Yet, there are several systematic methods to estimate that probability. Such methods are usually based on previously having performed the test on a reference group
Reference group
A reference group is a concept referring to a group to which an individual or another group is compared.Sociologists call any group that individuals use as a standard for evaluating themselves and their own behavior a reference group....
in which the presence or absence on the condition is known (or at least estimated by another test that is considered highly accurate, such as by "Gold standard
Gold standard (test)
In medicine and statistics, gold standard test refers to a diagnostic test or benchmark that is the best available under reasonable conditions. It does not have to be necessarily the best possible test for the condition in absolute terms...
), in order to establish data of test performance. These data are subsequently used to to interpret the test result of any individual tested by the method. An alternative or complement to reference group-based methods is comparing a test result to a previous test on the same individual, which is more common in tests for monitoring
Monitoring (medicine)
In medicine, monitoring is the evaluation of a disease or condition over time.It can be performed by continuously measuring certain parameters , and/or by repeatedly performing medical tests .Transmitting data from a monitor to a distant...
.
The most important systematic reference group-based methods to estimate post-test probability includes the ones summarized and compared in the following table, and further described in individual sections below.
| Method | Establishment of performance data | Method of individual interpretation | Ability to accurately interpret subsequent tests | Additional advantages | Additional disadvantages |
|---|---|---|---|---|---|
| By predictive values | Direct quotients from reference group | Most straightforward: Predictive value equals probability | Usually low: Separate reference group required for every subsequent pre-test state | Available both for binary Binary classification Binary classification is the task of classifying the members of a given set of objects into two groups on the basis of whether they have some property or not. Some typical binary classification tasks are... and continuous values |
|
| By likelihood ratio | Derived from sensitivity and specificity Sensitivity and specificity Sensitivity and specificity are statistical measures of the performance of a binary classification test, also known in statistics as classification function. Sensitivity measures the proportion of actual positives which are correctly identified as such Sensitivity and specificity are statistical... |
Post-test odds given by multiplying pretest odds with the ratio | Theoretically limitless | Pre-test state (and thus the pre-test probability) does not have to be same as in reference group | Requires binary Binary classification Binary classification is the task of classifying the members of a given set of objects into two groups on the basis of whether they have some property or not. Some typical binary classification tasks are... values |
| By relative risk Relative risk In statistics and mathematical epidemiology, relative risk is the risk of an event relative to exposure. Relative risk is a ratio of the probability of the event occurring in the exposed group versus a non-exposed group.... |
Quotient of risk among exposed and risk of unexposed | Pre-test probability multiplied by the relative risk | Low, unless subsequent relative risks are derived from same multivariate regression analysis | Relatively intuitive to use | Result usually related to incidence rather than having the condition right now |
| By diagnostic criteria and clinical prediction rules | Variable, but usually most tedious | Variable | Usually excellent for all test included in criteria | Usually most preferable if available |
By predictive values
Predictive values can be used to estimate the post-test probability of an individual if the pre-test probability of the individual can be assumed to be roughly equal to the prevalence in a reference groupReference group
A reference group is a concept referring to a group to which an individual or another group is compared.Sociologists call any group that individuals use as a standard for evaluating themselves and their own behavior a reference group....
on which both test results and knowledge on the presence or absence of the condition (for example a disease, such as may determined by "Gold standard
Gold standard (test)
In medicine and statistics, gold standard test refers to a diagnostic test or benchmark that is the best available under reasonable conditions. It does not have to be necessarily the best possible test for the condition in absolute terms...
) are available.
If the test result is of a binary classification
Binary classification
Binary classification is the task of classifying the members of a given set of objects into two groups on the basis of whether they have some property or not. Some typical binary classification tasks are...
into either positive or negative tests, then the following table can be made:
| Condition (as determined by "Gold standard Gold standard (test) In medicine and statistics, gold standard test refers to a diagnostic test or benchmark that is the best available under reasonable conditions. It does not have to be necessarily the best possible test for the condition in absolute terms... ") |
||||
| Positive | Negative | |||
| Test outcome |
Positive | True Positive | False Positive (Type I error) |
→ Positive predictive value Positive predictive value In statistics and diagnostic testing, the positive predictive value, or precision rate is the proportion of subjects with positive test results who are correctly diagnosed. It is a critical measure of the performance of a diagnostic method, as it reflects the probability that a positive test... |
| Negative | False Negative (Type II error) |
True Negative | → Negative predictive value Negative predictive value In statistics and diagnostic testing, the negative predictive value is a summary statistic used to describe the performance of a diagnostic testing procedure. It is defined as the proportion of subjects with a negative test result who are correctly diagnosed. A high NPV means that when the test... |
|
| ↓ Sensitivity Sensitivity and specificity Sensitivity and specificity are statistical measures of the performance of a binary classification test, also known in statistics as classification function. Sensitivity measures the proportion of actual positives which are correctly identified as such Sensitivity and specificity are statistical... |
↓ Specificity Sensitivity and specificity Sensitivity and specificity are statistical measures of the performance of a binary classification test, also known in statistics as classification function. Sensitivity measures the proportion of actual positives which are correctly identified as such Sensitivity and specificity are statistical... |
|||
Pre-test probability can be calculated from the diagram as follows:
Pretest probability = (True positive + False negative) / Total sample
Also, in this case, the positive post-test probability (the probability of having the target condition if the test falls out positive), is numerically equal to the positive predictive value
Positive predictive value
In statistics and diagnostic testing, the positive predictive value, or precision rate is the proportion of subjects with positive test results who are correctly diagnosed. It is a critical measure of the performance of a diagnostic method, as it reflects the probability that a positive test...
, and the negative post-test probability (the probability of having the target condition if the test falls out negative) is numerically complementary to the negative predictive value
Negative predictive value
In statistics and diagnostic testing, the negative predictive value is a summary statistic used to describe the performance of a diagnostic testing procedure. It is defined as the proportion of subjects with a negative test result who are correctly diagnosed. A high NPV means that when the test...
(
In the diagram above, this positive post-test probability, that is, the posttest probability of a target condition given a positive test result, is calculated as:
Positive posttest probability = True positives / (True positives + False positives)
Similarly:
The post-test probability of disease given a negative result is calculated as:
Negative posttest probability = False negatives / (False negatives + True negatives)
The validity of the equations above also depend on that the sample from the population does not have substantial sampling bias that could cause the groups of those who have the condition and those who do not to be substantially disproportionate from corresponding prevalence and "non-prevalence" in the population. In effect, the equations above are not valid with merely a case-control study that separately collects one group with the condition and one group without it.
By likelihood ratio
The above methods are inappropriate to use if the pretest probability differs from the prevalence in the reference group used to establish, among others, the positive predictive value of the test. Such difference can occur if another test preceded, or the person involved in the diagnostics considers that another pretest probability has to be used because of knowledge of, for example, specific complaints, other elements of a medical historyMedical history
The medical history or anamnesis of a patient is information gained by a physician by asking specific questions, either of the patient or of other people who know the person and can give suitable information , with the aim of obtaining information useful in formulating a diagnosis and providing...
, signs in a physical examination
Physical examination
Physical examination or clinical examination is the process by which a doctor investigates the body of a patient for signs of disease. It generally follows the taking of the medical history — an account of the symptoms as experienced by the patient...
, either by calculating on each finding as a test in itself with its own sensitivity and specificity, or at least making a rough estimation of the individual pre-test probability.
In these cases, the prevalence in the reference group is not completely accurate in representing the pre-test probability of the individual, and, consequently, the predictive value (whether positive or negative) is not completely accurate in representing the post-test probability of the individual of having the target condition.
In these cases, a posttest probability can be estimated more accurately by using a likelihood ratio for the test. Likelihood ratio is calculated from sensitivity and specificity
Sensitivity and specificity
Sensitivity and specificity are statistical measures of the performance of a binary classification test, also known in statistics as classification function. Sensitivity measures the proportion of actual positives which are correctly identified as such Sensitivity and specificity are statistical...
of the test, and thereby it does not depend on prevalence in the reference group, and, likewise, it does not change with changed pre-test probability, in contrast to positive or negative predictive values (which would change). Also, in effect, the validity of post-test probability determined from likelihood ratio is not vulnerable to sampling bias in regard to those with and without the condition in the population sample, and can be done as a case-control study that separately gathers those with and without the condition.
Estimation of post-test probability from pre-test probability and likelihood ratio goes as follows:
- Pretest odds = (Pretest probability / (1 - Pretest probability)
- Posttest odds = Pretest odds * Likelihood ratio
In equation above, positive post-test probability is calculated using the likelihood ratio positive, and the negative post-test probability is calculated using the likelihood ratio negative.
- Posttest probability = Posttest odds / (Posttest odds + 1)
The relation can also be estimated by a so called Fagan nomogram (shown at right) by making a straight line from the point of the given pre-test probability to the given likelihood ratio in their scales, which, in turn, estimates the post-test probability at the point where that straight line crosses its scale.
The post-test probability can, in turn, be used as pre-test probability for additional tests if it continues to be calculated in the same manner.
Example
An individual was screened with the test of fecal occult bloodFecal occult blood
Fecal occult blood refers to blood in the feces that is not visibly apparent. A fecal occult blood test checks for hidden blood in the stool...
(FOB) to estimate the probability for that person having the target condition of bowel cancer, and it fell out positive (blood were detected in stool). Before the test, that individual had a pre-test probability of having bowel cancer of, for example, 3% (0.03), as could have been estimated by evaluation of, for example, the medical history, examination and previous tests of that individual.
The sensitivity, specificity etc. of the FOB test were established with a population sample of 203 people (without such heredity), and fell out as follows:
| Patients with bowel cancer (as confirmed on endoscopy Endoscopy Endoscopy means looking inside and typically refers to looking inside the body for medical reasons using an endoscope , an instrument used to examine the interior of a hollow organ or cavity of the body. Unlike most other medical imaging devices, endoscopes are inserted directly into the organ... ) |
||||
| Positive | Negative | |||
| Fecal occult blood screen test outcome |
Positive | TP = 2 | FP = 18 | → Positive predictive value = TP / (TP + FP) = 2 / (2 + 18) = 2 / 20 = 10% |
| Negative | FN = 1 | TN = 182 | → Negative predictive value = TN / (FN + TN) = 182 / (1 + 182) = 182 / 183 ≈ 99.5% |
|
| ↓ Sensitivity = TP / (TP + FN) = 2 / (2 + 1) = 2 / 3 ≈ 66.67% |
↓ Specificity = TN / (FP + TN) = 182 / (18 + 182) = 182 / 200 = 91% |
|||
From this, the likelihood ratios of the test can be established:
- Likelihood ratio positive = sensitivity / (1 − specificity) = 66.67% / (1 − 91%) = 7.4
- Likelihood ratio negative = (1 − sensitivity) / specificity = (1 − 66.67%) / 91% = 0.37
- Pretest probability (in this example) = 0.03
- Pretest odds = 0.03 / (1 - 0.03) = 0.0309
- Positive posttest odds = 0.0309 * 7.4 = 0.229
- Positive posttest probability = 0.229 / (0.229 + 1) = 0.186 or 18.6%
Thus, that individual has a post-test probability (or "post-test "risk") of 18.6% of having bowel cancer.
The prevalence
Prevalence
In epidemiology, the prevalence of a health-related state in a statistical population is defined as the total number of cases of the risk factor in the population at a given time, or the total number of cases in the population, divided by the number of individuals in the population...
in the population sample is calculated to be:
- Prevalence = (2 + 1) / 203 = 0.0148 or 1.48%
The individual's pre-test probability was more than twice the one of the population sample, although the individual's post-test probability was less than twice the one of the population sample (which is estimated by the positive predictive value of the test of 10%), opposite to what would result by a less accurate method of simply multiplying relative risks.
Specific sources of inaccuracy
Specific sources of inaccuracy when using likelihood ratio to determine a post-test probability include interference with determinants or previous tests or overlap of test targets, as explained below:Interference with test
Post-test probability, as estimated from the pre-test probability with likelihood ratio, should be handled with caution in individuals with other determinants (such as risk factors) than the general population, as well as in individuals that have undergone previous tests, because such determinants or tests may also influence the test itself in unpredictive ways, still causing inaccurate results. An example with the risk factor of obesity
Obesity
Obesity is a medical condition in which excess body fat has accumulated to the extent that it may have an adverse effect on health, leading to reduced life expectancy and/or increased health problems...
is that additional abdominal fat can make it difficult to palpate abdominal organs and decrease the resolution of abdominal ultrasonography
Abdominal ultrasonography
Abdominal ultrasonography is a form of medical ultrasonography to visualise abdominal anatomical structures...
, and similarly, remnant barium contrast from a previous radiography can interfere with subsequent abdominal examinations, in effect decreasing the sensitivities and specificities of such subsequent tests. On the other hand, the effect of interference can potentially improve the efficacy of subsequent tests as compared to usage in the reference group, such as some abdominal examinations being easier when performed on underweight people.
Overlap of tests
Furthermore, the validity of calculations upon any pre-test probability that itself is derived from a previous test depend on that the two tests do not significantly overlap in regard to the target parameter being tested, such as blood tests of substances belonging to one and the same deranged metabolic pathway
Metabolic pathway
In biochemistry, metabolic pathways are series of chemical reactions occurring within a cell. In each pathway, a principal chemical is modified by a series of chemical reactions. Enzymes catalyze these reactions, and often require dietary minerals, vitamins, and other cofactors in order to function...
. An example of the extreme of such an overlap is where the sensitivity and specificity has been established for a blood test detecting "substance X", and likewise for one detecting "substance Y". If, in fact, "substance X" and "substance Y" are one and the same substance, then, making a two consecutive tests of one and the same substance may not have any diagnostic value at all, although the calculation appears to show a difference. In contrast to interference as described above, increasing overlap of tests only decreases their efficacy. In the medical setting, diagnostic validity is increased by combining tests of different modalities to avoid substantial overlap, for example in making a combination of a blood test, a biopsy
Biopsy
A biopsy is a medical test involving sampling of cells or tissues for examination. It is the medical removal of tissue from a living subject to determine the presence or extent of a disease. The tissue is generally examined under a microscope by a pathologist, and can also be analyzed chemically...
and radiograph
Radiography
Radiography is the use of X-rays to view a non-uniformly composed material such as the human body. By using the physical properties of the ray an image can be developed which displays areas of different density and composition....
.
Methods to overcome inaccuracy
To avoid such sources of inaccuracy by using likelihood ratios, the optimal method would be to gather a large reference group of equivalent individuals, in order to establish separate predictive values for use of the test in such individuals. However, with more knowledge of an individual's medical history, physical examination and previous test etc. that individual becomes more unique, with increasing difficulty to find a reference group to establish tailored predictive values, making an estimation of post-test probability by predictive values invalid.
Another method to overcome such inaccuracies is by evaluating the test result in the context of diagnostic critera, as described in the next section.
By relative risk
Post-test probability can sometimes be estimated by multiplying the pre-test probability with a relative riskRelative risk
In statistics and mathematical epidemiology, relative risk is the risk of an event relative to exposure. Relative risk is a ratio of the probability of the event occurring in the exposed group versus a non-exposed group....
given by the test. In clinical practice, this is usually applied in evaluation of a medical history
Medical history
The medical history or anamnesis of a patient is information gained by a physician by asking specific questions, either of the patient or of other people who know the person and can give suitable information , with the aim of obtaining information useful in formulating a diagnosis and providing...
of an individual, where the "test" usually is a question (or even assumption) regarding various risk factors, for example, sex, tobacco smoking
Tobacco smoking
Tobacco smoking is the practice where tobacco is burned and the resulting smoke is inhaled. The practice may have begun as early as 5000–3000 BCE. Tobacco was introduced to Eurasia in the late 16th century where it followed common trade routes...
or weight, but it can potentially be a substantial test such as putting the individual on a weighing scale
Weighing scale
A weighing scale is a measuring instrument for determining the weight or mass of an object. A spring scale measures weight by the distance a spring deflects under its load...
. When using relative risks, the resultant probability is usually rather related to the individual developing the condition over a period of time (similarly to the incidence
Incidence
Incidence may refer to:* Incidence , a measure of the risk of developing some new condition within a specified period of time* Incidence , the binary relations describing how subsets meet...
in a population), instead of being the probability of an individual of having the condition in the present, but can indirectly be an estimation of the latter.
Usage of hazard ratio
Hazard ratio
In survival analysis, the hazard ratio is the ratio of the hazard rates corresponding to the conditions described by two sets of explanatory variables. For example, in a drug study, the treated population may die at twice the rate per unit time as the control population. The hazard ratio would be...
can be used somewhat similarly to relative risk.
One risk factor
To establish a relative risk, the risk in an exposed group is divided by the risk in an unexposed group.If only one risk factor of an individual is taken into account, the post-test probability can be estimated by multiplying the relative risk with the risk in the control group. The control group usually represents the unexposed population, but if a very low fraction of the population is exposed, then the prevalence in the general population can often be assumed to be equal to the prevalence in the control group. In such cases, the post-test probability can be estimated by multiplying the relative risk with the risk in the general population.
For example, the incidence
Incidence
Incidence may refer to:* Incidence , a measure of the risk of developing some new condition within a specified period of time* Incidence , the binary relations describing how subsets meet...
of breast cancer
Breast cancer
Breast cancer is cancer originating from breast tissue, most commonly from the inner lining of milk ducts or the lobules that supply the ducts with milk. Cancers originating from ducts are known as ductal carcinomas; those originating from lobules are known as lobular carcinomas...
in a woman in the United Kingdom at age 55 to 59 is estimated to be approximately 280 cases per 100.000 per year, and the risk factor of having been exposed to high-dose ionizing radiation
Ionizing radiation
Ionizing radiation is radiation composed of particles that individually have sufficient energy to remove an electron from an atom or molecule. This ionization produces free radicals, which are atoms or molecules containing unpaired electrons...
to the chest (for example, as treatments for other cancers) confers a relative risk of breast cancer between 2.1 to 4.0, compared to unexposed. Because a low fraction of the population is exposed, the prevalence in the unexposed population can be assumed to be equal to the prevalence in the general population. Subsequently, it can be estimated that a woman in the United Kingdom that is aged between 55 and 59 and that has been exposed to high-dose ionizing radiation should have a risk of developing breast cancer over a period of one year of between 588 and 1.120 in 100.000 (that is, between 0,6% and 1.1%).
Multiple risk factors
Theoretically, the total risk in the presence of multiple risk factors can be roughly estimated by multiplying with each relative risk, but is generally much less accurate than using likelihood ratios, and is usually done only because it is much easier to perform when only relative risks are given, compared to, for example, converting the source data to sensitivities and specificities and calculate by likelihood ratios. Likewise, relative risks are often given instead of likelihood ratios in the literature because the former is more intuitive. Sources of inaccuracy of multiplying relative risks include:- Relative risks are affected by the prevalence of the condition in the reference group (in contrast to likelihood ratios, which are not), and this issue results in that the validity of post-test probabilities become less valid with increasing difference between the prevalence in the reference group and the pre-test probability for any individual. Any known risk factor or previous test of an individual almost always confers such a difference, decreasing the validity of using relative risks in estimating the total effect of multiple risk factors or tests. Most physicians do not appropriately take such differences in prevalence into account when interpreting test results, which may cause unnecessary testing and diagnostic errors.
- A separate source of inaccuracy of multiplying several relative risks, considering only positive tests, is that it tends to overestimate the total risk as compared to using likelihood ratios. This overestimation can be explained by the inability of the method to compensate for the fact that the total risk cannot be more than 100%. This overestimation is rather small for small risks, but becomes higher for higher values. For example, the risk of developing breast cancer at an age younger than 40 years in women in the United Kingdom can be estimated to be approximately 2%. Also, studies on Ashkenazi JewsAshkenazi JewsAshkenazi Jews, also known as Ashkenazic Jews or Ashkenazim , are the Jews descended from the medieval Jewish communities along the Rhine in Germany from Alsace in the south to the Rhineland in the north. Ashkenaz is the medieval Hebrew name for this region and thus for Germany...
has indicated that a mutation in BRCA1BRCA1BRCA1 is a human caretaker gene that produces a protein called breast cancer type 1 susceptibility protein, responsible for repairing DNA. The first evidence for the existence of the gene was provided by the King laboratory at UC Berkeley in 1990...
confers a relative risk of 21.6 of developing breast cancer in women under 40 years of age, and a mutation in BRCA2BRCA2BRCA2 is a protein that in humans is encoded by the BRCA2 gene.BRCA2 orthologs have been identified in most mammals for which complete genome data are available....
confers a relative risk of 3.3 of developing breast cancer in women under 40 years of age. From these data, it may be estimated that a woman with a BRCA1 mutation would have a risk of approximately 40% of developing breast cancer at an age younger than 40 years, and woman with a BRCA2 mutation would have a risk of approximately 6%. However, in the rather improbable situation of having both a BRCA1 and a BRCA2 mutation, simply multiplying with both relative risks would result in a risk of over 140% of developing breast cancer before 40 years of age, which can not possibly be accurate in reality.
The (latter mentioned) effect of overestimation can be compensated for by converting risks to odds, and relative risks to odds ratio
Odds ratio
The odds ratio is a measure of effect size, describing the strength of association or non-independence between two binary data values. It is used as a descriptive statistic, and plays an important role in logistic regression...
s. However, this does not compensate for (former mentioned) effect of any difference between pre-test probability of an individual and the prevalence in the reference group.
A method to compensate for both sources of inaccuracy above is to establish the relative risks by multivariate regression analysis. However, to retain its validity, relative risks established as such need to be multiplied with all the other risk factors in the same regression analysis, and without any addition of other factors beyond the regression analysis.
In addition, multiplying multiple relative risks has the same risk of missing important overlaps of the included risk factors, similarly to when using likelihood ratios. Also, different risk factors can act in synergy
Synergy
Synergy may be defined as two or more things functioning together to produce a result not independently obtainable.The term synergy comes from the Greek word from , , meaning "working together".-Definitions and usages:...
, with the result that, for example, two factors that both individually have a relative risk of 2 have a total relative risk of 6 when both are present, or can inhibit each other, somewhat similarly to the interference described for using likelihood ratios.
By diagnostic criteria and clinical prediction rules
Most major diseases have established diagnostic criteria and/or clinical prediction ruleClinical prediction rule
A clinical prediction rule is type of medical research study in which researchers try to identify the best combination of medical sign, symptoms, and other findings in predicting the probability of a specific disease or outcome....
s. The establishment of diagnostic criteria or clinical prediction rules consists of a comprehensive evaluation of many tests that are regarded to be important in estimating the probability of a condition of interest, sometimes also including how to divide it into subgroups, and when and how to treat the condition. Such establishment can include usage of predictive values, likelihood ratios as well as relative risks.
For example, the ACR criteria for systemic lupus erythematosis defines the diagnosis as presence of at least 4 out of 11 findings, each of which can be regarded as a target value of a test with its own sensitivity and specificity. In this case, there has been evaluation of the tests for these target parameters when used in combination in regard to, for example, interference between them and overlap of target parameters, thereby striving to avoid inaccuracies that could otherwise arise if attempting to calculate the probability of the disease using likelihood ratios of the individual tests. Therefore, if diagnostic criteria have been established for a condition, it is generally most appropriate to interpret any post-test probability for that condition in the context of these criteria.
Also, there are risk assessment tools for estimating the combined risk of several risk factors, such as the online tool http://hp2010.nhlbihin.net/atpiii/calculator.asp?usertype=prof from the Framingham Heart Study
Framingham Heart Study
The Framingham Heart Study is a long-term, ongoing cardiovascular study on residents of the town of Framingham, Massachusetts. The study began in 1948 with 5,209 adult subjects from Framingham, and is now on its third generation of participants...
for estimating the risk for coronary heart disease outcomes using multiple risk factors, including age, gender, blood lipids, blood pressure and smoking, being much more accurate than multiplying the individual relative risks of each risk factor.
Still, an experienced physician may estimate the post-test probability (and the actions it motivates) by a broad consideration including criteria and rules in addition to other methods described previously, including both individual risk factors and the performances of tests that have been carried out.
Clinical use of pre- and post-test probabilities
A clinically useful parameter is the absolute (rather than relative, and not negative) difference between pre- and post-test probability, calculated as:Absolute
Absolute value
In mathematics, the absolute value |a| of a real number a is the numerical value of a without regard to its sign. So, for example, the absolute value of 3 is 3, and the absolute value of -3 is also 3...
difference =
Absolute value
In mathematics, the absolute value |a| of a real number a is the numerical value of a without regard to its sign. So, for example, the absolute value of 3 is 3, and the absolute value of -3 is also 3...
(pre-test probability) - (post-test probability)
A major factor for such an absolute difference is the power of the test itself, such as can be described in terms of, for example, sensitivity and specificity or likelihood ratio. Another factor is the pre-test probability, with a lower pre-test probability resulting in a lower absolute difference, with the consequence that even very powerful tests achieve a low absolute difference for very unlikely conditions in an individual (such as rare disease
Rare disease
A rare disease, also referred to as an orphan disease, is any disease that affects a small percentage of the population.Most rare diseases are genetic, and thus are present throughout the person's entire life, even if symptoms do not immediately appear...
s in the absence of any other indicating sign), but on the other hand, that even tests with low power can make a great difference for highly suspected conditions.
The probabilities in this sense may also need to be considered in context of conditions that are not primary targets of the test, such as profile-relative probabilities in a differential diagnostic procedure.
The absolute difference can be put in relation to the benefit for an individual that a medical test
Medical test
A diagnostic test is any kind of medical test performed to aid in the diagnosis or detection of disease. For example:* to diagnose diseases, and preferably sub-classify it regarding, for example, severity and treatability...
achieves, such as can roughly be estimated as:
, where:
- bn is the net benefit of performing a medical test
- Λp is the absolute difference between pre- and posttest probability of conditions (such as diseases) that the test is expected to achieve.
- ri is the rate of how much probability differences are expected to result in changes in interventions (such as a change from "no treatment" to "administration of low-dose medical treatment"). For example, if the only expected effect of a medical test is to make one disease more likely compared to another, but the two diseases have the same treatment (or neither can be treated), then, this factor is very low and the test is probably without value for the individual in this aspect.
- bi is the benefit of changes in interventions for the individual
- hi is the harm of changes in interventions for the individual, such as side effectsSide EffectsSide Effects is an anthology of 17 comical short stories written by Woody Allen between 1975 and 1980, all but one of which were previously published in, variously, The New Republic, The New York Times, The New Yorker, and The Kenyon Review. It includes Allen's 1978 O...
of medical treatment - ht is the harm caused by the test itself
Additional factors that influence a decision whether a medical test should be performed or not include: cost of the test, availability of additional tests, potential interference with subsequent test (such as an abdominal palpation potentially inducing intestinal activity whose sounds interfere with a subsequent abdominal auscultation), time taken for the test or other practical or administrative aspects. Also, even if not beneficial for the individual being tested, the results may be useful for the establishment of statistics in order to improve health care for other individuals.
See also
- Diagnostic test interpretation, including general sources of inaccuracy and imprecision